1. Sqoop
1.1 Sqoop介绍
-
Sqoop 是一个在结构化数据和 Hadoop 之间进行批量数据迁移的工具
-
结构化数据可以是MySQL、Oracle等关系型数据库
-
把关系型数据库的数据导入到 Hadoop 与其相关的系统
-
把数据从 Hadoop 系统里抽取并导出到关系型数据库里
-
-
底层用 MapReduce 实现数据
- 命令执行过程中,map 0% ,Reduce0%----》map 100% ,Reduce 100%

-
| id | name | age |
|---|---|---|
| 1 | zhangsan | 18 |

1.2 Sqoop安装
-
下载、上传、解压、重命名和授权
- https://mirrors.tuna.tsinghua.edu.cn/apache/sqoop/1.3.7/sqoop-1.3.7.bin__hadoop-2.6.0.tar.gz
-
上传到 /home/hadoop 目录,直接在xshell拖拽进入家目录即可
-
#Sqoop的安装 sudo tar -xvf sqoop-1.3.7.bin__hadoop-2.6.0.tar.gz -C /usr/local #改名 sudo mv /usr/local/sqoop-1.3.7.bin__hadoop-2.6.0/ /usr/local/sqoop #授权 sudo chown -R hadoop /usr/local/sqoop
1.3 Sqoop配置和验证
1.3.1 sqoop配置
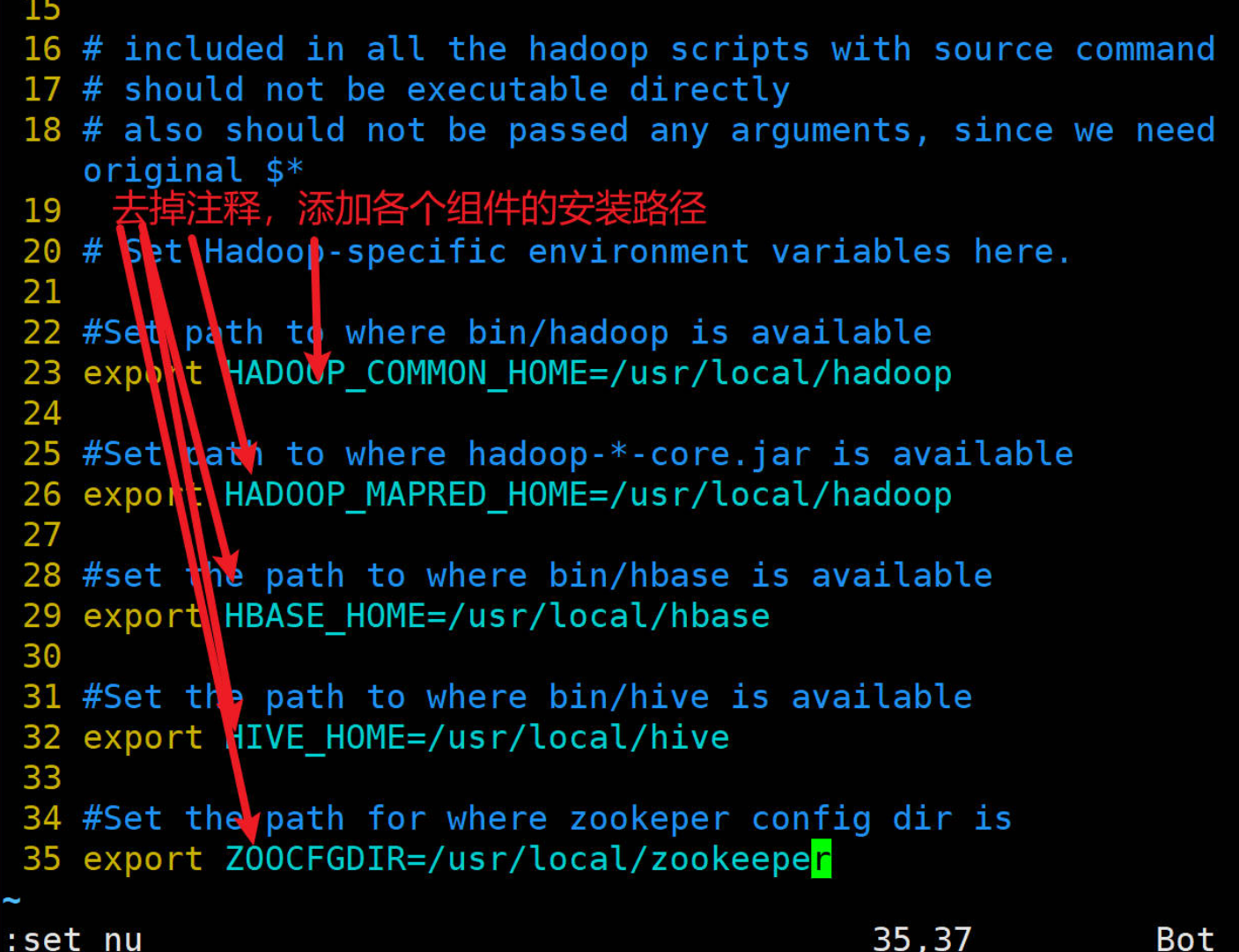
#1、修改配置文件
mv /usr/local/sqoop/conf/sqoop-env-template.sh /usr/local/sqoop/conf/sqoop-env.sh# 进入配置目录,把各个组件的路径写入
cd /usr/local/sqoop/conf/
sudo vim sqoop-env.sh
#2、上传 jar 文件
cd /usr/local/sqoop/lib/
#2.1 上传 MySQL 的驱动文件,拖拽上传进xshell#2.2拷贝 hive 的驱动文件
cp /usr/local/hive/lib/hive-common-2.3.7.jar /usr/local/sqoop/lib/#3、配置环境变量
#编辑环境变量
vim /home/hadoop/.bashrc#在环境变量最后添加以下内容
export SQOOP_HOME=/usr/local/sqoop
export PATH=$PATH:$SQOOP_HOME/bin#刷新环境变量
source /home/hadoop/.bashrc#验证是否安装成功
sqoop version
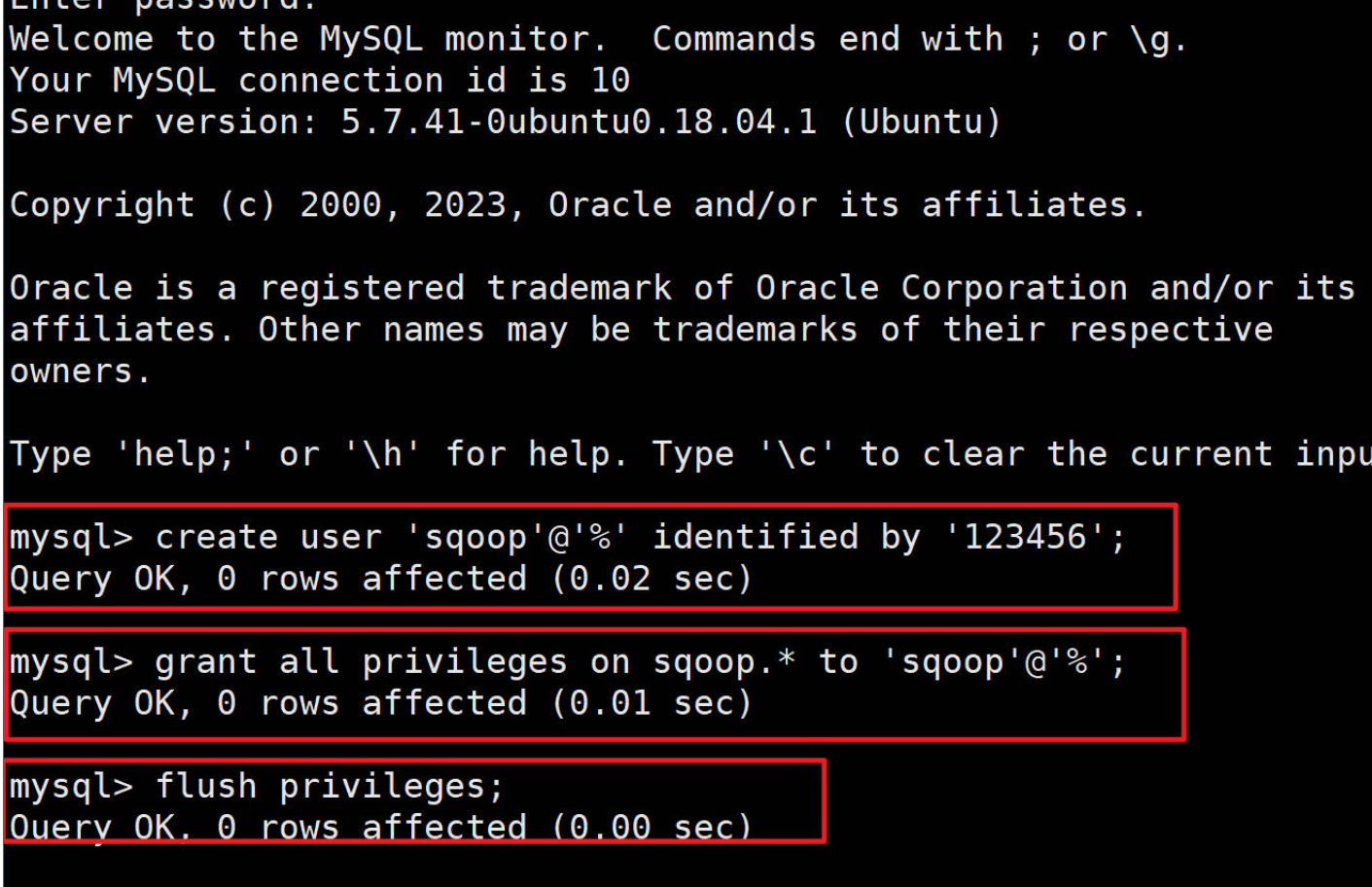
1.3.2 在MySQL中创建sqoop用户
#查看管理员账户和密码
sudo cat /etc/mysql/debian.cnf #用查看的账户和密码登录
mysql -u debian-sys-maint -p#登录成功再执行下面命令,可参考下图
#创建sqoop用户,
create user 'sqoop'@'%' identified by '123456';
#并对用户授权
grant all privileges on sqoop.* to 'sqoop'@'%';
#刷新使授权生效
flush privileges;#退出
exit;
执行MySQL示例:
1.3.3 验证sqoop是否成功运行及常见错误:
- #测试能否成功连接数据库
#测试能否成功连接数据库
sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456
