本文将主要介绍torchvision.datasets的使用,并以CIFAR-10为例进行介绍,对可视化工具tensorboard进行介绍,包括安装,使用,可视化过程等,最后介绍DataLoader的使用。希望对你有帮助
Pytorch公共数据集
torchvision.datasets.*
torchvision是pytorch的一个图形库,torchvision包由流行的数据集、模型架构和计算机视觉的通用图像转换组成。例如tensorboard、transfroms
在这里将主要介绍torchvision.datasets.*
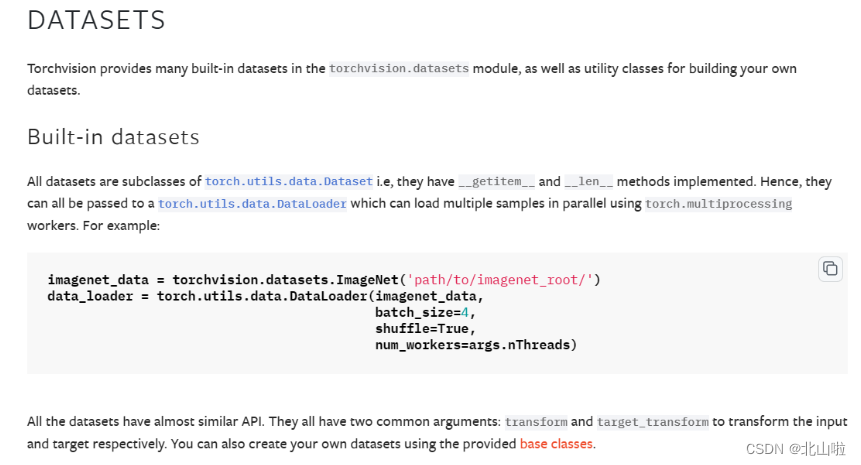
在datasets中包含了许多公共的应用于图像领域的数据集。包含:图像分类、图像检测或分割、光流法、立体声匹配等
在本章当中,将以图像分类领域的CIFAR10数据集作为torchvision.datasets的例子进行介绍,因为他比较小,下载比较快。
CIFAR-10是一个更接近普适物体的彩色图像数据集。CIFAR-10 是由Hinton 的学生Alex Krizhevsky 和Ilya Sutskever 整理的一个用于识别普适物体的小型数据集。一共包含10 个类别的RGB 彩色图片。
每个图片的尺寸为32 × 32 ,每个类别有6000个图像,数据集中一共有50000 张训练图片和10000 张测试图片。
下面是数据集中的类,以及每个类的10张随机图像

参数介绍
这些数据集的参数也是大同小异,由于CIFAR10数据集较小,下载就快。大家可以触类旁通
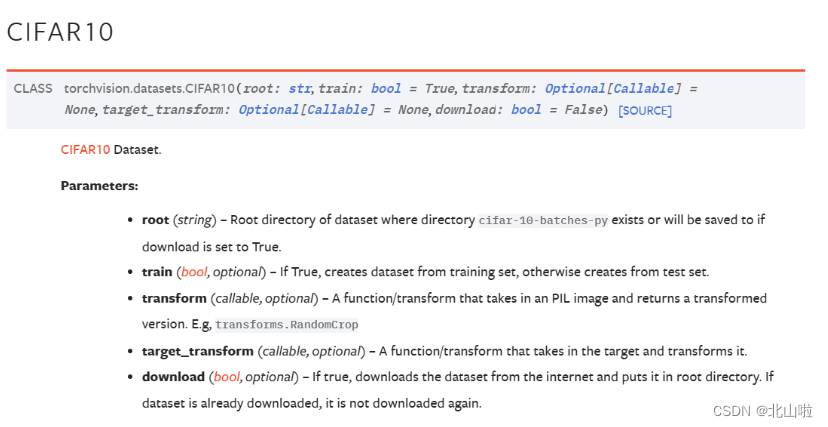
- root :即指定数据集要下载在哪一个文件夹里面
- train(bool):如果True即为训练集,否则False则为测试集
- transform :进行图像变换的各种操作,如Resize、RandomCrop、Compose
- target_transform :对于标签进行transform 操作
- download :是否下载数据集,建议设置为True即可
import torch
import torchvision
from torch.utils.data import Dataset
from torch.utils.tensorboard import SummaryWriter
#transform属性
trans_tool = torchvision.transforms.Compose([torchvision.transforms.ToTensor() # 转为Tensor类型# torchvision.transforms.Resize((5, 5)) # 进行大小裁剪
])# 数据集划分
tran_dataset = torchvision.datasets.CIFAR10(root="./dataset",train=True,transform=trans_tool,download=True)
test_dataset = torchvision.datasets.CIFAR10(root="./dataset",train=False,transform=trans_tool,download=True)
