一、redis 的线程模型
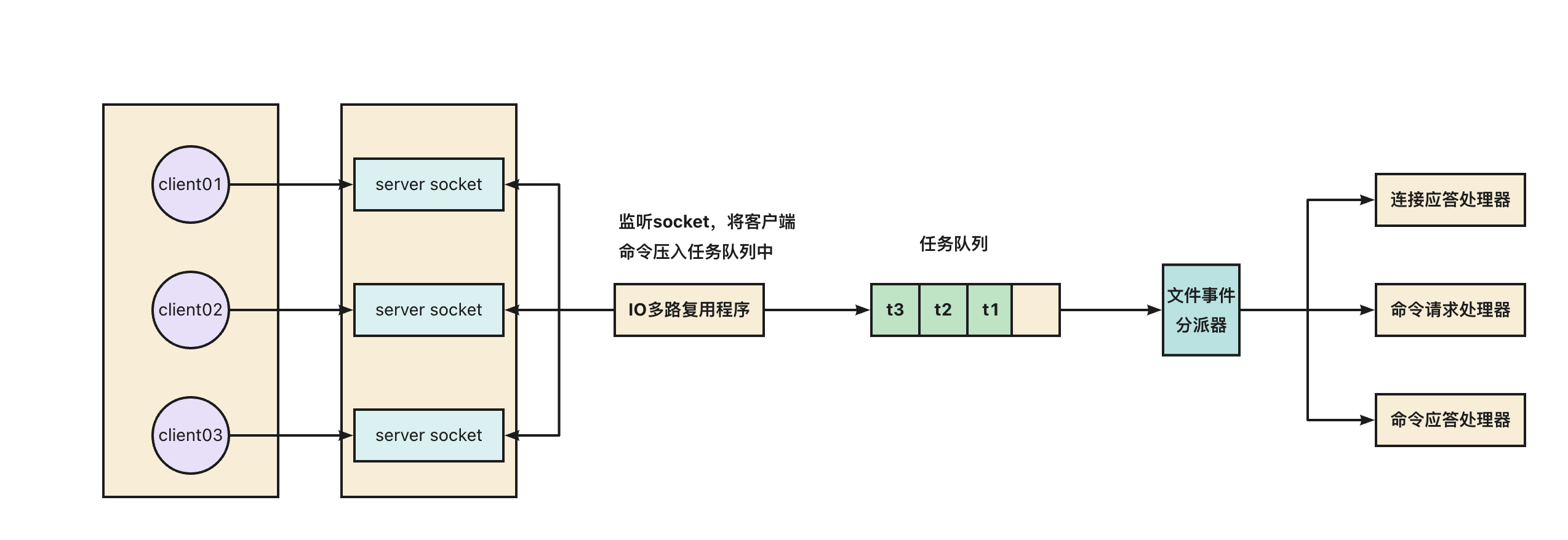
redis 内部使用文件事件处理器 file event handler,它是单线程的,所以redis才叫做单线程模型。它采用IO多路复用机制同时监听多个 socket,将产生事件的 socket 压入内存队列中,事件分派器根据 socket 上的事件类型来选择对应的事件处理器进行处理。
1.1 文件事件处理器的结构
- 多个 socket
- IO 多路复用程序
- 文件事件分派器
- 事件处理器(连接应答处理器、命令请求处理器、命令回复处理器)
1.2 线程模型
多个 socket 可能会并发产生不同的操作,每个操作对应不同的文件事件,但是 IO多路复用程序会监听多个 socket,会将产生事件的 socket 放入队列中排队,事件分派器每次从队列中取出一个 socket,根据 socket 的事件类型交给对应的事件处理器进行处理。
1.3 使用单线程网络模型的好处
避免过多的上下文切换开销
多线程调度过程中必然需要在 CPU 之间切换线程上下文 context,而上下文的切换是有开销的。单线程则可以规避进程内频繁的线程切换开销,因为程序始终运行在进程中单个线程内,没有多线程切换的场景。
避免同步机制的开销
如果 Redis 选择多线程模型,势必涉及到底层数据同步的问题,必然会引入某些同步机制,比如锁,而我们知道 Redis 不仅仅提供了简单的 key-value 数据结构,还有 list、set 和 hash 等等其他丰富的数据结构,而不同的数据结构对同步访问的加锁粒度又不尽相同,可能会导致在操作数据过程中带来很多加锁解锁的开销,增加程序复杂度的同时还会降低性能。
简单可维护
Redis 的作者 Salvatore Sanfilippo (别称 antirez) 对 Redis 的设计和代码有着近乎偏执的简洁性理念。因此代码的简单可维护性必然是 Redis 早期的核心准则之一,而引入多线程必然会导致代码的复杂度上升和可维护性下降。前面我们提到引入多线程必须的同步机制,如果 Redis 使用多线程模式,那么所有的底层数据结构都必须实现成线程安全的,这无疑又使得 Redis 的实现变得更加复杂。总而言之,Redis 选择单线程可以说是多方博弈之后的一种权衡:在保证足够的性能表现之下,使用单线程保持代码的简单和可维护性。
在 v6.0 版本之前,Redis 的核心网络模型一直是一个典型的单 Reactor 模型:利用 epoll/select/kqueue 等多路复用技术,在单线程的事件循环中不断去处理事件(客户端请求),最后回写响应数据到客户端:

- aeEventLoop:这是 Redis 自己实现的一个高性能事件库,里面封装了适配各个系统的 I/O多路复用(I/O multiplexing),EventLoop除了 处理socket 的读写事件外,还要处理一些定时任务。aeEventLoop本质是一个线程,服务启动时就一直循环,调用 aeProcessEvent 处理文件(网络)或者时间事件;等价于Java中NIO的select线程