使用命令报错时:
#测试能否成功连接数据库 sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456**报错信息如下:**ERROR manager.CatalogQueryManager: Failed to list databases
com.mysql.jdbc.exceptions.jdbc4.CommunicationsException: Communications link failure
完整信息在下面:
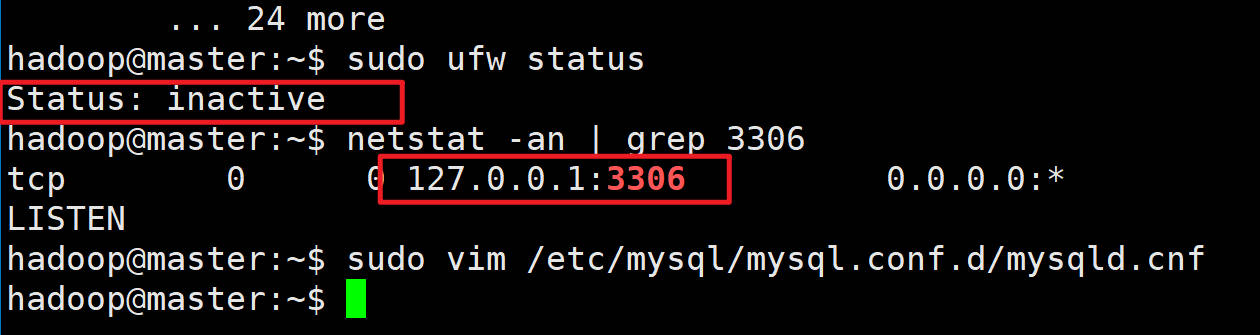
Warning: /usr/local/sqoop/../hcatalog does not exist! HCatalog jobs will fail. Please set $HCAT_HOME to the root of your HCatalog installation. Warning: /usr/local/sqoop/../accumulo does not exist! Accumulo imports will fail. Please set $ACCUMULO_HOME to the root of your Accumulo installation. 。。。at org.apache.sqoop.Sqoop.runTool(Sqoop.java:243)at org.apache.sqoop.Sqoop.main(Sqoop.java:252) Caused by: java.net.ConnectException: Connection refused (Connection refused)at java.net.PlainSocketImpl.socketConnect(Native Method)at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:350)at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:206)at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:188)at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)at java.net.Socket.connect(Socket.java:589)at com.mysql.jdbc.StandardSocketFactory.connect(StandardSocketFactory.java:211)at com.mysql.jdbc.MysqlIO.<init>(MysqlIO.java:301)... 24 more原因:没有开启远程登录,需要修改配置
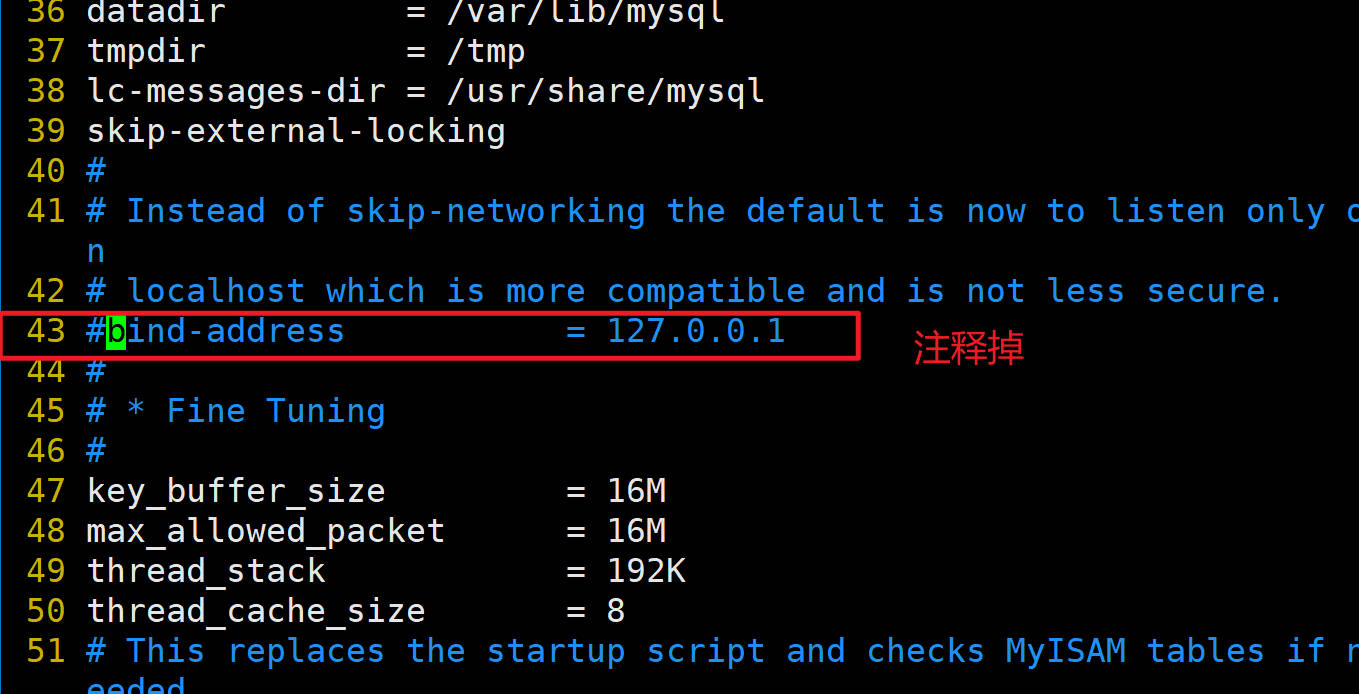
**解决方案:**#查看状态(防火墙是inactive状态) sudo ufw status #查看端口 netstat -an | grep 3306
~~~shell#编辑端口
#注释掉43行的bind-address
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf##修改端口,需要重启虚拟机
sudo reboot
成功状态:
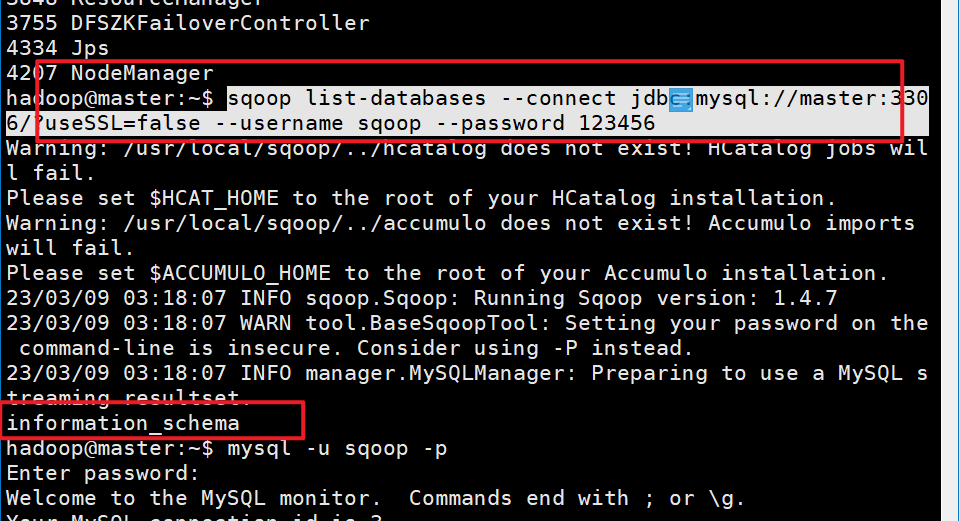
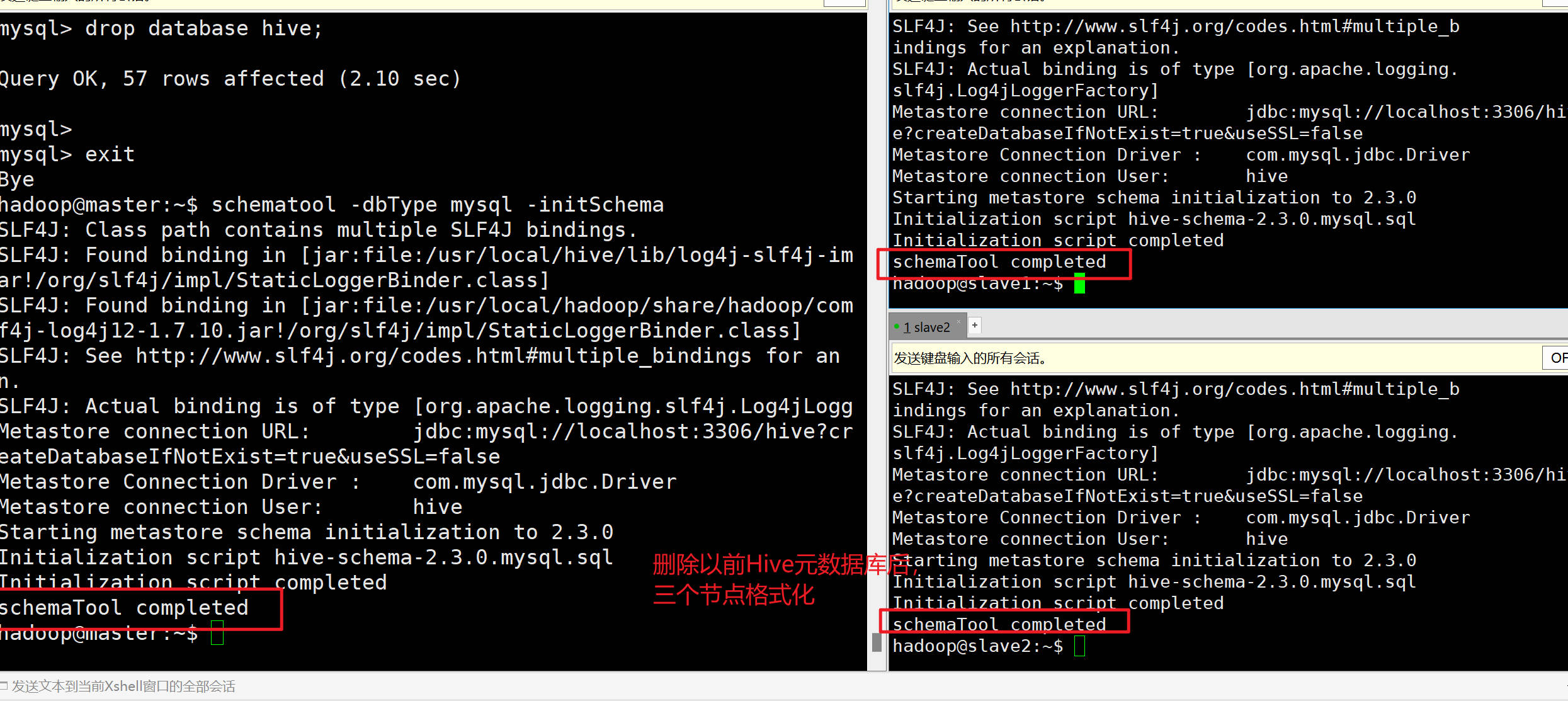
