一、3D中国地图
1. 一定要使用 echarts 5.0及以上的版本;
2. echarts 5.0没有内置中国地图了。点击下载 china.json;
3. 一共使用了四层地图。
(1)第一层是中国地图各省细边框和展示南海诸岛;
(2)第二层是实现中国地图外边框的宽度和阴影,与第一层完全重合,隐藏南海诸岛;
(3)第三层和第四层形成一个底层3d立体,使用top往下偏移,隐藏南海诸岛。
// html
<div class="china-map" ref="chinaMap"></div>
// 引入资源
import * as echarts from 'echarts'
import china from '@/assets/json/china.json'
// 方法
chinaEchart(){
//注册地图,这个特别重要
echarts.registerMap('china', china)
let myChart = echarts.init(this.$refs.chinaMap);
//echart 配制option
var options= {
tooltip: {
show:true,
triggerOn: "mousemove", //mousemove、click
padding:[4,8],
borderWidth:1,
borderColor:'#409eff',
backgroundColor:'rgba(255,255,255,0.7)',
textStyle:{
color:'#000000',
fontSize:13
},
formatter: function(e) {
return e.name;
}
},
geo: [
// 第一层
{
map: "china",
z: 3,
zoom: 1.2,
aspectScale: 0.85,
roam: false,
top: '10%',
layoutSize: "100%", //保持地图宽高比
regions: [
{ // 隐藏南海诸岛,因为顶层已经添加过了
name: '南海诸岛',
itemStyle: {
borderWidth: 0.5,
shadowBlur: 0,
borderColor: '#61aacb',
areaColor: '#104584'
}
}
],
itemStyle:{
borderColor: '#c8feff',
borderWidth: 0.5,
shadowBlur: 3,
shadowColor: '#66edff',
areaColor: '#0862db'
},
emphasis:{
itemStyle:{
shadowBlur: 10,
borderWidth: 1,
areaColor: '#2da9ff',
},
label:{
show:false,
color: '#ffffff',
}
},
select:{
itemStyle:{
shadowBlur: 10,
borderWidth: 1,
areaColor: '#2da9ff',
},
label:{
color: '#ffffff',
}
}
},
// 第二层
{
map: "china",
z: 2,
zoom: 1.2,
aspectScale: 0.85,
roam: false,
silent:true,
top: '10%',
layoutSize: "100%", //保持地图宽高比
regions: [
{ // 隐藏南海诸岛,因为顶层已经添加过了
name: '南海诸岛',
itemStyle: {
opacity: 0 // 为 0 时不绘制该图形
},
label: {
show: false
}
}
],
itemStyle:{
borderColor: '#d8feff',
borderWidth: 3,
shadowBlur: 10,
shadowColor: '#22a1ff',
areaColor: '#0862db',
shadowOffsetX: 0,
shadowOffsetY: 8
},
},
// 第三层
{
map: "china",
z: 1,
zoom: 1.2,
aspectScale: 0.85,
top: '11.5%',
silent:true,
layoutSize: "100%", //保持地图宽高比
itemStyle:{
borderColor: '#c8feff',
borderWidth: 1,
shadowBlur: 0,
shadowColor: '#99c4ff',
areaColor: '#4ebaff',
},
regions: [
{ // 隐藏南海诸岛,因为顶层已经添加过了
name: '南海诸岛',
itemStyle: {
opacity: 0 // 为 0 时不绘制该图形
},
label: {
show: false
}
}
],
},
// 第四层
{
map: "china",
z: 0,
zoom: 1.2,
aspectScale: 0.85,
top: '12%',
silent:true,
layoutSize: "100%", //保持地图宽高比
itemStyle:{
borderColor: '#66edff',
borderWidth: 2,
shadowBlur: 20,
shadowColor: '#4d99ff',
areaColor: '#1752ad',
shadowOffsetX: 0,
shadowOffsetY: 8
},
regions: [
{ // 隐藏南海诸岛,因为顶层已经添加过了
name: '南海诸岛',
itemStyle: {
opacity: 0 // 为 0 时不绘制该图形
},
label: {
show: false
}
}
],
},
],
series: [
// 地图
{
type: "map",
geoIndex: 0,
data: []
}
]
}
myChart.setOption(options);
}
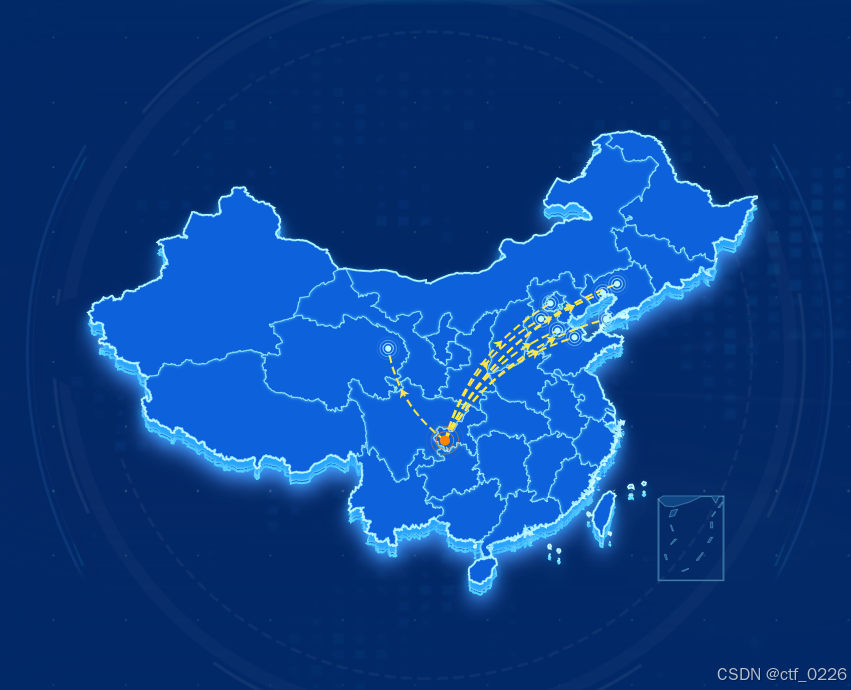
二、地图飞线
1. 飞线有一对多,多对多;
