使用msigdbr r包
#BiocManager::install("msigdb")
#https://www.gsea-msigdb.org/gsea/msigdb
#https://cran.r-project.org/web/packages/msigdbr/vignettes/msigdbr-intro.html
#https://bioconductor.org/packages/release/data/experiment/vignettes/msigdb/inst/doc/msigdb.html#the-molecular-signatures-database-msigdb
#https://www.gsea-msigdb.org/gsea/msigdb/collections.jsp
library(msigdb)library(ExperimentHub)
library(GSEABase)
#6提取并制备人的hallmarks列表---------
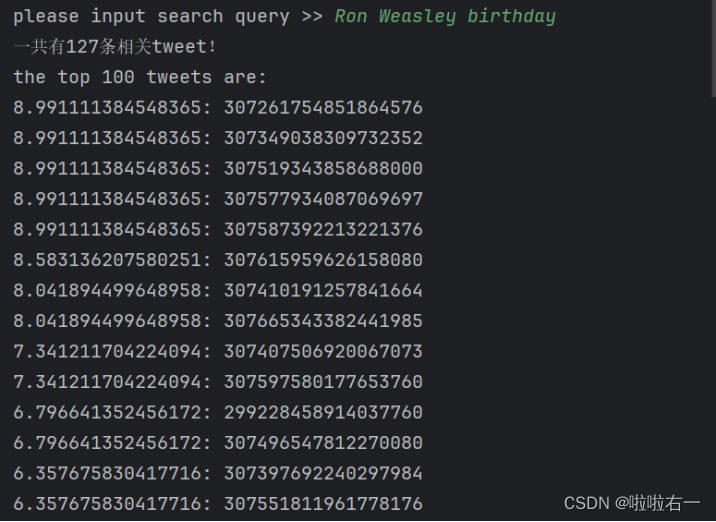
all_gene_sets_hs = msigdbr::msigdbr(species = "Homo sapiens") #Mus musculusall_gene_sets_hs
all_gene_sets_hs$gs_name %>%table()
all_gene_sets_hs$gs_cat %>%table()
all_gene_sets_hs$gs_subcat %>%table()
all_gene_sets_hs$gs_id %>%table() %>%tail()all_gene_sets_hs_list=split(x = all_gene_sets_hs$gene_symbol,f=all_gene_sets_hs$gs_name )all_gene_sets_hs_list
length(all_gene_sets_hs_list)MSIGDB_CANONICAL= all_gene_sets_hs %>% dplyr::filter(gs_cat=="H")
MSIGDB_CANONICALMSIGDB_CANONICAL_list=split(x=MSIGDB_CANONICAL$gene_symbol,f = MSIGDB_CANONICAL$gs_name)length(MSIGDB_CANONICAL_list)

完整代码如下
.libPaths(c("/home/data/t040413/R/x86_64-pc-linux-gnu-library/4.2","/home/data/t040413/R/yll/usr/local/lib/R/site-library", "/usr/local/lib/R/library","/home/data/refdir/Rlib/"))#BiocManager::install("msigdb")
#https://www.gsea-msigdb.org/gsea/msigdb
#https://cran.r-project.org/web/packages/msigdbr/vignettes/msigdbr-intro.html
#https://bioconductor.org/packages/release/data/experiment/vignettes/msigdb/inst/doc/msigdb.html#the-molecular-signatures-database-msigdb
#https://www.gsea-msigdb.org/gsea/msigdb/collections.jsp
library(msigdb)library(ExperimentHub)
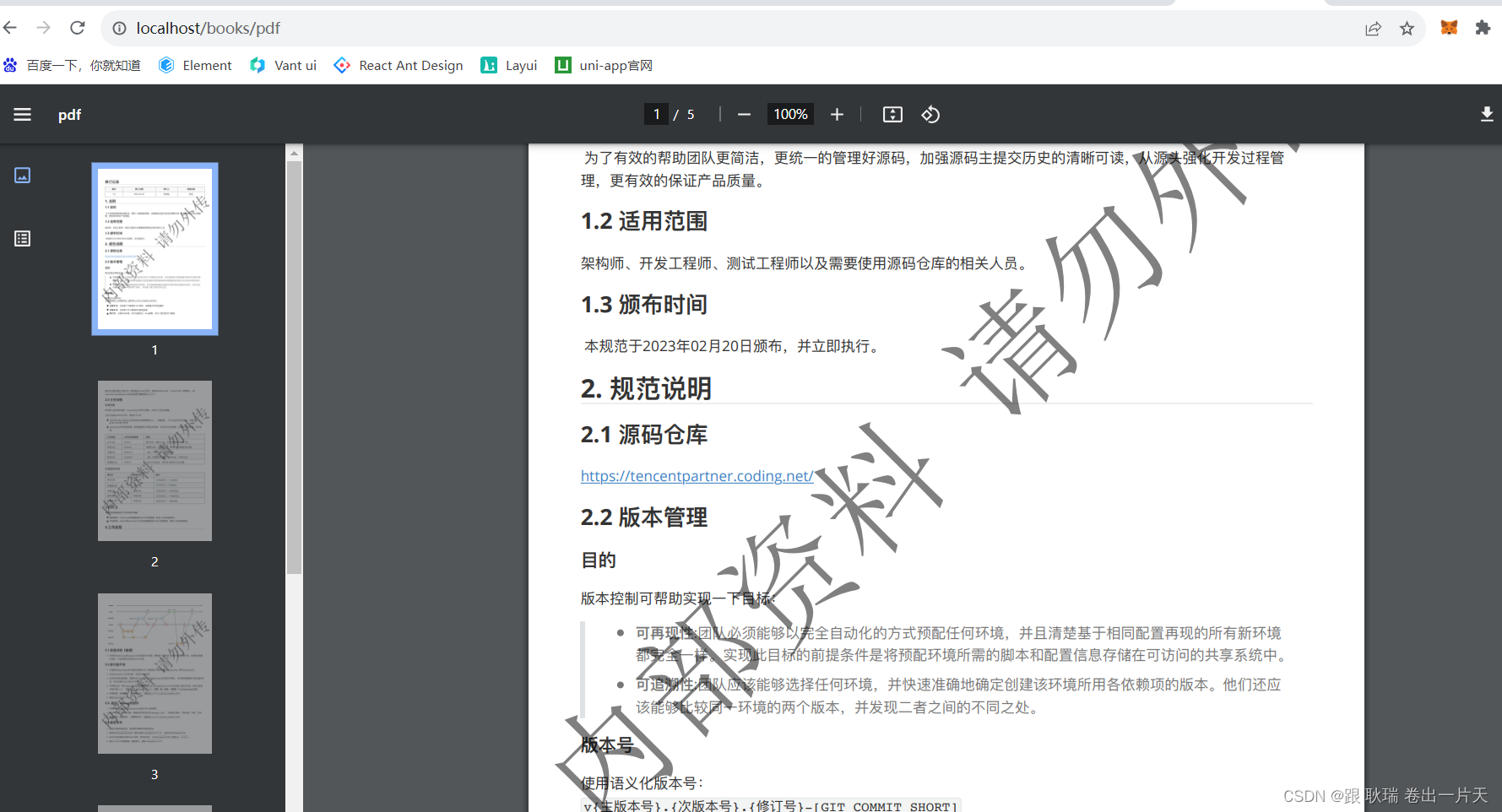
library(GSEABase)#To download the data, we first need to get a list of the data available in the msigdb package and determine the unique identifiers for each data. The query() function assists in getting this list.1#1 获取总的基因集合的名字--------
eh = ExperimentHub()
all_gene_sets_name=query(eh , 'msigdb')
all_gene_sets_name#Data can then be downloaded using the unique identifier.
eh[['EH5421']]#use the custom accessor to select a specific version of MSigDB
msigdb.hs = getMsigdb(org = 'hs', id = 'SYM', version = '7.4')
msigdb.hs#Each signature is stored in a GeneSet object and can be processed using functions in the GSEABase R/Bioconductor package.gs = msigdb.hs[[1000]]