**如果Sqoop转移数据到Hive不成功需注意:**之前Hive初始化是在单机伪分布式状态下进行的,和现在集群状态不符,需要重新格式化HIve,删除MySQL的hive元数据库
#hive如果想重新配置的同学 #在配置完master的hive之后,不要初始化,根据情形进行下面操作 #情形一:如果单机节点没有配好,#按照Hive单机的安装步骤,在master配置完hive后,需要同步给slave1和slave2scp /usr/local/hive hadoop@slave1:/usr/local/scp /usr/local/hive hadoop@slave2:/usr/local/#同步系统环境变量scp /home/hadoop/.bashrc hadoop@slave1:/home/hadoopscp /home/hadoop/.bashrc hadoop@slave2:/home/hadoop#三个节点上刷新source /home/hadoop/.bashrc#情形二:单机已经成功,其他节点是克隆出来的#查看mysql数据里的hive元数据信息#查看默认的账号和密码,使用以下命令:sudo cat /etc/mysql/debian.cnfmysql -u debian-sys-maint -p #输入cat命令显示的密码#当前节点数据库有哪些show databases;#查看的密码#三个节点都要执行超级用户登录后,查看有没有hive的数据库,有的话删除drop database hive;#三个节点初始化操作schematool -dbType mysql -initSchema验证状态-Hive初始化成功:
再次执行查询数据库命令:
#测试能否成功连接数据库 sqoop list-databases --connect jdbc:mysql://master:3306/?useSSL=false --username sqoop --password 123456
1.3.4 使用前的数据准备
1.3.4.1 mysql数据准备(下面操作可在dbeaver中进行)
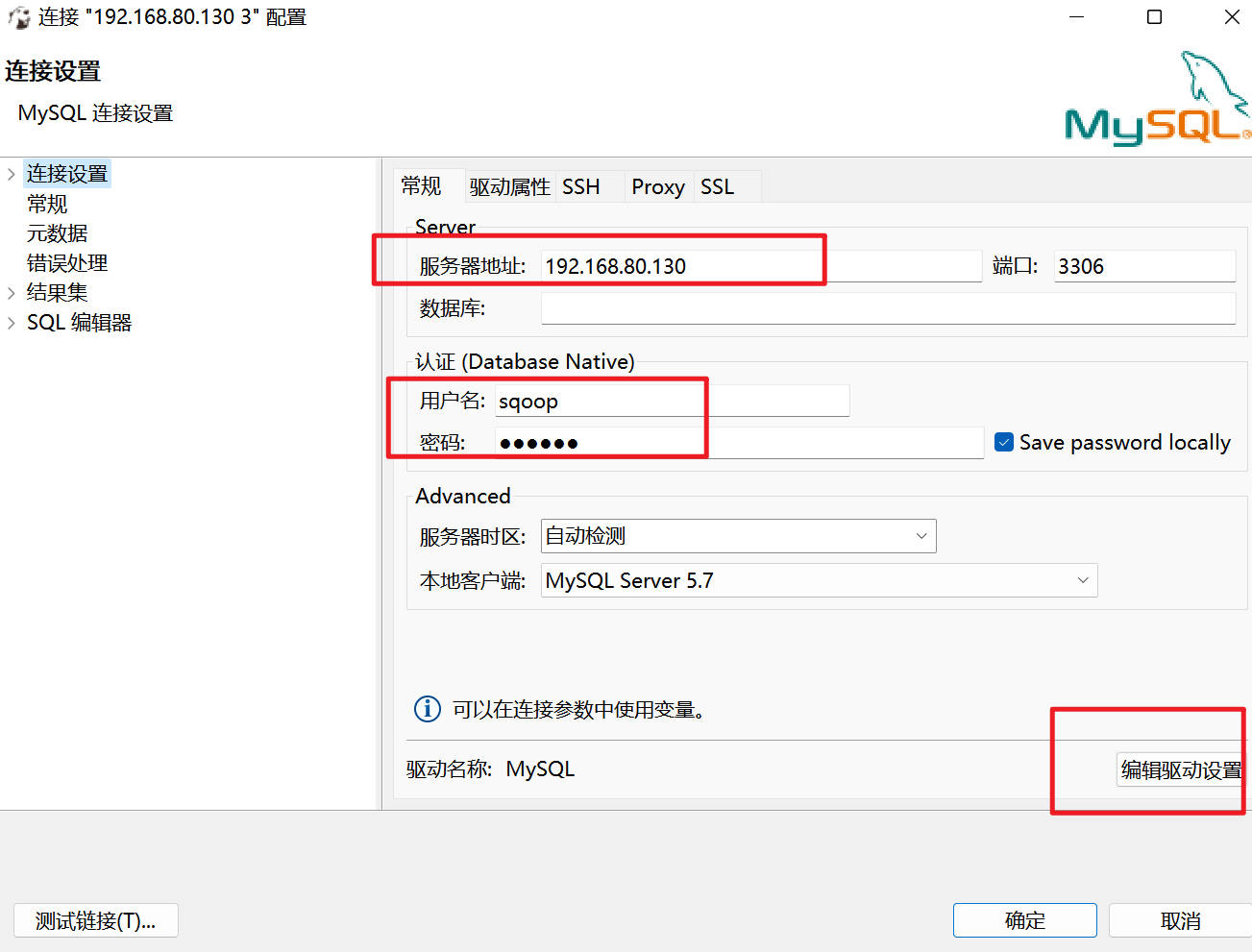
#(1)使用sqoop用户登录MySQL,使用以下命令:
#如果使用dbeaver连接MySQL,不用在输入这步命令了
mysql -u sqoop -p#(2)创建并使用使用sqoop数据库,使用以下命令:
create database sqoop
use sqoop#(3)创建student表用于演示导入MySQL数据到HDFS,使用以下命令:
CREATE TABLE IF NOT EXISTS `student`(
`id` int PRIMARY KEY COMMENT '编号',`name` varchar(20) COMMENT '名字',`age` int COMMENT '年龄'
)COMMENT '学生表';#(4) 向student表插入一些数据,使用以下命令:
INSERT INTO student VALUES(1, 'zhangsan', 20);
INSERT INTO student VALUES(2, 'lisi', 24);
INSERT INTO student VALUES(3, 'wangwu', 18);
INSERT INTO student VALUES(4, 'zhaoliui', 22);#(5) 创建student2表用于装载Hive导出的数据,使用以下命令:
CREATE TABLE IF NOT EXISTS `student2`(
`id` int PRIMARY KEY COMMENT '编号',
`name` varchar(20) COMMENT '名字',
`age` int COMMENT '年龄'
)COMMENT '学生表';
dbeaver远程登录MySQL失败:
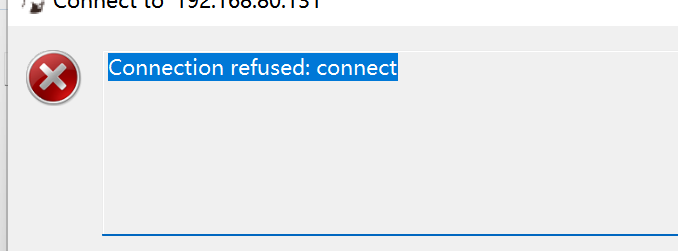