2. 起点和终点使用effectScatter标点。
// 起点名称和经纬度
const fromName = '重庆市'
const fromLatlng = [106.33,29.35]
// 终点名称和经纬度
const geoCoordMap = [
{ name: '盘锦市', latlng: [120.93141287481329, 40.93448132827849]},
{ name: '沧州市', latlng: [116.71809759843096, 37.96769678343516]},
{ name: '东营市', latlng: [118.29234782217573, 37.44294670885357]},
{ name: '大连市', latlng: [121.26593157813807, 38.886009413952934]},
{ name: '沈阳市', latlng: [122.220947193165, 41.64094730550629]},
{ name: '北京市', latlng: [116.07673639616456, 40.110426254643315]},
{ name: '白银市', latlng: [101.09220648866805, 36.568363251217576]},
{ name: '石家庄市', latlng: [115.20215293852858, 38.886009413952934]}
]
//飞线数据
const linesData = geoCoordMap.map(row=>{
return {
coords: [
fromLatlng,
row.latlng
],
fromName: fromName,
toName: row.name,
lineStyle: {
color: '#FFE747',
curveness: 0.2
}
}
})
// 终点标点数据
let effectData = geoCoordMap.map(row=>{
return {
value: row.latlng,
name: row.name,
lineStyle: {
color: '#FFE747'
}
}
})
// series新增飞线
series: [
// 飞线
{
type: 'lines',
zlevel: 5,
effect: {
show: true,
period: 5, //箭头指向速度,值越小速度越快
trailLength: 0, //特效尾迹长度[0,1]值越大,尾迹越长重
symbol: 'arrow', //ECharts 提供的标记类型包括 'circle', 'rect', 'roundRect', 'triangle', 'diamond', 'pin', 'arrow'
symbolSize: 8, //图标大小
},
lineStyle: {
color: '#FFE747',
type: 'dashed',
width: 2, //尾迹线条宽度
opacity: 1, //尾迹线条透明度
curveness: 0.3 //尾迹线条曲直度
},
data: linesData,
markPoint:{
symbol: 'circle', //ECharts 提供的标记类型包括 'circle', 'rect', 'roundRect', 'triangle', 'diamond', 'pin', 'arrow'
symbolSize: 8, //图标大小
}
},
//起点
{
type: 'effectScatter',
coordinateSystem: 'geo',
zlevel: 6,
rippleEffect: {
//涟漪特效
period: 4, //动画时间,值越小速度越快
brushType: 'stroke', //波纹绘制方式 stroke, fill
scale: 4 //波纹圆环最大限制,值越大波纹越大
},
label: {
show: false,
position: 'right', //显示位置
offset: [5, 0], //偏移设置
formatter: '{b}', //圆环显示文字
color: 'red'
},
symbol: 'circle',
symbolSize: function(val) {
return 10; //圆环大小
},
itemStyle: {
show: false,
color: '#ff8400',
},
data: [{value: fromLatlng,name: fromName}]
},
// 终点
{
type: 'effectScatter',
coordinateSystem: 'geo',
zlevel: 6,
rippleEffect: {
//涟漪特效
period: 4, //动画时间,值越小速度越快
brushType: 'stroke', //波纹绘制方式 stroke, fill
scale: 4 //波纹圆环最大限制,值越大波纹越大
},
label: {
show: false,
position: 'right', //显示位置
offset: [5, 0], //偏移设置
formatter: '{b}', //圆环显示文字
color: 'red'
},
symbol: 'circle',
symbolSize: function(val) {
return 6; //圆环大小
},
itemStyle: {
show: false,
color: '#befaff',
},
data: effectData
}]

![[AI]Mac本地部署Deepseek R1模型 — — 保姆级教程](https://i-blog.csdnimg.cn/direct/e27f966317884800befe62c3622dd29f.png)















![[MySQL]5-MySQL扩展(分片)](https://i-blog.csdnimg.cn/direct/301565fac552457fb599b7c79e07db10.png)