gs
geneIds(gs)#get collection type
collectionType(gs)#get MSigDB category
bcCategory(collectionType(gs))#get MSigDB subcategory
bcSubCategory(collectionType(gs))#get description
description(gs)#calculate the number of signatures in each category
table(sapply(lapply(msigdb.hs, collectionType), bcCategory))#calculate the number of signatures in each subcategory
table(sapply(lapply(msigdb.hs, collectionType), bcSubCategory))#plot the distribution of sizes
hist(sapply(lapply(msigdb.hs, geneIds), length),main = 'MSigDB signature size distribution',xlab = 'Signature size')listCollections(msigdb.hs)
#> [1] "c1" "c2" "c3" "c4" "c5" "c6" "c7" "c8" "h"
listSubCollections(msigdb.hs)#retrieeve the hallmarks gene sets
subsetCollection(msigdb.hs, 'h')#retrieve the biological processes category of gene ontology
subsetCollection(msigdb.hs, 'c5', 'GO:BP')#4提取所有人类基因集合数据----------
all_species=msigdbr::msigdbr_species()
all_species
all_gene_sets_hs = msigdbr::msigdbr(species = "Homo sapiens") #Mus musculushead(all_gene_set_hs)#查看所有的collections------
all_collections=msigdbr::msigdbr_collections()
all_collections#5 提取人 鼠 特定的ollection------
#You can retrieve data for a specific collection, such as the hallmark gene sets.m_gene_sets = msigdbr::msigdbr(species = "mouse", category = "H")
head(m_gene_sets)h_gene_sets = msigdbr::msigdbr(species = "human", category = "H")
head(h_gene_sets)h_gene_sets$gs_name#6提取并制备人的hallmarks列表---------
all_gene_sets_hs = msigdbr::msigdbr(species = "Homo sapiens") #Mus musculus
#saveRDS(all_gene_sets_hs,file="~/datasets/all_gene_sets_hs_msigdb.rds")all_gene_sets_hs
all_gene_sets_hs$gs_name %>%table()
all_gene_sets_hs$gs_cat %>%table()
all_gene_sets_hs$gs_subcat %>%table()
all_gene_sets_hs$gs_id %>%table() %>%tail()
all_gene_sets_hs_list=split(x = all_gene_sets_hs$gene_symbol,f=all_gene_sets_hs$gs_name )
all_gene_sets_hs_list
length(all_gene_sets_hs_list)
MSIGDB_CANONICAL= all_gene_sets_hs %>% dplyr::filter(gs_cat=="H")
MSIGDB_CANONICAL
MSIGDB_CANONICAL_list=split(x=MSIGDB_CANONICAL$gene_symbol,f = MSIGDB_CANONICAL$gs_name)
length(MSIGDB_CANONICAL_list)
names(MSIGDB_CANONICAL_list)#saveRDS(MSIGDB_CANONICAL_list,file = "~/datasets/Genesets_Dec19.rds")





![buuctf_练[GYCTF2020]FlaskApp](https://img-blog.csdnimg.cn/img_convert/16756c3a126348e1e74c0cd16fa55e0f.png)