print(tran_dataset[0])
#Tensorboard
writer = SummaryWriter("logs")
for i in range(10):#显示测试集前10的图片img, label = tran_dataset[i]writer.add_image("CIFAR10",img,i)
writer.close()
Files already downloaded and verified
Files already downloaded and verified
(tensor([[[0.2314, 0.1686, 0.1961, ..., 0.6196, 0.5961, 0.5804],[0.0627, 0.0000, 0.0706, ..., 0.4824, 0.4667, 0.4784],[0.0980, 0.0627, 0.1922, ..., 0.4627, 0.4706, 0.4275],...,[0.8157, 0.7882, 0.7765, ..., 0.6275, 0.2196, 0.2078],[0.7059, 0.6784, 0.7294, ..., 0.7216, 0.3804, 0.3255],[0.6941, 0.6588, 0.7020, ..., 0.8471, 0.5922, 0.4824]],[[0.2431, 0.1804, 0.1882, ..., 0.5176, 0.4902, 0.4863],[0.0784, 0.0000, 0.0314, ..., 0.3451, 0.3255, 0.3412],[0.0941, 0.0275, 0.1059, ..., 0.3294, 0.3294, 0.2863],...,[0.6667, 0.6000, 0.6314, ..., 0.5216, 0.1216, 0.1333],[0.5451, 0.4824, 0.5647, ..., 0.5804, 0.2431, 0.2078],[0.5647, 0.5059, 0.5569, ..., 0.7216, 0.4627, 0.3608]],[[0.2471, 0.1765, 0.1686, ..., 0.4235, 0.4000, 0.4039],[0.0784, 0.0000, 0.0000, ..., 0.2157, 0.1961, 0.2235],[0.0824, 0.0000, 0.0314, ..., 0.1961, 0.1961, 0.1647],...,[0.3765, 0.1333, 0.1020, ..., 0.2745, 0.0275, 0.0784],[0.3765, 0.1647, 0.1176, ..., 0.3686, 0.1333, 0.1333],[0.4549, 0.3686, 0.3412, ..., 0.5490, 0.3294, 0.2824]]]), 6)
利用tensorboard查看,在控制台输入即可:
tensorboard --logdir 目录
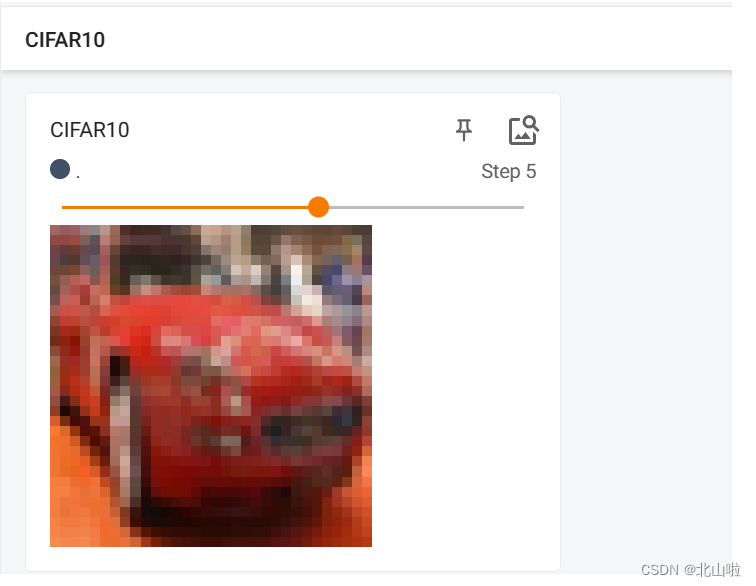
关于torchvision.datasets.CIFAR10介绍已经讲解完毕,后续内容为扩展内容,包括:tensorboard、DataLoader的使用
