1.Redis客户端介绍
1.基础介绍
Redis是一种客户端-服务器结构的程序,通过网络进行互动
客户端的多种形态
1.自带了命令行客户端:redis-cil
2.图形化界面的客户端:依赖windows系统,连接服务器有诸多限制,不建议使用
3.基于redis的api自行开发客户端:工作常见
2.特征与性能选择
1.Redis的快,是相对于MySQL这样的关系型数据库比较的
2.如果和内存中的操作变量相比,就没有优势了
3.是否要采用redis要结合实际的需求。单机系统不用redis,分布式再使用redis
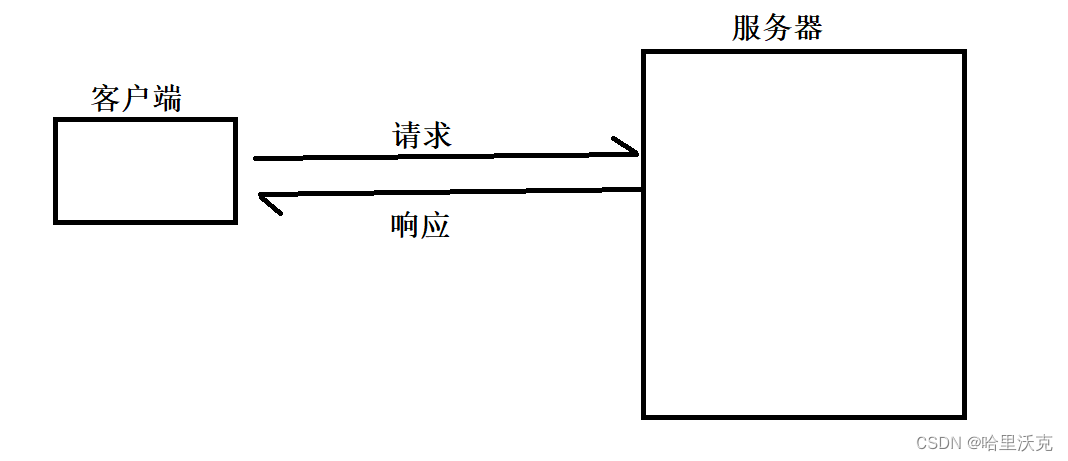
2.通用命令
先redis-cil指令进入到客户端中
1.核心命令
1.set [key] [value]:把key和value存储进去
2.get [key]:根据key取出value。如果不存在,返回nil
key和value都是字符串
2.全局命令
Redis支持多种数据结构,整体Redis是键值对存储的,对应的value可以有多种形式
1.keys
keys pattern:用来查询当前服务器上匹配的key。通过一些特殊符号来描述key模样,匹配key上述模样的key查询出来.查询的时间复杂度为O(N)
? :匹配任意一个字符
* :匹配0个或者多个任意字符
[abc] :只能匹配[]内的字符,固定了选项
[^a] :不能匹配[]内的字符,其他都能找到
[a-c] :匹配[]内范围的的固定字符
特别注意的是:在生产环境上的key可能非常多,而redis是一个单线程服务器,如果执行keys *,那么时间就会非常长,redis服务器会被阻塞,使得其他客户端不能被服务器提供服务.并且这样可能会出现keys *阻塞其他的redis查询就会超时,导致数据读取要从MySQL中进行读取,MySQL比较脆弱,一波请求可能就把系统弄崩溃
2.exists
exists key [key...]:判断key是否存在,返回个数,可以查询多个key,至少输入一个.查一个redis是按照hash的方式进行组织的,使用时的时间复杂度为O(1),查多个就O(N)
3.del
del [key...]:删除指定key,可以删除多个.删除一个的时间复杂度为O(1).
redis一般作为缓存,其实del删除的是热点数据,数据依然存在MySQL中,所以删除几个key的安全影响不大.如果redis作为数据库,那么删除数据的影响更大.redis作为消息队列,那么影响会根据情况分析了.
