目录
- 什么是注意力机制
- 1、SENet的实现
- 2、CBAM的实现
- 3、ECA的实现
- 4、CA的实现
什么是注意力机制
注意力机制是深度学习常用的一个小技巧,它有多种多样的实现形式,尽管实现方式多样,但是每一种注意力机制的实现的核心都是类似的,就是注意力。
注意力机制的核心重点就是让网络关注到它更需要关注的地方。
当我们使用卷积神经网络去处理图片的时候,我们会更希望卷积神经网络去注意应该注意的地方,而不是什么都关注,我们不可能手动去调节需要注意的地方,这个时候,如何让卷积神经网络去自适应的注意重要的物体变得极为重要。
注意力机制就是实现网络自适应注意的一个方式。
一般而言,注意力机制可以分为通道注意力机制,空间注意力机制,以及二者的结合。
1、SENet的实现
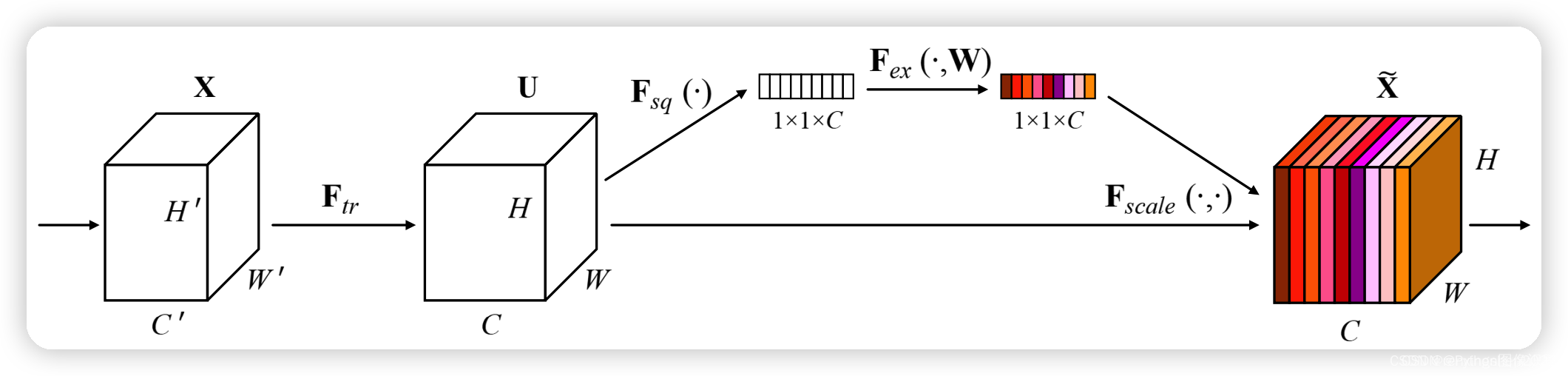
SE注意力模块是一种通道注意力模块,SE模块能对输入特征图进行通道特征加强,且不改变输入特征图的大小。
-
SE模块的S(Squeeze):对输入特征图的空间信息进行压缩
-
SE模块的E(Excitation):学习到的通道注意力信息,与输入特征图进行结合,最终得到具有通道注意力的特征图
-
SE模块的作用是在保留原始特征的基础上,通过学习不同通道之间的关系,提高模型的表现能力。在卷积神经网络中,通过引入SE模块,可以
动态地调整不同通道的权重,从而提高模型的表现能力。
实现方式:
1、对输入进来的特征层进行全局平均池化。
2、然后进行两次全连接,第一次全连接神经元个数较少,第二次全连接神经元个数和输入特征层相同。
3、在完成两次全连接后,我们再取一次Sigmoid将值固定到0-1之间,此时我们获得了输入特征层每一个通道的权值(0-1之间)。
4、在获得这个权值后,我们将这个权值乘上原输入特征层即可。
实现代码
import torch
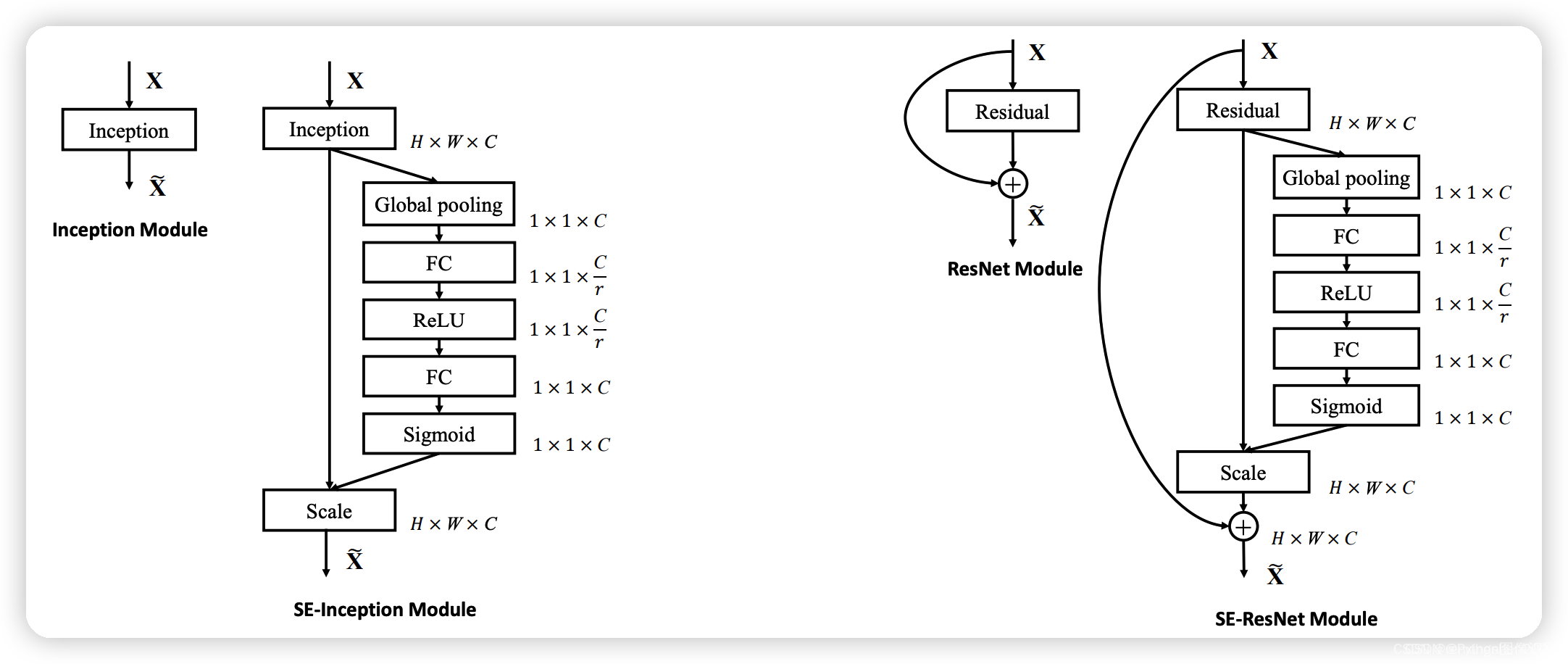
from torch import nnclass SEAttention(nn.Module):def __init__(self, channel=512, reduction=16):super().__init__()# 对空间信息进行压缩self.avg_pool = nn.AdaptiveAvgPool2d(1)# 经过两次全连接层,学习不同通道的重要性self.fc = nn.Sequential(nn.Linear(channel, channel // reduction, bias=False),nn.ReLU(inplace=True),nn.Linear(channel // reduction, channel, bias=False),nn.Sigmoid())def