- client :代表一个客户端连接。Redis 是典型的 CS 架构(Client <—> Server),客户端通过 socket 与服务端建立网络通道然后发送请求命令,服务端执行请求的命令并回复。Redis 使用结构体 client 存储客户端的所有相关信息,包括但不限于封装的套接字连接 – conn,当前选择的数据库指针 –db,读入缓冲区 – querybuf,写出缓冲区 – buf,写出数据链表 – reply等;
- acceptTcpHandler:角色 Acceptor 的实现,当有新的客户端连接时会调用这个方法,它会调用系统 accept 创建一个 socket 对象,同时创建 client 对象,并将 socket 添加到 EventLoop 的监听列表中(等价于NIO中注册socket到select上),并注册当对应的读事件发生时的回调函数 readQueryFromClient:即绑定 Handler,这样当该客户端发起请求时,就会调用对应的回调函数处理请求;
- readQueryFromClient:角色 Handler 的实现,主要负责解析并执行客户端的命令请求,并将结果写到对应的 client->buf 或者 client->reply 中;
- beforeSleep:事件循环之前的操作,主要执行一些常规任务,比如将 client 中的数据写会给客户端、进行一些持久化任务(AOF 或者RDB操作,主从同步)等。
下面我们描绘一下 客户端client 与 Redis server 建立连接、发起请求到接收到返回的整个过程:
- 首先Redis 服务器启动,开启主线程事件循环 aeMain,注册 acceptTcpHandler 连接应答处理器到用户配置的监听端口对应的文件描述符,等待新连接到来;
- 客户端和服务端建立网络连接,acceptTcpHandler 被调用,主线程将 readQueryFromClient 命令读取处理器绑定到新连接对应的文件描述符上作为对应事件发生时的回调函数,并初始化一个 client 绑定这个客户端连接;
- 客户端发送请求命令,触发读就绪事件,主线程调用 readQueryFromClient 通过 socket 读取客户端发送过来的命令存入 client->querybuf 读入缓冲区;
- 接着调用 processInputBuffer,在其中使用 processInlineBuffer 或者 processMultibulkBuffer 根据 Redis 协议解析命令,最后调用 processCommand 执行命令;
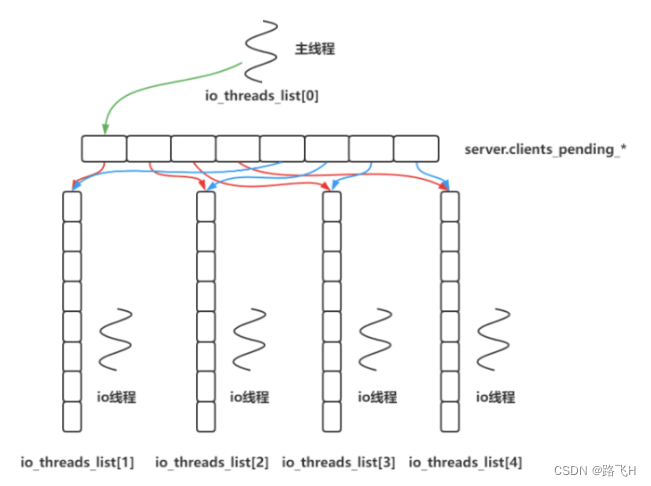
- 根据请求命令的类型(SET, GET, DEL, EXEC 等),分配相应的命令执行器去执行,最后调用 addReply 函数族的一系列函数将响应数据写入到对应 client 的写出缓冲区:client->buf 或者 client->reply ,client->buf 是首选的写出缓冲区,固定大小 16KB,一般来说可以缓冲足够多的响应数据,但是如果客户端在时间窗口内需要响应的数据非常大,那么则会自动切换到 client->reply链表上去,使用链表理论上能够保存无限大的数据(受限于机器的物理内存),最后把 client 添加进一个 LIFO 队列 clients_pending_write;
