文章目录
- 集成学习
- Boosting
- AdaBoost
- 梯度提升树GBDT
- XGBoost
- xgboost库
- sklearn API
- xgboost库
- xgboost应用
集成学习
集成学习(ensemble learning)的算法主要包括三大类:装袋法(Bagging),提升法(Boosting)和stacking。
在博客【机器学习】集成学习(以随机森林为例)里面主要写到了什么是集成学习,以及以随机森林为代表的bagging算法,感兴趣的可以事先阅读一下。
本文主要集中在集成学习Boosting算法思想,包括Adaboost、梯度提升树和XGboost算法。
Boosting
Boosting 的过程很类似于人类学习的过程,我们学习新知识的过程往往是迭代式的,第一遍学习的时候,我们会记住一部分知识,但往往也会犯一些错误,对于这些错误,我们的印象会很深。第二遍学习的时候,就会针对犯过错误的知识加强学习,以减少类似的错误发生。不断循环往复,直到犯错误的次数减少到很低的程度 。
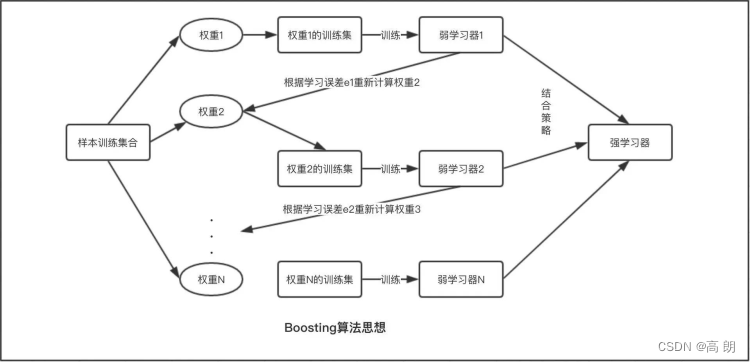 Boosting算法的工作机制:
Boosting算法的工作机制:
首先从训练集用初始权重训练出一个弱学习器1,根据弱学习的学习误差率表现来更新训练样本的权重,使得之前弱学习器1学习误差率高的训练样本点的权重变高,使得这些误差率高的点在后面的弱学习器2中得到更多的重视。
然后基于调整权重后的训练集来训练弱学习器2.,如此重复进行,直到弱学习器数达到事先指定的数目N,最终将这N个弱学习器通过集合策略进行整合,得到最终的强学习器。
Boosting的重点在于取新模型之长补旧模型之短来降低偏差(bias),尽可能获得无偏估计。
AdaBoost
AdaBoost是Adaptive Boosting的缩写,即自适应提升法。
算法步骤:
Step1: Initialise the dataset and assign equal weight to each of the data point.
Step2: Provide this as input to the model and identify the wrongly classified data points.
Step3: Increase the weight of the wrongly classified data points.
Step4: if (got required results)Goto step 5elseGoto step 2
Step5: End
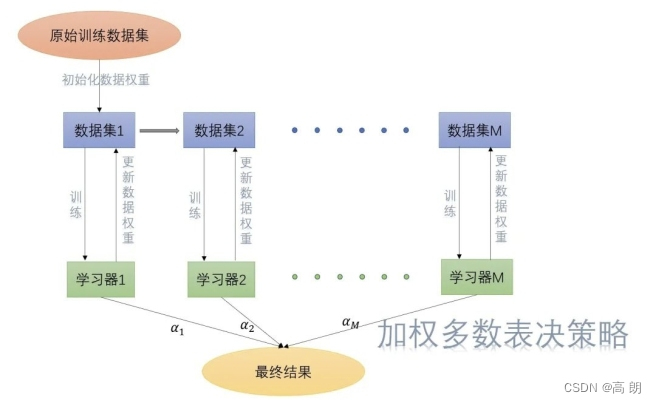
初始的时候,赋予每个训练样本相同的权重;然后每次迭代后,增加分类错误样本的权重(数据集还是原来的数据集,只不过各个样本的权重变了),使得下一轮迭代时更加关注这些样本。
最终,我们需要将这些基础学习器集成在一起,自然就是哪个学习器学习性能好,哪一个系数大一些啦。这里的学习性能就要通过误分类率来评定了,误分类率小的学习器我们就用的多一些,误分类率大的学习器我们就少用一些,这就是加权多数表决策略,最后得到最终学习器。
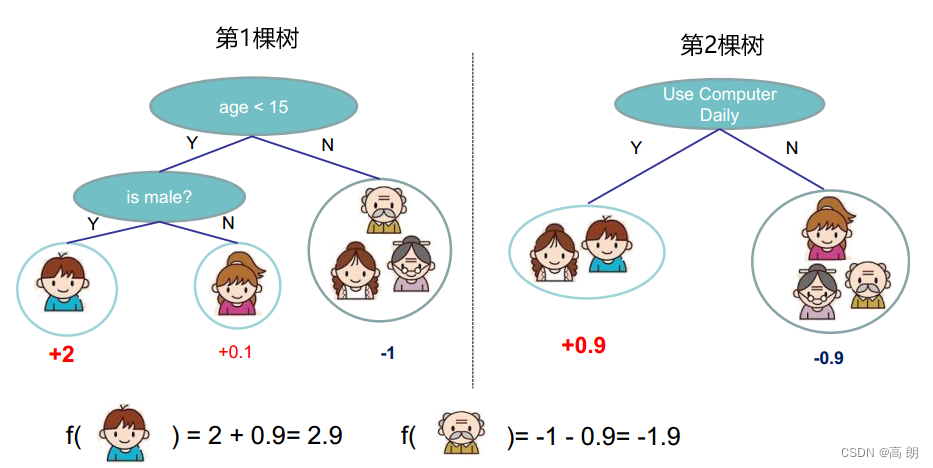
AdaBoost一般选用决策树桩(decision stump)作为弱学习器。所谓stump是指由一个决策节点和两个叶子节点组成的二叉树:
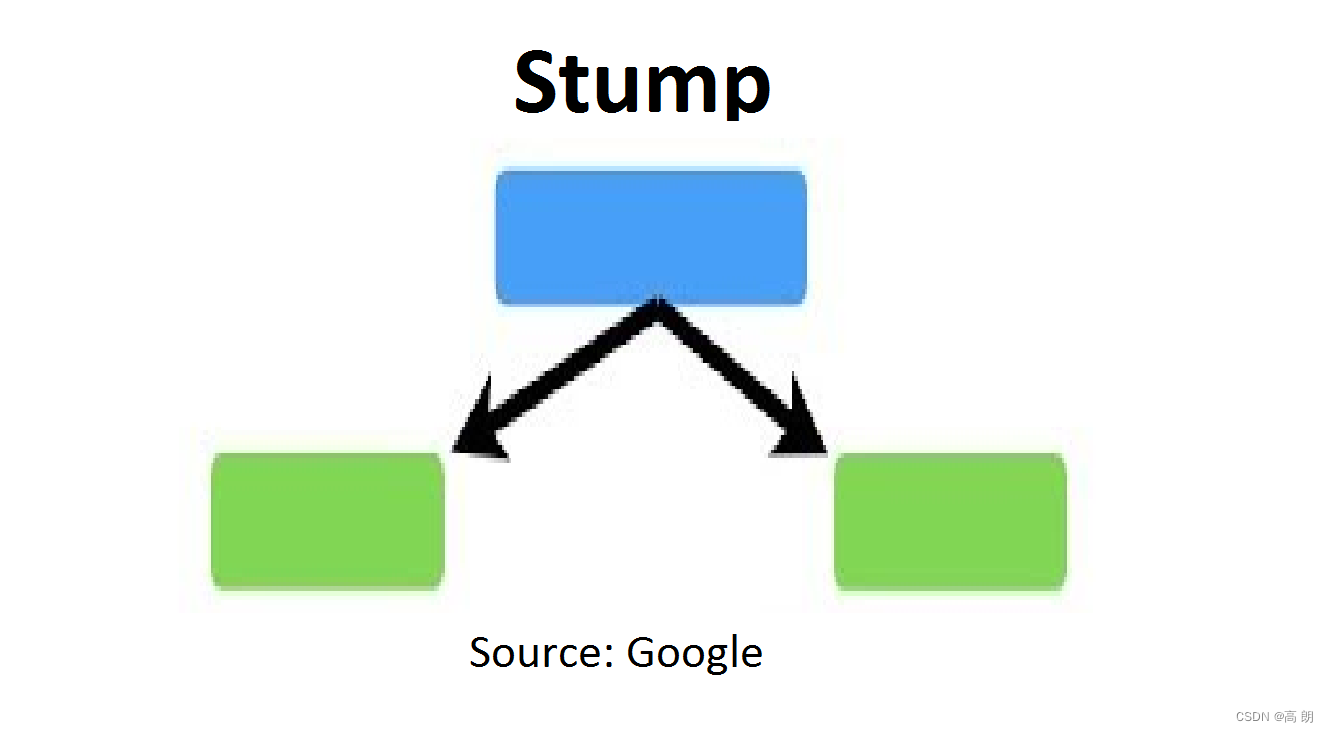 树桩可以理解为在某一处“划一刀”,左边为一类,右边为一类,可以看下面那个例子。
树桩可以理解为在某一处“划一刀”,左边为一类,右边为一类,可以看下面那个例子。
以二分类问题的学习过程示例,包含了三轮迭代:
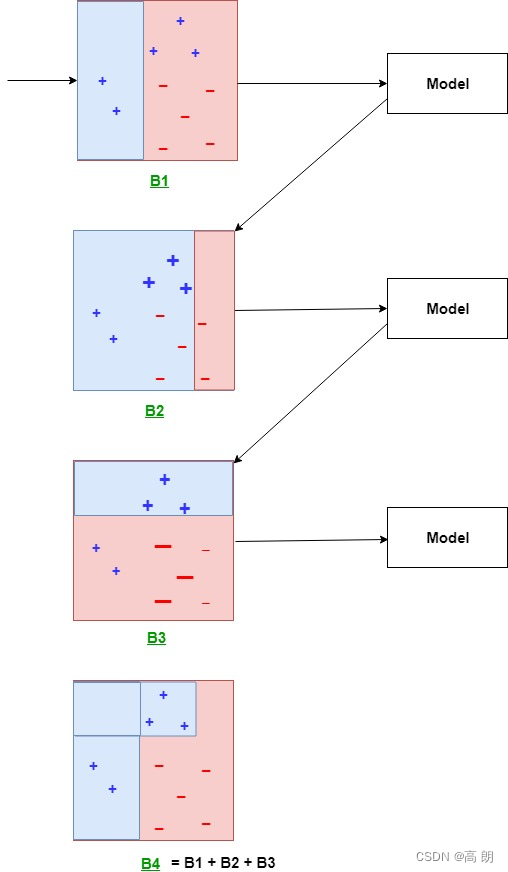
具体算法描述及示例:

-
输入: 训练集数据集 ( x 1 , y 1 ) , . . . , ( x m , y m ) (x_1,y_1),...,(x_m,y_m) (x1,y1),...,(xm,ym),共m个样本, x i x_i xi属性, y i y_i yi标签,取值是-1或+1.
-
初始化: D i = 1 / m D_i=1/m Di=1/m,初始状态所有样本的权重相同, D i D_i Di表示第 i i i个样本的权重。
-
迭代循环:
1)使用权值分布为 D t D_t Dt的数据集,训练得到一个弱分类器 h t h_t ht.
2)计算 h t h_t ht在训练数据上面的误差 ε t ε_t εt.
3)根据训练误差 ε t ε_t εt计算出权重调整系数 α t α_t αt.
4)更新所有训练样本的权重,用于下一次迭代.
5)当训练误差比较低(比如错误率为0)或者弱分类器数目达到预先的设置值(超参控制),就停止循环 -
最终的分类器就是各个各个弱分类器的加权求和,如果是分类问题,就再加上符号函数
sign(输入数据大于0,输出1;等于0,输出0;小于0,输出-1) .
训练误差 ε t ε_t εt: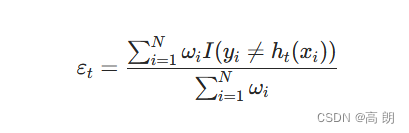
其中 I ( y i ≠ h t ( x i ) I(y_i\neq h_t(x_i) I(yi=ht(xi))的含义是如果 y i ≠ h t ( x i ) y_i\neq h_t(x_i) yi=ht(xi) 成立,则返回1,否则返回0。
权重一般是做过归一化的,所以分母里面的所有权重之和其实为1;而且分子中分类正确的样本的 I I I值为0,也就是上面的公式可以简化为:
 调整系数 α t α_t αt:
调整系数 α t α_t αt:
α t = 1 2 ln 1 − ε t ε t α_t = \frac{1}{2} \ln \frac{1-ε_t}{ε_t} αt=21lnεt1−εt
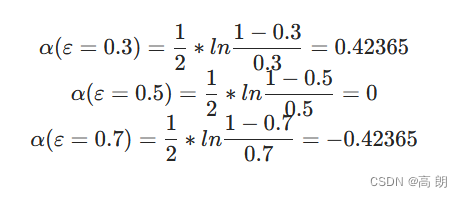
当弱分类器的准确率为0.5时,其权重为0;准确率大于0.5(即错误率小于0.5)时,权重大于0;准确率小于0.5(即错误率大于0.5)时,权重小于0。错误率 ε ε ε越小, α α α越大,即当前模型的表现越好,在最终的生成器中占的权重就越大。
样本权重更新:
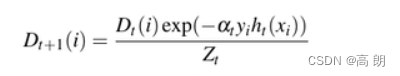
分析:
 当弱分类器在某个样本上分类正确的时候,该样本的权重会降低;否则就会提升,符合理论预期。
当弱分类器在某个样本上分类正确的时候,该样本的权重会降低;否则就会提升,符合理论预期。
增加了预测错误的样本的权重是为了在下一轮迭代中更关注他们,主要有两种方式来实现:
1)N个样本的数据集,每一轮选择本轮使用的m(m < N)个,根据权重随机采样,这样权重大的样本就更容易被选中,甚至选中多次了。
2)原来有N个样本,每次选N个样本进行弱学习器的训练。第一轮大家权重一样,第二轮的时候,根据权重先将原数据集划分“Bucket”,权重高的样本会占据多个bucket。每个bucket被选中的几率是一样的,所以权重高的样本就可能被多选几次。
每轮迭代改变了样本的权重后,对下一轮的影响是体现在挑选数据集的时候。当数据集选好后,这些数据集又会被赋予相同的权重,开始新一轮的迭代。后续不断按此方式迭代,直到错误率降到某个阈值或者达到预设的迭代次数。
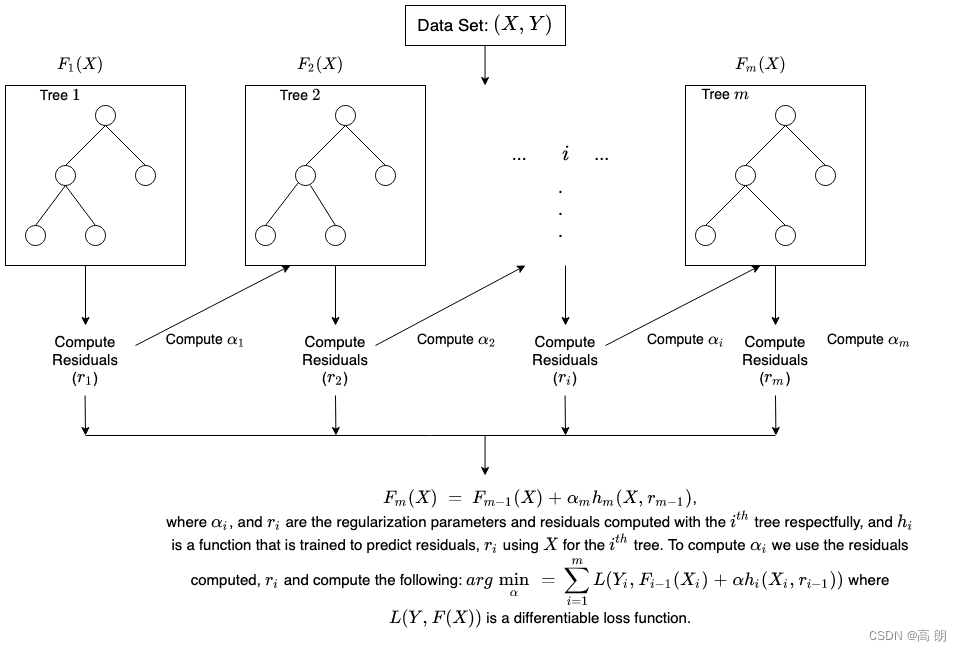
梯度提升树GBDT
Adaboost,是利用前一轮迭代弱学习器的误差率来更新训练集的权重,这样一轮轮的迭代下去。GBDT也是迭代,使用了前向分布算法,但是弱学习器限定了只能使用CART回归树模型,同时迭代思路和Adaboost也有所不同。
GB里面的重点在于每次迭代的时候是拟合残差。所谓残差residual就是真实值和预测值的差值: r e s i d u a l i = y i − f ( x i ) residual_i=y_i−f(xi_) residuali=yi−f(xi),它表示了数据模型中所不可能刻画的部分。所以GB的思想大致可以描述如下:
1)初始:先有一个初始的弱学习器,然后用这个学习器去训练样本上面进行预测,得到每个样本的残差。
2)第一轮:用训练样本作为属性,第一轮得到的残差作为target(而不是原始样本的target),训练得到第2个弱学习器。然后用这个弱学习器对样本进行预测得到预测值,并计算与真实值的残差,作为一下轮样本的target。
3)第N轮:重复前面的步骤。每次变化的是使用上一轮计算的残差作为本轮样本的target。
4)N次迭代后得到最终的强学习器。
弱学习器CART回归树模型是回归模型的,我们一般使用均方误差作为损失函数,即
L ( θ ) = 1 2 ∑ i = 0 n ( f ( x i ) − y i ) L(\theta)= \frac{1}{2}\sum_{i=0}^n(f(x_i)-y_i) L(θ)=21i=0∑n(f(xi)−yi)
采用梯度下降方式求解最最佳的模型:
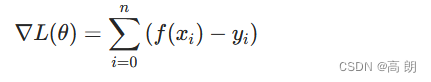
中间的 ( f ( x i ) − y i ) (f(x_i)-y_i) (f(xi)−yi)加个负号就是残差,对残差的拟合,其实就是对负梯度的拟合,根据残差来更新集成后的模型实际就是根据负梯度来更新。
尽管这里残差和负梯度的值完全一样,但二者代表的含义却是不一样的:负梯度指向的是单个模型参数更新的方向,残差(即梯度提升)则表示了集成模型下一个模型的拟合目标。梯度的不断下降可以让模型的参数逐渐收敛到最优参数上,而残差的不断拟合则让集成之后的模型越来越解决真实数据的生成机制。
梯度下降是参数空间的优化:针对单个模型的参数优化,找到最优的一组参数;
梯度提升是函数空间的优化:用多个模型的组合来逼近问题的解,每个模型都是一个函数
可以从损失函数的负梯度角度去构造更丰富的提升方法,即构造更多的损失函数。因为基于残差的损失函数有一个明显的缺点就是对异常值比较敏感。对于异常值后续模型会对这个值关注过多,这样并不好,所以一般回归类的损失函数会使用绝对损失(absolute loss)或者huber损失函数(huber loss) 来代替平方损失函数:
梯度提升中则将权重换成了梯度.