forward(self, x):# 取出batch size和通道数b, c, _, _ = x.size()# b,c,w,h -> b,c,1,1 -> b,c 压缩与通道信息学习y = self.avg_pool(x).view(b, c)# b,c->b,c->b,c,1,1y = self.fc(y).view(b, c, 1, 1)# 激励操作return x * y.expand_as(x)if __name__ == '__main__':input = torch.randn(50, 512, 7, 7)se = SEAttention(channel=512, reduction=8)output = se(input)print(input.shape)print(output.shape)SE模块是一个即插即用的模块,在上图中左边是在一个卷积模块之后直接插入SE模块,右边是在ResNet结构中添加了SE模块。
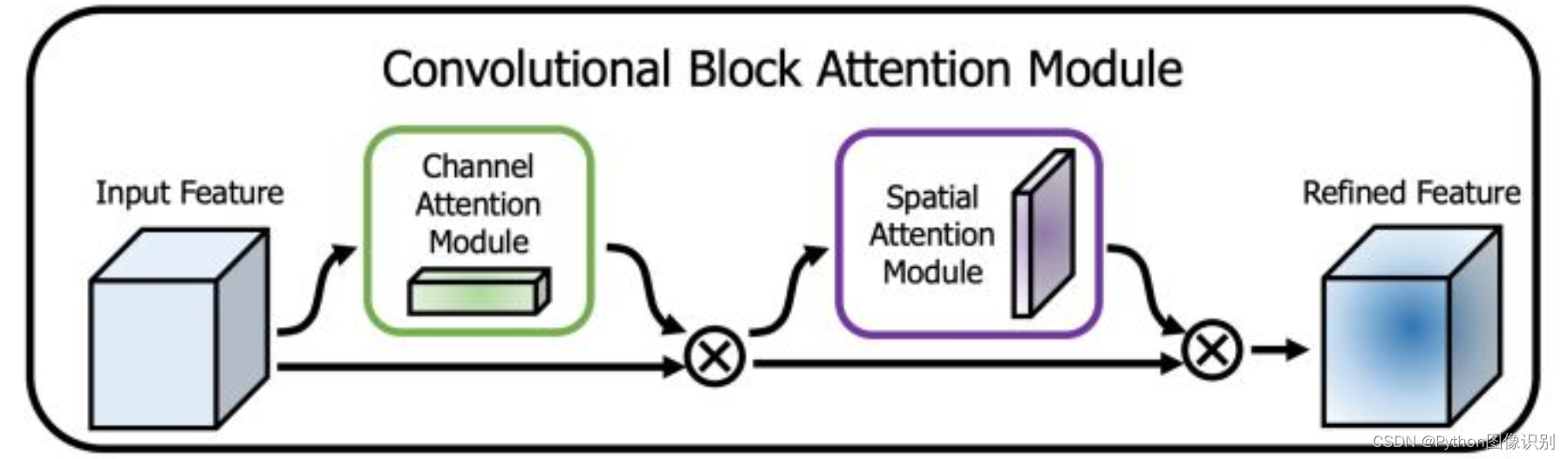
2、CBAM的实现
CBAM将通道注意力机制和空间注意力机制进行一个结合,相比于SENet只关注通道的注意力机制可以取得更好的效果。其实现示意图如下所示,CBAM会对输入进来的特征层,分别进行通道注意力机制的处理和空间注意力机制的处理。
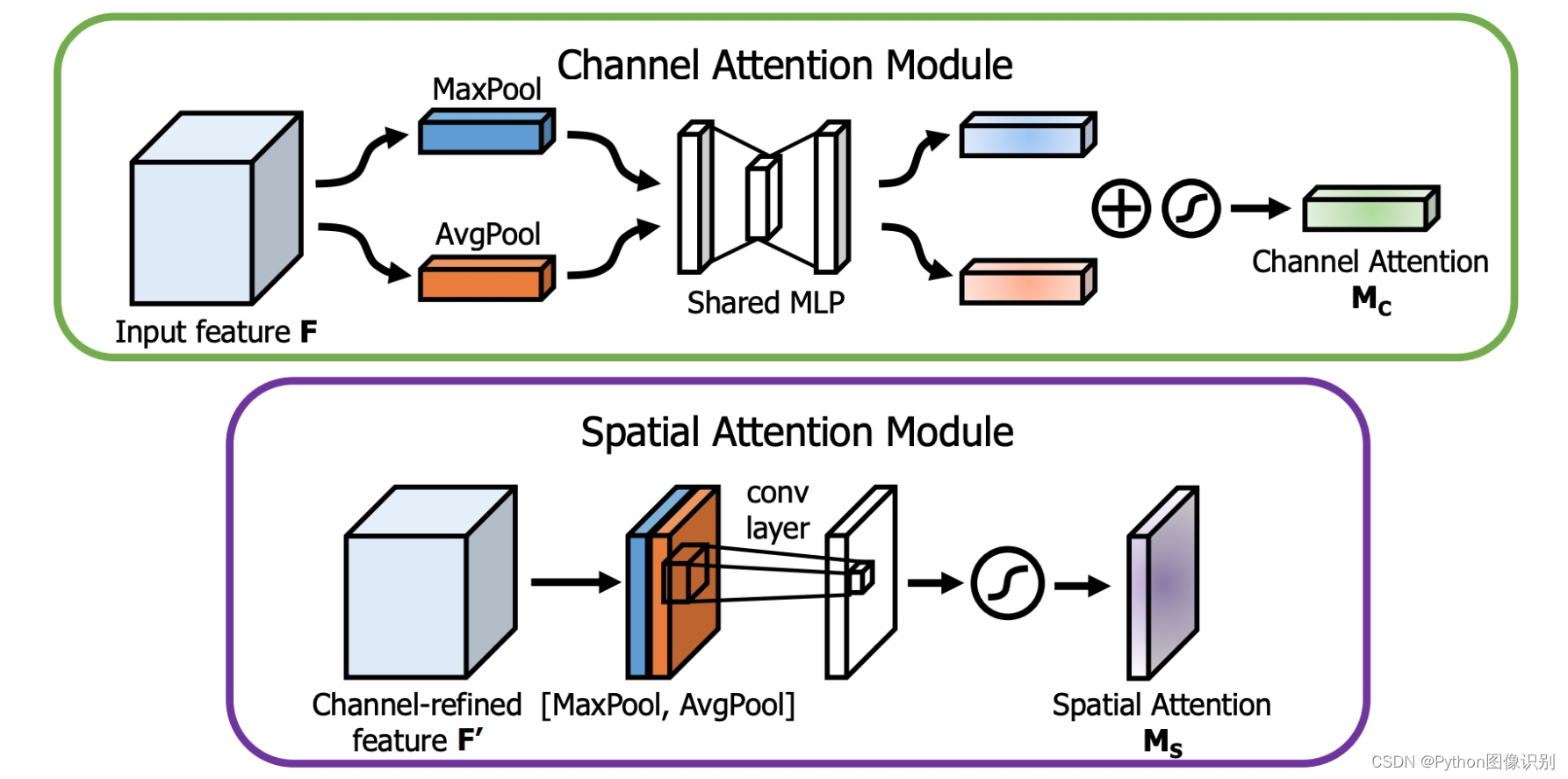
下图是通道注意力机制和空间注意力机制的具体实现方式:
图像的上半部分为通道注意力机制,通道注意力机制的实现可以分为两个部分,我们会对输入进来的单个特征层,分别进行全局平均池化和全局最大池化。之后对平均池化和最大池化的结果,利用共享的全连接层进行处理,我们会对处理后的两个结果进行相加,然后取一个sigmoid,此时我们获得了输入特征层每一个通道的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
图像的下半部分为空间注意力机制,我们会对输入进来的特征层,在每一个特征点的通道上取最大值和平均值。之后将这两个结果进行一个堆叠,利用一次通道数为1的卷积调整通道数,然后取一个sigmoid,此时我们获得了输入特征层每一个特征点的权值(0-1之间)。在获得这个权值后,我们将这个权值乘上原输入特征层即可。
实现代码:
import torch
from torch import nn
