逆合成旨在找到一系列合适的反应物,以高效合成目标产物。这是解决有机合成路线的重要方法,也是有机合成路线设计的最简单、最基本的方法。
早期的逆合成研究多依赖编程,随后这一工作被 AI 接替。然而,现有的逆合成方法多关注单步逆合成,可解释性差,且无法兼顾分子的短程信息和长程信息,性能受限。
为此,山东大学的魏乐义和电子科技大学的邹权课题组共同开发了 RetroExplainer。这一可解释的深度学习算法,可以 4 步识别有机物的逆合成路线,给出易得的反应物。RetroExplainer 有望为有机化学逆合成研究提供强力工具。
作者 | 雪菜
编辑 | 三羊
有机化学逆合成 (Retrosynthesis) 旨在找到一系列合适的反应物,以高效合成目标产物。这一过程是计算机辅助合成中不可或缺的基础性工作。

上世纪 60 年代,Corey 等人尝试通过编程进行逆合成分析,并开发了有机化学模拟合成 (OCSS) 软件。然而,随着数据量的增加,这一工作很快被 AI 接手。其中,深度学习 (Deep Learning) 模型被寄予厚望,也产出了相当的成果。
早期的 AI 逆合成研究中,研究者往往基于反应模板从产物倒推到反应物,即基于模板的逆合成。其中,基于多层感知器的分子指纹 (Molecular Fingerprints) 常被用于产物的编码和模板的选择。
随后,研究人员开始探寻无模板和半模板的合成方法,主要包括:
1、基于序列的逆合成;
2、基于图表的逆合成。
二者的主要区别在于分子的表现形式。前者用线性化的字符串表示分子,如 SMILES 规范;而后者会使用分子图模型表示分子,主要包括反应中心 (RC, Reaction Center) 的预测和合成子 (Synthon) 的完成。

虽然现有的逆合成方法已经取得了重大进展,但仍存在 3 个内源性问题:
1、基于序列的逆合成会遗漏分子信息,而基于图表的逆合成会忽视分子的序列信息和长程特征。两种方法在特征学习中都会受到限制,性能很难再提升;
2、基于深度学习的逆合成方法可解释性很差。虽然基于模板的逆合成能给出易懂的合成路线,但算法的决策机制依然很模糊,模型的可重复性和可行性有待考虑;
3、现有方法多聚焦于单步逆合成。这种方法看似可以给出合理的反应物,然而这些反应物可能很难购买,或是需要复杂的后处理。因此,多步逆合成在实际的化学合成中可能更具意义。
为此,山东大学的魏乐义和电子科技大学的邹权课题组共同开发了 RetroExplainer。这一算法能够基于深度学习进行逆合成预测,同时兼顾算法的可解释性和可行性。RetroExplainer 在几乎 12 个基准数据集中的表现优于其他算法,提出的合成路线中 86.9% 的反应得到了文献的验证。这一成果已发表于「Nature Communications」。

论文链接:
https://www.nature.com/articles/s41467-023-41698-5
关注公众号,后台回复「逆合成」获取完整论文 PDF
实验过程
算法构建:模块 + 子网格
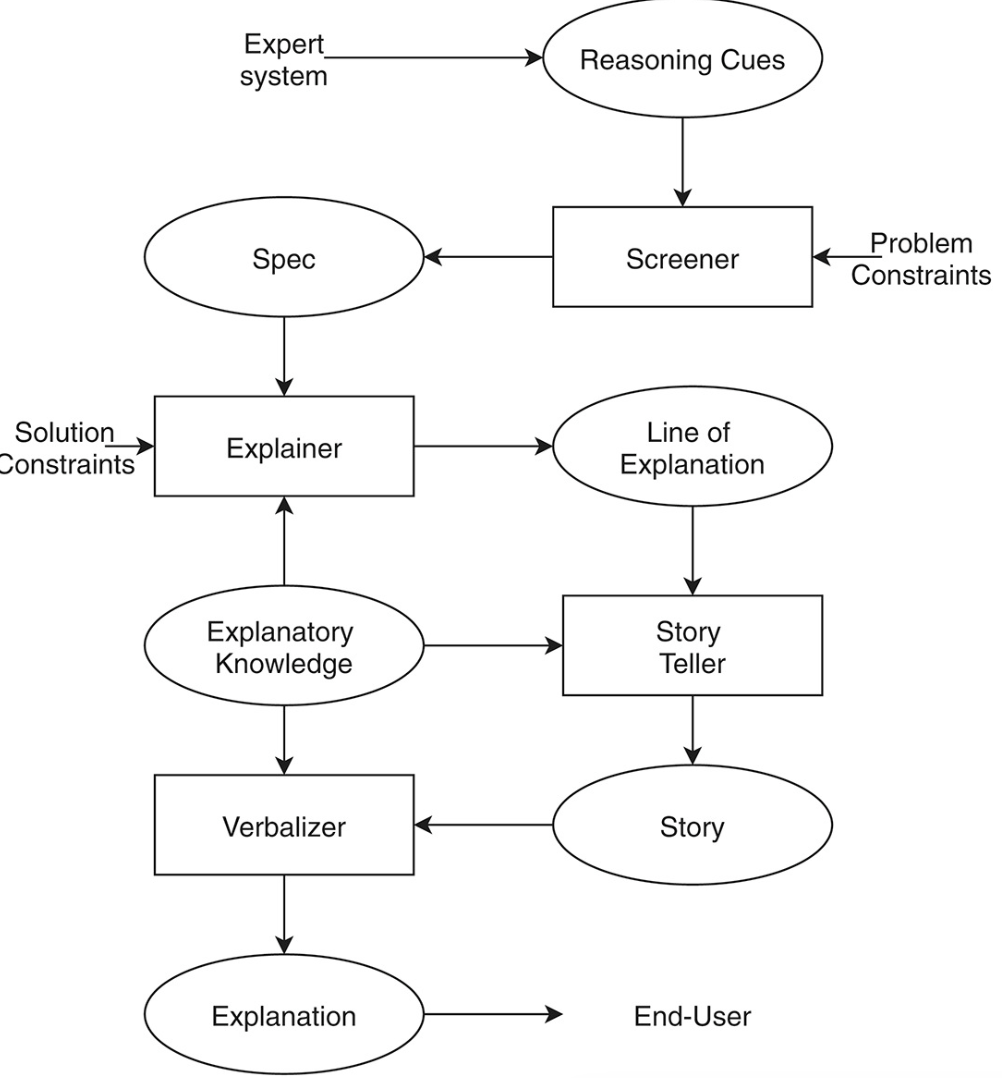
整个逆合成分析过程包括 4 步:分子的图表编码、多任务学习、决策、多步合成路线预测。
RetroExplainer 主要包括 4 个模块:多感知多尺度图 Transformer (MSMS-GT)、动态自适应多任务学习 (DAMT)、可解释的决策模块及路线预测模块。