tensorboard可视化工具
torch.utils.tensorboard
在Pytorch发布后,网络及训练过程的可视化工具也相应地被开发出来,方便用户监督所建立模型的结构和训练过程
深度学习网络通常具有很深的层次结构,而且层与层之间通常会有并联、串联等连接方式,利用有效的工具将建立的深度学习网络结构有层次化的展示,这就需要使用相关的深度学习网络结构可视化库。
从Pytorch1.1之后,加入了tensorboard
一般安装新版的pytorch会自动安装,如果没安装,则在终端命令行下使用下面命令即可安装
pip install tensorboard
-
add_image()添加图片
-
add_scalar()添加标量数据
主要代码如下
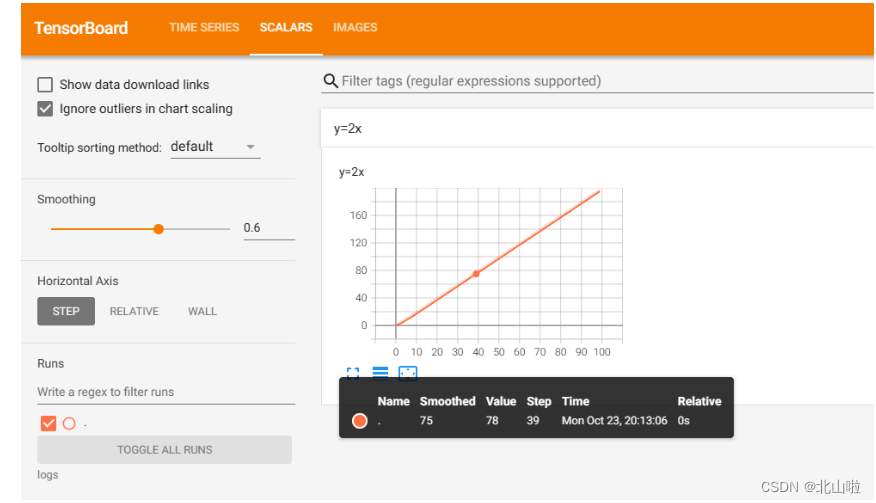
from torch.utils.tensorboard import SummaryWriterwriter = SummaryWriter("logs") # 创建SummaryWriter,将运行结果存logs文件夹中
for i in range(100):writer.add_scalar("y=2x",2*i,i) # 第一个参数相当于标题,第二个参数就相当于纵坐标的值,第三个参数就相当于横坐标的值
writer.close()
可视化操作
在终端输入:tensorboard --logdir 目录
访问:http://localhost:6006即可
writer.add_image的例子
from PIL import Image
from torchvision import transforms
from torch.utils.tensorboard import SummaryWriterimg_path = r"./pic.png"
# 打开一张图片
img = Image.open(img_path)
# 使用transforms对图像进行变换
# 实例化totensor对象
to_tens = transforms.ToTensor()
# 将pic变成Tensor类型的图片
tens_img = to_tens(img) # 自动调用call函数
#print(tens_img)# 使用上一篇文章中tensorboard进行查看
writer = SummaryWriter("transforms_logs")
writer.add_image("test_transforms",tens_img) # 标题,图像类型
writer.close()
DataLoader的使用
from torch.utils.data import DataLoader
torch的DataLoader主要是用来装载数据,就是给定已知的数据集,把数据集装载进DataLoaer,然后送入深度学习网络进行训练。
在torch.utils.data.DataLoader()参数中,只有dataset为必填参数,其他的均有默认值,下文介绍几个重要的参数

-
dataset:表示要读取的数据集
-
batch_size:表示每次从数据集中取多少个数据
-
shuffle:表示是否为乱序取出,True表示前后不一样
