监督式机器学习 (ML) 彻底改变了人工智能,并催生了众多创新产品。然而,对于监督式机器学习,总是需要更大、更复杂的数据集,而收集这些数据集的成本很高。如何确定标签质量?如何确保数据代表生产数据?这个问题的一个令人兴奋的新解决方案,特别是对于目标检测任务,是生成一个大规模的合成数据集。合成数据减轻了获取训练机器学习模型所需的大型标记数据集的挑战。
这篇文章主要介绍如何使用UnrealSynth虚幻合成数据生成器 生成合成数据。
现在,我们将向您展示如何:
- 使用 UnrealSynth虚幻合成数据生成器 在新环境中生成所需对象的大型数据集
- 使用合成数据集训练对象检测模型
- 根据少量实际示例微调此模型。
使用 UnrealSynth虚幻合成数据生成器 生成合成数据集
我们选择使用UnrealSynth虚幻合成数据生成器 来生成检测日常杂货物品的合成数据集。训练此模型需要创建感兴趣对象的 3D 资产、自动创建场景、渲染图像数据以及生成边界框标签。
我们为这个项目的所有 3 个对象创建了 63D 资产扫描,并使用 UnrealSynth虚幻合成数据生成器包自动生成标记数据。如之前的博客文章中所述,我们控制了目标对象的位置和方向,以及每个渲染的背景对象的排列、形状和纹理。此外,我们随机选择了每个渲染图像的照明、物体色调、模糊和噪点。
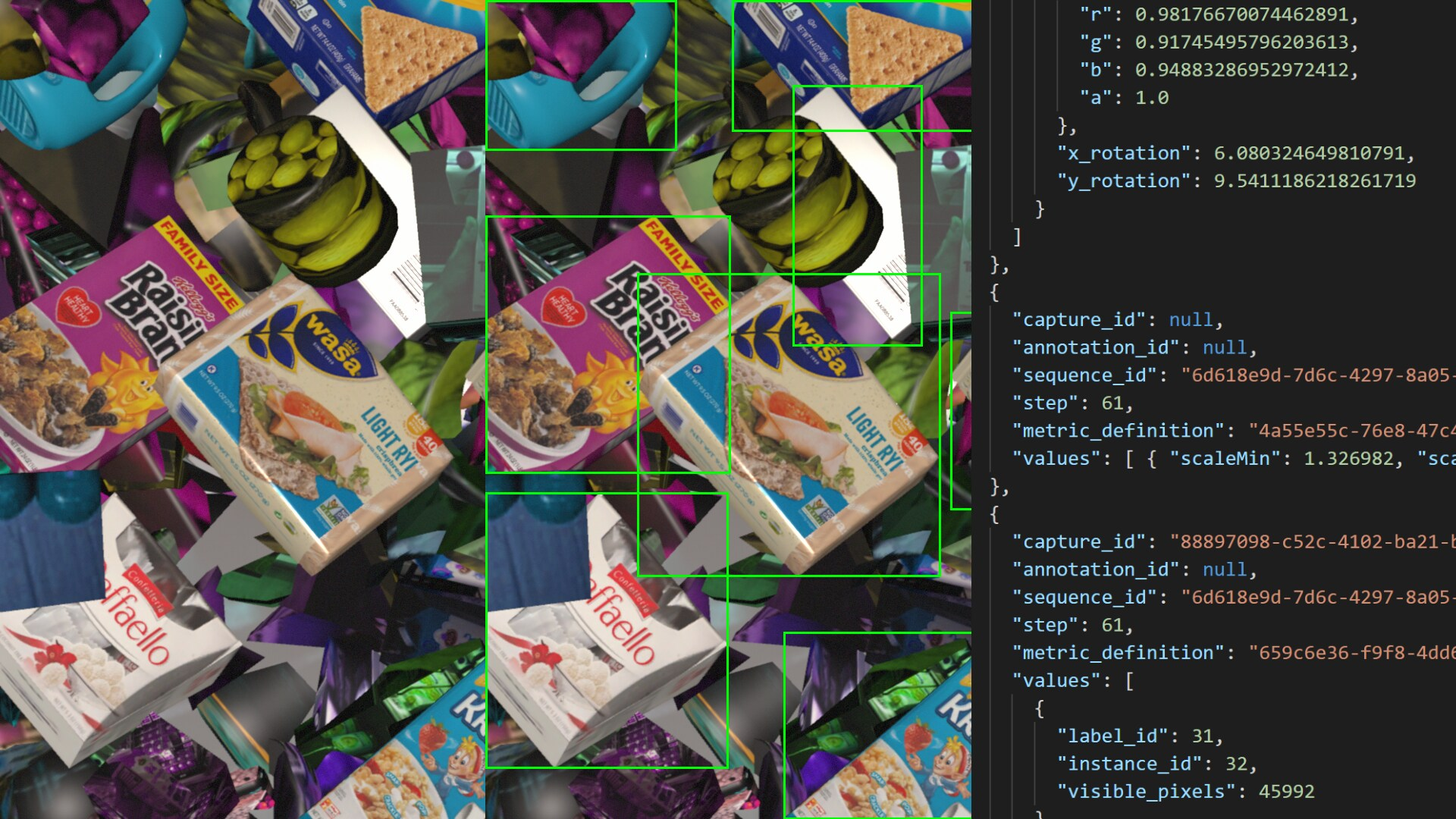
带有边界框和关联元数据 JSON 的合成数据示例
为了创建我们的环境,我们有两种类型的资产:前台资产和后台资产。前景资产是我们检测到的对象的扫描。相反,背景对象构成了我们的背景或遮挡了我们的目标对象(干扰因素)。
制作这些资产面临着一系列独特的挑战。首先,对于背景和干扰对象,我们需要曝光和改变它们的纹理和色调。其次,前景资产必须是现实的。因此,扫描前景物体需要更多的关注和扫描后的一些修饰。
创建真实世界的数据集
为了确保我们真实世界的数据集是多样化的,我们放置了具有不同照明和背景条件的对象。我们还确保每张照片中的对象集各不相同,并且每张照片中的对象位置、方向和配置都不同。

带有人工注释的边界框标签的真实数据示例
在真实数据和合成数据上训练对象检测模型
我们以 2x10 的初始学习率训练了所有模型-4批量大小为 4 个。在训练之前,我们将训练数据拆分为训练集和验证集。我们选择了 mAP 最高的型号IoU=0.5和 mAR100在验证集上。
当仅使用真实世界的数据进行训练时,我们使用了 760 张图像进行训练。我们使用 mAP 选择了性能最佳的模型IoU=0.5和 mAR100在真实世界的验证数据集上。在合成数据上训练时,我们使用了 400,000 张图像进行训练。我们找到了性能最佳的模型,同样是根据合成验证集的性能确定的。最后,为了进行微调,我们采用了性能最佳的合成模型,并使用真实世界的图像进行了微调。在本例中,我们使用真实世界验证集上的性能选择了性能最佳的模型。
