目录
前言
逻辑时钟讲解
算法类比为面包店内取号
Lamport算法的时间戳原理
Lamport算法的5个原则
举例说明
算法实现
参考文献
-
前言
- 在并发系统中,同步与互斥是实现资源共享的关键
- Lamport面包店算法作为一种经典的解决并发问题的算法,它的实现原理和应用是每个探索并发控制的人必须要了解的知识点
- Dijkstra于1965年提出的基于共享存储的临界区互斥访问问题
- Dijkstra提出了基于对内存单元的原子性读写实现的方案
- 然而,Lamport指出Dijkstra的方案会因为节点在临界区内失效而导致系统死锁
- 在其于1974年发表的文章A New Solution of Dijkstra’s Concurrent Programming Problem中,Lamport提出了完全基于软件实现的解决方案,被称为“面包店算法”
- Lamport面包店算法是一种经典的分布式系统中互斥访问共享资源的算法,用来解决多个线程并发访问一个共享的单用户资源的互斥问题,因其设计思想类似于面包店中取号排队的方式,因此被称为面包店算法
- "面包店算法"模拟面包店内取号服务的模式,实现了先来先服务的的互斥访问
- 这个算法也可以称为时间戳策略,或者叫做Lamport逻辑时钟
-
逻辑时钟讲解
- 这里先陈述一下这个逻辑时钟的内容:
- 是一种在分布式系统中对事件进行时间戳排序的方法,在其中定义了因果关系,称为before
- 例如,before在航班满员,航班可预订
- 这里“事件预订”before“航班满员”,预订和满员就形成了因果关系
