一、给计算机集群起别名——互通
总纲:
1、准备3台客户机(关闭防火墙、静态IP、主机名称都设置好)
2、安装JDK(可点击)
3、配置环境变量
4、安装Hadoop
5、配置hadoop的环境变量
6、配置集群
7、群起测试
1.1、环境准备
下载安装虚拟机以及安装centOS系统,一文搞定
先配置好一台机器,其他机器直接从这一台克隆过去,注意一定要改IP地址不能两两之间发生冲突
修改Linux系统IP地址:vim /etc/sysconfig/network-scripts/ifcfg-enp0s3 #如果是VMware后缀应该是/ifcfg-ens33
修改主机名称:vim /etc/hostname #直接键入命令hostname就可以查看当前主机的名称
修改主机映射(实现主机与主机之间用别名互联互通):vim /etc/hosts
针对上面三个命令,如下三个参考文本
TYPE=Ethernet
PROXY_METHOD=none
BROWSER_ONLY=no
BOOTPROTO=static
DEFROUTE=yes
IPV4_FAILURE_FATAL=no
IPV6INIT=yes
IPV6_AUTOCONF=yes
IPV6_DEFROUTE=yes
IPV6_FAILURE_FATAL=no
IPV6_ADDR_GEN_MODE=stable-privacy
NAME=enp0s3
UUID=8b0a9ecf-ce7c-4568-ab9b-e8f7fbc75c0a
DEVICE=enp0s3
ONBOOT=yes
# 重点
IPADDR=192.168.2.113
NETMASK=225.225.225.0
GATEWAY=192.168.2.2
DNS1=192.168.2.2
DNS2=223.5.5.5
# 直接将内容localhost.localdomain改为本台机器取的别名,如hadoop113
hadoop113
#修改之后键入hostname查看当前主机的名称,如果没有生效就重启一下虚拟机,命令reboot或者(shutdown -r now)
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
# 上面那2行不动它的,下面注重IP与别名的映射
192.168.2.113 hadoop113
192.168.2.114 hadoop114
192.168.2.115 hadoop115
192.168.2.123 hadoop123
192.168.2.124 hadoop124
192.168.2.125 hadoop1251.2、环境变量配置
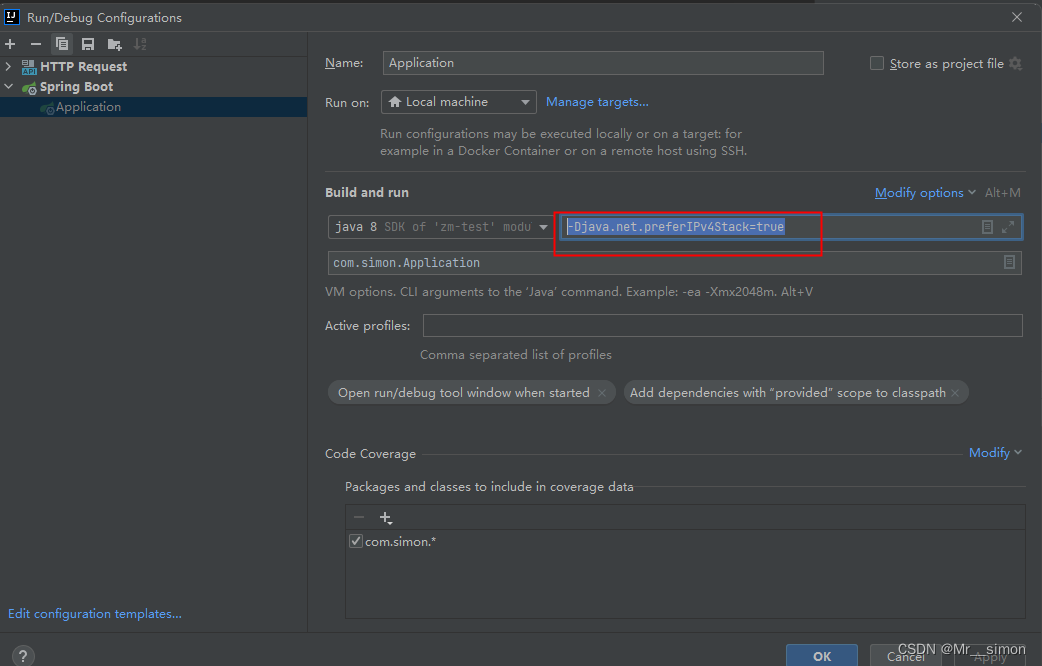
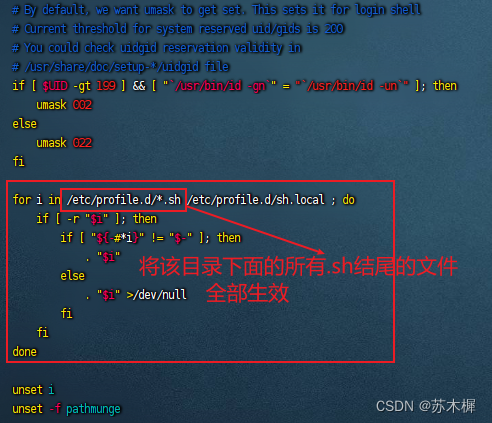
以前我们把环境变量都配置在vim /etc/profile里面,现在都配置在vim /etc/profile.d目录下面,文件的名字见名知意
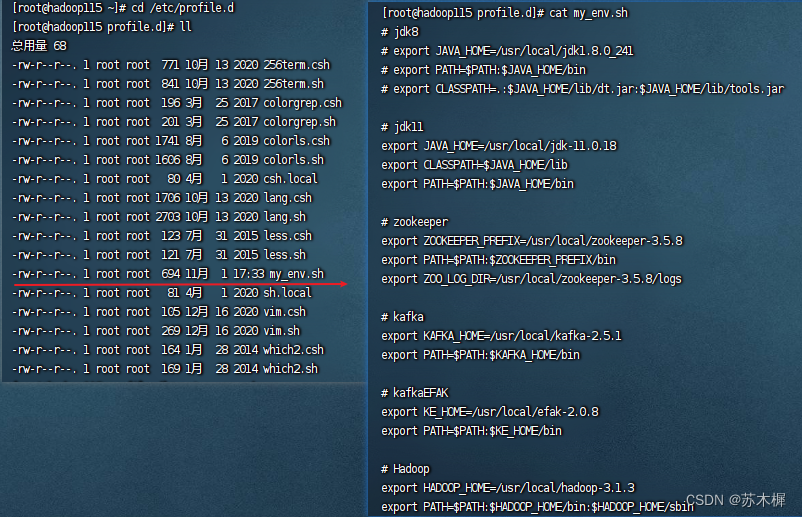
如下图,我将我的环境变量全都配置在my_env.sh里面
二、集群分发脚本xsync——互联
2.1、SCP (secure copy) 安全拷贝
(1)scp定义
scp可以实现服务器与服务器之间的数据拷贝。(from serverl to server2)
(2)基本语法
SCP -r $pdir/$fname $user@host:$pdir/$fname
命令 递归 要拷贝的文件路径/名称 目的地用户@主机:目的地路径/名称
重点说明Linux对权限管控很严,一定要看被接收的用户是否具备相应权限,如:创建文件夹的权限等等
(3)案例说明
将hadoop-3.1.3分发到hadoop114服务器 scp -r hadoop-3.1.3/ root@hadoop114:/usr/local/