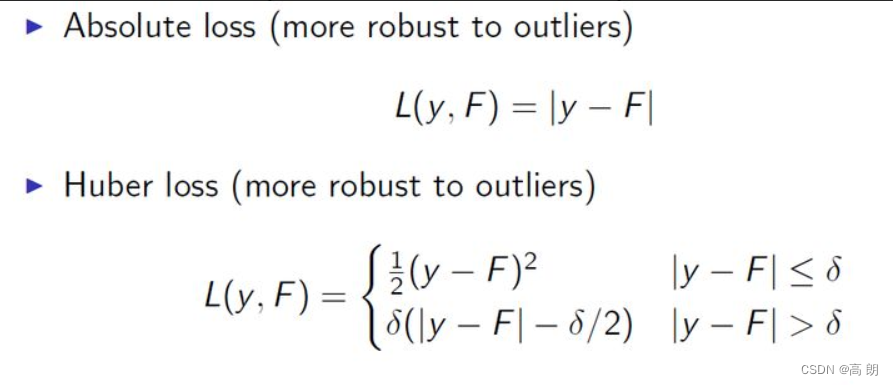
具体算法流程:

 完整的迭代公式:
完整的迭代公式:
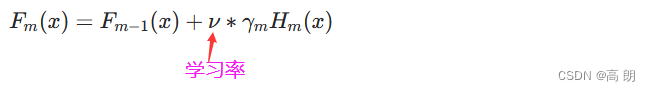
XGBoost
XGBoost(eXtreme Gradient Boosting)是对GBDT的优化和工程化的实现。优化可分为算法优化和工程实现方面的优化:
1.Algorithmic Enhancements: 算法改进
a)Regularization: It penalizes more complex models through both LASSO (L1) and Ridge (L2) regularization to prevent overfitting.
正则化: 它通过 LASSO(L1)和 Ridge(L2)正则化对更复杂的模型进行惩罚,以防止过度拟合。
b)Sparsity Awareness: XGBoost naturally admits sparse features for inputs by automatically ‘learning’ best missing value depending on training loss and handles different types of sparsity patterns in the data more efficiently.
稀疏意识: XGBoost 可根据训练损失自动 "学习 "最佳缺失值,从而自然地接受稀疏特征输入,并更高效地处理数
据中不同类型的稀疏模式。
c)Weighted Quantile Sketch: XGBoost employs the distributed weighted Quantile Sketch algorithm to effectively find the optimal split points among weighted datasets.
加权量子草图: XGBoost 采用分布式加权 Quantile Sketch 算法,能有效地在加权数据集中找到最佳分割点。
d)Cross-validation: The algorithm comes with built-in cross-validation method at each iteration, taking away the need to explicitly program this search and to specify the exact number of boosting iterations required in a single run.
交叉验证: 该算法在每次迭代时都内置了交叉验证方法,因此无需对这一搜索进行明确编程,也无需指定单次运行中
所需的精确提升迭代次数。2.System Optimization: 系统优化
a)Parallelization: XGBoost approaches the process of sequential tree building using parallelized implementation. This is possible due to the interchangeable nature of loops used for building base learners; the outer loop that enumerates the leaf nodes of a tree, and the second inner loop that calculates the features. This nesting of loops limits parallelization because without completing the inner loop (more computationally demanding of the two), the outer loop cannot be started. Therefore, to improve run time, the order of loops is interchanged using initialization through a global scan of all instances and sorting using parallel threads. This switch improves algorithmic performance by offsetting any parallelization overheads in computation.
并行化: XGBoost 采用并行化实现方式来处理顺序树构建过程。之所以能做到这一点,是因为用于构建基础学习器
的循环具有可互换性;外循环用于枚举树的叶节点,第二个内循环用于计算特征。循环的这种嵌套限制了并行化,因
为如果不完成内循环(这两个循环对计算要求更高),就无法启动外循环。因此,为了缩短运行时间,我们通过对所
有实例进行全局扫描和使用并行线程进行排序的初始化方法来交换循环的顺序。这种切换可以抵消计算中的并行化开
销,从而提高算法性能。
b)Tree Pruning: The stopping criterion for tree splitting within GBM framework is greedy in nature and depends on the negative loss criterion at the point of split. XGBoost uses ‘max_depth’ parameter as specified instead of criterion first, and starts pruning trees backward. This ‘depth-first’ approach improves computational performance significantly.
树形修剪: 在 GBM 框架内,树分割的停止准则本质上是贪婪的,取决于分割点的负损失准则。XGBoost 使用指定
的 "max_depth "参数,而不是准则优先,并开始向后修剪树。这种 "深度优先 "的方法大大提高了计算性能。
c)Hardware Optimization: This algorithm has been designed to make efficient use of hardware resources. This is accomplished by cache awareness by allocating internal buffers in each thread to store gradient statistics. Further enhancements such as ‘out-of-core’ computing optimize available disk space while handling big data-frames that do not fit into memory.
硬件优化: 该算法旨在有效利用硬件资源。通过在每个线程中分配内部缓冲区来存储梯度统计数据,从而实现缓存感
知。进一步的增强功能,如 "核外 "计算,可优化可用磁盘空间,同时处理内存中无法容纳的大数据帧。
XGBoost算法主要是对目标函数两个方面的优化:1.加了一个正则项;2.使用泰勒公式展开

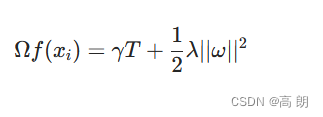
其中 T T T为树f的叶节点个数, ω ω ω为所有叶节点输出回归值构成的向量, γ , λ γ,λ γ,λ为超参数。添加正则项可以防止过拟合、降低方差,获取更好的泛化效果。
泰勒公式:

xgboost库
- 网页文档:xgboost documents
- anaconda安装命令:
pip install xgboost
XGBoost本身的核心是基于梯度提升树实现的集成算法,整体来说可以有三个核心部分:集成算法本身,用于集成的弱评估器,以及应用中的其他过程。三个部分中,前两个部分包含了XGBoost的核心原理以及数学过程,最后的部分主要是在XGBoost应用中占有一席之地。
使用XGboost我们通常有两个库,一个是xgboost库,一个是sklearn里面封装的XGboost类。
使用xgboost中设定的建模流程来建模,和使用sklearnAPI中的类来建模,模型效果是比较相似的,但是xgboost库本身的运算速度(尤其是交叉验证)以及调参手段比sklearn要简单。
XGBoost是基于梯度提升树算法。
集成算法通过在数据上构建多个弱评估器,汇总所有弱评估器的建模结果,以获取比单个模型更好的回归或分类表现。
弱评估器被定义为是表现至少比随机猜测更好的模型,即预测准确率不低于50%的任意模型。
集成不同弱评估器的方法有很多种。
随机森林是一次性建立多个平行独立的弱评估器的装袋法。
提升法是逐一构建弱评估器,经过多次迭代逐渐累积多个弱评估器的方法。提升法的中最著名的算法包括Adaboost和梯度提升树,XGBoost就是由梯度提升树发展而来的。梯度提升树中可以有回归树也可以有分类树,两者都以CART树算法作为主流,XGBoost背后也是CART树,这意味着XGBoost中所有的树都是二叉的。
以梯度提升回归树为例:
梯度提升回归树是专注于回归的树模型的提升集成模型,其建模过程大致如下:最开始先建立一棵树,然后逐渐迭代,每次迭代过程中都增加一棵树,逐渐形成众多树模型集成的强评估器。
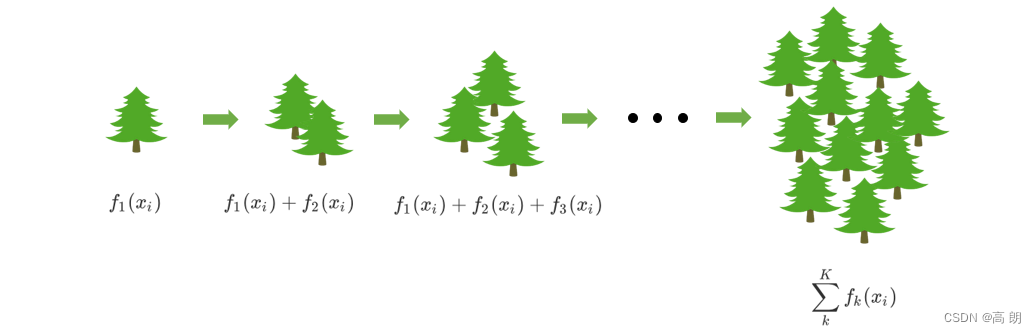
对于决策树而言,每个被放入模型的任意样本 i i i最终一个都会落到一个叶子节点上。而对于回归树,每个叶子节点上的值是这个叶子节点上所有样本的均值。
对于梯度提升回归树来说,每个样本的预测结果可以表示为所有树上的结果的加权求和:
其中, K K K是树的总数量, k k k代表第 k k k棵树, γ k \gamma_k γk 是这棵树的权重, h k h_k hk表示这棵树上的预测结果。

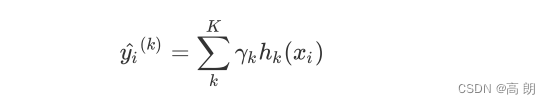
XGB作为GBDT的改进,在预测 y ^ \hat y y^上却有所不同。对于XGB来说,每个叶子节点上会有一个预测分数(prediction score),也被称为叶子权重。这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取值,用 f k ( x i ) f_k(x_i) fk(xi) 或者 w w w来表示,其中 f k f_k fk表示第 k k k棵决策树, x i x_i xi表示样本 i i i对应的特征向量。
当只有一棵树的时候, f 1 ( x i ) f_1(x_i) f1(xi)就是提升集成算法返回的结果,但这个结果往往非常糟糕。当有多棵树的时候,集成模型的回归结果就是所有树的预测分数之和,假设这个集成模型中总共有 K K K棵决策树,则整个模型在这个样本 i i i上给出的预测结果为:
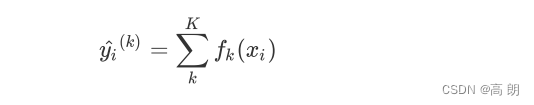
求解预测值 y ^ \hat y y^的方式不同 是XGBosst与GBDT核心区别:
GBDT中预测值是由所有弱分类器上的预测结果的加权求和,其中每个样本上的预测结果就是样本所在的叶子节点的均值。而XGBT中的预测值是所有弱分类器上的叶子权重直接求和得到,计算叶子权重是一个复杂的过程。
在集成中我们需要的考虑的第一件事是我们的超参数K,究竟要建多少棵树

n_estimators越大,模型的学习能力就会越强,模型也越容易过拟合。
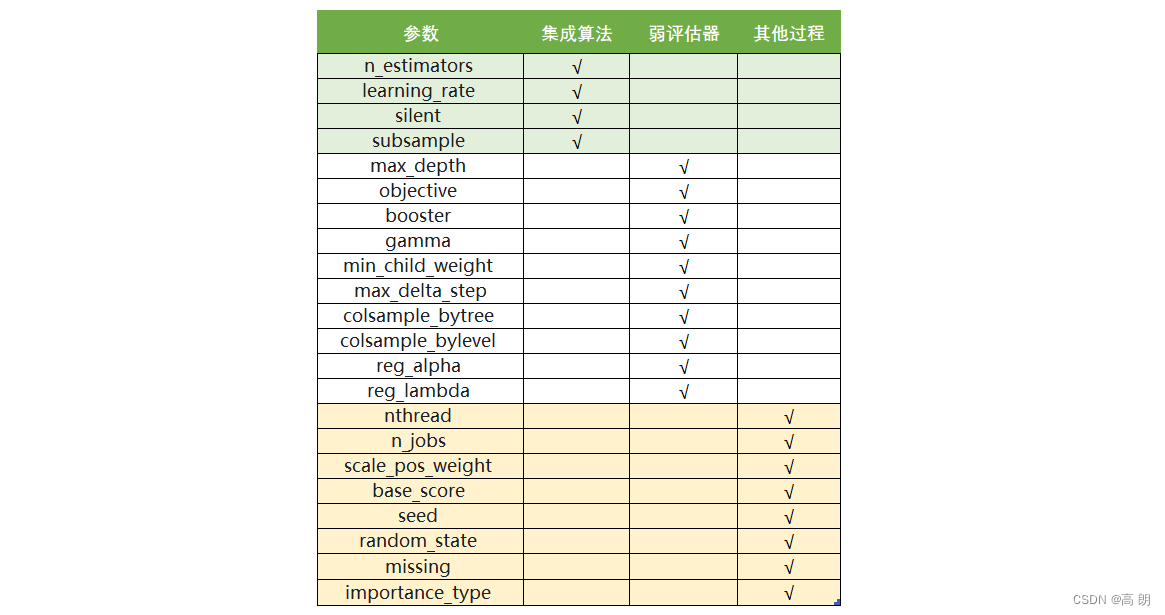
sklearn API
class xgboost.XGBRegressor (
max_depth=3,
learning_rate=0.1,
n_estimators=100,
silent=True,
objective='reg:linear',
booster='gbtree',
n_jobs=1,