- 现实世界中,确定事件预订发生在事件满员之前,需要预订发生在比满员更早的时间
- 因果关系是一个事件(因)和第二个事件(果)之间的作用关系,其中后一个事件被认为是前一个事件的结果
- 一般来说,一个事件是很多原因综合产生的结果,而且原因都发生在较早的时间点
- 而在分布式系统中,有时不可能说两个事件中的一个首先发生;关系“happened before”只是系统中事件的部分排序
- 我们用分布式系统中的事件的先后关系,用“->”符号来表示,例如:若事件a发生在事件b之前,那么a->b
- 该关系需要满足下列三个条件:
- 1-如果a和b是同一进程中的事件,a在b之前发生,则a->b
- 2-如果事件a是消息发送方,b是接收方,则a->b
- 3-对于事件a、b、c,如果有a->b,b->c,则有a->c
- 注意,对于任何一个事件a,a->a都是不成立的,也就是说,关系->是反自反的
- 有了上面的定义,我们也可以定义出“并发”(concurrent)的概念了:
- 对于事件a、b,如果a->b,b->a两个都不成立,那么a和b就是并发的
- 直观上,上面的->关系非常好理解,即“xxx在xxx之前发生”
- 也就是说,一个系统在输入I1下,如果有a->b,那么对于这个系统的同一个输入I1,无论重复运行多少次,a也始终发生在b之前;
- 如果在输入I1下a和b是并发的,则表示在同一个输入I1下的不同运行中,a可能在b之前,也可能在b之后,也可能恰好同时发生
- 也就是说,并发并不是指一定同时发生,而是表示一种不确定性
- ->和并发的概念,就是我们理解一个系统时最基础的概念之一了
- 有了上面的概念,我们可以给系统引入时钟了