from torch.nn import initclass ChannelAttention(nn.Module):def __init__(self, channel, reduction=16):super().__init__()self.maxpool = nn.AdaptiveMaxPool2d(1)self.avgpool = nn.AdaptiveAvgPool2d(1)self.se = nn.Sequential(nn.Conv2d(channel, channel // reduction, 1, bias=False),nn.ReLU(),nn.Conv2d(channel // reduction, channel, 1, bias=False))self.sigmoid = nn.Sigmoid()def forward(self, x):max_result = self.maxpool(x)avg_result = self.avgpool(x)max_out = self.se(max_result)avg_out = self.se(avg_result)output = self.sigmoid(max_out + avg_out)return outputclass SpatialAttention(nn.Module):def __init__(self, kernel_size=7):super().__init__()self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=kernel_size // 2)self.sigmoid = nn.Sigmoid()def forward(self, x):max_result, _ = torch.max(x, dim=1, keepdim=True)avg_result = torch.mean(x, dim=1, keepdim=True)result = torch.cat([max_result, avg_result], 1)output = self.conv(result)output = self.sigmoid(output)return outputclass CBAMAttention(nn.Module):def __init__(self, channel=512, reduction=16, kernel_size=7):super().__init__()self.ca = ChannelAttention(channel=channel, reduction=reduction)self.sa = SpatialAttention(kernel_size=kernel_size)def forward(self, x):b, c, _, _ = x.size()out = x * self.ca(x)out = out * self.sa(out)return