为什么选它?
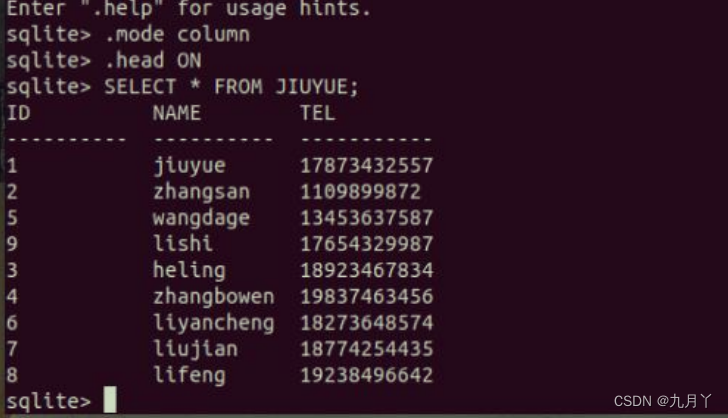
克隆有很多,为什么选它,它是中国人做的,阿里达摩院,5分钟音频数据集就够了。
国内做的有什么好处,因为大家都是中国人,说的是中国话,技术最大的难题不是基础,而是语言与环境,咱们在国内可以问作者,好沟通。
2种方法
modelscope和kantts版,官方推荐的是modelscope,我推荐的是kantts。
为什么?modelscope整个包有30g,集成了很多不需要的东西,而且每次使用他会从网上下载一些其他的东西,哪天不让你用了,就挂了。而kantts是他开源的版本,只有语音本身,虽然比modelscope复杂会遇到很多问题,但是他是最小的,并且可以纯离线使用的。复杂你也不用担心,因为我会帮你。
kantts使用前检查
首先检查你的cpu架构,如果cpu不支持这个指令集,那么就没必要往后看了。
x86_64架构
uname -m
cpu支持avx2指令集
cat /proc/cpuinfo | grep avx2
如果什么都没有弹出,那就是不支持了
安装
首先安装conda
ubuntu安装python以及conda-CSDN博客
gpu以及cuda驱动安装
#安装显卡驱动
sudo apt-get update
sudo apt-get install gcc
sudo apt-get install make
scp mqq@192.168.51.132:/home/mqq/NVIDIA-Linux-x86_64-535.98.run /home/mqq/NVIDIA-Linux-x86_64-535.98.run--------自己从网上下载
sudo sh NVIDIA-Linux-x86_64-535.98.run
nvidia-smi
sudo apt purge nvidia-driver*
sudo apt install nvidia-driver-535
scp mqq@192.168.51.132:/home/mqq/cuda_12.2.1_535.86.10_linux.run /home/mqq/cuda_12.2.1_535.86.10_linux.run ----网上自己下载
sudo sh cuda_12.2.1_535.86.10_linux.run --silent --toolkit
sudo sh cuda_12.2.1_535.86.10_linux.run
nvcc -V
clone他的开源项目
git clone https://github.com/alibaba-damo-academy/KAN-TTS.git
进入tts里面,发现有一个environmentpip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simpleconda env create -f environment.yaml如果报错了他会回滚全部的,建议一个一个安装,写到request.txt里面,发现哪个报错了,先把他删掉,后面单独下载到本地(找资源和换网都行),然后上传上去。
如果你在国外,那你可以下载下来,如果你在国内由于网络原因部分包下载不下来。
此时就要切换镜像源。当然切完之后你依然有部分包下载不下来。
这2个包,要自己本地弄下来,然后手动安装好,然后在上传上去。

然后就能得到了一个maas的包了,但是你哥我呢,特别贴心。给你做好了maas的conda环境。
 你只要把下载下来,解压到你的conda目录,你就拥有了maas的python环境。
你只要把下载下来,解压到你的conda目录,你就拥有了maas的python环境。
然后就可以训练了
训练
切分
首先准备一堆数据集,用我的切分方法,将音频切分成3-15秒的