在合成数据和真实世界数据上训练的模型的性能比较
使用合成数据的优点之一是我们可以快速迭代数据集,而无需经历繁琐且耗时的数据收集过程。为了生成可用的合成数据集,我们对数据集生成过程的许多方面进行了迭代。最初,我们没有包括环境照明效果或遮挡效果。在这些数据集上训练的模型在真实世界数据上的表现很糟糕,有许多误报和漏报。为了获得适度成功的结果,我们发现允许背景物体和其他目标物体的环境照明效果和遮挡至关重要。值得庆幸的是,使用 UnrealSynth虚幻合成数据生成器 ,我们创建了一个参数化良好的环境,可以在其中轻松快速地自定义数据集,并且只需几分钟即可生成具有不同域随机化参数的新大型数据集。
包括环境照明和遮挡在内,我们在 400,000 个合成样本上训练了一个模型。该模型在真实图像上表现不佳(见上表),尤其是在遮挡严重和光线不足的情况下表现不佳。然而,当物体具有复杂的方向时,模型的表现相当不错。这些结果表明,该问题是一个领域差距问题。为了验证这一假设,我们尝试使用一些真实世界的训练数据对这个模型进行微调。
我们做的第一件事是在 76 张真实世界图像上微调我们的合成训练模型。我们发现,在10%的真实样本中,我们的表现优于仅使用真实世界数据训练的模型。具体来说,我们发现假阳性和假阴性的数量显着下降。此外,我们还发现边界框定位方面有显著改进。然而,我们仍然看到该模型在复杂照明的情况下苦苦挣扎(图 3 中的第三行第三列)。
然而,用 380 个真实示例微调这个模型,我们发现所有指标都有显着的改进。我们看到 mAP 提高了近 22%IoU=0.5mAR 改善约 12%100与仅真实世界的模型相比。此外,我们发现 mAP 提高了 42%,这表明使用真实数据微调在合成数据上训练的模型也改善了边界框定位。特别是,在杂乱无章的示例中,微调后的模型表现令人钦佩,只有少数误报。此外,在具有挑战性的照明环境中,微调模型几乎可以检测到所有物体。这些结果表明,大型、随机、合成的数据集降低了模型的假阴性率和假阳性率。
关键要点和结论
使用在现实世界中执行的合成数据训练模型会带来一些与如何生成有用数据集相关的挑战。对于对象检测,主要困难在于如何创建目标对象的数字孪生,使合成数据集多样化,以及使用此数据集训练模型。使用资源扫描解决方案,您可以在 Unity 中创建目标资源的合成版本。然后,使用UnrealSynth虚幻合成数据生成器 ,您可以参数化地改变资产和环境的各个方面,并大规模生成合成数据。
立即免费试用
我们发布了一个 UnrealSynth虚幻合成数据生成器 工具包,用于创建虚拟场景生成合成数据。生成的数据可用于YOLO 等 AI 模型的训练提供自动生成的图像和标注数据。
转载:使用虚拟合成数据训练对象检测模型 (mvrlink.com)