outif __name__ == '__main__':input = torch.randn(50, 512, 7, 7)kernel_size = input.shape[2]cbam = CBAMAttention(channel=512, reduction=16, kernel_size=kernel_size)output = cbam(input)print(input.shape)print(output.shape)3、ECA的实现
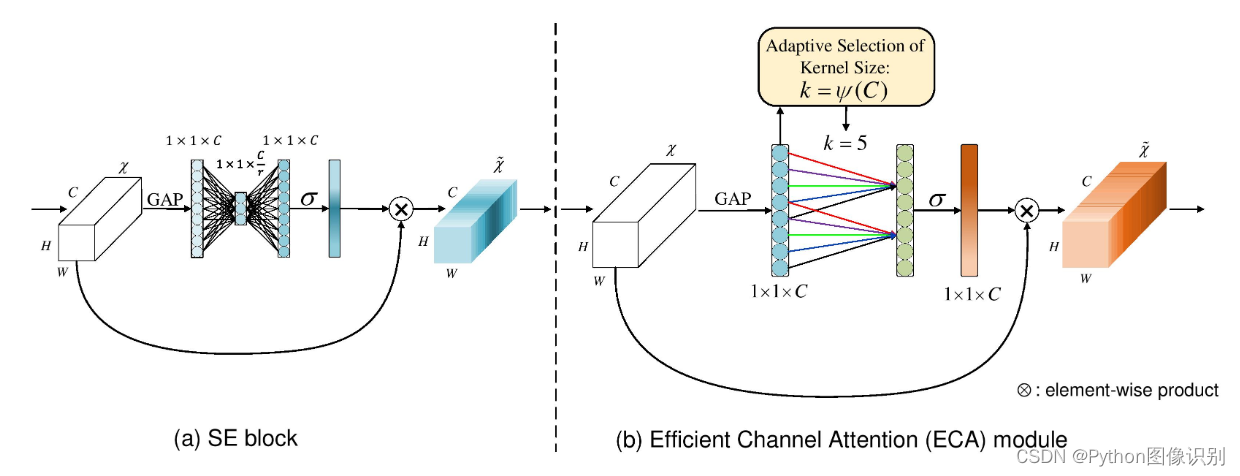
ECANet是也是通道注意力机制的一种实现形式。ECANet可以看作是SENet的改进版。
ECANet的作者认为SENet对通道注意力机制的预测带来了副作用,捕获所有通道的依赖关系是低效并且是不必要的。
在ECANet的论文中,作者认为卷积具有良好的跨通道信息获取能力。
ECA模块的思想是非常简单的,它去除了原来SE模块中的全连接层,直接在全局平均池化之后的特征上通过一个1D卷积进行学习。
既然使用到了1D卷积,那么1D卷积的卷积核大小的选择就变得非常重要了,了解过卷积原理的同学很快就可以明白,1D卷积的卷积核大小会影响注意力机制每个权重的计算要考虑的通道数量。用更专业的名词就是跨通道交互的覆盖率。
如下图所示,左图是常规的SE模块,右图是ECA模块。ECA模块用1D卷积替换两次全连接。
代码实现:
import torch
from torch import nn
from torch.nn import initclass ECAAttention(nn.Module):def __init__(self, kernel_size=3):super().__init__()self.gap = nn.AdaptiveAvgPool2d(1)self.conv = nn.Conv1d(1, 1, kernel_size=kernel_size, padding=(kernel_size - 1) // 2)self.sigmoid = nn.Sigmoid()def init_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):init.kaiming_normal_(m.weight, mode='fan_out')if m.bias is not None:init.constant_(m.bias, 0)elif isinstance(m, nn.BatchNorm2d):init.constant_(m.weight, 1)init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):init.normal_(m.weight, std=0.001)if