nthread=None,
gamma=0,
min_child_weight=1,
max_delta_step=0,
subsample=1,
colsample_bytree=1,
colsample_bylevel=1,
reg_alpha=0,
reg_lambda=1,
scale_pos_weight=1,
base_score=0.5,
random_state=0,
seed=None,
missing=None,
importance_type='gain',
**kwargs)
 导入的库:
导入的库:
from xgboost import XGBRegressor as XGBR # sklearn api
from sklearn.datasets import fetch_california_housing # 加利福尼亚房价数据集
from sklearn.model_selection import KFold, cross_val_score as CVS, train_test_split as TTS #验证
from sklearn.metrics import mean_squared_error as MSE #均差平方和# 常用基础库
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
from time import time
import datetime
数据集处理:
housing_california = fetch_california_housing()
X = housing_california.data # data
y = housing_california.target # label
Xtrain,Xtest,Ytrain,Ytest = TTS(X,y,test_size=0.3,random_state=420)
模型:
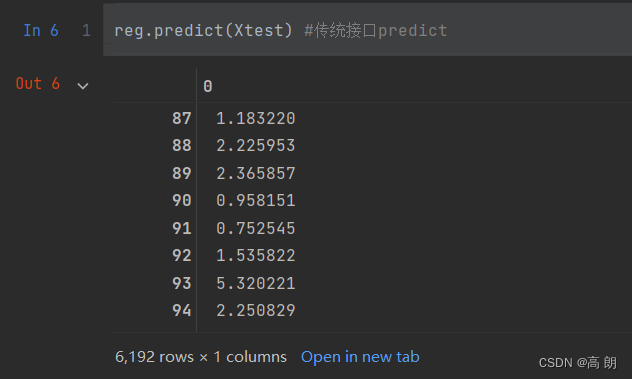
reg = XGBR(n_estimators=100).fit(Xtrain,Ytrain)
reg.predict(Xtest) #传统接口predict 返回预测值
评估:
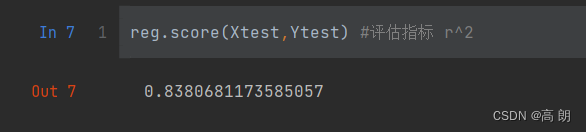
reg.score(Xtest,Ytest) #评估指标 r^2
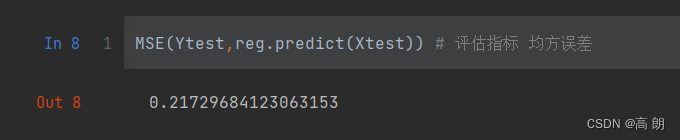
MSE(Ytest,reg.predict(Xtest)) # 评估指标 均方误差
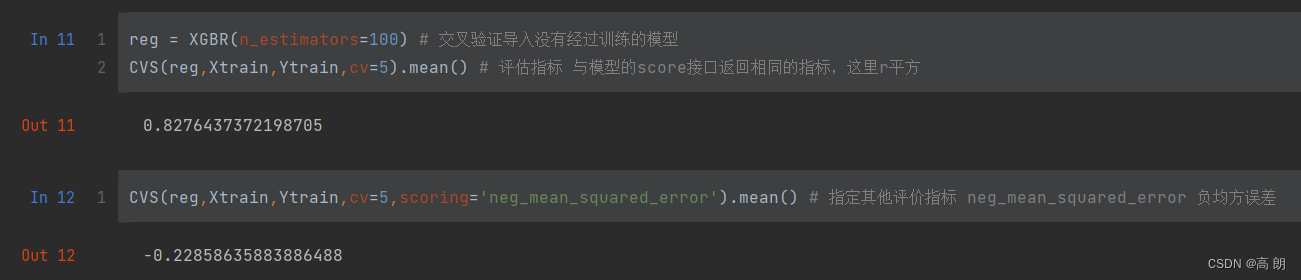
reg = XGBR(n_estimators=100) # 交叉验证导入没有经过训练的模型
CVS(reg,Xtrain,Ytrain,cv=5).mean() # 评估指标 与模型的score接口返回相同的指标,这里r平方
CVS(reg,Xtrain,Ytrain,cv=5,scoring='neg_mean_squared_error').mean() # 指定其他评价指标 neg_mean_squared_error 负均方误差
属性:
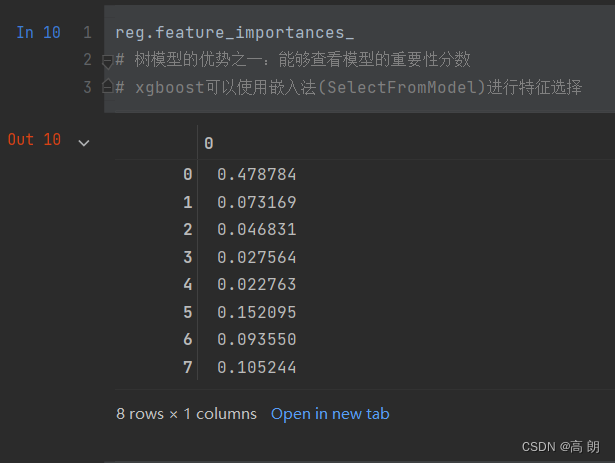
eg.feature_importances_
# 树模型的优势之一:能够查看模型的重要性分数
# xgboost可以使用嵌入法(SelectFromModel)进行特征选择
- 重要参数
n_estimators
画学习曲线来找出最佳的n_estimators参数
(1)定义绘制以训练样本数为横坐标的学习曲线的函数
def plot_learning_curve(estimator, # 模型title, # 图标题X, # 训练集y, # 标签ax=None, #选择子图ylim=None, #设置纵坐标的取值范围cv=None, #交叉验证n_jobs=None #设定索要使用的线程):from sklearn.model_selection import learning_curveimport matplotlib.pyplot as pltimport numpy as nptrain_sizes, train_scores, test_scores = learning_curve(estimator, X, y,shuffle=True,cv=cv,random_state=420,n_jobs=n_jobs)if ax == None:ax = plt.gca()else:ax = plt.figure()ax.set_title(title)if ylim is not None:ax.set_ylim(*ylim)ax.set_xlabel("Training examples")ax.set_ylabel("Score")ax.grid() #绘制网格,不是必须ax.plot(train_sizes, np.mean(train_scores, axis=1), 'o-', color="r",label="Training score")ax.plot(train_sizes, np.mean(test_scores, axis=1), 'o-', color="g",label="Test score")ax.legend(loc="best")return ax
(2)交叉验证画图
cv = KFold(n_splits=5, shuffle = True, random_state=42) # 5折 交叉验证 打乱顺序
plot_learning_curve(XGBR(n_estimators=100,random_state=420),"XGB",Xtrain,Ytrain,ax=None,cv=cv)
plt.show() # 过拟合 训练集表现很好, 测试集不太好
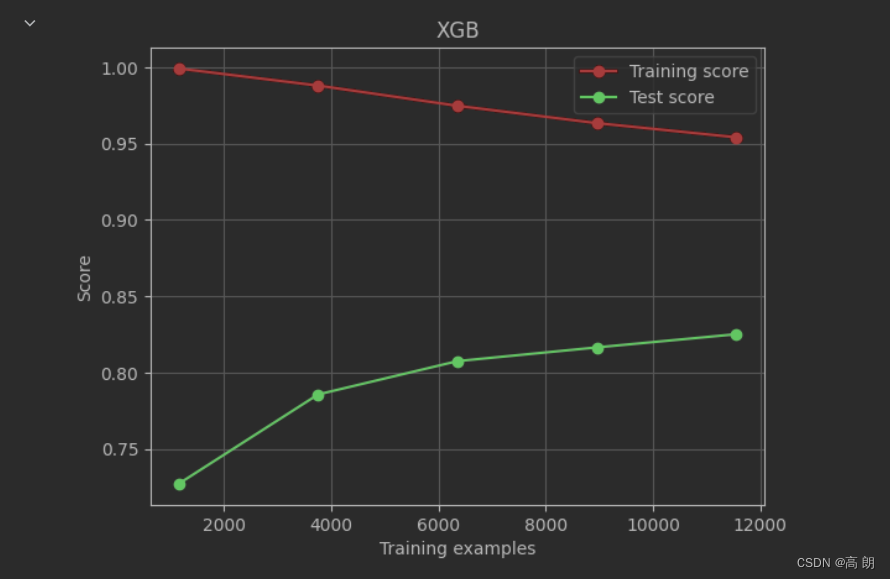 训练集的效果要比测试集好很多,模型过拟合,探讨一下,效果最好的学习曲线是什么样的:
训练集的效果要比测试集好很多,模型过拟合,探讨一下,效果最好的学习曲线是什么样的:
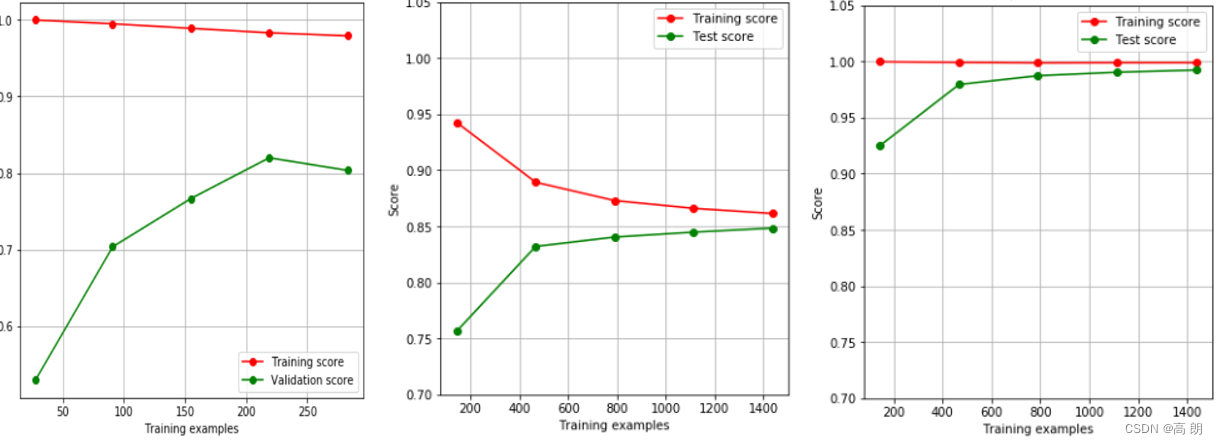 第3个图是最想达到的,但现实数据集很难做到,往往还是通过来降低训练集的效果,提高测试的效果,逼近两者,如图2所示。
第3个图是最想达到的,但现实数据集很难做到,往往还是通过来降低训练集的效果,提高测试的效果,逼近两者,如图2所示。
(3)大范围调参
axisx = range(10,1010,50)
rs = []
for i in axisx:reg = XGBR(n_estimators=i,random_state=420)rs.append(CVS(reg,Xtrain,Ytrain,cv=cv).mean())
print(axisx[rs.index(max(rs))],max(rs))
plt.figure(figsize=(20,5))
plt.plot(axisx,rs,c="red",label="XGB")
plt.legend()
plt.show()
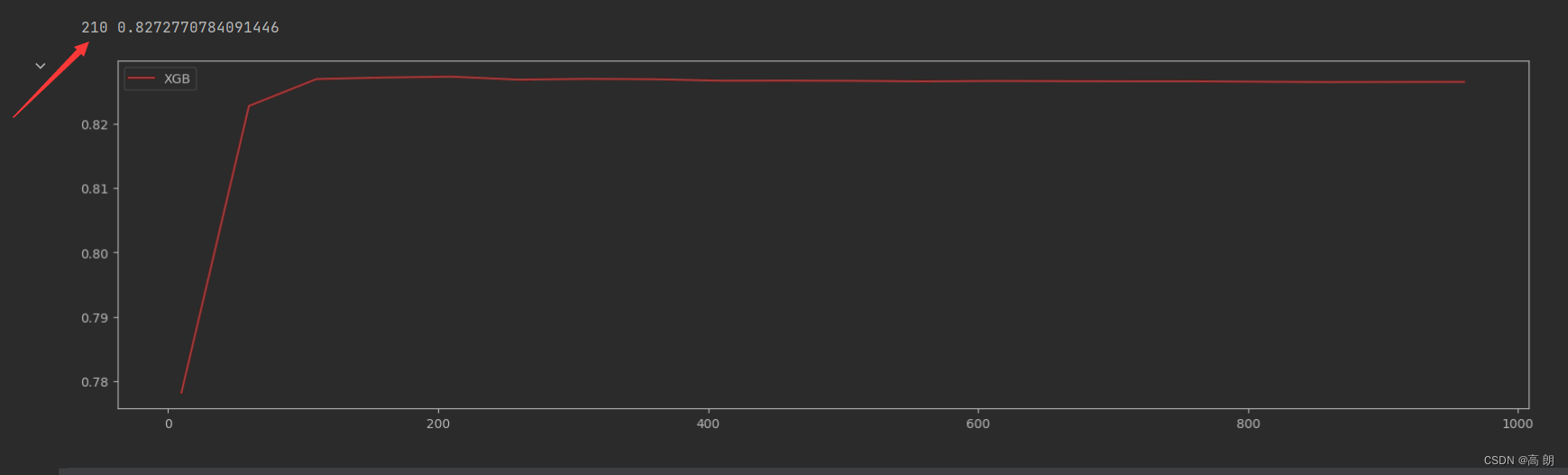 参数应该再210附近,缩小范围,继续调参。
参数应该再210附近,缩小范围,继续调参。
(4)增加考虑因素
在机器学习中,我们用来衡量模型在未知数据上的准确率的指标,叫做泛化误差(Genelization error)。
一个集成模型(f)在未知数据集(D)上的泛化误差 E ( f ; D ) E(f;D) E(f;D),由 方差(var),偏差(bais)和噪声(ε) 共同决定。其中偏差就是训练集上的拟合程度决定,方差是模型的稳定性决定,噪音是不可控的。而泛化误差越小,模型就越理想。
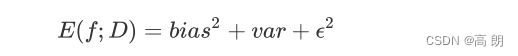
要考虑泛化误差中我们可控的部分:
a)学习曲线获得的分数的最高点,即考虑偏差最小的点.
b)模型会相对不稳定,因此我们应当将方差也纳入考虑的范围.
不仅要考虑偏差的大小,还要考虑方差的大小
axisx = range(50,1050,50)
rs = []
var = []
ge = []
for i in axisx:reg = XGBR(n_estimators=i,random_state=420)cvresult = CVS(reg,Xtrain,Ytrain,cv=cv)#记录1-偏差rs.append(cvresult.mean())#记录方差var.append(cvresult.var())#计算泛化误差的可控部分ge.append((1 - cvresult.mean())**2+cvresult.var())
#打印R2最高所对应的参数取值,并打印这个参数下的方差
print(axisx[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])
#打印方差最低时对应的参数取值,并打印这个参数下的R2
print(axisx[var.index(min(var))],rs[var.index(min(var))],min(var))
#打印泛化误差可控部分的参数取值,并打印这个参数下的R2,方差以及泛化误差的可控部分
print(axisx[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))
plt.figure(figsize=(20,5))
plt.plot(axisx,rs,c="red",label="XGB")
plt.legend()
plt.show()
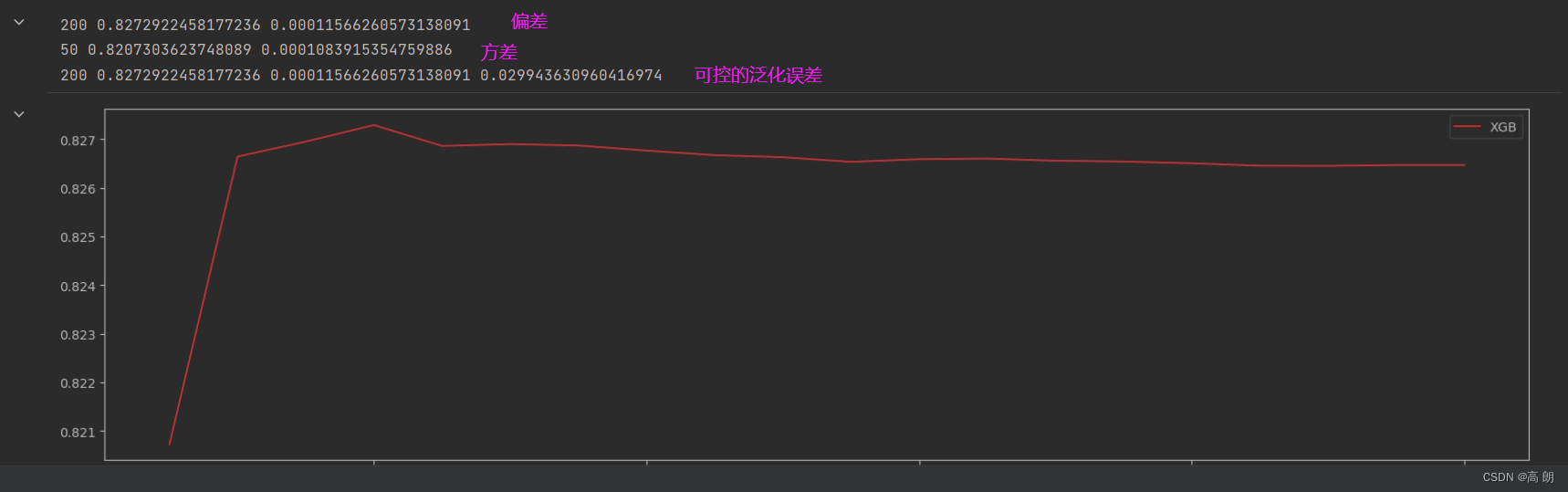 可以看得在200附近,缩小范围,继续调参。【方差非常非常小,其实可以不考虑这个因素】
可以看得在200附近,缩小范围,继续调参。【方差非常非常小,其实可以不考虑这个因素】
【偏差-模型的准确率,方差-模型的稳定性】
(5)缩小范围
axisx = range(100,300,10)
rs = []
var = []
ge = []
for i in axisx:reg = XGBR(n_estimators=i,random_state=420)cvresult = CVS(reg,Xtrain,Ytrain,cv=cv)rs.append(cvresult.mean())var.append(cvresult.var())ge.append((1 - cvresult.mean())**2+cvresult.var())
print(axisx[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])
print(axisx[var.index(min(var))],rs[var.index(min(var))],min(var))
print(axisx[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))
rs = np.array(rs)
var = np.array(var)*0.01
plt.figure(figsize=(20,5))
plt.plot(axisx,rs,c="blue",label="XGB")
#添加方差线
plt.plot(axisx,rs+var,c="red",linestyle='-.')
plt.plot(axisx,rs-var,c="red",linestyle='-.')
plt.legend()
plt.show()
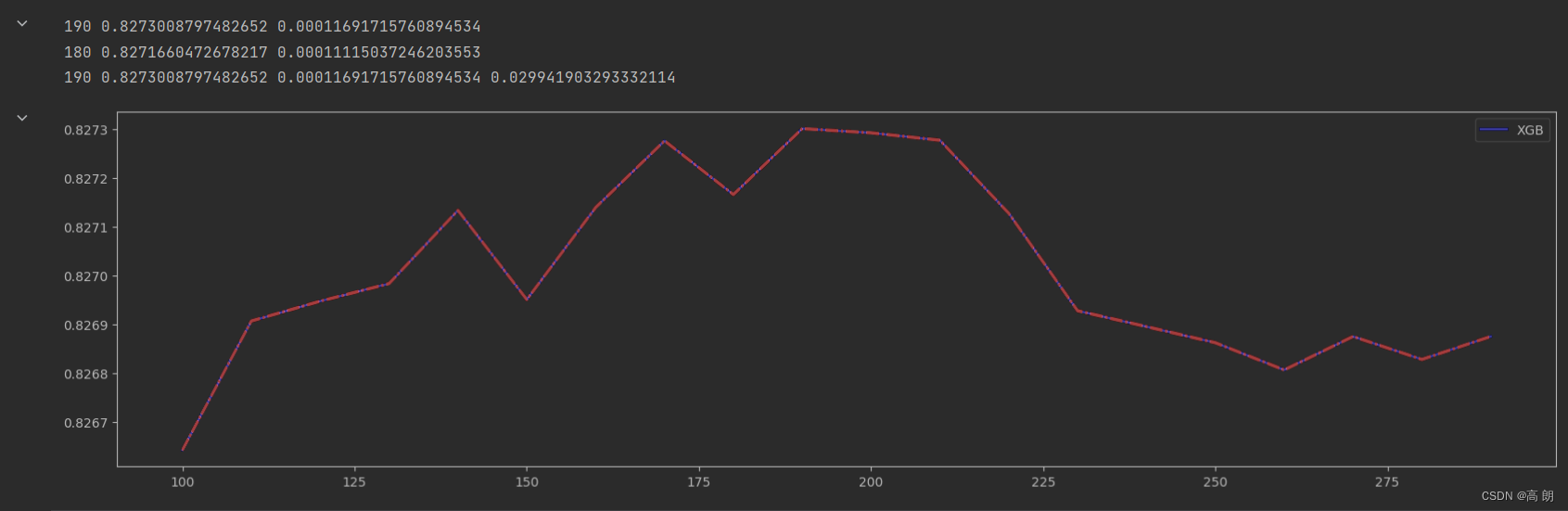 三条线重合,方差真的没什么影响,选定
三条线重合,方差真的没什么影响,选定n_estimators=190
单独查看一下可控误差的曲线图:
#看看泛化误差的可控部分如何?
plt.figure(figsize=(20,5))
plt.plot(axisx,ge,c="gray",linestyle='-.')