- 这里的时钟就是lamport逻辑时钟
- 一个时钟,本质上是一个事件到实数(假设时间是连续的)的函数
- 这个函数将每个事件映射到一个数字,代表这个事件发生的时间
- 形式一点来说,对于每个进程Pi,都有一个时钟Ci,这个时钟将该进程中的事件a映射到Ci(a)
- 对于一个事件b,假设b属于进程Pj,那么C(b)=Cj(b)
- 这里插一句,从这个定义也可以看到大师对分布式系统的理解
- 分布式系统中不存在一个“全局”的实体
- 在该系统中,每个进程都是一个相对独立的实体,它们有自己的本地信息(本地Knowledge)
- 而整个系统的信息则是各个进程的信息的一个聚合
- 有了时钟的一个“本质定义”还不够,我们需要考虑,什么样的时钟是一个有意义的,或者说正确的时钟
- 其实,有了前文的->关系的定义,正确的时钟应满足的条件已经十分明显了:
- 时钟条件:对于任意两个事件a,b,如果a->b,那么C(a)<C(b)
- 注意,反过来讲这个条件可不成立
- 如果我们要求反过来也成立,即“如果a->b为假,那么C(a)<C(b)也为假”,那就等于要求并发事件必须同时发生,这显然是不合理的
- 结合前文->关系的定义,我们可以把上面的条件细化成如下两条:
- 1-如果a和b是进程Pi中的两个事件,并且在Pi中,a在b之前发生,那么Ci(a)<Ci(b)
- 2-如果a是Pi发送消息m,b是Pj接收消息m,那么Ci(a)<Cj(b)
- 上面就定义了合理的逻辑时钟
- 显然,一个系统可以有无数个合理的逻辑时钟
- 实现逻辑时钟也相对简单,只要遵守两条实现规则就可以了:
- 1-每个进程Pi在自己的任何两个连续的事件之间增加Ci值