4.expire
expire key second:作用是给指定的key设定过期时间,设定的key超时就会自动删除
pexpire key 毫秒:设定毫秒级别的超时时间
expire的时间复杂度为O(1)
应用:手机验证码,优惠券,基于redis实现的分布式锁,设定加锁的过期时间.
5.ttl
ttl key:查询过期时间还有多少
pttl key:毫秒级的查询
时间复杂度为O(1).-1表示没有关联过期时间,-2为key不存在
redis的过期策略的实现方式:
1.redis的策略有两方面定期删除和惰性删除
2.惰性删除:key到过期时间了,但是不先删除,下一次访问时使用key,那么就删除key并且返回nil
3.定时删除:会定期执行删除的操作,不过每次都只会抽取一部分,进行检验过期时间.保证这个检测过程的时间短,以为长时间进行检测会造成阻塞
4.两个删除策略,对整体效果一般,还会有很多的key残留.那么redis在此基础上还补充了一些内存的淘汰机制
5.redis最开始是单线程的,当然随着版本迭代,现在可以使用多线程.那么其实可以针对这一特性将加入一个定时器来节省cpu处理多个key.有两种方法可以实现:优先级队列和时间轮
6.实现优先级队列,我们对优先级队列设置出队列的要求,那么在数据设定过期时间后,我们可以实现一个数据结构,将过期的截至时间和key组合,并且将其放在优先级队列中,优先级队列对的头部为最先截至的时间的结构,找到key即可删除.并且每次根据头部的截至时间进行唤醒线程对优先级队列进行操作.一旦存在新数据,那么将线程唤醒,加入到队列中,更新一下最先截至的时间并且进行线程进行休眠操作
7.时间轮:创建一个数组,一个数组为单位时间,指针指向的位置就是执行的位置.指针往后走,并且数组为环形数组.只需要将超时时间挂到相对应的数组位置上,并且通过链表的形式存储.每次走到一个位置遍历下方的链表,删除超时的key即可
8.redis源代码中,删除的核心机制就是事件循环
6.type
type key:查看key对应value的类型
3.认识数据类型即其编码方式
1.key对应的value有很多种类型,常见的有:none,string,list,set,zset,hash,stream
2.不同的value类型对应的操作各不相同
3.在redis底层,针对实现不同类型进行特定的优化,来节省时间和空间的效果背后的数据结构不一定是保准的原数据结构,不过功能和效率达到同样效果
string
1.raw:最基本的字符串,对标C++为char
2.int:通常用于计数,存储整数一般用int
3.embstr:对短字符串进行优化,占据空间会更小
hash
1.hashtable:最基本的hash表
2.ziplist:压缩哈希表,redis内部的hash表,和真hash结构不太一样,思想是一致的.在hash表元素个数比较少的时候使用.
3.list
1.linkedlist:链表
2.ziplist:压缩链表,适用于元素少的,空间利用率高,元素多了操作效率会变低
3.quicklist: redis3.2版本的类型,同时兼顾上面两种的优点
4.set
1.hashtable:
2.intset:集合中存的都是整数时的优化
5.zset
1.skiplist:跳表,也是一种链表,不同于普通链表,每个节点都有多个指针域,巧妙通过这些指针域跳跃遍历
2.ziplist
object encoding key:查看key中value的具体结构类型
3.单线程模型
1.redis只是用一个线程来处理所有的命令请求,而不是redis服务器只有一个线程,其实也有多个线程,多线程在处理网络IO,而命令操作只有一个线程进行
2.假设多个客户端同时操作一个redis服务器,redis是单线程的,当前收到多个请求时是串行执行的.请求到服务器都在队列中排队,按顺序执行,而非并发执行命令
3.redis的业务逻辑短平快,所以串行也不太影响cpu效率
redis虽然是单线程模型,但是效率高的原因
1.效率高是与数据库进行比较的
2.redis访问的是内存,而数据库访问硬盘
3.redis核心功能比数据库的核心功能更简单
4.单线程模型,避免了一些多线程竞争的操作,由于redis的操作短平快
5.处理网络IO的时候,使用epoll进行IO多路复用机制(一个线程管理多个socket)