plt.show()
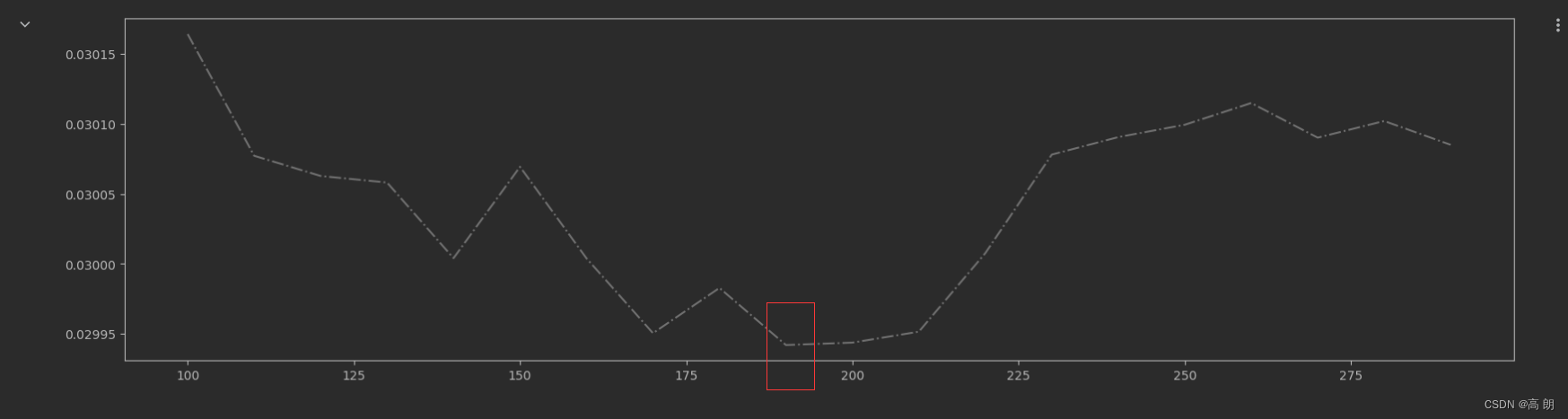 确定190的时候最低
确定190的时候最低
(6)设定调好的参数, 检测模型效果
time0 = time()
print(XGBR(n_estimators=190,random_state=420).fit(Xtrain,Ytrain).score(Xtest,Ytest))
print(time()-time0)
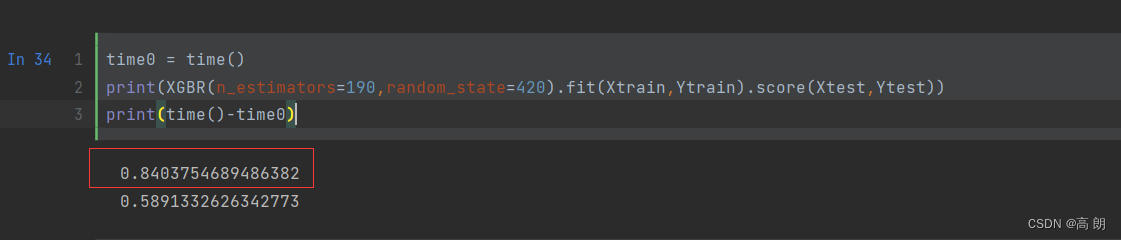 准确率确实提升了。
准确率确实提升了。
(7)总结
a)XGBoost中的树的数量决定了模型的学习能力,树的数量越多,模型的学习能力越强。只要XGB中树的数量足够了,即便只有很少的数据, 模型也能够学到训练数据100%的信息,所以XGB也是天生过拟合的模型。但在这种情况下,模型会变得非常不稳定。
b)XGB中树的数量很少的时候,对模型的影响较大,当树的数量已经很多的时候,对模型的影响比较小,只能有微弱的变化。当数据本身就处于过拟合的时候,再使用过多的树能达到的效果甚微,反而浪费计算资源。当唯一指标或者准确率给出的
n_estimators看起来不太可靠的时候,我们可以改造学习曲线来帮助我们。
c)树的数量提升对模型的影响有极限,最开始,模型的表现会随着XGB的树的数量一起提升,但到达某个点之后,树的数量越多,模型的效果会逐步下降,这也说明了暴力增加
n_estimators不一定有效果。
这些都和随机森林中的参数n_estimators表现出一致的状态。在随机森林中我们总是先调整n_estimators,当n_estimators的极限已达到,我们才考虑其他参数,但XGB中的状况明显更加复杂,当数据集不太寻常的时候会更加复杂。
建议优先调整
n_estimators,一般都不会建议一个太大的数目,300以下为佳。
- 重要参数
subsample【有放回随机抽样】
我们都知道树模型是天生过拟合的模型,并且如果数据量太过巨大,树模型的计算会非常缓慢,因此,我们要对我们的原始数据集进行有放回抽样(bootstrap)。有放回的抽样每次只能抽取一个样本,若我们需要总共N个样本,就需要抽取N次。每次抽取一个样本的过程是独立的,这一次被抽到的样本会被放回数据集中,下一次还可能被抽到,因此抽出的数据集中,可能有一些重复的数据。
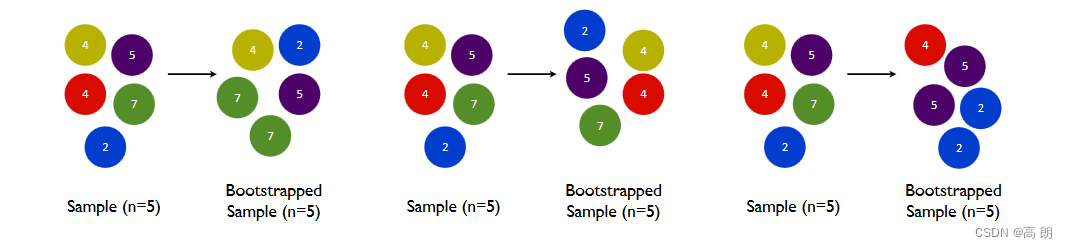
有放回抽样都是我们防止过拟合,让单一弱分类器变得更轻量的必要操作。实际应用中,每次抽取50%左右的数据就能够有不错的效果了。
在梯度提升树中,我们每一次迭代都要建立一棵新的树,因此我们每次迭代中,都要有放回抽取一个新的训练样本。不过,这并不能保证每次建新树后,集成的效果都比之前要好。因此我们规定,在梯度提升树中,每构建一个评估器,都让模型更加集中于数据集中容易被判错的那些样本。来看看下面的这个过程。
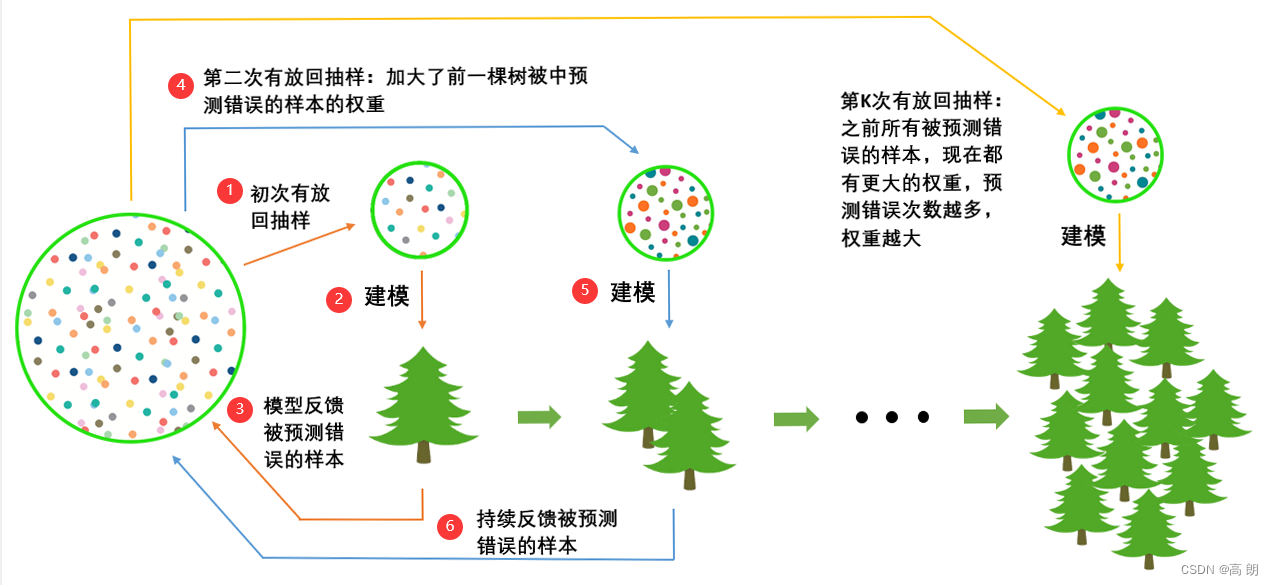 在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二棵决策树,于是开始进行第二次又放回抽样。但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样中,我们加大了被第一棵树判断错误的样本的权重。也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
在建第一棵树时,我们对数据进行初次又放回抽样,然后建模。建模完毕后,我们对模型进行一个评估,然后将模型预测错误的样本反馈给我们的数据集,一次迭代就算完成。紧接着,我们要建立第二棵决策树,于是开始进行第二次又放回抽样。但这次有放回抽样,和初次的随机有放回抽样就不同了,在这次的抽样中,我们加大了被第一棵树判断错误的样本的权重。也就是说,被第一棵树判断错误的样本,更有可能被我们抽中。
基于这个有权重的训练集来建模,我们新建的决策树就会更加倾向于这些权重更大的,很容易被判错的样本。不停的迭代这个过程:
在sklearn中,我们使用参数subsample来控制我们的随机抽样。在xgb和sklearn中,这个参数都默认为1且不能取到0,这说明我们无法控制模型是否进行随机有放回抽样,只能控制抽样抽出来的样本量大概是多少。
| 参数含义 | xgb.train() | xgb.XGBRegressor() |
|---|---|---|
| 随机抽样的时候抽取的样本比例,范围(0,1] | subsample,默认1 | subsample,默认1 |
采样会减少样本数量,而从学习曲线来看样本数量越少模型的过拟合会越严重,因为对模型来说,数据量越少模型学习越容易,学到的规则也会越具体越不适用于测试样本。所以subsample参数通常是在样本量本身很大的时候来调整和使用。
代码测试:
axisx = np.linspace(0,1,20)
rs = []
for i in axisx:reg = XGBR(n_estimators=190,subsample=i,random_state=420)rs.append(CVS(reg,Xtrain,Ytrain,cv=cv).mean())
print(axisx[rs.index(max(rs))],max(rs))
plt.figure(figsize=(20,5))
plt.plot(axisx,rs,c="green",label="XGB")
plt.legend()
plt.show()
 其实添加了这个参数,模型的效果还变差了一点,数据量不多,直接用全部数据,当然还可以细化一下参数再看看:
其实添加了这个参数,模型的效果还变差了一点,数据量不多,直接用全部数据,当然还可以细化一下参数再看看:
#细化学习曲线
axisx = np.linspace(0.05,1,20)
rs = []
var = []
ge = []
for i in axisx:reg = XGBR(n_estimators=190,subsample=i,random_state=420)cvresult = CVS(reg,Xtrain,Ytrain,cv=cv)rs.append(cvresult.mean())var.append(cvresult.var())ge.append((1 - cvresult.mean())**2+cvresult.var())
print(axisx[rs.index(max(rs))],max(rs),var[rs.index(max(rs))])
print(axisx[var.index(min(var))],rs[var.index(min(var))],min(var))
print(axisx[ge.index(min(ge))],rs[ge.index(min(ge))],var[ge.index(min(ge))],min(ge))
rs = np.array(rs)
var = np.array(var)
plt.figure(figsize=(20,5))
plt.plot(axisx,rs,c="black",label="XGB")
plt.plot(axisx,rs+var,c="red",linestyle='-.')
plt.plot(axisx,rs-var,c="red",linestyle='-.')
plt.legend()
plt.show()
 确实是全数据效果好一点。
确实是全数据效果好一点。
- 重要参数
etalearning_rate【迭代决策树】
 在XGB中,我们完整的迭代决策树的公式应该写作:
在XGB中,我们完整的迭代决策树的公式应该写作:

我们让 k k k棵树的集成结果 y ^ i k \hat y^{k}_i y^ik加上我们新建的树上的叶子权重 f k + 1 ( x i ) f_{k+1}(x_i) fk+1(xi),就可以得到第 k + 1 k+1 k+1次迭代后,总共 k + 1 k+1 k+1棵树的预测结果 y ^ i k + 1 \hat y^{k+1}_i y^ik+1了。其中 η \eta η 读作"eta",是迭代决策树时的步长(shrinkage),又叫做学习率(learning rate)。
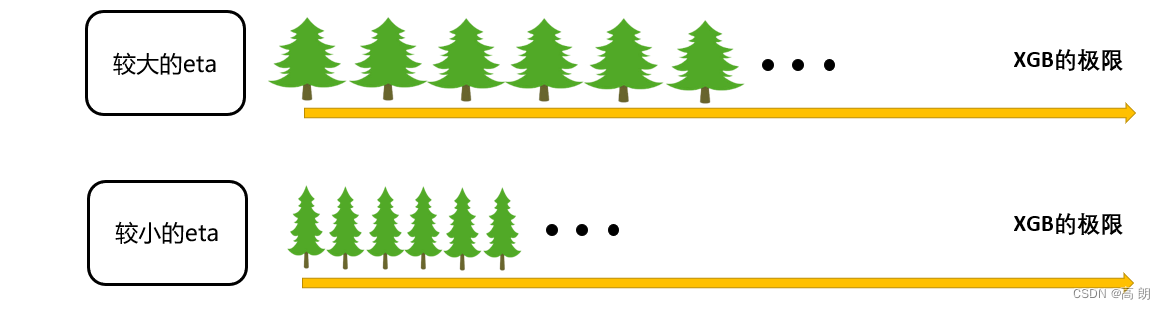 η \eta η越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳。 η \eta η越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢。
η \eta η越大,迭代的速度越快,算法的极限很快被达到,有可能无法收敛到真正的最佳。 η \eta η越小,越有可能找到更精确的最佳值,更多的空间被留给了后面建立的树,但迭代速度会比较缓慢。
sklearn代码:
# 首先我们先来定义一个评分函数,这个评分函数能够帮助我们直接打印Xtrain上的交叉验证结果
def regassess(reg,Xtrain,Ytrain,cv,scoring = ["r2"],show=True):score = []for i in range(len(scoring)):if show:print("{}:{:.2f}".format(scoring[i],CVS(reg,Xtrain,Ytrain,cv=cv,scoring=scoring[i]).mean()))score.append(CVS(reg,Xtrain,Ytrain,cv=cv,scoring=scoring[i]).mean())return score
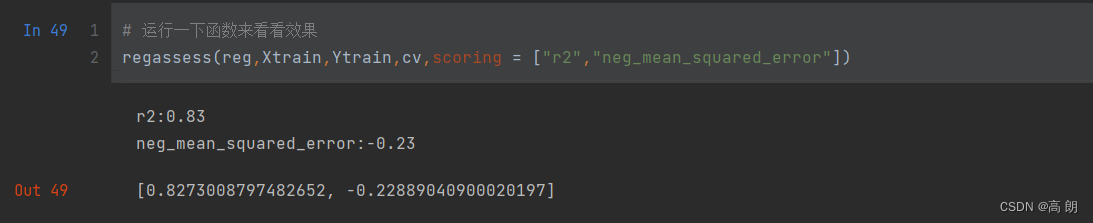
# 运行一下函数来看看效果
regassess(reg,Xtrain,Ytrain,cv,scoring = ["r2","neg_mean_squared_error"])
#关闭打印功能
regassess(reg,Xtrain,Ytrain,cv,scoring = ["r2","neg_mean_squared_error"],show=False)
#观察一下eta如何影响我们的模型:
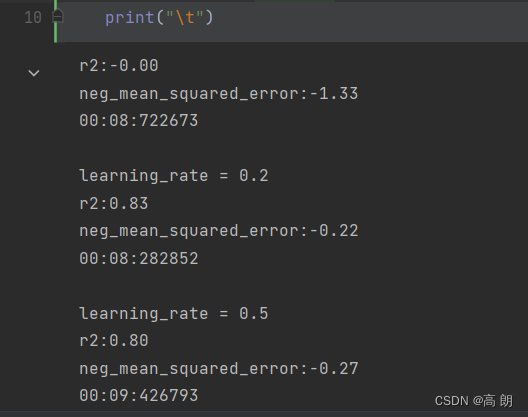
from time import time
import datetime
for i in [0,0.2,0.5,1]:time0=time()reg = XGBR(n_estimators=190,random_state=420,learning_rate=i)print("learning_rate = {}".format(i))regassess(reg,Xtrain,Ytrain,cv,scoring = ["r2","neg_mean_squared_error"])print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))print("\t")
axisx = np.arange(0.05,1,0.05)
rs = []
te = []
for i in axisx:reg = XGBR(n_estimators=190,random_state=420,learning_rate=i)score = regassess(reg,Xtrain,Ytrain,cv,scoring =
["r2","neg_mean_squared_error"],show=False)test = reg.fit(Xtrain,Ytrain).score(Xtest,Ytest)rs.append(score[0])te.append(test)
print(axisx[rs.index(max(rs))],max(rs))
plt.figure(figsize=(20,5))
plt.plot(axisx,te,c="gray",label="XGB")
plt.plot(axisx,rs,c="green",label="XGB")
plt.legend()
plt.show()
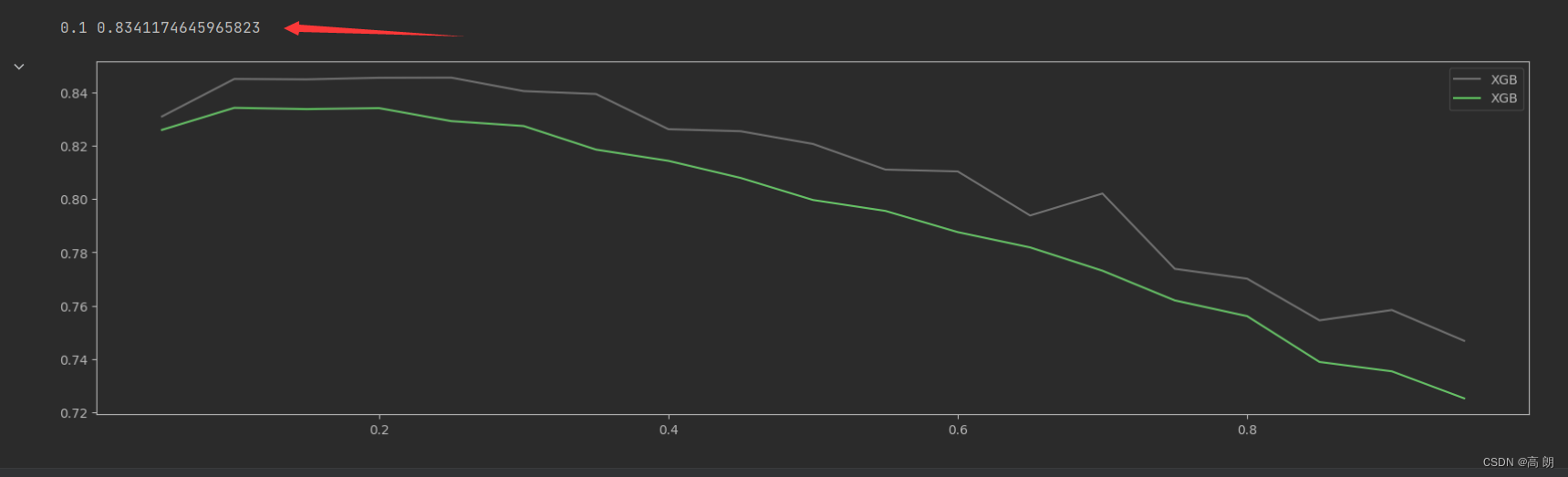
虽然从图上来说,默认的0.1看起来是一个比较理想的情况,并且看起来更小的步长更利于现在的数据,但我们也无法确定对于其他数据会有怎么样的效果。所以通常,我们不调整 η \eta η ,即便调整,一般它也会在[0.01,0.2]之间变动。如果我们希望模型的效果更好,更多的可能是从树本身的角度来说,对树进行剪枝,而不会寄希望于调整 η \eta η。
- 重要参数
booster
梯度提升算法中不只有梯度提升树,XGB作为梯度提升算法的进化,自然也不只有树模型一种弱评估器。在XGB中,除了树模型,我们还可以选用线性模型,比如线性回归,来进行集成。虽然主流的XGB依然是树模型,但我们也可以使用其他的模型。基于XGB的这种性质,我们有参数“booster"来控制我们究竟使用怎样的弱评估器。

for booster in ["gbtree","gblinear","dart"]:reg = XGBR(n_estimators=190,learning_rate=0.1,random_state=420,booster=booster).fit(Xtrain,Ytrain)print(booster)print(reg.score(Xtest,Ytest))
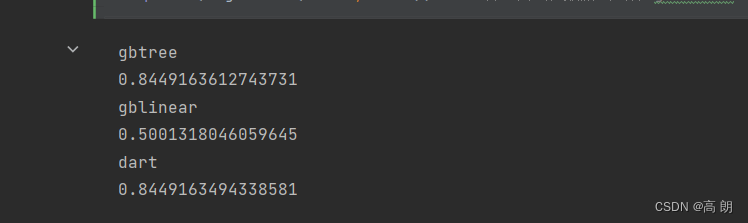
- 重要参数
objective【目标函数】
不同于逻辑回归和SVM等算法中固定的损失函数写法,集成算法中的损失函数是可选的,要选用什么损失函数取决于我们希望解决什么问题,以及希望使用怎样的模型。
如果我们的目标是进行回归预测,那我们可以选择调节后的均方误差RMSE作为我们的损失函数。如果我们是进行分类预测,那我们可以选择错误率error或者对数损失log_loss。只要我们选出的函数是一个可微的,能够代表某种损失的函数,它就可