a:RetroExplainer 流程示意图;
b:MSMS-GT 架构;
c:DAMT 算法示意图;
d:与反应机制类似的决策过程。
MSMS-GT 通过化学键嵌入和原子的拓扑嵌入捕获重要的化学信息。编码后的信息通过多头注意力 (Multi-Head Attention) 机制融合成分子向量。
在 DAMT 模块中,分子信息被同时输入至反应中心预测 (RCP)、离去基团匹配 (LGM, Leaving Group Match) 和离去基团连接 (LGC, Leaving Group Connect) 子网格中。
RCP 会识别化学键和原子相邻氢原子数量的变化,LGM 会将产物中的离去基团与数据库中的匹配,LGC 会将离去基团和产物残基相连。
决策模块会基于 5 个逆合成动作和决策曲线的能量分数 (E, Energy Score),将产物转换为反应物,反向模拟分子组装过程。
最终,使用启发式树搜索算法找到高效的产物合成路线,同时确保反应物的可得性。
性能对比:USPTO 基准数据集
为验证 RetroExplainer 的性能,研究人员基于美国专利及商标局 (USPTO) 收录的化学反应,与其他 21 种逆合成算法进行了对比,评价指标为 top-k 准确率。

可以看到,基于 USPTO-50K 数据集,在 8 项评价指标中,RetroExplainer 有 5 项优于其他算法,其平均准确率位列第一。虽然 RetroExplainer 在 top-10 准确率中不及 LocalRetro,但二者的差距仅 1%。
为消除相似分子带来的影响,研究人员用谷本相似性 (Tanimoto Similarity) 对数据进行了重划分,并与 R-SMILE、LocalRetro 这两种准确率最高的算法进行了对比。

结果中可以看到,RetroExplainer 在大多数数据集中有更好的表现,体现了其稳定性和适应性。
随后,研究人员在更大规模的 USPTO-MIT 和 USPTO-FULL 数据集进行了算法性能对比。RetroExplainer 各项指标均优于其他算法,且与其他算法差距更大,说明 RetroExplainer 在大规模的数据分析中更有潜力。

可解释性:决策可视化
受双分子亲核取代反应 (SN2) 的启发,研究人员基于深度学习引导的分子组装设计了可解释的逆合成预测过程。决策过程包括 6 个阶段:原产物 §、离去基团匹配 (S-LGM)、初始化 (IT)、离去基团连接 (S-LGC)、反应中心化学键变化 (S-RCP)、氢原子数变化 (HC)。
基于每个阶段对最终决策的贡献,DAMT 的子网格会为每个阶段生成一个能量分数 (E)。
具体流程如下:
1、P 阶段将各阶段的 E 初始化为 0;
2、S-LGM 阶段,根据 LGM 模块的预测概率,选择离去基团;
3、将 S-LGM 阶段选择的离去基团的 E 与 RCP、LGM 模块预测的响应事件概率相加,得到 IT 阶段的能量;
4、S-LGC 和 S-RCP 阶段,基于动态规划算法,扩展搜索树中的所有可能节点。选择概率大于预设阈值的事件,同时将 E 固定;
5、调整每个原子的氢原子数和形式电荷,确保得到的分子图符合化合价规则,并计算最终 E。

