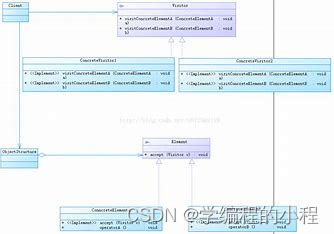
一、什么是闭合项集? Close算法对Apriori算法的改进在什么地方?
闭合项集:就是指一个项集x,它的直接超集的支持度计数都不等于它本身的支持度计数。
改进的地方:
改进方向:
加速频繁项目集合的生成,减少数据库库的扫描次数。
close算法改进基于的基本原理:
一个频繁闭合项目集的所有闭合子集一定是频繁的;一个非频繁闭合项目集的所有闭合超集一定是非频繁的。
二、Fp-tree是如何压缩数据库的?建立下表的条件模式库,并挖掘频繁模式。Min_ sup=3.关联规则的种类有哪些?举例说明。
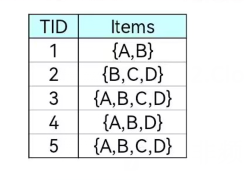
解题思路:
1、建立项头表
我们第一次扫描数据,得到所有频繁一项集的计数。然后删除支持低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。接着第二次也是最后一次扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
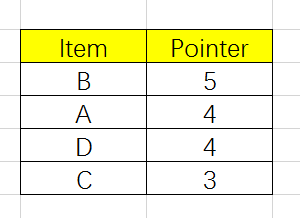
2、将原始数据进行排序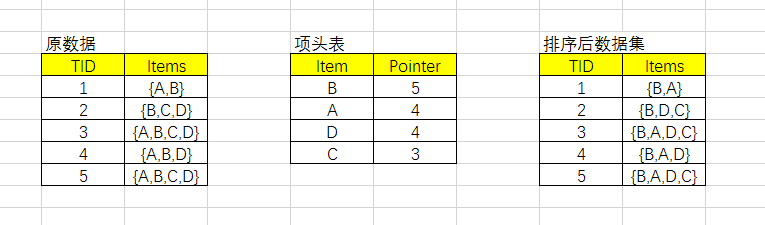
3、FP Tree的建立
有了项头表和排序后的数据集,我们就可以开始FP树的建立了。开始FP树没有数据,建立FP树时我们一条条的读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,靠后的是子孙节点。如果有共用的祖先,则对应的共用祖先节点计数加1。插入后,如果有新节点出现,则项头表的节点会通过节点链表链接上新节点。知道所有的数据都插入到FP树后。FP树建立完成
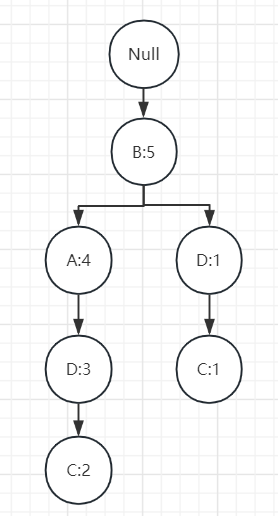
4、FP Tree的挖掘
得到了FP树和项头表以及节点链表,我们首先要从项头表的底部项依次向上挖掘。对于项头表对应于FP树的每一项,我们要找到它的条件模式基。所谓条件模式基是以我们要挖掘的节点作为叶子节点所对应的FP子树。得到这个FP子树,我们将子树中每个节点的的计数设置为叶子节点的计数,并删除计数低于支持度的节点。从这个条件模式基,我们就可以递归挖掘得到频繁项集了。
5、FP Tree算法归纳
1)扫描数据,得到所有频繁一项集的的计数。然后删除支持度低于阈值的项,将1项频繁集放入项头表,并按照支持度降序排列。
2)扫描数据,将读到的原始数据剔除非频繁1项集,并按照支持度降序排列。
3)读入排序后的数据集,插入FP树,插入时按照排序后的顺序,插入FP树中,排序靠前的节点是祖先节点,而靠后的是子孙节点。如果有共用的祖先,则对应的公用祖先节点计数加1。插入后,如果有新节点出现,则项头表对应的节点会通过节点链表链接上新节点。直到所有的数据都插入到FP树后,FP树的建立完成。
4)从项头表的底部项依次向上找到项头表项对应的条件模式基。从条件模式基递归挖掘得到项头表项项的频繁项集(可以参见第4节对F的条件模式基的频繁二项集到频繁5五项集的挖掘)。
5)如果不限制频繁项集的项数,则返回步骤4所有的频繁项集,否则只返回满足项数要求的频繁项集。



![2023年中国自动排气阀产业链、市场规模及存在问题分析]图[](https://img-blog.csdnimg.cn/img_convert/9cc8e72252ce081b74d8f2af16c45015.png)