- 2-如果事件a是Pi发送消息m,那么在m中应该带上时间戳Tm=Ci(a);如果b是进程Pj接收到消息m,那么,进程Pj应该设置Cj为大于max(Tm,Cj(b))
- 有了上面逻辑时钟的定义,我们现在可以为一个系统中所有的事件排一个全序,就是使用事件发生时的逻辑时钟读数进行排序,读数小的在先
- 当然,此时可能会存在两个事件同时发生的情况
- 如果要去除这种情况,方法也非常简单:如果a在进程Pi中,b在进程Pj中,Ci(a)=Cj(b)且i < j,那么a在b之前
- 形式化一点,我们可以把系统事件E上的全序关系“=>”定义为:
- 假设a是Pi中的事件,b是Pj中的事件,那么:a=>b当且仅当以下两个条件之一成立:
- 1-Ci(a)<Cj(b)
- 2-Ci(a)=Cj(b) 且 i < j
-
算法类比为面包店内取号
- Lamport把上面这些数理逻辑时钟的概念以非常直观地类比为顾客去面包店采购
- 面包店只能接待一位顾客的采购
- step1:已知有n位顾客要进入面包店采购,安排他们按照次序在前台登记一个签到号码;该签到号码逐次加1
- step2:根据签到号码的由小到大的顺序依次入店购货
- step3:完成购买的顾客在前台把其签到号码归0;如果完成购买的顾客要再次进店购买,就必须重新排队
- 这个类比中的顾客就相当于线程,而入店购货就是进入临界区独占访问该共享资源
- 由于计算机实现的特点,存在两个线程获得相同的签到号码的情况,这是因为两个线程几乎同时申请排队的签到号码,读取已经发出去的签到号码情况,这两个线程读到的数据是完全一样的,然后各自在读到的数据上找到最大值,再加1作为自己的排队签到号码