#查看状态
sudo ufw status
#查看端口
netstat -an | grep 3306#编辑端口
#注释掉43行的bind-address
sudo vim /etc/mysql/mysql.conf.d/mysqld.cnf
#bind-address = 127.0.0.1##修改端口,需要重启虚拟机
sudo reboot
数据准备完成后:
- student表:
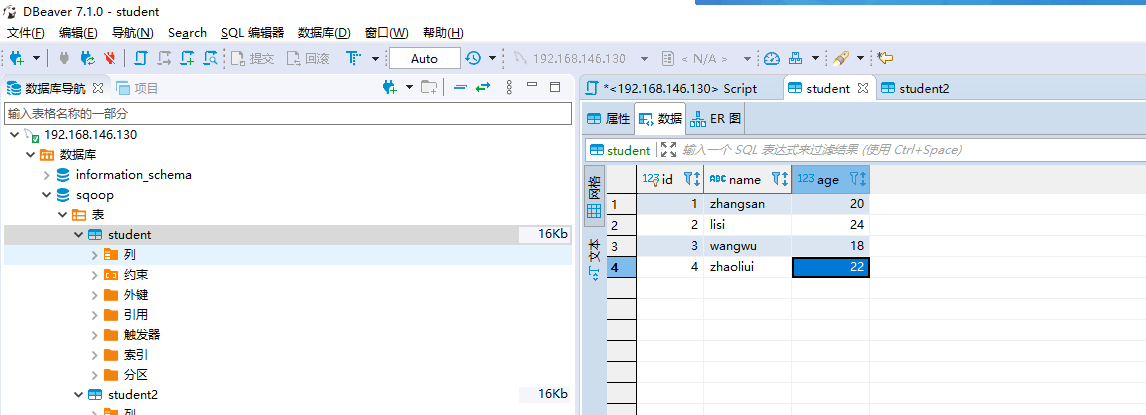
- student2表:
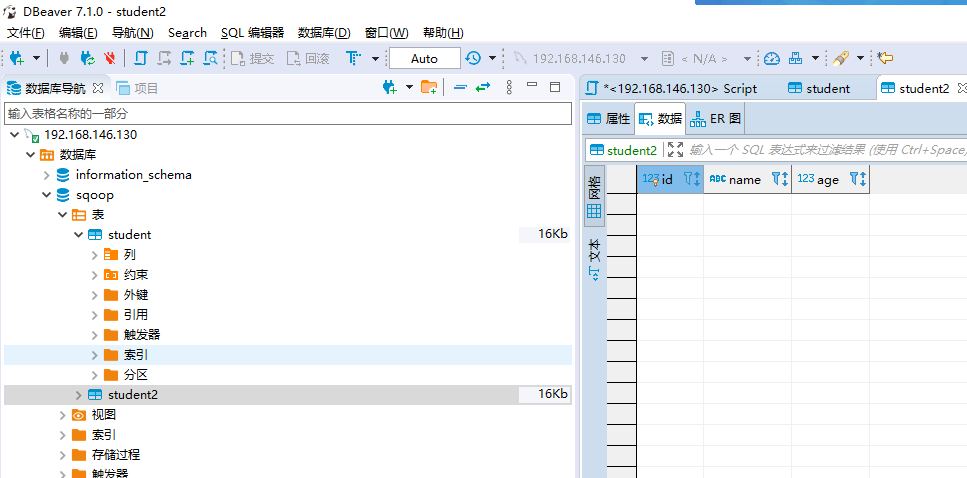
1.3.4.2 Hive的准备(也在dbeaver中执行):
--(1) 启动hive,使用以下命令:
hiveserver2
--(2) 打开DBeaver连接Hive--(3) 创建sqoop数据库,使用以下命令:
CREATE DATABASE sqoop;--(4) 使用sqoop数据库,使用以下命令:
USE sqoop;--(5) 创建student表用于装载MySQL导入的数据,使用以下命令:
CREATE TABLE IF NOT EXISTS student(id INT COMMENT '编号',name STRING COMMENT '名字',age INT COMMENT '年龄'
) COMMENT '学生表'
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ' ';
- 如果搭建完HadoopHA后在启动Hive报错
hive启动时,提示java.net.UnknownHostException:ns
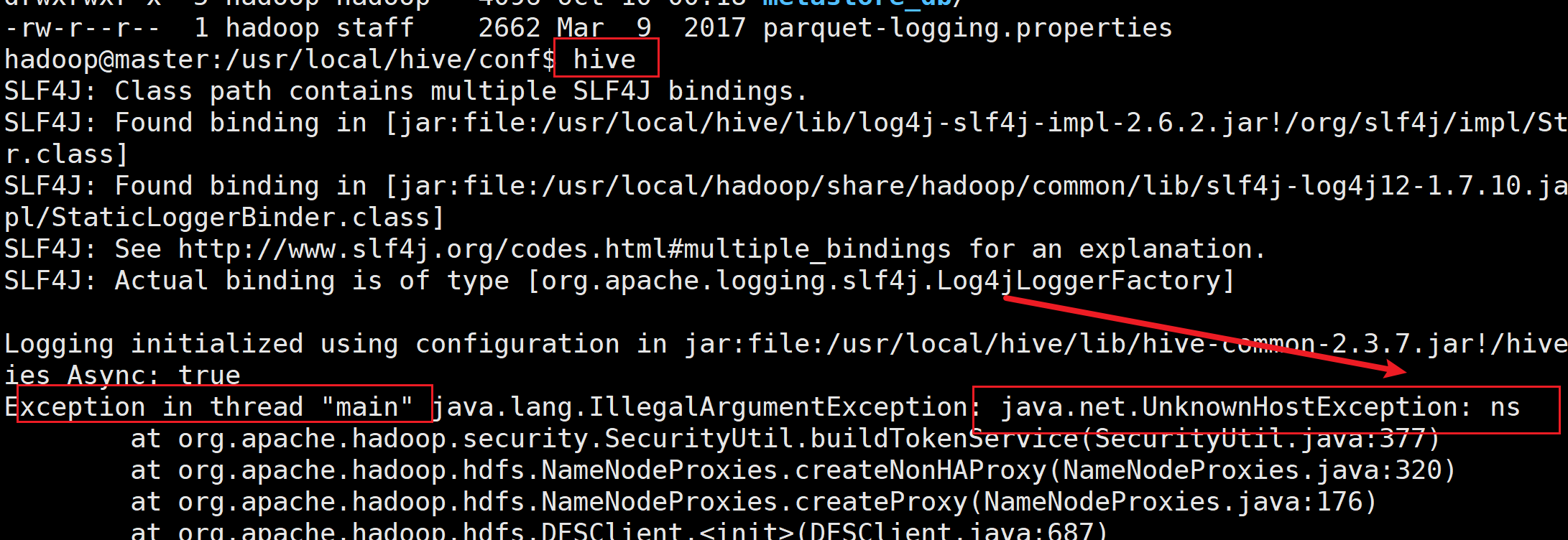
注意复制HDFS的core-site.xml和hdfs-site.xml到hive目录的conf下面
cp /usr/local/hadoop/etc/hadoop/hdfs-site.xml /usr/local/hive/conf
cp /usr/local/hadoop/etc/hadoop/core-site.xml /usr/local/hive/conf
1.5 Sqoop命令
Sqoop 的常用命令
| 命令 | 说明 |
|---|---|
| list-databases | 列出所有数据库名 |
| list-tables | 列出某个数据库下所有表 |
| import | 将数据导入到 HDFS 集群,hive,hbase,hdfs本身等等 |
| export | 将 HDFS 集群数据导出 |
| help | 打印 sqoop 帮助信息 |
| version | 打印 sqoop 版本信息 |
Sqoop 的公共参数
| 命令 | 说明 |
|---|---|
| –connect | 连接关系型数据库的URL |
| –username | 连接数据库的用户名 |
| –password | 连接数据库的密码 |
Sqoop的 import 命令参数
| 参数 | 说明 |
|---|---|
| –fields-terminated-by | Hive中的列分隔符,默认是逗号 |
| –lines-terminated-by | Hive中的行分隔符,默认是\n |
| –append | 将数据追加到HDFS中已经存在的DataSet中,如果使用该参数,sqoop会把数据先导入到临时文件目录,再合并。 |
| –columns | 指定要导入的字段 |
| –m或–num-mappers | 启动N个map来并行导入数据,默认4个。 |
| –query或**–e** | 将查询结果的数据导入,使用时必须伴随参–target-dir,–hive-table,如果查询中有where条件,则条件后必须加上$CONDITIONS关键字 |