以是我们XGB中的损失函数。
损失函数的核心是衡量模型的泛化能力,即模型在未知数据上的预测的准确与否。XGB引入了模型复杂度来衡量算法的运算效率。XGB的目标函数被写作:传统损失函数 + 模型复杂度。【XGB的是实现了模型表现和运算速度的平衡的算法。】
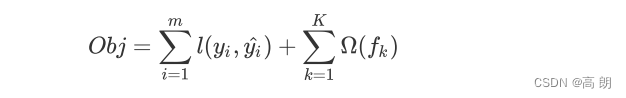 其中 i i i代表数据集中的第 i i i个样本, m m m表示导入第 k k k棵树的数据总量, K K K代表建立的所有树(n_estimators),当只建立了 t t t棵树的时候,式子应当为 ∑ k = 1 t Ω ( f k ) \sum_{k=1}^t \Omega (f_k) ∑k=1tΩ(fk)。第一项代表传统的损失函数,衡量真实标签 y i y_i yi 与预测值 y ^ i \hat y_i y^i之间的差异,通常是RMSE,调节后的均方误差。第二项代表模型的复杂度,使用树模型的某种变换 Ω \Omega Ω 表示,这个变化代表了一个从树的结构来衡量树模型的复杂度的式子,可以有多种定义。注意,我们的第二项中没有特征矩阵 x i x_i xi的介入。我们在迭代每一棵树的过程中,都最小化 O b j Obj Obj来力求获取最优的 y ^ \hat y y^,因此我们同时最小化了模型的错误率和模型的复杂度。
其中 i i i代表数据集中的第 i i i个样本, m m m表示导入第 k k k棵树的数据总量, K K K代表建立的所有树(n_estimators),当只建立了 t t t棵树的时候,式子应当为 ∑ k = 1 t Ω ( f k ) \sum_{k=1}^t \Omega (f_k) ∑k=1tΩ(fk)。第一项代表传统的损失函数,衡量真实标签 y i y_i yi 与预测值 y ^ i \hat y_i y^i之间的差异,通常是RMSE,调节后的均方误差。第二项代表模型的复杂度,使用树模型的某种变换 Ω \Omega Ω 表示,这个变化代表了一个从树的结构来衡量树模型的复杂度的式子,可以有多种定义。注意,我们的第二项中没有特征矩阵 x i x_i xi的介入。我们在迭代每一棵树的过程中,都最小化 O b j Obj Obj来力求获取最优的 y ^ \hat y y^,因此我们同时最小化了模型的错误率和模型的复杂度。
与其他算法一样,我们最小化目标函数以求模型效果最佳,并且我们可以通过限制n_estimators来限制我们的迭代次数,因此我们可以看到生成的每棵树所对应的目标函数取值。目标函数中的第二项看起来是与 棵树都相关,但我们的第一个式子看起来却只和样本量相关,其实不是,第一项传统损失函数也是与已经建好的所有树相关的,相关在这里:
y ^ i ( t ) \hat y^{(t)}_i y^i(t) 中已经包含了所有树的迭代结果,因此整个目标函数都与 棵树相关。
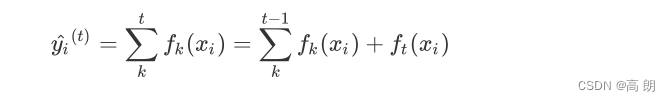
从另一个角度去理解我们的目标函数就是的方差-偏差:
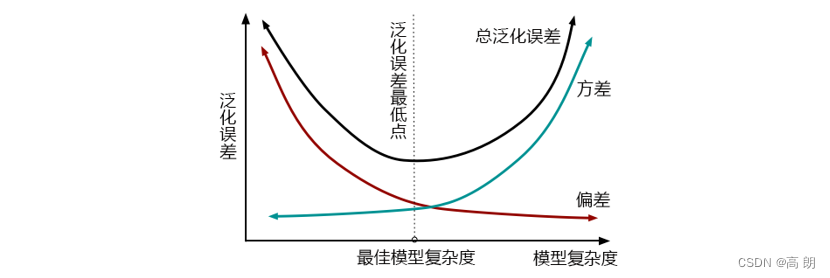 方差和偏差是此消彼长的,并且模型的复杂度越高,方差越大,偏差越小。方差可以被简单地解释为模型在不同数据集上表现出来地稳定性,而偏差是模型预测的准确度。那方差-偏差困境就可以对应到我们的 O b j Obj Obj中了:
方差和偏差是此消彼长的,并且模型的复杂度越高,方差越大,偏差越小。方差可以被简单地解释为模型在不同数据集上表现出来地稳定性,而偏差是模型预测的准确度。那方差-偏差困境就可以对应到我们的 O b j Obj Obj中了:
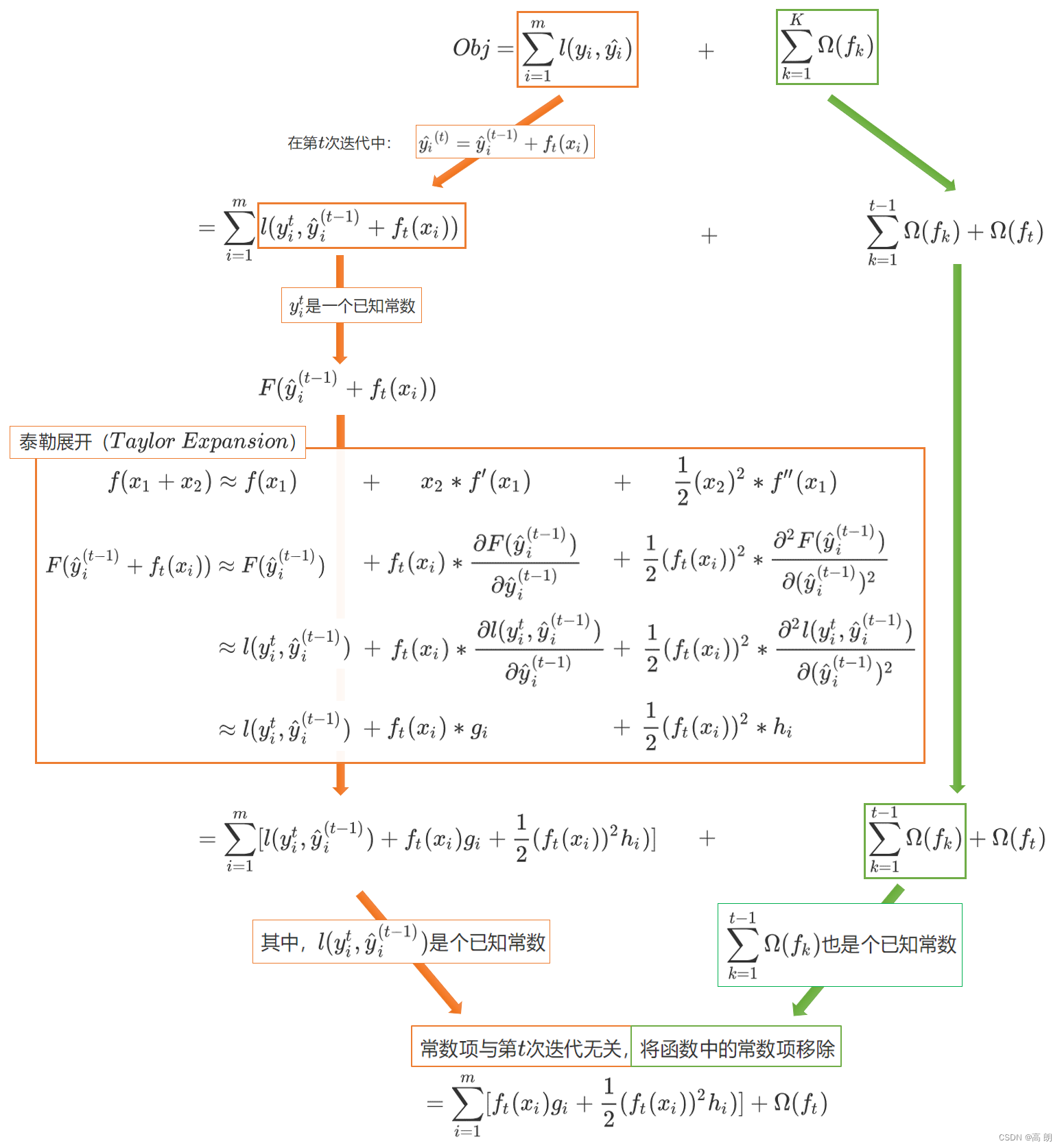
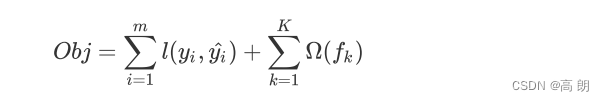 第一项是衡量我们的偏差,模型越不准确,第一项就会越大。第二项是衡量我们的方差,模型越复杂,模型的学习就会越具体,到不同数据集上的表现就会差异巨大,方差就会越大。
第一项是衡量我们的偏差,模型越不准确,第一项就会越大。第二项是衡量我们的方差,模型越复杂,模型的学习就会越具体,到不同数据集上的表现就会差异巨大,方差就会越大。
所以我们求解 O b j Obj Obj的最小值,其实是在求解方差与偏差的平衡点,以求模型的泛化误差最小,运行速度最快。
我们知道树模型和树的集成模型都是学习天才,是天生过拟合的模型,因此大多数树模型最初都会出现在图像的右上方,我们必须通过剪枝来控制模型不要过拟合。现在XGBoost的损失函数中自带限制方差变大的部分,也就是说XGBoost会比其他的树模型更加聪明,不会轻易落到图像的右上方。
在应用中,我们使用参数“objective"来确定我们目标函数的第一部分中的 l ( y i , y ^ i ) l(y_i,\hat y_i) l(yi,y^i),也就是衡量损失的部分。
xgboost库和sklearn API:
| xgb.train() | xgb.XGBRegressor() | xgb.XGBClassifier() |
|---|---|---|
| obj:默认binary:logistic | objective:默认reg:linear | objective:默认binary:logistic |
 还可以选择自定义损失函数。比如说,我们可以选择输入平方损失 l ( y i , y ^ i ) = ( y i − y ^ i ) 2 l(y_i,\hat y_i) = (y_i-\hat y_i)^2 l(yi,y^i)=(yi−y^i)2,此时我们的XGBoost其实就是算法梯度提升机器(gradient boosted machine)。在xgboost中,我们被允许自定义损失函数,但通常我们还是使用类已经为我们设置好的损失函数。我们的回归类中本来使用的就是reg:linear,因此在这里无需做任何调整。注意:分类型的目标函数导入回归类中会直接报错。
还可以选择自定义损失函数。比如说,我们可以选择输入平方损失 l ( y i , y ^ i ) = ( y i − y ^ i ) 2 l(y_i,\hat y_i) = (y_i-\hat y_i)^2 l(yi,y^i)=(yi−y^i)2,此时我们的XGBoost其实就是算法梯度提升机器(gradient boosted machine)。在xgboost中,我们被允许自定义损失函数,但通常我们还是使用类已经为我们设置好的损失函数。我们的回归类中本来使用的就是reg:linear,因此在这里无需做任何调整。注意:分类型的目标函数导入回归类中会直接报错。
xgboost库和sklearn API底层的实现是有差异的,一般来说,xgboost库是要优于sklearn API的,推荐使用xgboost库,上面的直接替换成xgboost需要的参数即可。
xgboost库
建模流程:
 其中最核心的,是
其中最核心的,是DMtarix这个读取数据的类,以及train()这个用于训练的类。
与sklearn把所有的参数都写在类中的方式不同,xgboost库中必须先使用字典设定参数集,再使用train来将参数及输入,然后进行训练。
用字典设定参数集是因为XGB所涉及到的参数实在太多,全部写在xgb.train()中太长也容易出错。
params {eta, gamma, max_depth, min_child_weight, max_delta_step, subsample, colsample_bytree,colsample_bylevel, colsample_bynode, lambda, alpha, tree_method string, sketch_eps, scale_pos_weight, updater,refresh_leaf, process_type, grow_policy, max_leaves, max_bin, predictor, num_parallel_tree}
xgboost.train (params, dtrain, num_boost_round=10, evals=(), obj=None, feval=None, maximize=False,
early_stopping_rounds=None, evals_result=None, verbose_eval=True, xgb_model=None, callbacks=None,learning_rates=None)
大致看一下参数,后面进行详解,其实这些参数只是写法不同,功能与sklearn API是相同的。
简单看一下代码建模流程:
#xgb实现法
import xgboost as xgb
#使用类Dmatrix读取数据
dtrain = xgb.DMatrix(Xtrain,Ytrain) # 特征矩阵和标签
dtest = xgb.DMatrix(Xtest,Ytest)
# 写明参数
param = {'verbosity': 0,'objective':'reg:squarederror',"eta":0.1}
num_round = 190 # n_estimators
#类train,可以直接导入的参数是训练数据,树的数量,其他参数都需要通过params来导入
bst = xgb.train(param, dtrain, num_round)
#predict接口
preds = bst.predict(dtest) #接口predict
from sklearn.metrics import r2_score
r2_score(Ytest,bst.predict(dtest))MSE(Ytest,bst.predict(dtest))
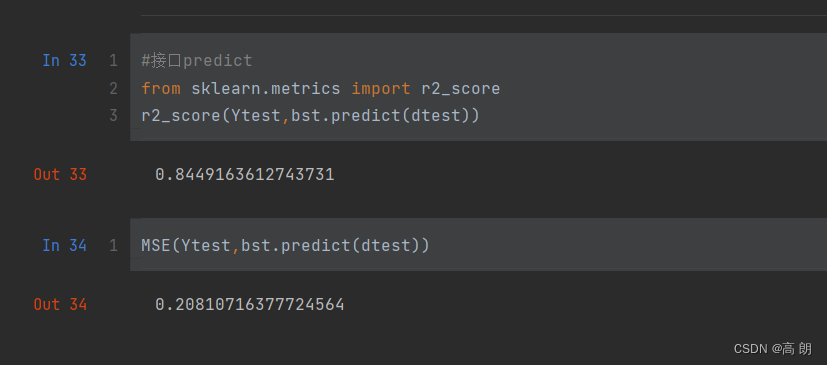 效果是明显比sklearn API要好的。
效果是明显比sklearn API要好的。
怎么去求解XGB的目标函数:
求解目标函数的目的:为了求得在第 t t t次迭代中最优的树 f t f_t ft。
在求解XGB的目标函数的过程中,我们考虑的是如何能够将目标函数转化成更简单的,与树的结构直接相关的写法,以此来建立树的结构与模型的效果(包括泛化能力与运行速度) 之间的直接联系。也因为这种联系的存在,XGB的目标函数又被称为“结构分数”。
第t次迭代的结果是前面t-1次加上第k次的结果:
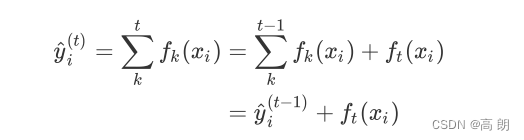 前面已经提到了,xgboost主要优化是:1.添加了正则项。2.泰勒展开。
前面已经提到了,xgboost主要优化是:1.添加了正则项。2.泰勒展开。
 其中 g i g_i gi 和 h i h_i hi分别是在损失函数 l ( y i t , y ^ i ( t − 1 ) ) l(y^t_i,\hat y^{(t-1)}_i) l(yit,y^i(t−1))上对 所求的一阶导数和二阶导数,他们被统称为每个样本的梯度统计量(gradient statisticts)。在许多算法的解法推导中,我们求解导数都是为了让一阶导数等于0来求解极值,而现在我们求解导数只是为了配合泰勒展开中的形式,仅仅是简化公式的目的罢了。所以GBDT和XGB的区别之中,GBDT求一阶导数,XGB求二阶导数,这两个过程根本是不可类比的。XGB在求解极值为目标的求导中也是求解一阶导数。
其中 g i g_i gi 和 h i h_i hi分别是在损失函数 l ( y i t , y ^ i ( t − 1 ) ) l(y^t_i,\hat y^{(t-1)}_i) l(yit,y^i(t−1))上对 所求的一阶导数和二阶导数,他们被统称为每个样本的梯度统计量(gradient statisticts)。在许多算法的解法推导中,我们求解导数都是为了让一阶导数等于0来求解极值,而现在我们求解导数只是为了配合泰勒展开中的形式,仅仅是简化公式的目的罢了。所以GBDT和XGB的区别之中,GBDT求一阶导数,XGB求二阶导数,这两个过程根本是不可类比的。XGB在求解极值为目标的求导中也是求解一阶导数。
关于上面泰勒公式详解:
1)常规泰勒展开:
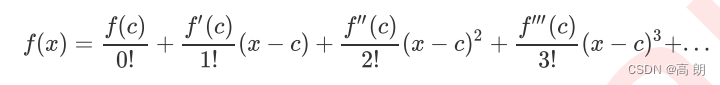 其中 f ′ ( c ) f'(c) f′(c)表示 f ( x ) f(x) f(x)上对x求导后,令x的值等于c所取得的值。
其中 f ′ ( c ) f'(c) f′(c)表示 f ( x ) f(x) f(x)上对x求导后,令x的值等于c所取得的值。
2)假设:c与x非常接近, 非常接近0,于是我们可以将式子改写成:
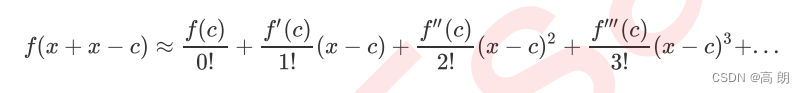 只取前两项,取约等于:
只取前两项,取约等于:
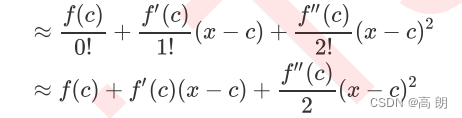
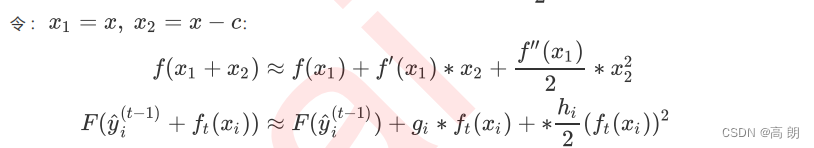 如刚才所说, x − c x-c x−c需要很小,与 x x x相比起来越小越好,那在我们的式子中,需要很小的这部分就是 f t ( x i ) f_t(x_i) ft(xi)。这其实很好理解,对于一个集成算法来说,每次增加的一棵树对模型的影响其实非常小,尤其是当我们有许多树的时候——比如,n_estimators=500的情况, f t ( x i ) f_t(x_i) ft(xi) 与 x x x 相比总是非常小的,因此这个条件可以被满足,泰勒展开可以被使用。如此,我们的目标函数可以被顺利转化成:【去掉常数项】
如刚才所说, x − c x-c x−c需要很小,与 x x x相比起来越小越好,那在我们的式子中,需要很小的这部分就是 f t ( x i ) f_t(x_i) ft(xi)。这其实很好理解,对于一个集成算法来说,每次增加的一棵树对模型的影响其实非常小,尤其是当我们有许多树的时候——比如,n_estimators=500的情况, f t ( x i ) f_t(x_i) ft(xi) 与 x x x 相比总是非常小的,因此这个条件可以被满足,泰勒展开可以被使用。如此,我们的目标函数可以被顺利转化成:【去掉常数项】