-
num_workers :表示是否多进程读取数据(默认为0);
-
drop_last : 表示当样本数不能被batchsize整除时(即总数据集/batch_size 不能除尽,有余数时),最后一批数据(余数)是否舍弃(default:
False) -
pin_memory: 如果为True会将数据放置到GPU上去(默认为false)
还是以上文的CIFAR10的测试集为例
from torch.utils.data import DataLoader
import torchvision
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)
Files already downloaded and verified
# 创建DataLoader实例
test_loader = DataLoader(dataset=test_set, # 引入数据集batch_size=4, # 每次取4个数据shuffle=True, # 打乱顺序num_workers=0, # 非多进程drop_last=False # 最后数据(余数)不舍弃
)
利用DataLoader的完整代码如下
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter# 准备测试集
test_set = torchvision.datasets.CIFAR10("dataset",train=False,transform=torchvision.transforms.ToTensor(),download=True)# 创建test_loader实例
test_loader = DataLoader(dataset=test_set, # 引入数据集batch_size=4, # 每次取4个数据shuffle=True, # 打乱顺序num_workers=0, # 非多进程drop_last=False # 最后数据(余数)不舍弃
)img,index = test_set[0]
print(img.shape) # 查看图片大小 torch.Size([3, 32, 32]) C h w,即三通道 32*32
print(index) # 查看图片标签
# 遍历test_loader
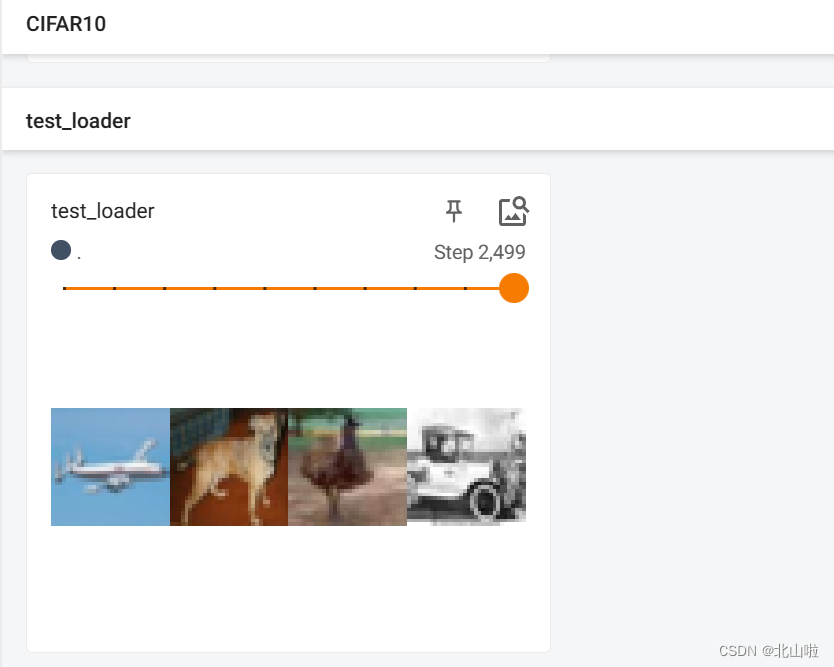
for data in test_loader:img,target = dataprint(img.shape) # 查看图片信息torch.Size([4, 3, 32, 32])表示一次4张图片,图片为3通道RGB,大小为32*32print(target) # tensor([4, 9, 8, 8])表示4张图片的target
# 在tensorboard 中显示
writer = SummaryWriter("logs")
step = 0
for data in test_loader:img, target = datawriter.add_images("test_loader",img,step)step = step+1
writer.close()tensorboard显示如下