| –table | 关系数据库的表名 |
| –target-dir | 指定导入数据存储的HDFS路径 |
| –null-string | string类型的列如果null,替换为指定字符串 |
| –null-non-string | 非string类型的列如果null,替换为指定字符串 |
| –check-column | 作为增量导入判断的列名 |
| –incremental | mode:append或lastmodified |
| –last-value | 指定某一个值,用于标记增量导入的位置 |
Sqoop 的 export 命令参数
| 参数 | 说明 |
|---|---|
| –input-fields-terminated-by | Hive中的列分隔符,默认是逗号 |
| –input-lines-terminated-by | Hive中的行分隔符,默认是\n |
| –export-dir | 存放数据的HDFS的源目录 |
| -m或–num-mappers | 启动N个map来并行导出数据,默认4个 |
| –table | 指定导出到哪个RDBMS中的表 |
| –update-key | 对某一列的字段进行更新操作 |
| –update-mode | updateonly或allowinsert(默认) |
Sqoop 的命令案例
- 导入到HDFS
#查看MySQL中已有的数据库名称
sqoop list-databases --connect jdbc:mysql://localhost:3306/ --username sqoop --password 123456#查看MySQL中Sqoop数据库中的表,使用以下命令
sqoop list-tables --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456#导入全部MySQL数据到HDFS,执行以下命令
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student --delete-target-dir -m 1#执行完成后,去HDFS查看数据是否导入成功,使用以下命令:
hdfs dfs -cat /user/student/part-m-00000#导入部分mysql数据到HDFS(导入时筛选)
#-- query不与--table同时使用
#必须在where后面加上$CONDITIONS
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --target-dir /user/student --delete-target-dir -m 1 --query 'select * from student where age <20 and $CONDITIONS'
查看–target-dir指定的路径
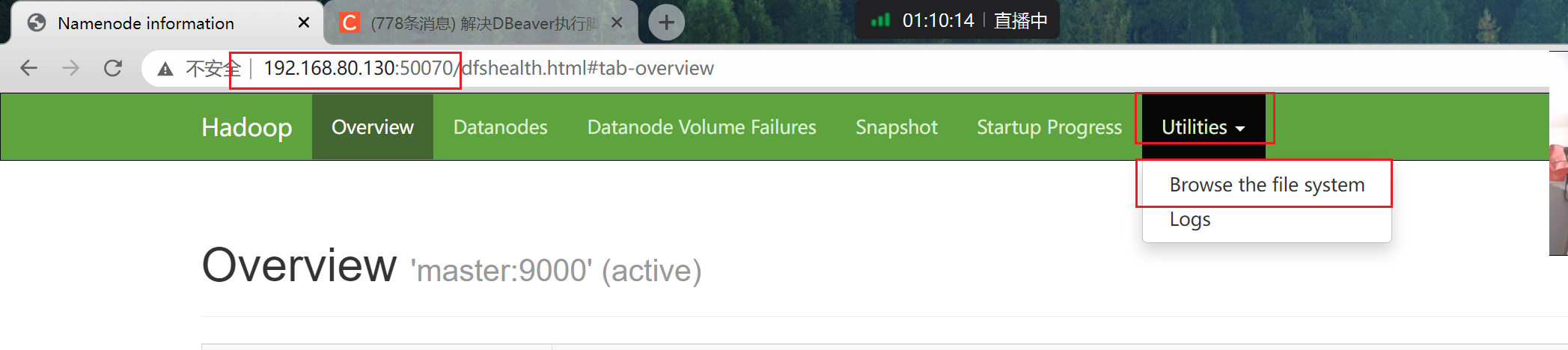
-
导入到Hive
#导入MySQL数据到hive sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student2 --delete-target-dir --hive-import --fields-terminated-by " " --columns id,name,age --hive-overwrite --hive-table sqoop.student -m 1#导入部分MySQL数据到hive(覆盖导入) sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --target-dir /user/student2 --delete-target-dir -m 1 --query 'select * from student where age <20 and $CONDITIONS' --hive-import --fields-terminated-by " " --columns id,name,age --hive-overwrite --hive-table sqoop.student2 #增量导入部分MySQL数据到hive #--incremental append不能和--delete-target-dir一起用 sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student --target-dir /user/student2 --hive-import --fields-terminated-by " " --columns id,name,age --hive-table sqoop.student2 --check-column id --incremental append --last-value 3 -m 1-
问题:导入数据权限不足,导入hive失败
-
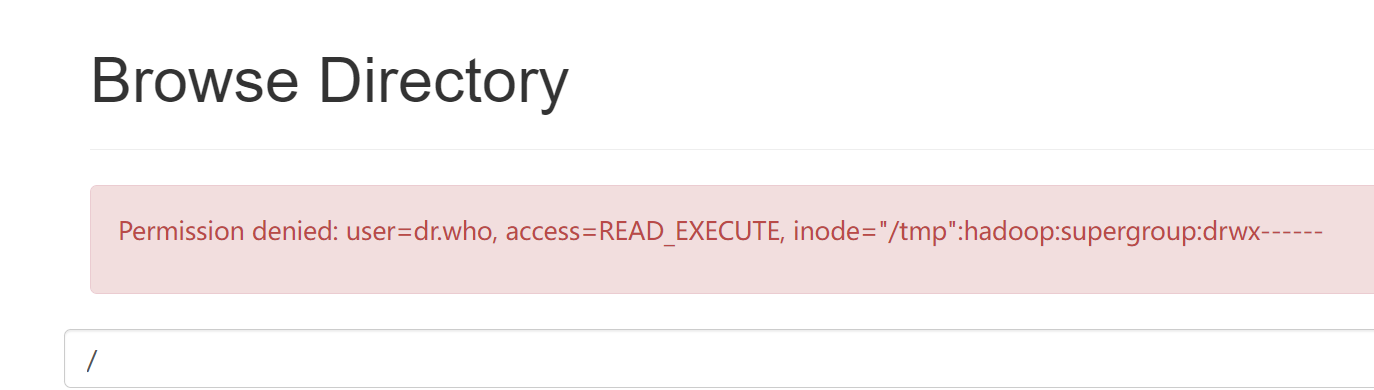
-
Hdfs页面操作文件出现 Permission denied: user=dr.who,
-
#在xshell hdfs dfs -chmod -R 755 /
-
-
-
-
导入到HBase
#导入数据到HBase,需要提前创建对应的表student
#导入数据之前
hbase shell
create 'student','info'#开始执行导入命令
sqoop import --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 -table student -hbase-table "student" --hbase-row-key "id" --column-family "info" --columns "id,name,age" --split-by id -m -1
- Hive导出到MySQL
#Sqoop 的导出命令案例
sqoop export --connect jdbc:mysql://localhost:3306/sqoop --username sqoop --password 123456 --table student2 --export-dir /usr/local/hive/warehouse/sqoop.db/student --input-fields-terminated-by " " -m 1

2. Flume
2.1Flume简介
-
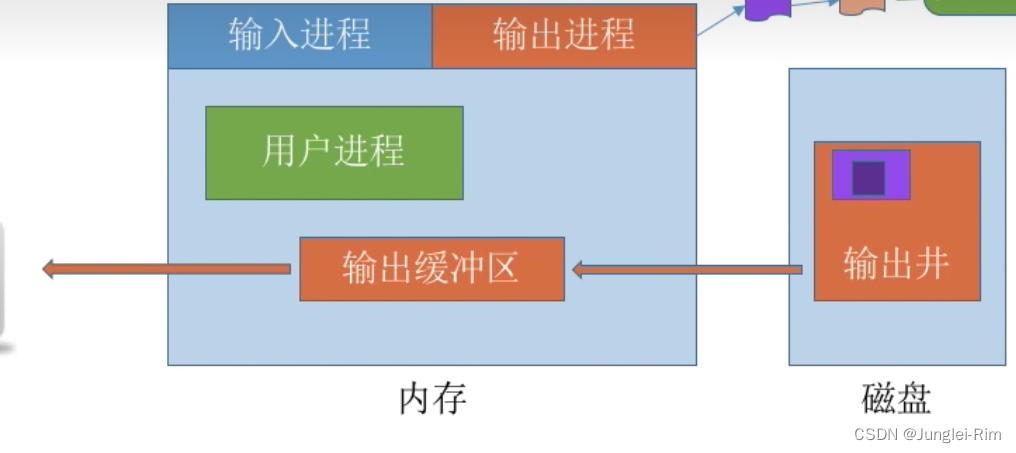
Flume是一个分布式的、高可靠的、高可用的将大批量的不同数据源的日志数据收集、聚合、移动**到数据中心(**HDFS)进行存储的系统
-
1、可以高速采集数据,采集的数据能够以想要的文件格式及压缩方式存储在hdfs上;
-
2、事务功能保证了数据在采集的过程中数据不丢失;
- 原子性
-
3、部分Source保证了Flume挂了以后重启依旧能够继续在上一次采集点采集数据,真正做到数据零丢失。
-
2.2Flume架构
- Agent 是 Flume 中最小的独立运行单位,一个 agent 就是一个 JVM(java虚拟机)
- 含有三个核心组件,分别是 source、channel 和 sink
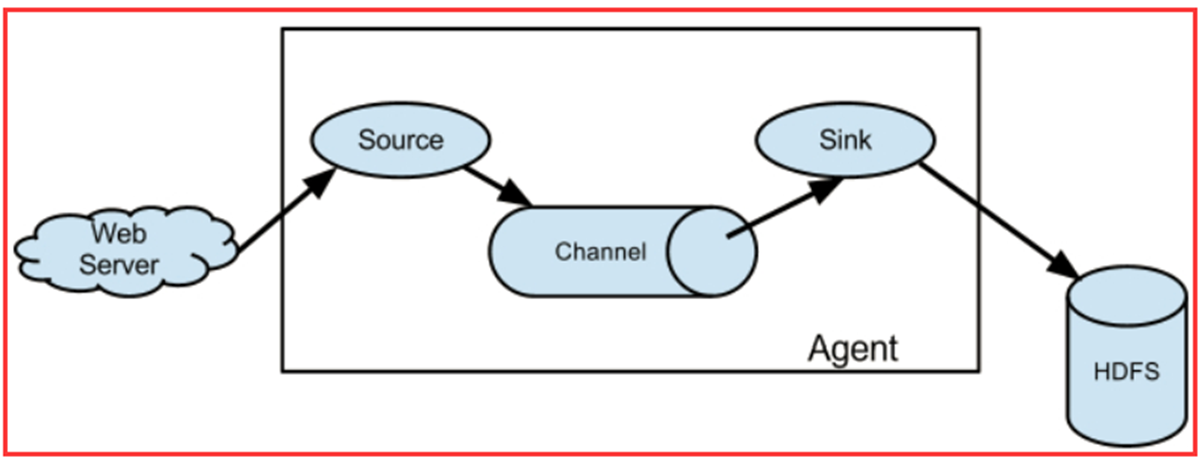
2.3 Flume安装
#下载、上传、解压、重命名和授权