- 为此,该算法规定如果两个线程的排队签到号码相等,则线程id号较小的具有优先权
- 进入临界区
- 已经拿到排队签到号码的线程,要轮询检查自己是否可以进入临界区
- 即检查n个线程中,自己是否具有最小的非0排队签到号码;或者自己是具有最小的非0排队签到号码的线程中,id号最小的
- 可以用伪代码表示上述检查:

- 非临界区
- 一旦线程在临界区执行完毕,需要把自己的排队签到号码置为0,表示处于非临界区
- 把该算法原理与分布式系统相结合,即可实现分布式锁
- 注意这个系统中需要引入时钟同步,博主的意见是可以采用SNTP实现时钟同步(非权威,仅供参考)
-
Lamport算法的时间戳原理
- 由部分排序可知,问题的关键点在于节点间的交互要在事件发生顺序上达成一致,而不是对于时间达成一致
- 所以,逻辑时钟指的是分布式系统中用于区分时间发生顺序的机制
- 从某种意义上来讲,现实世界的物理时间其实是逻辑时钟的特例
- 分布式系统中,按是否存在节点交互可分为三类事件,节点内部,发送事件,接收事件
- 每个事件对应一个Lamport时间戳,初始值为0
- 如果事件在节点内发生,时间戳+1
- 如果事件属于发送事件,时间戳+1并在消息中带上该时间戳
- 如果事件属于接收事件,时间戳=Max(本地时间戳,消息中的时间戳)+1
-
Lamport算法的5个原则
- 通过五条规则定义算法,为了方便起见,假设每个规则定义的操作形成单个事件:
- 为了请求资源,进程A发送消息(Tm:A)给所有的其他进程,并且把这个消息放到进程队列中,Tm是消息的时间戳