对音频切分成小音频(机器学习用)_我要用代码向我喜欢的女孩表白的博客-CSDN博客
数据标注
通过modelscope的autolabel方法,变成他能够处理的格式数据
此时要最小安装pip install modelscope(这个包很小,不超过100mb)
有时候可能下载很慢,你也可以windows下载下来,然后本地上传上去。
执行标注的代码
还要装这个包
pip install tts-autolabel -f https://modelscope.oss-cn-beijing.aliyuncs.com/releases/repo.html
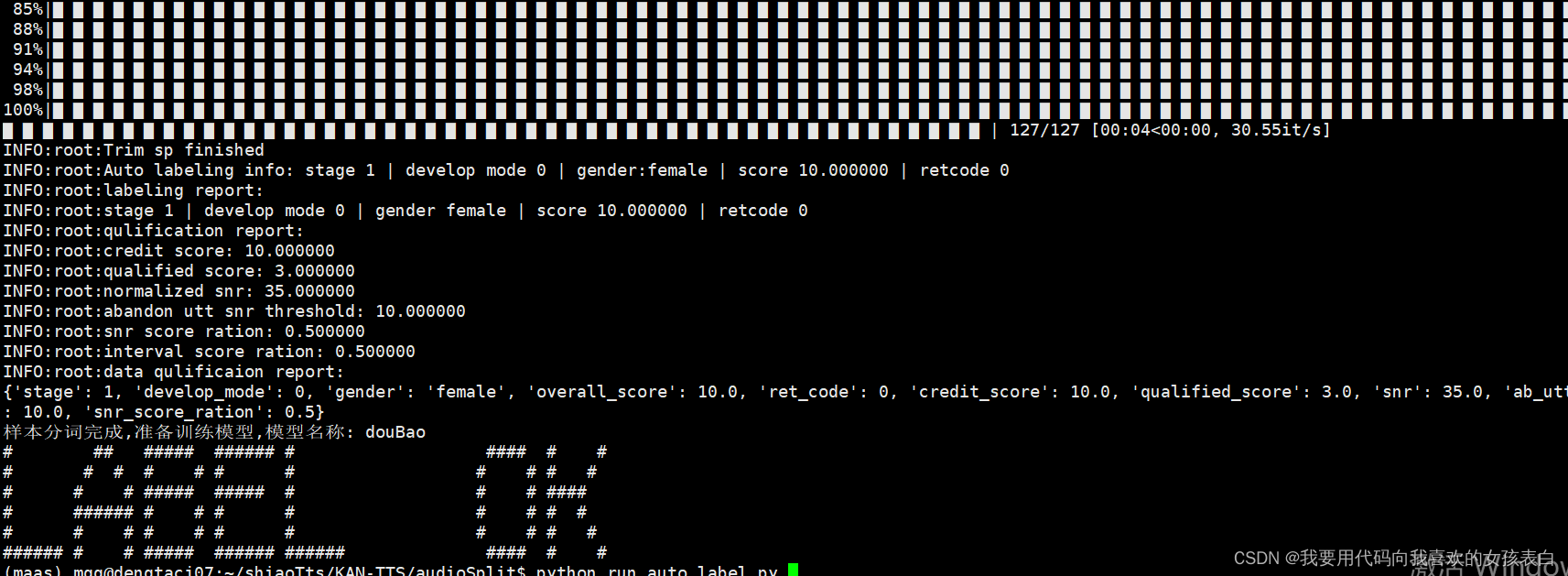
然后执行,他就在下载一个700mb的东西,下面我看源码,把他这个下载的删除,每次都要下载
代码(记得改路径)
这个是run_auto_label.py
# -*- coding: utf-8 -*-
from modelscope.tools import run_auto_label
import osdef training_model(model_name):input_wav = './output/'+model_name # wav audio pathwork_dir = './lableOutput/'+model_name # output pathos.makedirs(work_dir, exist_ok=True)ret, report = run_auto_label(input_wav = input_wav,work_dir = work_dir,resource_revision = "v1.0.7")print(report)print("样本分词完成,准备训练模型,模型名称: "+model_name)print("# ## ##### ###### # #### # # ")print("# # # # # # # # # # # ")print("# # # ##### ##### # # # #### ")print("# ###### # # # # # # # # ")print("# # # # # # # # # # # ")print("###### # # ##### ###### ###### #### # # ")if __name__ == '__main__':training_model("douBao")本地也要安装sox
sudo apt install sox
然后执行代码
python run_auto_label.py
数据预处理
先安装
pip install pyyaml
pip install tqdm
pip install sox
pip install pysptk
pip install torch
python /自己tts目录/KAN-TTS/kantts/preprocess/data_process.py --voice_input_dir 刚刚生成的标注的目录 --voice_output_dir 预处理的目录 --audio_config /自己tts目录/KAN-TTS/kantts/configs/audio_config_24k.yaml --speaker 人物名称随便起
audio_config_24k.yaml这个我训练的是24k的音质,还有16k以及其他的








![[EFI]asus strix b760-i 13900F电脑 Hackintosh 黑苹果efi引导文件](https://img-blog.csdnimg.cn/ec76ad13cf4a473cbda6286ec5fb40c6.png)