这里又有一个大坑,因为hadoop不能用root用户启动集群,而我又喜欢把软件安装在/usr/local目录下面,直接执行命令【scp -r hadoop-3.1.3/ zhu@hadoop114:/usr/local/】是复制不过去的,会报这个错误【scp: /usr/local//hadoop-3.1.3: Permission denied】所以我在根目录下面创建了一个中转文件夹transfer,修改其权限为【sudo chown zhu:zhu transfer】zhu用户,然后再使用scp复制到hadoop114和hadoop115上面,再用mv命令移动【mv hadoop-3.1.3/ /usr/local/】
将hadoop113服务器的hadoop-3.1.3文件拉到当前目录下 scp -r root@hadoop113:/usr/local/hadoop-3.1.3 ./
在一个中间机器执行 scp -r root@hadoop102:/opt/module/* root@hadoop104:/opt/module/
2.2、rsync远程同步工具
rsync主要用于备份和镜像。具有速度快、避免复制相同内容和支持符号链接的优点。
rsync和scp区别:用rsync做文件的复制要比scp的速度快,rsync只对差异文件做变更。scp是把所有文件都复制过去。
(1)基本语法
rsync -av $pdir/$fname $user@$host:$pdir/$fname
命令 选项参数 要拷贝的文件路径/名称 目的地用户@主机:目的地的路径/名称
选项参数说明
| 选项 | 功能 |
|---|---|
| -a | 归档拷贝 |
| -v | 显示复制过程 |
2.3、xsync集群分发脚本
集群分发文件和脚本
#!/bin/bash#1.判断参数个数
if [ $# -lt 1 ]
thenecho Not Enough Arguement!exit;
fi
#2.遍历集群所有机器
for host in hadoop113 hadoop114 hadoop115
doecho ======================= $host =======================#3.遍历所有目录,挨个发送for file in $@do#4.判断文件是否存在if [ -e $file ]then#5.获取父目录pdir=$(cd -P $(dirname $file); pwd)#6.获取当前文件的名称fname=$(basename $file)ssh $host "mkdir -p $pdir"rsync -av $pdir/$fname $host:$pdirelseecho $file does not exists!fi done
done
真心搞醉,#!bin/bash这个看上去人畜无害的实际上报这个错,-bash: /usr/local/bin/xsync: bin/bash: 坏的解释器: 没有那个文件或目录,最后在chatGPT的帮助下找到了错误。
echo $PATH查看Linux系统变量
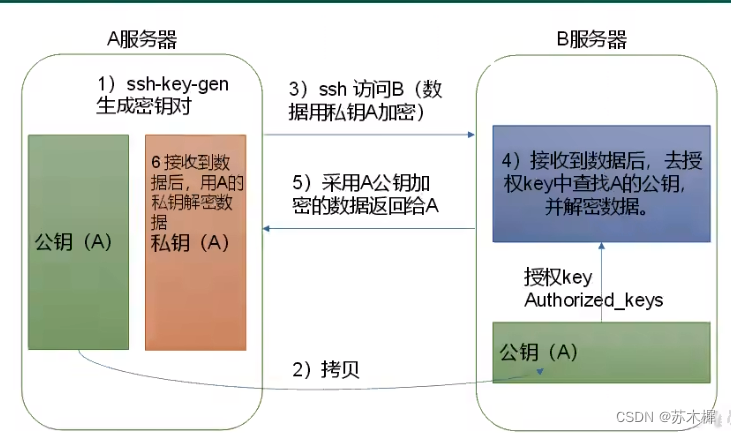
2.4、ssh免密登录
Linux的根目录是 /,下面有个root文件夹也就是~路径
命令:查看隐藏文件,ls -al
Linux服务器生成公私钥,命令:ssh-keygen -t rsa 连续三次回车即可生成
使用命令将生成的公钥发给各个服务器——免密登录
ssh-copy-id hadoop114 #将公钥发给hadoop114
ssh-copy-id hadoop115 #将公钥发给hadoop115
ssh-copy-id hadoop113 #将公钥发给自己所在的服务器
#执行完成之后,在~/.ssh/目录下面也可以看到这个authorized_keys文件里面的公钥配置,如下图就有本机和hadoop114可以免密登录本机

至此,免密登录+xsync集群分发脚本全套已完成,直接使你效率起飞。
三、Hadoop集群搭建
本集群搭建目标
| hadoop113 | hadoop114 | hadoop115 | |
|---|---|---|---|
| HDFS | NameNode DataNode | DataNode | SecondaryNameNode DataNode |
| YARN | NodeManager | ResourceManager NodeManager | NodeManager |