m.bias is not None:init.constant_(m.bias, 0)def forward(self, x):y = self.gap(x) # bs,c,1,1y = y.squeeze(-1).permute(0, 2, 1) # bs,1,cy = self.conv(y) # bs,1,cy = self.sigmoid(y) # bs,1,cy = y.permute(0, 2, 1).unsqueeze(-1) # bs,c,1,1return x * y.expand_as(x)if __name__ == '__main__':input = torch.randn(50, 512, 7, 7)eca = ECAAttention(kernel_size=3)output = eca(input)print(input.shape)print(output.shape)4、CA的实现
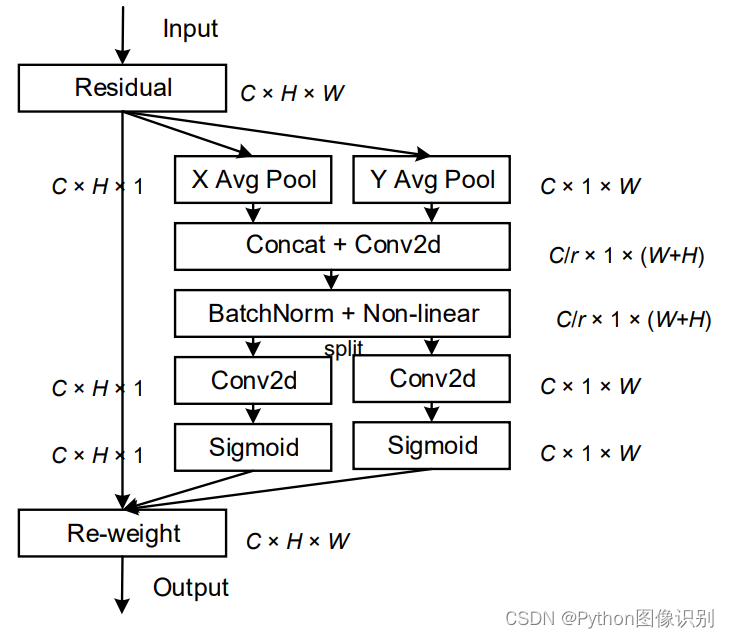
该文章的作者认为现有的注意力机制(如CBAM、SE)在求取通道注意力的时候,通道的处理一般是采用全局最大池化或平均池化,这样会损失掉物体的空间信息。作者期望在引入通道注意力机制的同时,引入空间注意力机制,作者提出的注意力机制将位置信息嵌入到了通道注意力中。
CA注意力的实现如图所示,可以认为分为两个并行阶段:
将输入特征图分别在为宽度和高度两个方向分别进行全局平均池化,分别获得在宽度和高度两个方向的特征图。假设输入进来的特征层的形状为[C, H, W],在经过宽方向的平均池化后,获得的特征层shape为[C, H, 1],此时我们将特征映射到了高维度上;在经过高方向的平均池化后,获得的特征层shape为[C, 1, W],此时我们将特征映射到了宽维度上。
然后将两个并行阶段合并,将宽和高转置到同一个维度,然后进行堆叠,将宽高特征合并在一起,此时我们获得的特征层为:[C, 1, H+W],利用卷积+标准化+激活函数获得特征。
之后再次分开为两个并行阶段,再将宽高分开成为:[C, 1, H]和[C, 1, W],之后进行转置。获得两个特征层[C, H, 1]和[C, 1, W]。
然后利用1x1卷积调整通道数后取sigmoid获得宽高维度上的注意力情况。乘上原有的特征就是CA注意力机制。
实现代码:
import torch