https://mirrors.tuna.tsinghua.edu.cn/apache/flume/1.9.0/apache-flume-1.9.0-bin.tar.gz#上传到 /home/hadoop 目录
sudo tar -xvf apache-flume-1.9.0-bin.tar.gz -C /usr/localsudo mv /usr/local/apache-flume-1.9.0-bin/ /usr/local/flumesudo chown -R hadoop /usr/local/flume
2.4 Flume配置
配置环境变量
#编辑环境变量
vim /home/hadoop/.bashrc#在环境变量最后添加以下内容
export FLUME_HOME=/usr/local/flume
export PATH=$PATH:$FLUME_HOME/bin#刷新环境变量
source /home/hadoop/.bashrc
配置 Agent
# 为 agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1# 设置 a1 的 channels 叫做 c1
a1.channels = c1
配置Source
# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command = tail -F /home/hadoop/tail-test.txt
配置 Channel
- 两种常见类型:MemoryChannel和FileChannel
# 设置 c1 的类型是 memory
a1.channels.c1.type = memory# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100
配置 Sink
# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs
# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text
# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true
组装 Source、Channel 和 Sink
# 设置 r1 连接 c1
a1.sources.r1.channels = c1# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
2.5 Flume使用
了解tail -F的命令
#(1)进入/home/hadoop目录,使用以下命令:
cd /home/hadoop/
#(2)创建touch tail-test.txt文件,使用以下命令:
touch tail-test.txt
#(3)向tail-test.txt文件中追加一些内容,使用以下命令:
echo 'hello 11111' >> tail-test.txt
echo 'hello 22222'>> tail-test.txt
echo 'hello 33333'>> tail-test.txt
#(4)查看tail-test.txt文件中的内容,使用以下命令:
cat tail-test.txt
#(5)复制(新开)一个xshell窗口监控tail-test.txt文件内容的变化,使用以下命令:
tail -F tail-test.txt
#(6)回到上一个xshell窗口,继续向tail-test.txt文件中追加一些内容,使用以下命令:
echo 'hello 44444' >> tail-test.txt
echo 'hello 55555'>> tail-test.txt
echo 'hello 66666'>> tail-test.txt