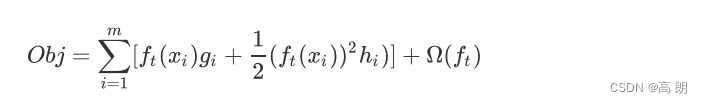 这个式子中, g i g_i gi和 h i h_i hi 只与传统损失函数相关,核心的部分是我们需要决定的树 f t f_t ft。
这个式子中, g i g_i gi和 h i h_i hi 只与传统损失函数相关,核心的部分是我们需要决定的树 f t f_t ft。
- 参数化决策树 f k ( x ) f_k(x) fk(x) :参数alpha,lambda
对于决策树而言,每个被放入模型的任意样本 i i i最终一个都会落到一个叶子节点上。对于回归树,通常来说每个叶子节点上的预测值是这个叶子节点上所有样本的标签的均值。但值得注意的是,XGB作为普通回归树的改进算法,在 y ^ \hat y y^上却有所不同
对于XGB来说,每个叶子节点上会有一个预测分数(predictionscore),也被称为叶子权重。这个叶子权重就是所有在这个叶子节点上的样本在这一棵树上的回归取值,用 f k ( x i ) f_k(x_i) fk(xi)或者 w w w来表示。
 当有多棵树的时候,集成模型的回归结果就是所有树的预测分数之和,假设这个集成模型中总共有 棵决策树,则整个模型在这个样本 上给出的预测结果为:
当有多棵树的时候,集成模型的回归结果就是所有树的预测分数之和,假设这个集成模型中总共有 棵决策树,则整个模型在这个样本 上给出的预测结果为: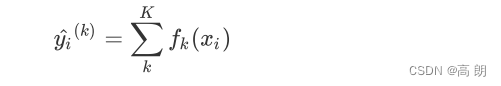
基于这个理解,我们来考虑每一棵树。对每一棵树,它都有自己独特的结构,这个结构即是指叶子节点的数量,树的深度,叶子的位置等等所形成的一个可以定义唯一模型的树结构。在这个结构中,我们使用 q ( x i ) q(x_i) q(xi)表示样本 x i x_i xi所在的叶子节点,并且使用 w q ( x i ) w_{q(x_i)} wq(xi)来表示这个样本落到第 t t t棵树上的第 q ( x i ) q(x_i) q(xi) 个叶子节点中所获得的分数,于是有:
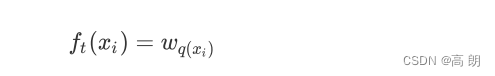 这是对于每一个样本而言的叶子权重,然而在一个叶子节点上的所有样本所对应的叶子权重是相同的。设一棵树上总共包含了 T T T个叶子节点,其中每个叶子节点的索引为 j j j,则这个叶子节点上的样本权重是 w j w_j wj 。依据这个,我们定义模型的复杂度 为 Ω ( f ) \Omega (f) Ω(f)(注意这不是唯一可能的定义,我们当然还可以使用其他的定义,只要满足叶子越多/深度越大,复杂度越大的理论,我们可以自己决定我们的 Ω ( f ) \Omega (f) Ω(f) 要是一个怎样的式子):
这是对于每一个样本而言的叶子权重,然而在一个叶子节点上的所有样本所对应的叶子权重是相同的。设一棵树上总共包含了 T T T个叶子节点,其中每个叶子节点的索引为 j j j,则这个叶子节点上的样本权重是 w j w_j wj 。依据这个,我们定义模型的复杂度 为 Ω ( f ) \Omega (f) Ω(f)(注意这不是唯一可能的定义,我们当然还可以使用其他的定义,只要满足叶子越多/深度越大,复杂度越大的理论,我们可以自己决定我们的 Ω ( f ) \Omega (f) Ω(f) 要是一个怎样的式子):
 这个结构中有两部分内容,一部分是控制树结构的 γ T \gamma T γT,另一部分则是我们的正则项。叶子数量 T T T可以代表整个树结构,这是因为在XGBoost中所有的树都是CART树(二叉树),所以我们可以根据叶子的数量 T T T判断出树的深度,而 γ \gamma γ是我们自定的控制叶子数量的参数。
这个结构中有两部分内容,一部分是控制树结构的 γ T \gamma T γT,另一部分则是我们的正则项。叶子数量 T T T可以代表整个树结构,这是因为在XGBoost中所有的树都是CART树(二叉树),所以我们可以根据叶子的数量 T T T判断出树的深度,而 γ \gamma γ是我们自定的控制叶子数量的参数。
至于第二部分正则项,参数 λ \lambda λ 和 α \alpha α 的作用其实非常容易理解,他们都是控制正则化强度的参数,我们可以二选一使用,也可以一起使用加大正则化的力度。当 λ \lambda λ 和 α \alpha α 都为0的时候,目标函数就是普通的梯度提升树的目标函数。
正则项的存在是XGB vs GBDT 核心区别之一
代码参数:
 当 λ \lambda λ 和 α \alpha α 越大,惩罚越重,正则项所占的比例就越大,在尽全力最小化目标函数的最优化方向下,叶子节点数量就会被压制,模型的复杂度就越来越低,所以对于天生过拟合的XGB来说,正则化可以一定程度上提升模型效果。
当 λ \lambda λ 和 α \alpha α 越大,惩罚越重,正则项所占的比例就越大,在尽全力最小化目标函数的最优化方向下,叶子节点数量就会被压制,模型的复杂度就越来越低,所以对于天生过拟合的XGB来说,正则化可以一定程度上提升模型效果。
网格搜索:
#使用网格搜索来查找最佳的参数组合
from sklearn.model_selection import GridSearchCV
param = {"reg_alpha":np.arange(0,5,0.05),"reg_lambda":np.arange(0,2,0.05)}
gscv = GridSearchCV(reg,param_grid = param,scoring = "neg_mean_squared_error",cv=cv)
#======【TIME WARNING:10~20 mins】======#
time0=time()
gscv.fit(Xtrain,Ytrain)
print(datetime.datetime.fromtimestamp(time()-time0).strftime("%M:%S:%f"))
gscv.best_params_
gscv.best_score_
preds = gscv.predict(Xtest)
from sklearn.metrics import r2_score,mean_squared_error as MSE
r2_score(Ytest,preds)
MSE(Ytest,preds)在实际应用中,正则化参数往往不是我们调参的最优选择,如果真的希望控制模型复杂度,我们会调整 γ \gamma γ 而不是调整这两个正则化参数,因此大家不必过于在意这两个参数最终如何影响了我们的模型效果。对于树模型来说,还是剪枝参数地位更高更优先。
寻找最佳树结构:求解 ω \omega ω与 T T T
定义了树和树的复杂度的表达式,树我们使用叶子节点上的预测分数来表达,而树的复杂度则是叶子数目加上正则项:
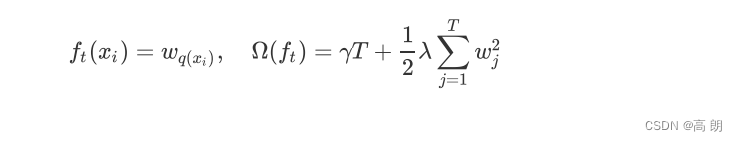
假设现在第 t t t棵树的结构已经被确定为 q q q,我们可以将树的结构带入我们的损失函数,来继续转化我们的目标函数。转化目标函数的目的是:建立树的结构(叶子节点的数量)与目标函数的大小之间的直接联系,以求出在第 t t t次迭代中需要求解的最优的树 f t f_t ft。注意,我们假设我们使用的是L2正则化(这也是参数lambda和alpha的默认设置,lambda为1,alpha为0),因此接下来的推导也会根据L2正则化来进行:
 上式的简单推导:
上式的简单推导:
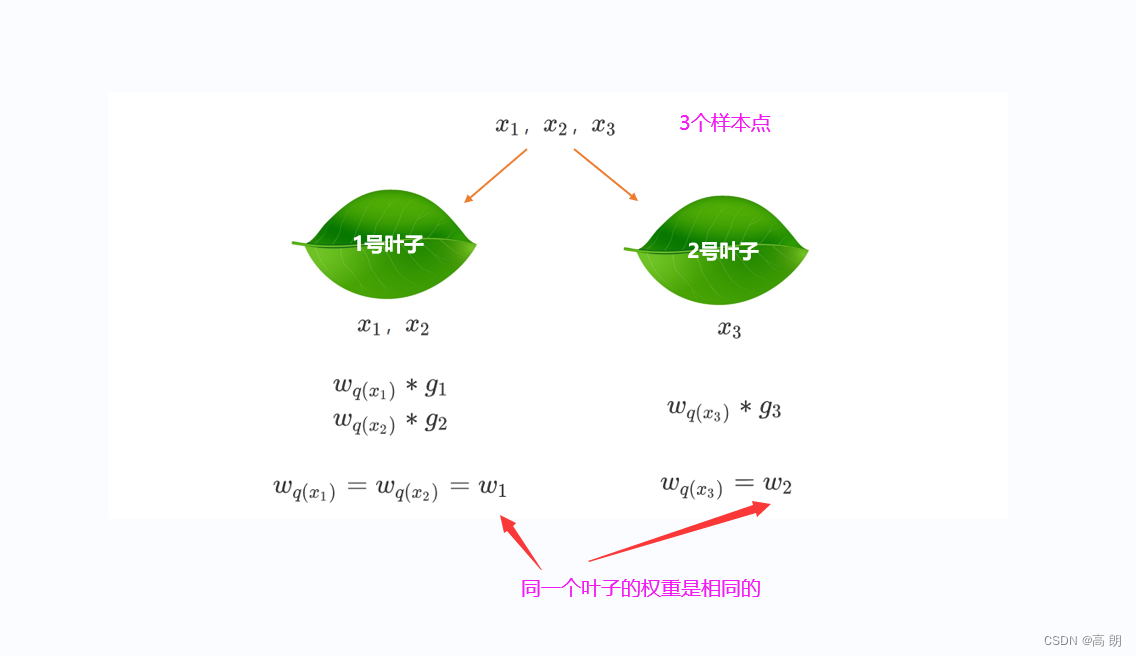 根据同一片叶子有相同的权重,可以推理出:
根据同一片叶子有相同的权重,可以推理出:
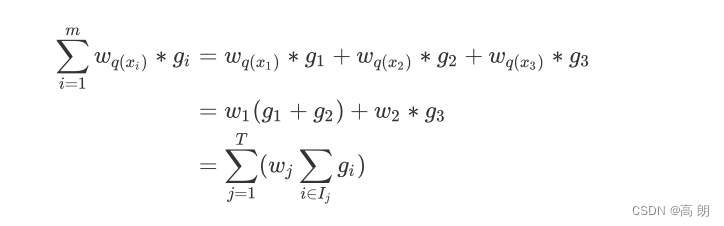
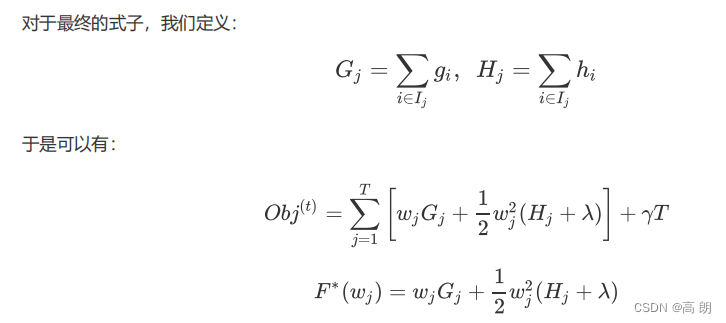 其中每个 j j j取值下都是一个以 为自变量的二次函数 F ∗ F^* F∗,我们的目标是追求让 O b j Obj Obj 最小,只要单独的每一个叶子 j j j取值下的二次函数都最小,那他们的加和必然也会最小。于是,我们在 F ∗ F^* F∗上对 w j w_j wj求导,让一阶导数等于0以求极值,可得:
其中每个 j j j取值下都是一个以 为自变量的二次函数 F ∗ F^* F∗,我们的目标是追求让 O b j Obj Obj 最小,只要单独的每一个叶子 j j j取值下的二次函数都最小,那他们的加和必然也会最小。于是,我们在 F ∗ F^* F∗上对 w j w_j wj求导,让一阶导数等于0以求极值,可得:
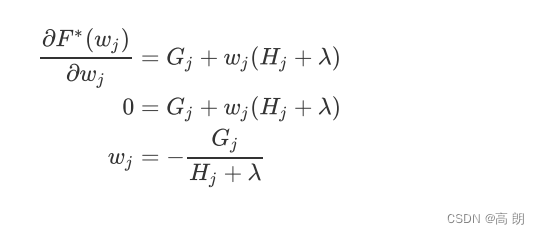 上式代入目标函数可得:
上式代入目标函数可得:
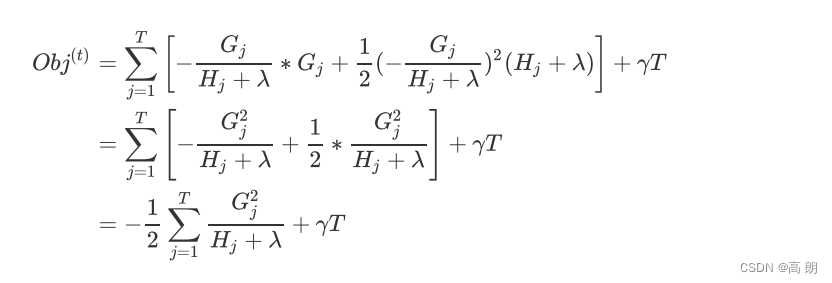 原来是损失函数 + 复杂度,现在式我们的样本量 i i i已经被归结到了每个叶子当中去,我们的目标函数是基于每个叶子节点,也就是树的结构来计算。所以,我们的目标函数又叫做“结构分数”(structure score),分数越低,树整体的结构越好。如此,我们就建立了树的结构(叶子)和模型效果的直接联系。
原来是损失函数 + 复杂度,现在式我们的样本量 i i i已经被归结到了每个叶子当中去,我们的目标函数是基于每个叶子节点,也就是树的结构来计算。所以,我们的目标函数又叫做“结构分数”(structure score),分数越低,树整体的结构越好。如此,我们就建立了树的结构(叶子)和模型效果的直接联系。
例子:
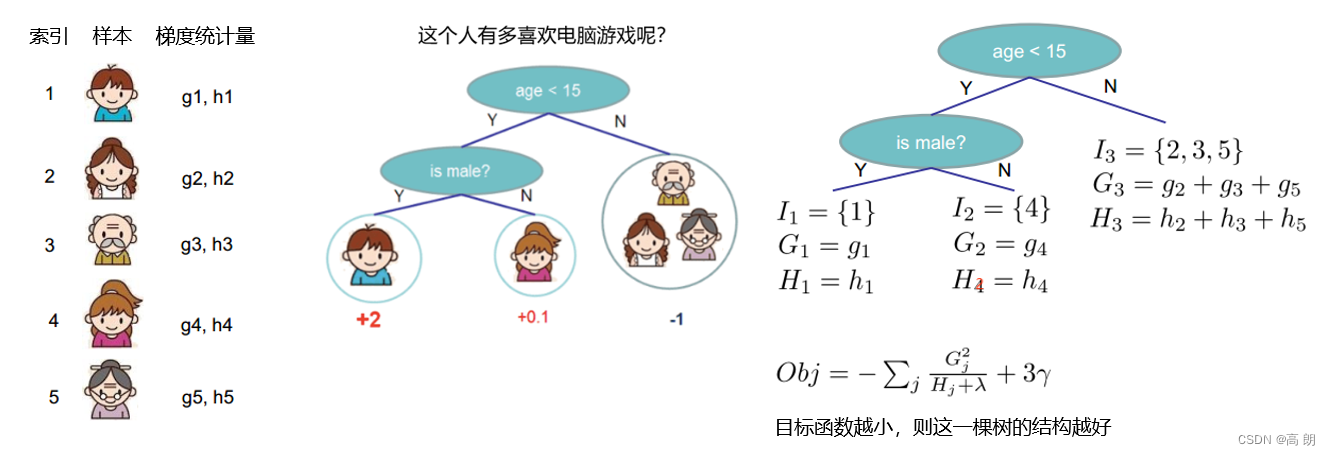
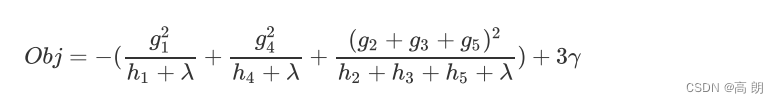 在XGB的运行过程中,我们会根据 O b j Obj Obj的表达式直接探索最好的树结构,也就是说找寻最佳的树。从式子中可以看出, λ \lambda λ 和 γ \gamma γ 是我们设定好的超参数, G j G_j Gj和 H j H_j Hj 是由损失函数和这个特定结构下树的预测结果 y ^ i ( t − 1 ) \hat y^{(t-1)}_i y^i(t−1)共同决定,而 T T T只由我们的树结构决定。则我们通过最小化 O b j Obj Obj所求解出的其实是 T T T,叶子的数量。所以本质也就是求解树的结构了。
在XGB的运行过程中,我们会根据 O b j Obj Obj的表达式直接探索最好的树结构,也就是说找寻最佳的树。从式子中可以看出, λ \lambda λ 和 γ \gamma γ 是我们设定好的超参数, G j G_j Gj和 H j H_j Hj 是由损失函数和这个特定结构下树的预测结果 y ^ i ( t − 1 ) \hat y^{(t-1)}_i y^i(t−1)共同决定,而 T T T只由我们的树结构决定。则我们通过最小化 O b j Obj Obj所求解出的其实是 T T T,叶子的数量。所以本质也就是求解树的结构了。
待我们选定了最佳的树结构(最佳的 )之后,我们使用这种树结构下计算出来的 G j G_j Gj和 H j H_j Hj就可以求解出每个叶子上的权重 ,如此就找到我们的最佳树结构,完成了这次迭代。
疑惑点:
G j G_j Gj和 H j H_j Hj的本质其实是损失函数上的一阶导数 g i g_i gi 和二阶导数 h i h_i hi之和,而一阶和二阶导数本质是:
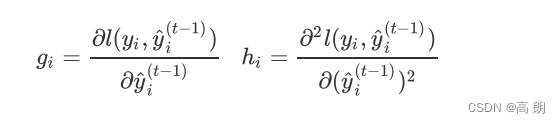 y i y_i yi是已知的标签,但我们有预测值的求解公式:
y i y_i yi是已知的标签,但我们有预测值的求解公式:
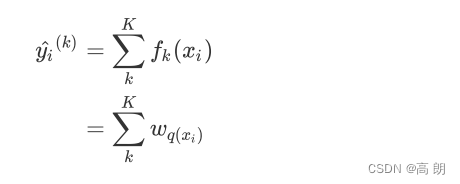 G j G_j Gj和 H j H_j Hj的计算中带有 ω \omega ω,那先确定最佳的 T T T ,再求出 G j G_j Gj和 H j H_j Hj,结合 λ \lambda λ求出叶子权重 ω j \omega_j ωj 的思路不觉得有些问题么?仿佛在带入 ω \omega ω 求解 ω \omega ω ?
G j G_j Gj和 H j H_j Hj的计算中带有 ω \omega ω,那先确定最佳的 T T T ,再求出 G j G_j Gj和 H j H_j Hj,结合 λ \lambda λ求出叶子权重 ω j \omega_j ωj 的思路不觉得有些问题么?仿佛在带入 ω \omega ω 求解 ω \omega ω ?
请注意我们的 y ^ i ( t − 1 ) \hat y^{(t-1)}_i y^i(t−1)与我们现在要求解的 w j w_j wj 其实不是在同一棵树上的。别忘记我们是在一直迭代的,我们现在求解的 w j w_j wj 是第 t t t棵树上的结果,而 y ^ i ( t − 1 ) \hat y^{(t-1)}_i y^i(t−1)是前面的 ( t − 1 ) (t-1) (t−1)棵树的累积 w w w,是在前面所有的迭代中已经求解出来的已知的部分。
求解第一棵树时,没有“前面已经迭代完毕的部分”,怎么办?
那我们如何求解第一棵树在样本 i i i下的预测值 y ^ i 1 \hat y^{1}_i y^i1呢?在建立第一棵树时,并不存在任何前面的迭代已经计算出来的信息,但根据公式我们需要使用如下式子来求解 f 1 ( x i ) f_1(x_i) f1(xi),并且我们在求解过程中还需要对前面所有树的结果进行求导。
 这时候,我们假设 y ^ i ( 0 ) = 0 \hat y^{(0)}_i = 0 y^i(0)=0来解决我们的问题,事实是,由于前面没有已经测出来的树的结果,整个集成算法的结果现在也的确为0。
这时候,我们假设 y ^ i ( 0 ) = 0 \hat y^{(0)}_i = 0 y^i(0)=0来解决我们的问题,事实是,由于前面没有已经测出来的树的结果,整个集成算法的结果现在也的确为0。
第0棵树的预测值假设为0,那求解第一棵树的 和 的过程是在对0求导?