4.1、修改hadoop配置文件
声明:本人hadoop安装在/usr/local文件夹下面,你可以安装在自己熟悉的目录
路径/usr/local/hadoop-3.1.3/etc/hadoop

core-site.xml配置:
<configuration><!-- 指定NameNode的地址 --><property><name>fs.defaultFS</name><value>hdfs://hadoop113:8020</value></property><!-- 指定hadoop数据的存储目录 --><property><name>hadoop.tmp.dir</name><value>/usr/local/hadoop-3.1.3/data</value></property>
</configuration>
hdfs-site.xml配置:
<configuration><!-- nn web端访问地址--><property><name>dfs.namenode.http-address</name><value>hadoop113:9870</value></property><!-- 2nn web端访问地址--><property><name>dfs.namenode.secondary.http-address</name><value>hadoop115:9868</value></property>
</configuration>
yarn-site.xml配置:
<configuration><!-- 指定MR走shuffle --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 指定ResourceManager的地址--><property><name>yarn.resourcemanager.hostname</name><value>hadoop114</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name><value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value></property>
</configuration>
mapred-site.xml配置:
<configuration><!-- 指定MapReduce程序运行在Yarn上 --><property><name>mapreduce.framework.name</name><value>yarn</value></property>
</configuration>
4.2、启动集群
4.2.1、启动hdfs
注意所有的这些命令都是在zhu(非root用户)用户下,hadoop的根目录执行的,即在笔者的linux上是/usr/local/hadoop3.1.3路径
第一步:注意第一次启动集群一定要初始化,命令:hdfs namenode -format,后续启动就不需要执行了
第二步:直接在hadoop根目录下键入命令 sbin/start-dfs.sh
如果看到一下信息就说明启动成功了,也可以输入hadoop113:9870可以看到web页面也表示成功了
[zhu@hadoop113 hadoop-3.1.3]$ sbin/start-dfs.sh
Starting namenodes on [hadoop113]
Starting datanodes
Starting secondary namenodes [hadoop115]
[zhu@hadoop113 hadoop-3.1.3]$ jps
12386 DataNode
12850 Jps
12223 NameNode
如果报以下错误,就是不能用root启动,权限太大了
Starting namenodes on [hadoop113]
ERROR: Attempting to operate on hdfs namenode as root
ERROR: but there is no HDFS_NAMENODE_USER defined. Aborting operation.