#查看tail -F命令是否监控到内容的变化
使用flume
目标:把tail-test.txt文件中新增的内容给采集到HDFS
#搭配着Flume把tail-test.txt文件中新增的内容给采集到HDFS上。
#(1)新开一个xshell窗口,创建exec-memory-hdfs.properties文件,使用以下命令:
touch exec-memory-hdfs.properties
#(2)编辑touch exec-memory-hdfs.properties文件,填写以下内容:
sudo vim exec-memory-hdfs.properties
# 单节点的 flume 配置文件
# 为 agent 起个名字叫做 a1
# 设置 a1 的 sources 叫做 r1
a1.sources = r1# 设置 a1 的 sinks 叫做 k1
a1.sinks = k1# 设置 a1 的 channels 叫做 c1
a1.channels = c1# 设置 r1 的类型是 exec,用于采集命令产生的数据
a1.sources.r1.type = exec# 设置 r1 采集 tail -F 命令产生的数据
a1.sources.r1.command = tail -F /home/hadoop/tail-test.txt# 设置 c1 的类型是 memory
a1.channels.c1.type = memory# 设置 c1 的缓冲区容量
a1.channels.c1.capacity = 1000
a1.channels.c1.transactionCapacity = 100# 设置 k1 的类型是 hdfs
a1.sinks.k1.type = hdfs# 设置 k1 输出路径,按照时间在 hdfs 上创建相应的目录
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-# 设置 k1 输出的数据保存为文本
a1.sinks.k1.hdfs.fileType = DataStream
a1.sinks.k1.hdfs.writeFormat = Text# 把时间戳放入数据的头中
a1.sinks.k1.hdfs.useLocalTimeStamp = true# 设置 r1 连接 c1
a1.sources.r1.channels = c1# 设置 k1 连接 c1
a1.sinks.k1.channel = c1
启动 Flume
- 启动三个节点zookeeper
zkServer.sh start
- 先启动hdfs和yarn
start-dfs.sh
start-yarn.sh
- 启动 Flume
#启动 Flume
flume-ng agent -n a1 -c conf -f /home/hadoop/exec-memory-hdfs.properties
验证flume
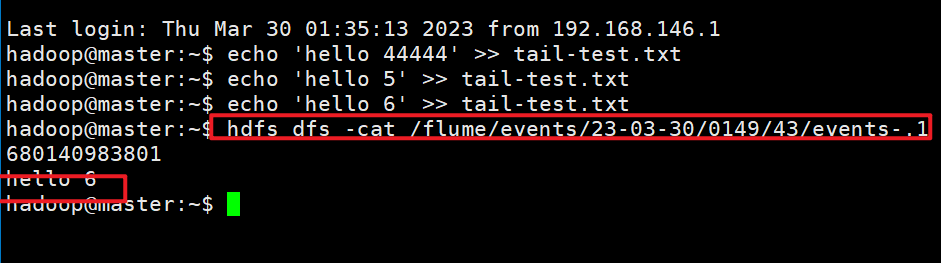
#(4)在第一个xshell窗口大量的向tail-test.txt文件中追加数据
echo 'hello 44444' >> tail-test.txt
echo 'hello 55555' >> tail-test.txt
echo 'hello 6666' >> tail-test.txt#2. 在xshell里,使用命令
hdfs dfs -cat /flume/events/目录的名称/文件名,可以看到数据
- 去HDFS的web监控页面查看是否采集到数据
- 能看到有新生成的目录
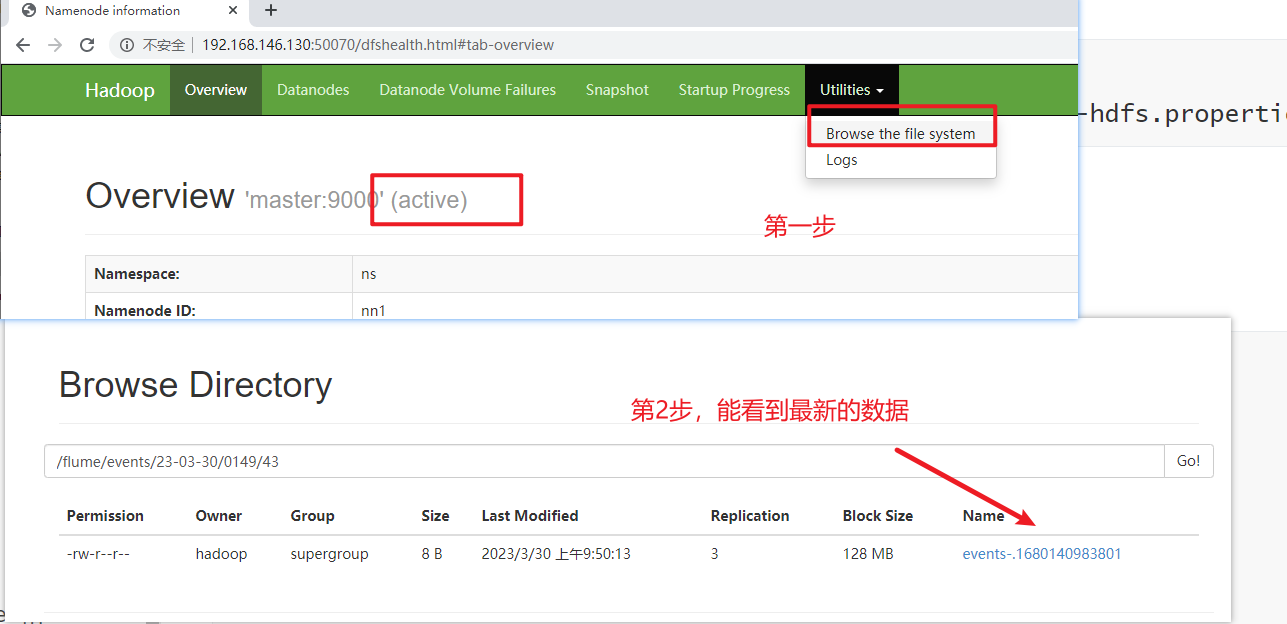
-
在xshell里,使用命令
hdfs dfs -cat /flume/events/目录的名称/文件名,可以看到数据