我们其实不是在对0求导,而是对一个变量 y ^ i ( t − 1 ) \hat y^{(t-1)}_i y^i(t−1)求导。只是除了求导之外,我们还需要在求导后的结果中带入这个变量此时此刻的取值,而这个取值在求解第一棵树时刚好等于0而已。更具体地,可以看看下面,对0求导,和对变量求导后,变量取值为0的区别:

为了找出最小的 O b j Obj Obj,枚举所有可能的树结构,浪费资源又浪费时间。【采用贪婪算法寻找最佳结构】
寻找最佳分枝:结构分数之差(贪婪算法)
贪婪算法指的是控制局部最优来达到全局最优的算法,决策树算法本身就是一种使用贪婪算法的方法。XGB作为树的集成模型,自然也想到采用这样的方法来进行计算,所以我们认为,如果每片叶子都是最优,则整体生成的树结构就是最优,如此就可以避免去枚举所有可能的树结构。
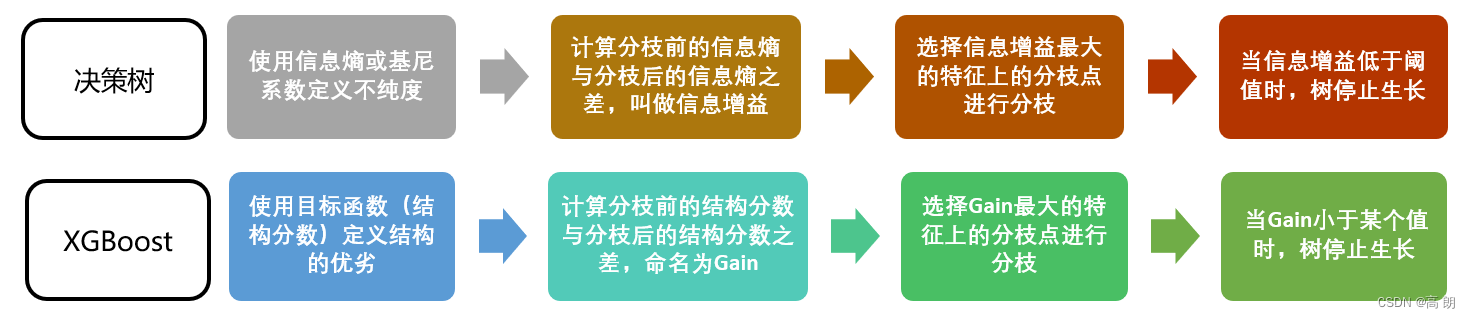 决策树中:我们使用基尼系数或信息熵来衡量分枝之后叶子节点的不纯度,分枝前的信息熵与分治后的信息熵之差叫做信息增益,信息增益最大的特征上的分枝就被我们选中,当信息增益低于某个阈值
决策树中:我们使用基尼系数或信息熵来衡量分枝之后叶子节点的不纯度,分枝前的信息熵与分治后的信息熵之差叫做信息增益,信息增益最大的特征上的分枝就被我们选中,当信息增益低于某个阈值
时,就让树停止生长。
XGB中:我们使用的方式是类似的:我们首先使用目标函数来衡量树的结构的优劣,然后让树从深度0开始生长,每进行一次分枝,我们就计算目标函数减少了多少,当目标函数的降低低于我们设定的某个阈值时,就让树停止生长。
具体计算例子:
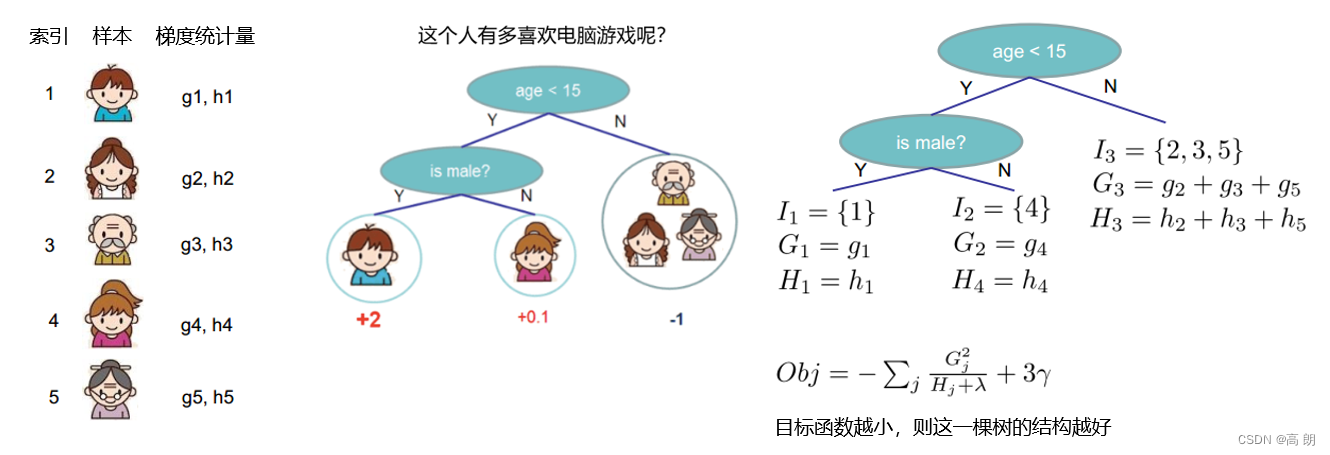
对于中间节点这一个叶子节点而言,我们的 T = 1 T=1 T=1 ,则这个节点上的结构分数为:

则分枝后的结构分数之差为:

CART树全部是二叉树,因此这个式子是可以推广的。从这个式子我们可以总结出,其实分枝后的结构分数之差为:
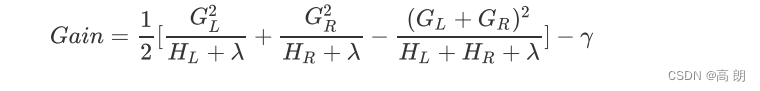 其中 G L G_L GL 和 H L H_L HL 从左节点(弟弟节点)上计算得出, G R G_R GR和 H R H_R HR 从有节点(妹妹节点)上计算得出,而 ( G L + G R ) (G_L+G_R) (GL+GR) 和 ( H L + H R ) (H_L+H_R) (HL+HR)从中间节点上计算得出。对于任意分枝,我们都可以这样来进行计算。在现实中,我们会对所有特征的所有分枝点进行如上计算,然后选出让目标函数下降最快的节点来进行分枝。对每一棵树的每一层,我们都进行这样的计算,比起原始的梯度下降,实践证明这样的求解最佳树结构的方法运算更快,并且在大型数据下也能够表现不错。
其中 G L G_L GL 和 H L H_L HL 从左节点(弟弟节点)上计算得出, G R G_R GR和 H R H_R HR 从有节点(妹妹节点)上计算得出,而 ( G L + G R ) (G_L+G_R) (GL+GR) 和 ( H L + H R ) (H_L+H_R) (HL+HR)从中间节点上计算得出。对于任意分枝,我们都可以这样来进行计算。在现实中,我们会对所有特征的所有分枝点进行如上计算,然后选出让目标函数下降最快的节点来进行分枝。对每一棵树的每一层,我们都进行这样的计算,比起原始的梯度下降,实践证明这样的求解最佳树结构的方法运算更快,并且在大型数据下也能够表现不错。
重要参数 γ \gamma γ:让树停止生长
前面的式子都涉及到这个参数 γ \gamma γ,从目标函数和结构分数之差 G a i n Gain Gain 的式子中来看, γ \gamma γ 是我们每增加一片叶子就会被剪去的惩罚项。增加的叶子越多,结构分数之差 G a i n Gain Gain 会被惩罚越重,所以 γ \gamma γ又被称之为是“复杂性控制”(complexity control),所以 是我们用来防止过拟合的重要参数。
实践证明, γ \gamma γ是对梯度提升树影响最大的参数之一,其效果丝毫不逊色于n_estimators和防止过拟合的神器max_depth。同时, γ \gamma γ 还是我们让树停止生长的重要参数。
在逻辑回归中,我们使用参数 t o l tol tol来设定阈值,并规定如果梯度下降时损失函数减小量小于 t o l tol tol下降就会停止。在XGB中,我们规定,只要结构分数之差 G a i n Gain Gain 是大于0的,即只要目标函数还能够继续减小,我们就允许树继续进行分枝。
也就是说,我们对于目标函数减小量的要求是:
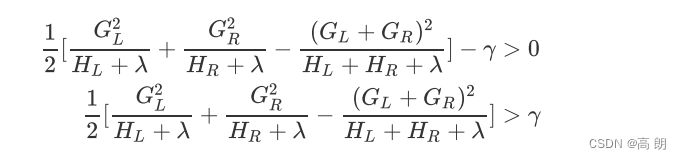
如此,我们可以直接通过设定 γ \gamma γ的大小来让XGB中的树停止生长。 γ \gamma γ因此被定义为,在树的叶节点上进行进一步分枝所需的最小目标函数减少量,在决策树和随机森林中也有类似的参数(min_split_loss,min_samples_split)。 γ \gamma γ设定越大,算法就越保守,树的叶子数量就越少,模型的复杂度就越低。
| 参数含义 | xgb.train() | xgb.XGBRegressor() |
|---|---|---|
| 复杂度的惩罚项 γ \gamma γ | gamma,默认0,取值范围[0, +∞] | gamma,默认0,取值范围[0, +∞] |
可以看到,我们完全无法从中看出什么趋势,偏差时高时低,方差时大时小,参数 γ \gamma γ引起的波动远远超过其他参数(其他参数至少还有一个先上升再平稳的过程,而 γ \gamma γ则是仿佛完全无规律)。在sklearn下XGBoost太不稳定,如果这样来调整参数的话,效果就很难保证。因此,为了调整 γ \gamma γ ,我们需要来引入新的工具,xgboost库中的类xgboost.cv。
来看用于回归和分类的评估指标都有哪些:
| 指标 | 含义 |
|---|---|
| rmse | 回归用,调整后的均方误差 |
| mae | 回归用,绝对平均误差 |
| logloss | 二分类用,对数损失 |
| mlogloss | 多分类用,对数损失 |
| error | 分类用,分类误差,等于1-准确率 |
| auc | 分类用,AUC面积 |
import xgboost as xgb
#为了便捷,使用全数据
dfull = xgb.DMatrix(X,y)#设定参数
param1 = {'verbosity':0,'objective':'reg:linear',"gamma":0}
num_round = 180
n_fold=5#使用类xgb.cv
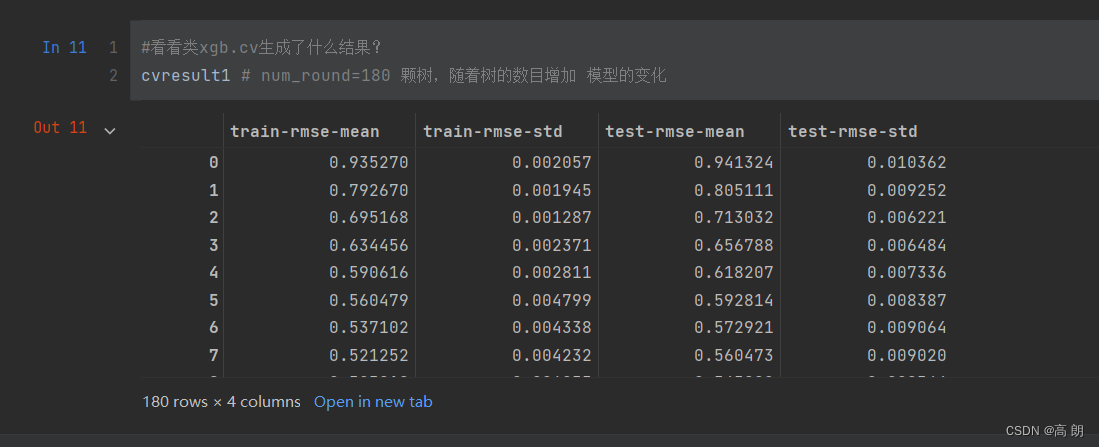
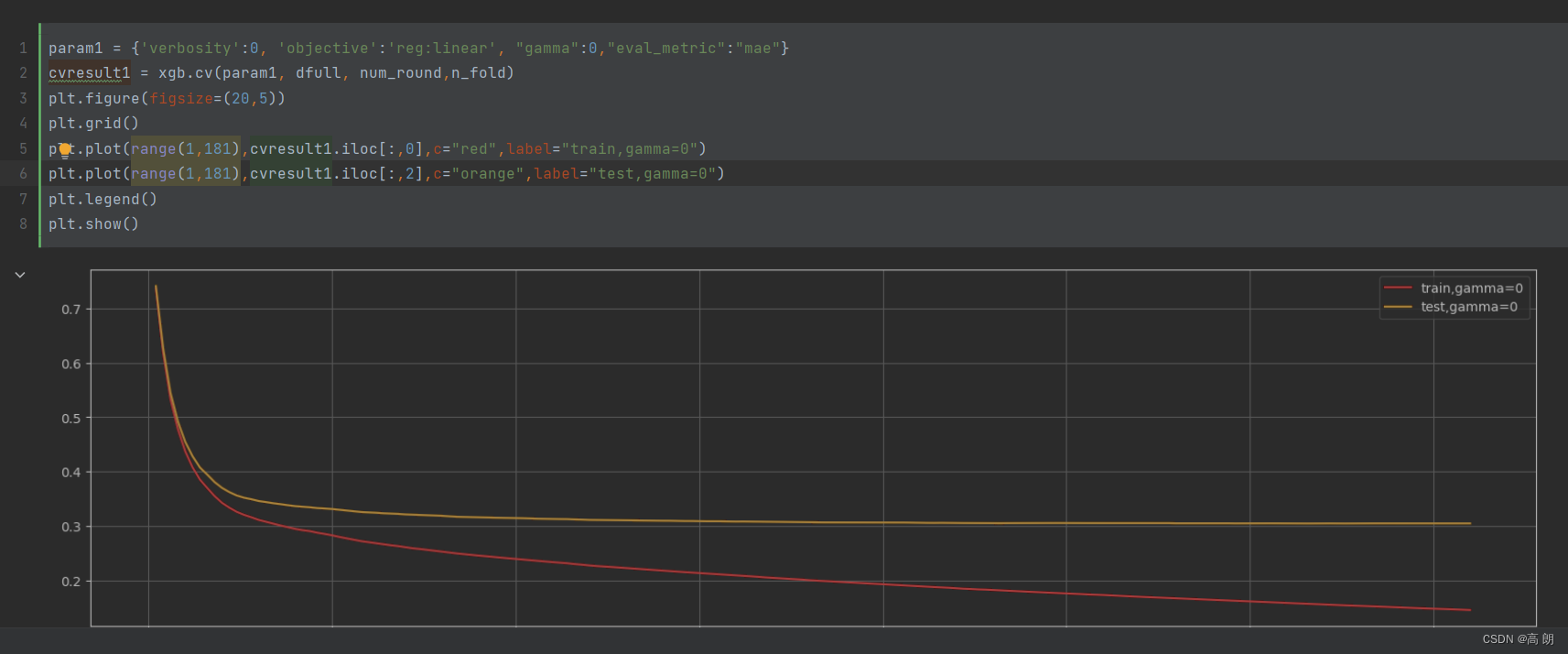
cvresult1 = xgb.cv(param1, dfull, num_round, n_fold)plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.legend()
plt.show()
cvresult1 变量:设置的180棵树,会迭代180次,返回了每一次的训练集和测试集的均方误差的均值和方差。
画图的结果:
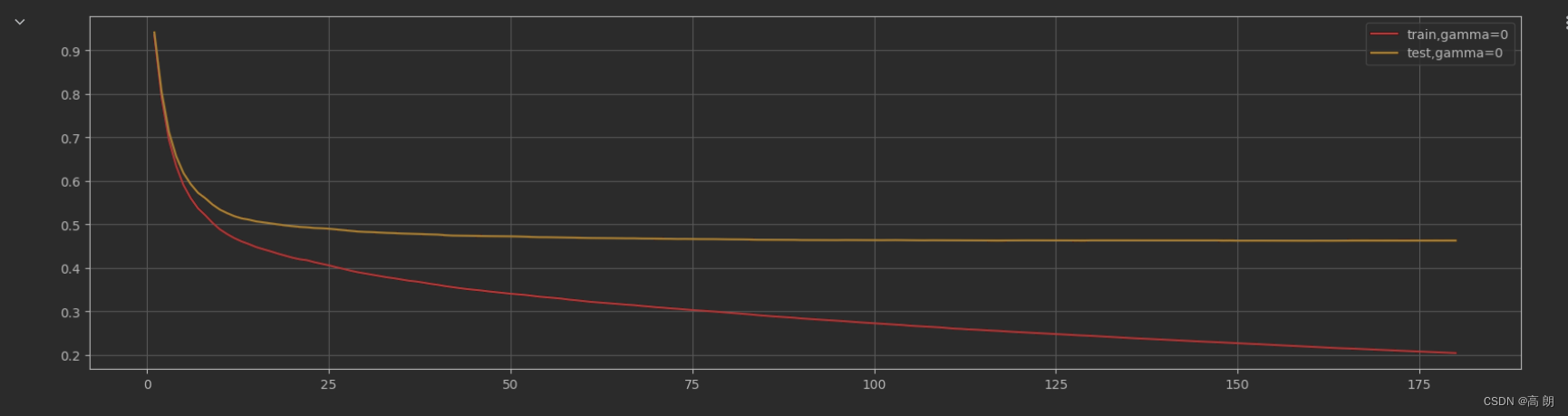
随着树的增多,均方误差都急剧下降后趋于平稳,平稳的空间就是过拟合的区间。
修改"eval_metric":"mae"模型评估指标
调整 γ \gamma γ【控制训练集上的训练–降低训练集上的表现】
param1 = {'verbosity':0,'objective':'reg:linear',"gamma":0}
param2 = {'verbosity':0,'objective':'reg:linear',"gamma":10}
num_round = 180
n_fold=5cvresult1 = xgb.cv(param1, dfull, num_round,n_fold)cvresult2 = xgb.cv(param2, dfull, num_round,n_fold)plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,181),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,181),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.plot(range(1,181),cvresult2.iloc[:,0],c="green",label="train,gamma=10")
plt.plot(range(1,181),cvresult2.iloc[:,2],c="blue",label="test,gamma=10")
plt.legend()
plt.show()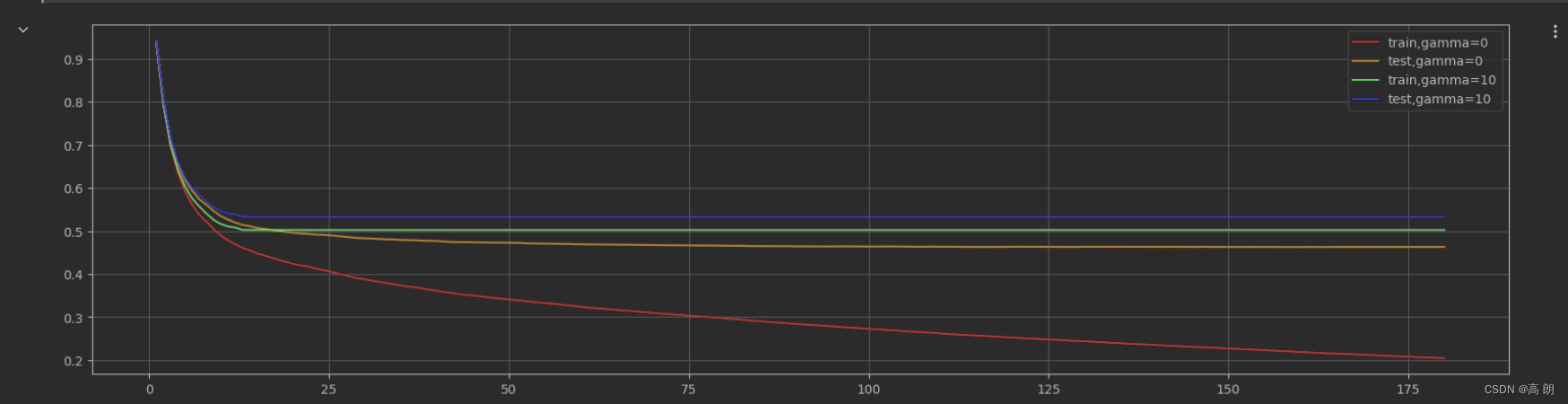 调整 γ \gamma γ后,过拟合确实有缓解,但是。。无论是训练集还是测试集都比之前的低。
调整 γ \gamma γ后,过拟合确实有缓解,但是。。无论是训练集还是测试集都比之前的低。
分类的例子:
from sklearn.datasets import load_breast_cancer
data2 = load_breast_cancer()
x2 = data2.data
y2 = data2.targetdfull2 = xgb.DMatrix(x2,y2)
param1 = {'verbosity':0,'objective':'binary:logistic',"gamma":0, "nfold":5}
param2 = {'verbosity':0,'objective':'binary:logistic',"gamma":0.5, "nfold":5}
num_round = 100cvresult1 = xgb.cv(param1, dfull2, num_round,metrics=("error"))cvresult2 = xgb.cv(param2, dfull2, num_round,metrics=("error")) plt.figure(figsize=(20,5))
plt.grid()
plt.plot(range(1,101),cvresult1.iloc[:,0],c="red",label="train,gamma=0")
plt.plot(range(1,101),cvresult1.iloc[:,2],c="orange",label="test,gamma=0")
plt.plot(range(1,101),cvresult2.iloc[:,0],c="green",label="train,gamma=2")
plt.plot(range(1,101),cvresult2.iloc[:,2],c="blue",label="test,gamma=2")
plt.legend()
plt.show()