- 当进程B接收到了进程A的(Tm:A)请求后,会把它放到自己的请求队列,然后发送一个带有时间戳的确认消息给A
- 为了释放资源,进程A移除所有(Tm:A)的请求消息,然后发送带时间戳的A释放资源请求消息给其他所有的进程
- 当进程B接收到进程A释放资源的请求,它会移除队列中任意的(Tm:A)的请求资源
- 当满足以下两个条件时,进程A会被赋予资源:
- 1-有一个(Tm:A)的请求,按照=>关系排在队列第一位(它在队列中=>其他请求(为了定义=>,我们定义一个消息,使用发送消息的事件来识别))
- 2-A接收到了一个时间戳大于Tm的来自所有其他进程的消息
-
举例说明
- 在下面这幅图中,我们可以看到现在有三个进程请求临界资源,分别是P1,P2,P3
- 在P2时间戳=33时,时间戳+1,P2将34写入自己的队列,P2发送request信号分别给三个进程
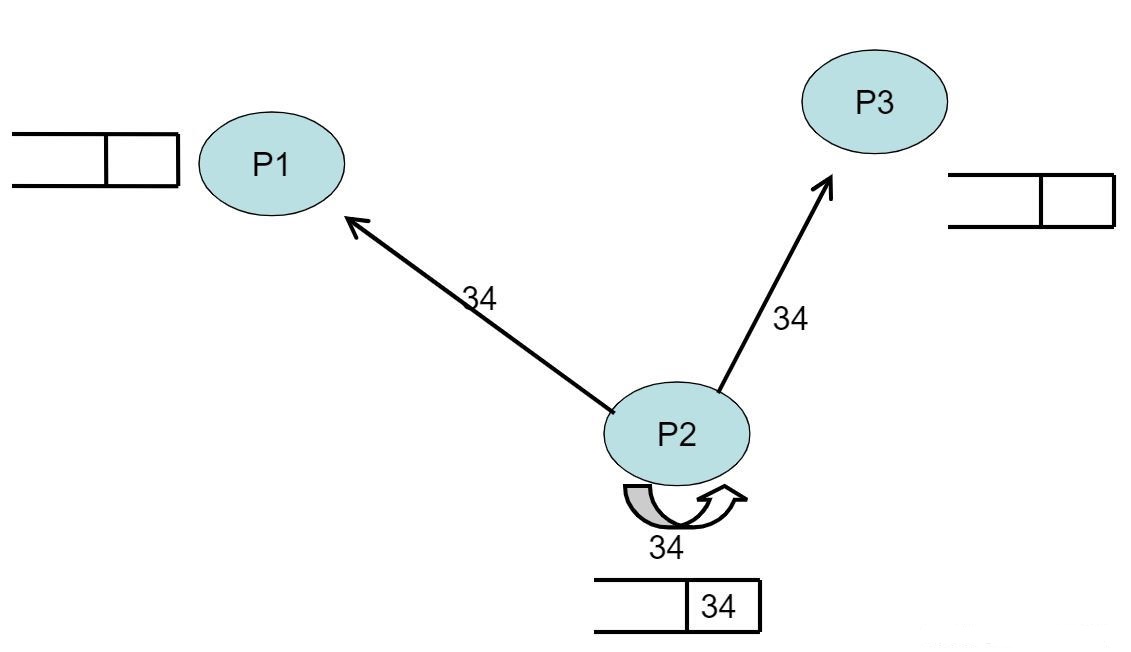
- 在P3时间戳=38时,P3收到P2的request信号,将34写入自己的队列,P3时间戳+1,向P2发送时间戳为39的reply信号
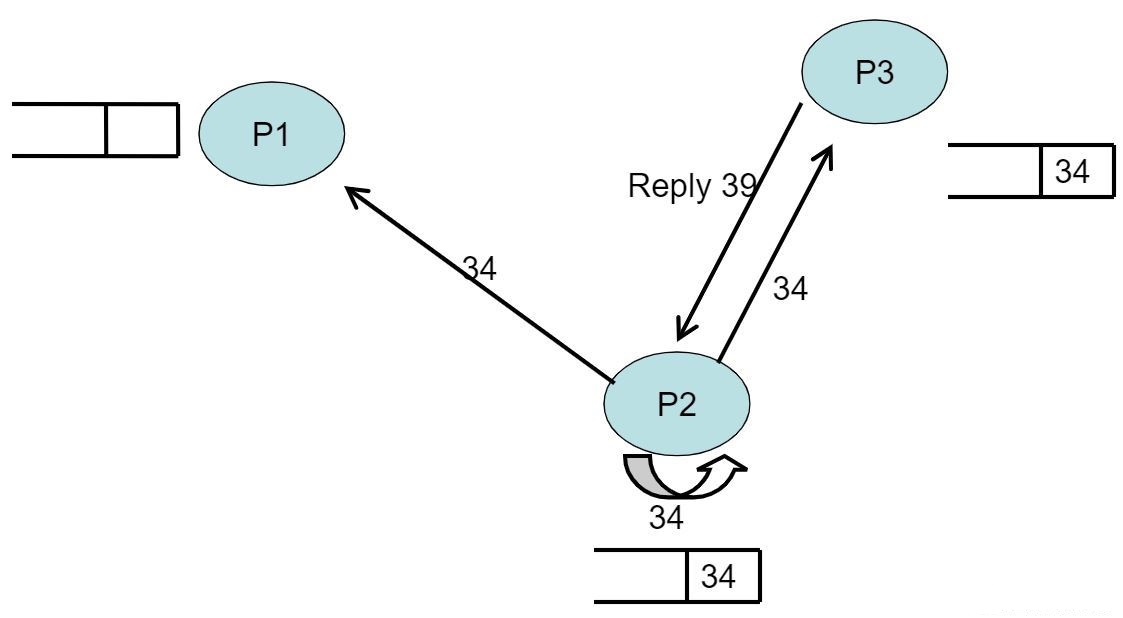
- 在P1时间戳=40时,P1时间戳+1,P1将41写入自己的队列,P1发送request信号分别给三个进程;此时P1还没有收到P2的请求信号
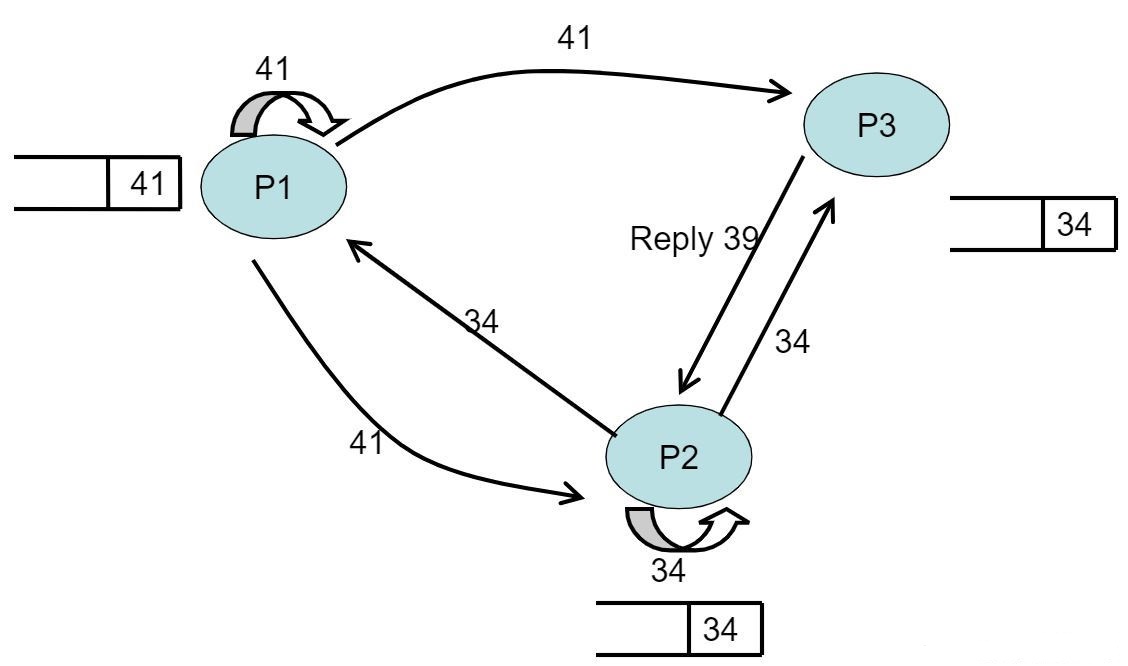
- 在P1时间戳=42时,P1收到P2的request信号,将34写入自己的队列,P1时间戳+1,向P2发送时间戳为43的reply信号