a:RetroExplainer 对 2 个预测结果的搜索线路;
b:排名前 12 预测路线的决策曲线;
c:6 种代表合成路线的结构变化过程。
基于 E 的变化绘制决策曲线,就能对 RetroExplainer 的决策过程进行分析,找出 RetroExplainer 的预测错误。
如图所示,产物的正确合成路线应为胺的脱保护反应,然而 RetroExplainer 将其排在第 6,排名第 1 的是 C-N 偶联反应。分析发现,HC 阶段中 RetroExplainer 倾向于增加胺的氢原子数,导致了这一差别,说明 RetroExplainer 在 HC 阶段对相似结构的分子可能存在同样的误判。
通过对比 RetroExplainer 排名第 1 和第 2 的反应,研究人员发现 E 可能与反应的难度有关。虽然反应 1 中 I:33 和 C:26 的连接不利于能量的减少,然而在 C:26 处连接一个氢原子需要前一反应 13 倍的能量。同时 I:33 的引入,弱化了 C-N 偶联反应面临的选择性问题。
同时,空间位阻也会对 RetroExplainer 的预测结果产生影响。对比排名第 4 和第 21 的反应,它们的分子结构一致,但离去基团连在了对称的 N 上,导致了 E 的差别。
路径规划:多步预测合成路线
为提高 RetroExplainer 预测的实际性,研究人员将其与 Retro 算法相结合,将后者的单步预测,替换为多步预测。
以支气管扩张剂普罗托醇 (Protokylol) 为例,RetroExplainer 为这一产物设计了 4 步的合成路线。随后,研究人员对这 4 步反应进行了文献调研,以探究其可行性。

图中蓝色文本是参考文献中记录的相似反应,红色部分为 RetroExplainer 的决策过程。
虽然很多反应没有找到完全一致的参考,但他们找到了相似的高产率反应。此外,RetroExplainer 为 101 个案例设计了 176 个实验,其中 153 个可以在 SciFinder 中找到相似的反应。
上述结果说明,RetroExplainer 对逆合成的预测优于目前其他算法。同时,RetroExplainer 决策透明,具有可解释性,且对反应进行多步规划,可行性更强。RetroExplainer 有望为有机化学逆合成研究提供强力工具。
性能 vs. 可解释性,矛盾的 AI
可解释性 (Explainability) 是在各个场景应用 AI 的关键因素。随着 AI 在无人驾驶、医疗诊断、金融保险等行业的不断发展,AI 的决策过程显得愈发重要,也面临着越来越多的实践、社会乃至法律问题。
同时,可解释性能够帮助用户理解、维护和使用 AI,发现并理解 AI 应用领域的新概念。可解释性还体现了结果的可行性,并告诉用户这一决策的收益是最大的。
然而,模型性能和模型的可解释性是困扰 ScienceAI 的一个很大问题,如果模型性能好、具有很好的跨测试集鲁棒性,那可能用高维深度特征效果会更好,但它不具备任何物理意义,也就是我们常说的「偏科研的可解释性大都很差」。
相反,如果用好解释的特征,虽然在物理上非常具有可解释性,但是实际模型表现会有很大的数据依赖性,换一个数据集模型性能就会下降。
二者的矛盾到现在都还没有一个很好的方式统一,但在本研究中,研究人员将 AI 的决策过程分步可视化,让使用者清晰地了解到各种预测结果在各阶段的得分变化,理解了 AI 的决策过程,也便于开发者进行模型的优化。
随着可解释 AI 的不断发展,人们对于 AI 的理解会更加深入,AI 的决策过程也会更加易懂。未来,人机之间的互动将不断增加,交互门槛进一步降低,AI 将在更多场景中投入使用,让生活更加便捷智能。
参考链接:
[1]http://www.chem.ucla.edu/~harding/IGOC/R/retrosynthesis.html
[2]https://zh.wikipedia.org/zh-cn/简化分子线性输入规范
[3]https://wires.onlinelibrary.wiley.com/doi/10.1002/widm.1391

![[ubuntu系统下的文本编辑器nano,vim,gedit,文件使用,以及版本更新问题]](https://img-blog.csdnimg.cn/d67618acd4a848a7a3b5d4b72b0176f6.png)


![[SHCTF 2023 校外赛道] pwn](https://img-blog.csdnimg.cn/3b5b5fce45cb44eca575cc5923e42f4c.png)


![[NSSCTF 2nd] web刷题记录](https://img-blog.csdnimg.cn/07e44ff1ffc846009243f4258b48f6e8.png)
![BUUCTF_练[CISCN2019 华北赛区 Day1 Web5]CyberPunk](https://img-blog.csdnimg.cn/img_convert/b32feae4f2b6f6686af7cbc770a59e13.png)