- 在事件循环 aeMain 中,主线程执行 beforeSleep --> handleClientsWithPendingWrites,遍历 clients_pending_write 队列,调用 writeToClient 把 client 的写出缓冲区里的数据回写到客户端,如果写出缓冲区还有数据遗留,则注册 sendReplyToClient 命令回复处理器到该连接的写就绪事件,等待客户端可写时在事件循环中再继续回写残余的响应数据。
二、一次客户端与redis的完整通信过程图解
2.1 建立连接
- 首先,redis 服务端进程初始化的时候,会将 server socket 的 AE_READABLE 事件与连接应答处理器关联。
- 客户端 socket01 向 redis 进程的 server socket 请求建立连接,此时 server socket 会产生一个 AE_READABLE 事件,IO 多路复用程序监听到 server socket 产生的事件后,将该 socket 压入队列中。
- 文件事件分派器从队列中获取 socket,交给连接应答处理器。
- 连接应答处理器会创建一个能与客户端通信的 socket01,并将该 socket01 的 AE_READABLE 事件与命令请求处理器关联。
2.2 执行一个set请求
- 客户端发送了一个 set key value 请求,此时 redis 中的 socket01 会产生 AE_READABLE 事件,IO 多路复用程序将 socket01 压入队列,
- 此时事件分派器从队列中获取到 socket01 产生的 AE_READABLE 事件,由于前面 socket01 的 AE_READABLE 事件已经与命令请求处理器关联,
- 因此事件分派器将事件交给命令请求处理器来处理。命令请求处理器读取 socket01 的 key value 并在自己内存中完成 key value 的设置。
- 操作完成后,它会将 socket01 的 AE_WRITABLE 事件与命令回复处理器关联。
- 如果此时客户端准备好接收返回结果了,那么 redis 中的 socket01 会产生一个 AE_WRITABLE 事件,同样压入队列中,
- 事件分派器找到相关联的命令回复处理器,由命令回复处理器对 socket01 输入本次操作的一个结果,比如 ok,之后解除 socket01 的 AE_WRITABLE 事件与命令回复处理器的关联。

三、redis为什么效率这么高?
- 纯内存操作。
- 核心是基于非阻塞的 IO 多路复用机制。
- C 语言实现,语言更接近操作系统,执行速度相对会更快。
- 单线程反而避免了多线程的频繁上下文切换问题,预防了多线程可能产生的竞争问题。
参考:中华石衫老师的亿级流量电商详情页缓存架构设计教程