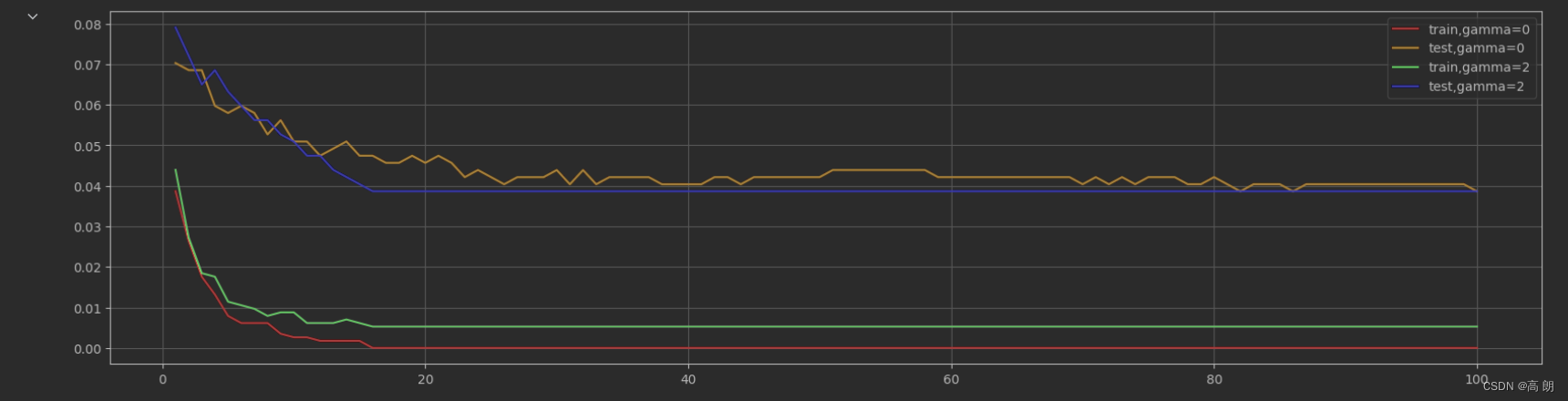 有缓解一点点过拟合。可以让我们直接看到参数如何影响了模型的泛化能力。
有缓解一点点过拟合。可以让我们直接看到参数如何影响了模型的泛化能力。
xgboost应用
- 过拟合:剪枝参数与回归模型调参
作为天生过拟合的模型,XGBoost应用的核心之一就是减轻过拟合带来的影响。作为树模型,减轻过拟合的方式主要是靠对决策树剪枝来降低模型的复杂度,以求降低方差。
可以用来防止过拟合的参数:
- 复杂度控制 γ \gamma γ
- 正则化的两个参数 λ \lambda λ 和 α \alpha α ,
- 控制迭代速度的参数 η \eta η
- 管理每次迭代前进行的随机有放回抽样的参数subsample
所有的这些参数都可以用来减轻过拟合。
除此之外,我们还有几个影响重大的,专用于剪枝的参数:
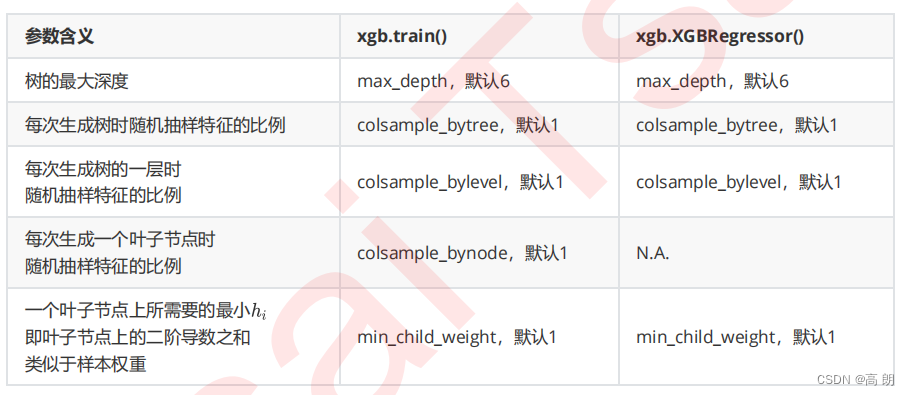 树的最大深度是是最常用的剪枝参数,不过在XGBoost中,最大深度的功能与参数 γ \gamma γ 相似,这两个参数中我们只使用一个进行调参即可。
树的最大深度是是最常用的剪枝参数,不过在XGBoost中,最大深度的功能与参数 γ \gamma γ 相似,这两个参数中我们只使用一个进行调参即可。
三个随机抽样特征的参数中,前两个比较常用。在建立树时对特征进行抽样其实是决策树和随机森林中比较常见的一种方法,但是在XGBoost之前,这种方法并没有被使用到boosting算法当中过。Boosting算法一直以抽取样本(横向抽样)来调整模型过拟合的程度,而实践证明其实纵向抽样(抽取特征)更能够防止过拟合。
参数min_child_weight不太常用,它是一篇叶子上的二阶导数 h i h_i hi之和,当样本所对应的二阶导数很小时,比如说为0.01,min_child_weight若设定为1,则说明一片叶子上至少需要100个样本。本质上来说,这个参数其实是在控制叶子上所需的最小样本量,因此对于样本量很大的数据会比较有效。如果样本量很小(比如我们现在使用的波士顿房价数据集,则这个参数效用不大)。就剪枝的效果来说,这个参数的功能也被 替代了一部分,通常来说我们会试试看这个参数,但这个参数不是我的优先选择。
获得了一个数据集后,我们先使用网格搜索找出比较合适的
n_estimators和eta组合,然后使用gamma或者max_depth观察模型处于什么样的状态(过拟合还是欠拟合,处于方差-偏差图像的左边还是右边?),最后再决定是否要进行剪枝。通常来说,对于XGB模型,大多数时候都是需要剪枝的。接下来我们就来看看使用xgb.cv这个类
来进行剪枝调参,以调整出一组泛化能力很强的参数。
设定默认参数开始,先观察一下默认参数下,我们的交叉验证曲线长什么样:
housing_california = fetch_california_housing()
X = housing_california.data # data
y = housing_california.target # labelimport xgboost as xgbdfull = xgb.DMatrix(X,y)
param1 = {'verbosity':0,'objective':'reg:linear' #并非默认,"subsample":1,"max_depth":6,"eta":0.3,"gamma":0,"lambda":1,"alpha":0,"colsample_bytree":1,"colsample_bylevel":1,"colsample_bynode":1,"nfold":5}
num_round = 200cvresult1 = xgb.cv(param1, dfull, num_round)fig,ax = plt.subplots(1,figsize=(15,8))
#ax.set_ylim(top=5)
ax.grid()
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
ax.legend(fontsize="xx-large")
plt.show()
 过拟合有点严重,接下来开始进行剪枝。我们的目标是:训练集和测试集的结果尽量接近,如果测试集上的结果不能上升,那训练集上的结果降下来也是不错的选择(让模型不那么具体到训练数据,增加泛化能力)。
过拟合有点严重,接下来开始进行剪枝。我们的目标是:训练集和测试集的结果尽量接近,如果测试集上的结果不能上升,那训练集上的结果降下来也是不错的选择(让模型不那么具体到训练数据,增加泛化能力)。
使用三组曲线:
- 一组用于展示原始数据上的结果
- 一组用于展示上一个参数调节完毕后的结果,
- 一组用于展示现在我们在调节的参数的结果。
第一组原始参数,第二组调节某个参数,在结果比第一组好的情况下,第三组对第二组的参数进行微调,如果第三组参数能够调的比第二组好,更新第二组参数为第三组的参数,第三组继续微调,如果怎么调也调不出比第二组好的参数,那么最佳参数就是第二组的参数。
调节最大深度max_depth:【已经调好了的】
num_round = 200
# 第一组 原始参数
param1 = {'verbosity':0,'objective':'reg:linear',"subsample":1,"max_depth":6,"eta":0.3,"gamma":0,"lambda":1,"alpha":0,"colsample_bytree":1,"colsample_bylevel":1,"colsample_bynode":1,"nfold":5}
cvresult1 = xgb.cv(param1, dfull, num_round)
# 第二组:调节了max_depth
# 第二组:调节了max_depth
param2 = {'verbosity':0,'objective':'reg:linear',"max_depth":3,"nfold":5}param3 = {'verbosity':0,'objective':'reg:linear',"max_depth":4,"nfold":5}cvresult2 = xgb.cv(param2, dfull, num_round)
cvresult3 = xgb.cv(param3, dfull, num_round)
fig,ax = plt.subplots(1,figsize=(15,8))
ax.grid()
ax.plot(range(1,201),cvresult1.iloc[:,0],c="red",label="train,original")
ax.plot(range(1,201),cvresult1.iloc[:,2],c="orange",label="test,original")
ax.plot(range(1,201),cvresult2.iloc[:,0],c="green",label="train,last")
ax.plot(range(1,201),cvresult2.iloc[:,2],c="blue",label="test,last")
ax.plot(range(1,201),cvresult3.iloc[:,0],c="gray",label="train,this")
ax.plot(range(1,201),cvresult3.iloc[:,2],c="pink",label="test,this")
ax.legend(fontsize="xx-large")
plt.show()
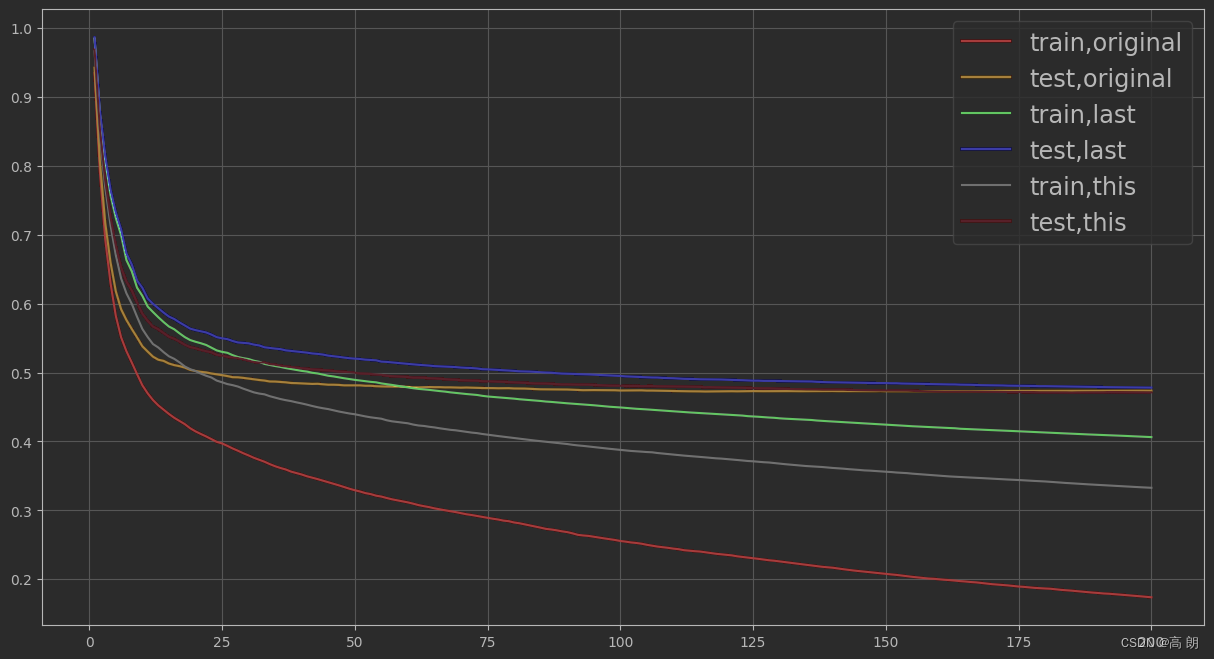
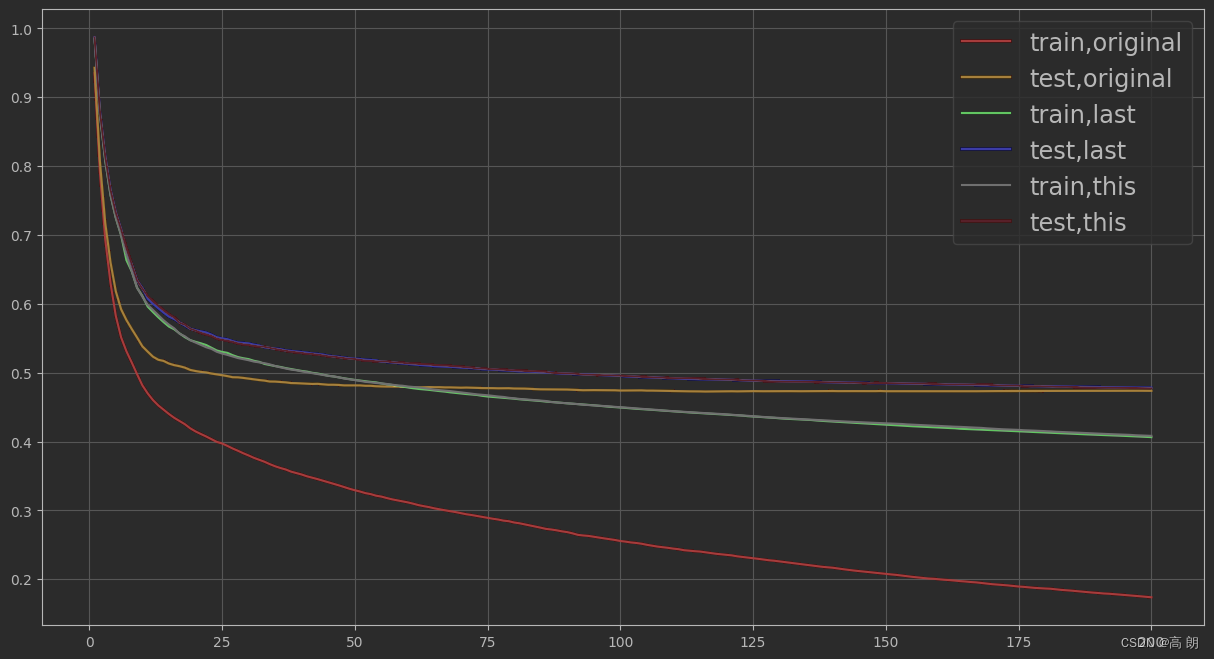
三组测试集误差几乎重叠,选与训练集间隔小的,即泛化能力强的,所以选择"max_depth":3
按照上面继续调节 e t a eta eta和 g a m m a gamma gamma,最后调出的最佳:
param3 = {'verbosity':0,'objective':'reg:linear',"max_depth":3,"eta":0.3,"gamma":0,"lambda":1,"alpha":0,"colsample_bytree":1,"colsample_bylevel":1,"colsample_bynode":1,"nfold":5}
- XGBoost模型的保存和调用
(1)使用Pickle保存和调用模型
a)保存
# 导入库
import pickle
dtrain = xgb.DMatrix(Xtrain,Ytrain)
#设定参数,对模型进行训练
param = {'silent':True,'obj':'reg:linear',"subsample":1,"eta":0.05,"gamma":20,"lambda":3.5,"alpha":0.2,"max_depth":4,"colsample_bytree":0.4,"colsample_bylevel":0.6,"colsample_bynode":1}
num_round = 180bst = xgb.train(param, dtrain, num_round)
#保存模型
pickle.dump(bst, open("xgboostonboston.dat","wb"))
#注意,open中我们往往使用w或者r作为读取的模式,但其实w与r只能用于文本文件,当我们希望导入的不是文本文件,而
是模型本身的时候,我们使用"wb"和"rb"作为读取的模式。其中wb表示以二进制写入,rb表示以二进制读入
b) 调用
#注意,如果我们保存的模型是xgboost库中建立的模型,则导入的数据类型也必须是xgboost库中的数据类型
dtest = xgb.DMatrix(Xtest,Ytest)
#导入模型
loaded_model = pickle.load(open("xgboostonboston.dat", "rb"))
print("Loaded model from: xgboostonboston.dat")
#做预测
ypreds = loaded_model.predict(dtest)
from sklearn.metrics import mean_squared_error as MSE, r2_score
MSE(Ytest,ypreds)
r2_score(Ytest,ypreds)
(2)使用Joblib保存和调用模型
bst = xgb.train(param, dtrain, num_round)
import joblib
#同样可以看看模型被保存到了哪里
joblib.dump(bst,"xgboost-boston.dat")
loaded_model = joblib.load("xgboost-boston.dat")
ypreds = loaded_model.predict(dtest)
MSE(Ytest, ypreds)
r2_score(Ytest,ypreds)
参考:
https://www.yuque.com/epimoni/blog/ub83i1q72y8cwxg7