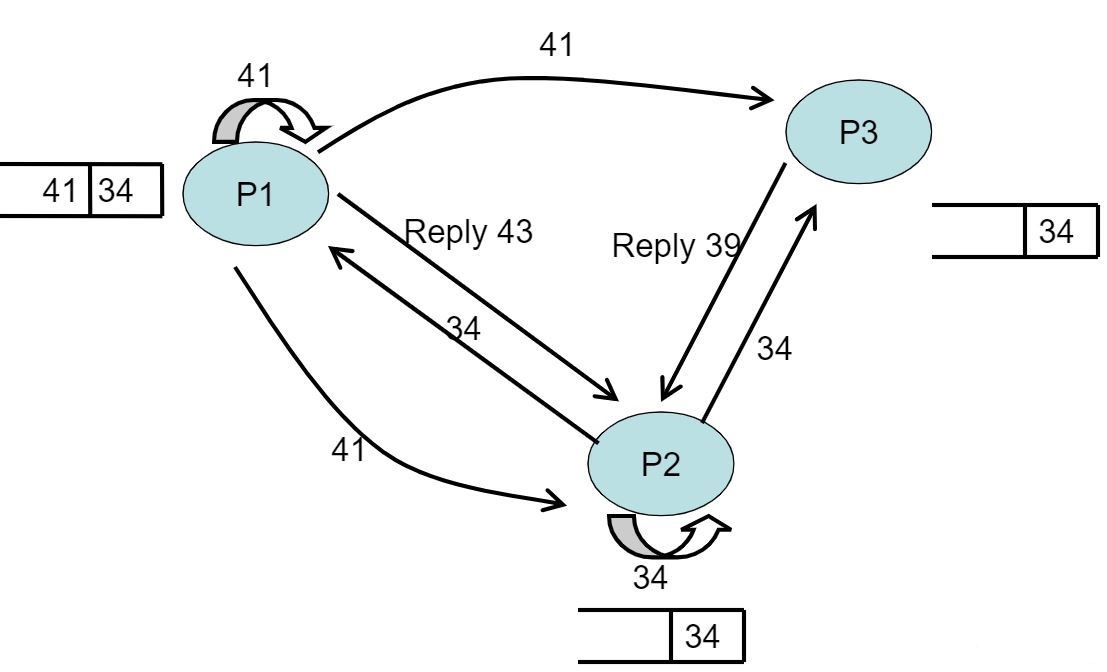
- 在P2收到其中一个进程的reply信号后,因为队头是自己的时间戳,所以P2进入临界区开始使用资源
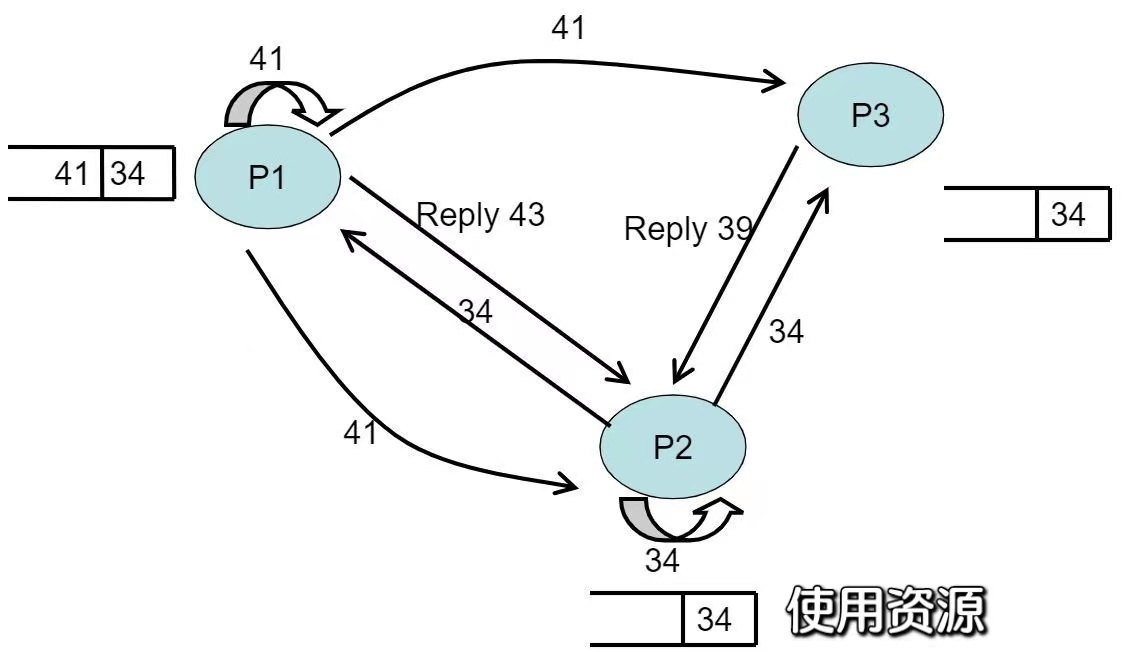
- 在P3时间戳=42时,P3收到P1的request信号,将41写入自己的队列,P3时间戳+1,向P1发送时间戳为43的reply信号
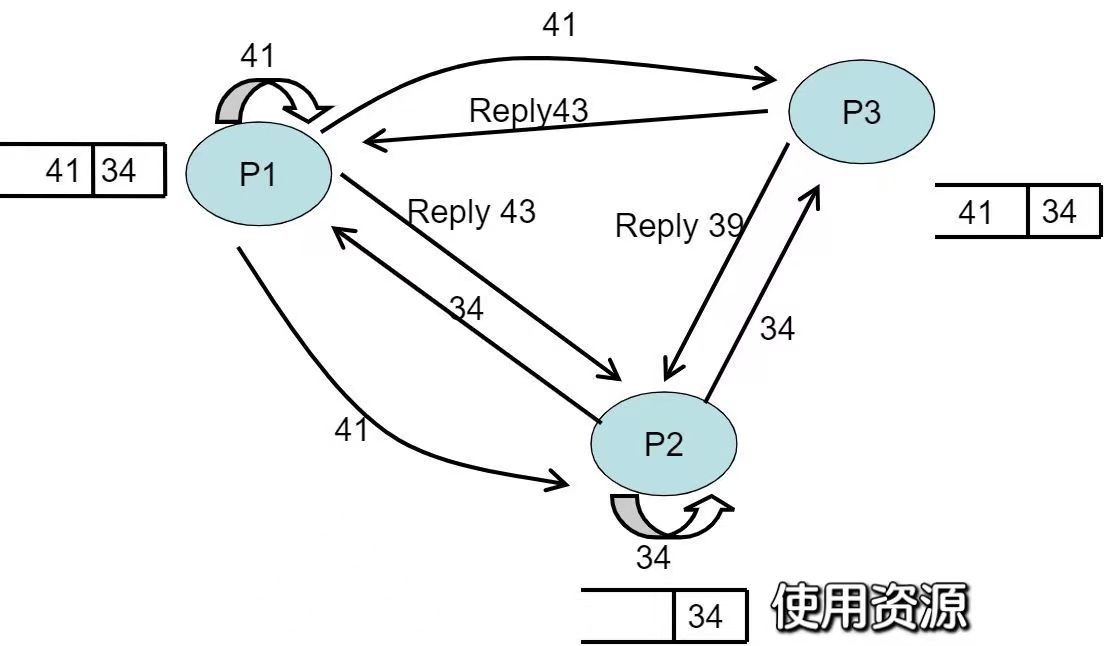
- 在P2时间戳=42时,P2收到P1的request信号,将41写入自己的队列,P2时间戳+1,向P1发送时间戳为43的reply信号
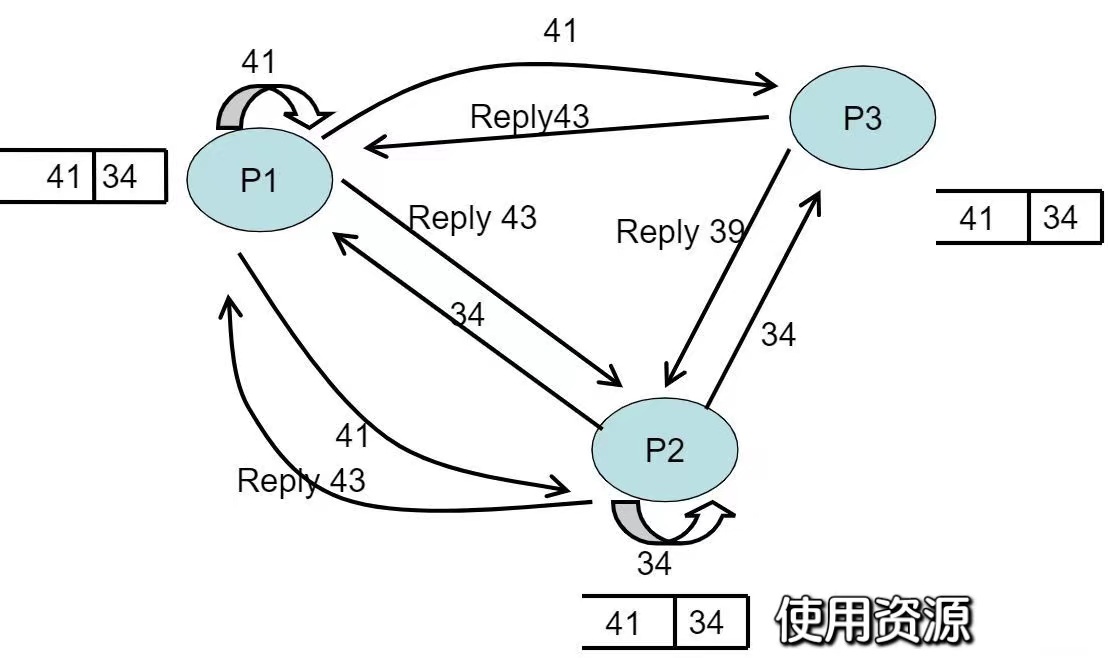
- 在P2时间戳=48时,向其他两个进程发送release信号,并将其在本地队列中释放,也在其他队列中释放
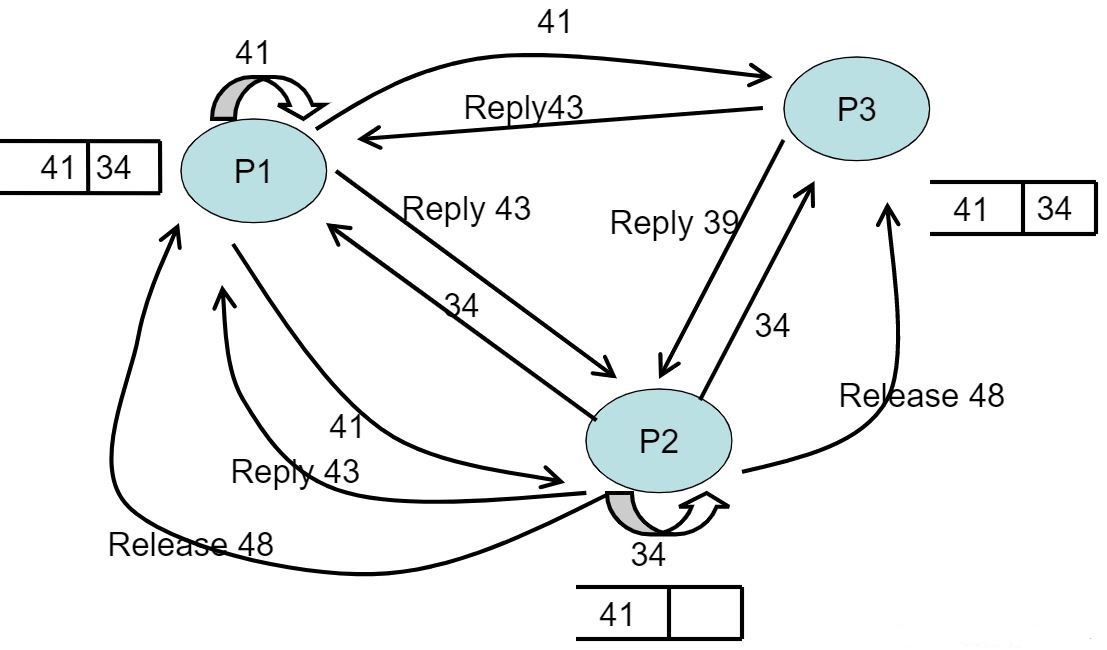
- 现在我们可以通过这个时空图回顾一下上述过程
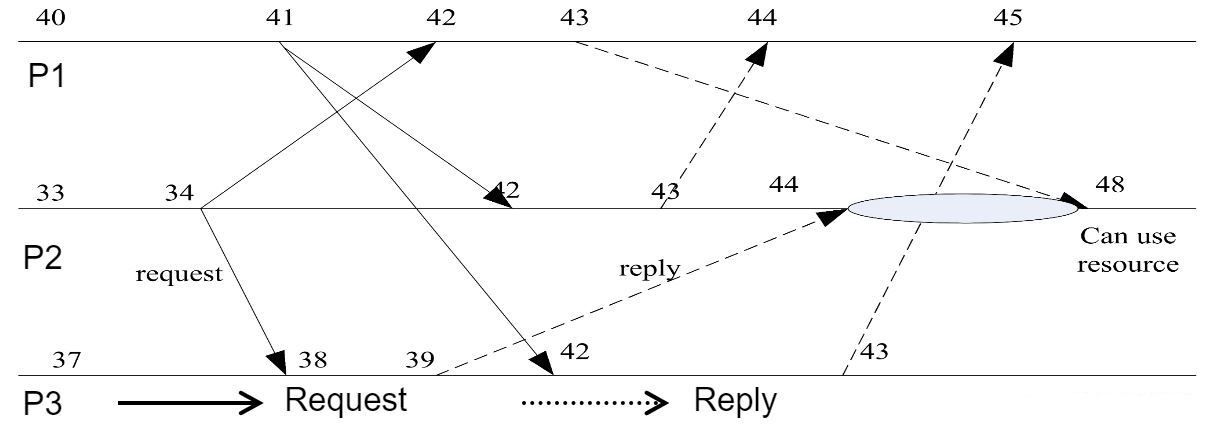
- 注意到在本地时间44,P2或许开始使用资源,因为它已经收到来自P1值为41的时间戳的消息,比P2值为34的时间戳的需求消息更大
- 此算法按照“发生在先”关系的顺序授予资源(无优先级倒置)
-
算法实现
- 定义
- 数组Choosing[i]为真,表示进程i正在获取它的排队登记号
- 数组Number[i]的值,是进程i的当前排队登记号;如果值为0,表示进程i未参加排队,不想获得该资源;规定这个数组元素的取值没有上界