from torch import nnclass CAAttention(nn.Module):def __init__(self, channel, reduction=16):super(CAAttention, self).__init__()self.conv_1x1 = nn.Conv2d(in_channels=channel, out_channels=channel // reduction, kernel_size=1, stride=1,bias=False)self.relu = nn.ReLU()self.bn = nn.BatchNorm2d(channel // reduction)self.F_h = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.F_w = nn.Conv2d(in_channels=channel // reduction, out_channels=channel, kernel_size=1, stride=1,bias=False)self.sigmoid_h = nn.Sigmoid()self.sigmoid_w = nn.Sigmoid()def forward(self, x):_, _, h, w = x.size()x_h = torch.mean(x, dim=3, keepdim=True).permute(0, 1, 3, 2)x_w = torch.mean(x, dim=2, keepdim=True)x_cat_conv_relu = self.relu(self.bn(self.conv_1x1(torch.cat((x_h, x_w), 3))))x_cat_conv_split_h, x_cat_conv_split_w = x_cat_conv_relu.split([h, w], 3)s_h = self.sigmoid_h(self.F_h(x_cat_conv_split_h.permute(0, 1, 3, 2)))s_w = self.sigmoid_w(self.F_w(x_cat_conv_split_w))out = x * s_h.expand_as(x) * s_w.expand_as(x)return outif __name__ == '__main__':input = torch.randn(50, 512, 7, 7)eca = CAAttention(512, reduction=16)output = eca(input)print(input.shape)print(output.shape)







![【蓝桥每日一题]-二分精确(保姆级教程 篇4) #kotori的设备 #银行贷款 #一元三次方程求解](https://img-blog.csdnimg.cn/6392744afbf14007a3545eaff1474d6e.png)