- 正在访问临界区的进程如果失败,规定它进入非临界区,Number[i]的值置0,即不影响其它进程访问这个互斥资源
- 代码
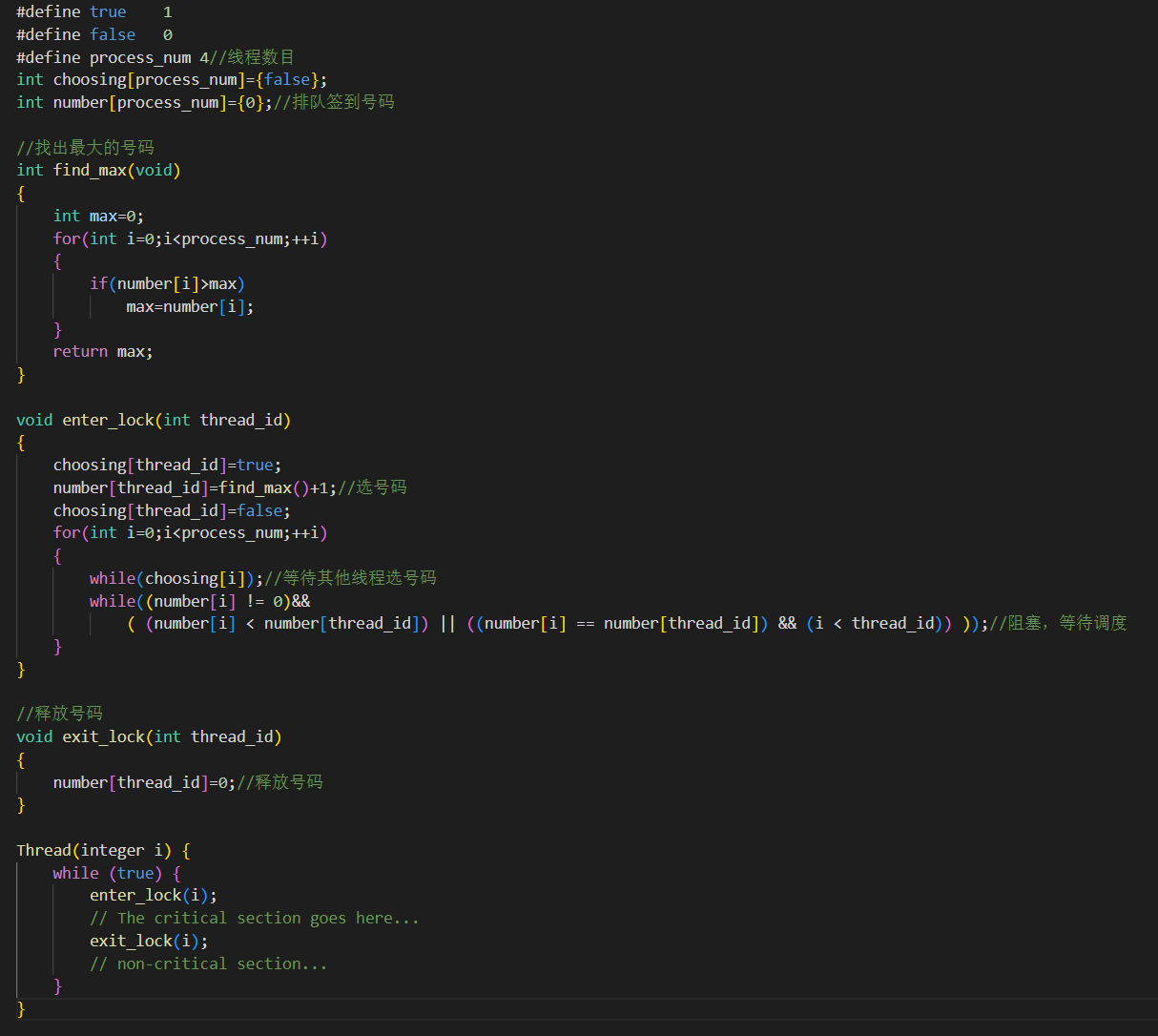
- 细节讨论
- 每个线程只写它自己的Choosing[i]、Number[i],只读取其它线程的这两个数据项
- 这个算法不需要基于硬件的原子(atomic)操作实现,即它可以纯软件实现
- 使用Choosing数组是必须的
- 假设不使用Choosing数组,那么就可能会出现这种情况:
- 设进程i的优先级高于进程j(即i<j),两个进程获得了相同的排队登记号(Number数组的元素值相等)
- 进程i在写Number[i]之前,被优先级低的进程j抢先获得了CPU时间片,这时进程j读取到的Number[i]为0,因此进程j进入了临界区
- 随后进程i又获得CPU时间片,它读取到的Number[i]与Number[j]相等,且i<j,因此进程i也进入了临界区
- 这样,两个进程同时在临界区内访问,可能会导致数据腐烂(data corruption)
- 算法使用了Choosing数组变量,使得修改Number数组的元素值变得“原子化”,解决了上述问题
- 具体实现时,可以把上述伪代码中的忙等待(busy wait),换成交出线程的执行权,例如yield操作
-
参考文献
- Original Paper
- On his publications page,Lamport has added some remarks regarding the algorithm