Starting datanodes
ERROR: Attempting to operate on hdfs datanode as root
ERROR: but there is no HDFS_DATANODE_USER defined. Aborting operation.
Starting secondary namenodes [hadoop115]
ERROR: Attempting to operate on hdfs secondarynamenode as root
ERROR: but there is no HDFS_SECONDARYNAMENODE_USER defined. Aborting operation.
①没有用户就新增用户:
[root@hadoop114 local] # useradd zhu
[root@hadoop114 local]# passwd zhu
更改用户 zhu 的密码 。
新的 密码:
重新输入新的 密码:
passwd:所有的身份验证令牌已经成功更新。
修改hadoop3.1.3文件夹权限:要保证整个目录下的所有文件及文件夹都是zhu用户的权限才行
# 如果权限不够记得加上sudo
chown zhu:zhu hadoop3.1.3/
②有用户就切换用户 su zhu,然后再次启动
解决之后又报这个错误,我只配了root用户得免密登录,没有配置zhu用户的免密登录,于是乎我去~/.ssh/authorized_keys文件一看,果然只有root的免密登录,最后我把zhu用户的免密登录也加上了
Starting namenodes on [hadoop113]
hadoop113: Warning: Permanently added ‘hadoop113,192.168.2.113’ (ECDSA) to the list of known hosts.
hadoop113: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting datanodes
hadoop115: Warning: Permanently added ‘hadoop115,192.168.2.115’ (ECDSA) to the list of known hosts.
hadoop114: Warning: Permanently added ‘hadoop114,192.168.2.114’ (ECDSA) to the list of known hosts.
hadoop115: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
hadoop113: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
hadoop114: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).
Starting secondary namenodes [hadoop115]
hadoop115: Permission denied (publickey,gssapi-keyex,gssapi-with-mic,password).

zhu用户也要拥有root权限 vim /etc/sudoers
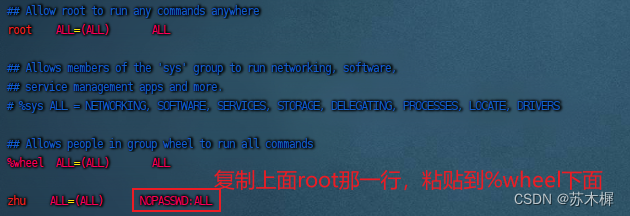
注意: zhu这一行不要直接放到 root 行下面,因为所有用户都属于 wheel 组,你先配置了 zhu 具有免密功能,但是程序执行到%wheel 行时,该功能又被覆盖回需要密码。所以 zhu 要放到%wheel 这行下面。
4.2.2、启动yarn
第一步:直接在hadoop114机器上hadoop根目录下键入命令 sbin/start-yarn.sh启动yarn,输入hadoop114:8088出现web页面也表示成功
如果执行上述命令,jps查看进程如下,说明yarn没有启动成功🙃
[zhu@hadoop114 hadoop-3.1.3]$ sbin/start-yarn.sh
Starting resourcemanager
Starting nodemanagers
[zhu@hadoop114 hadoop-3.1.3]$ jps
24692 Jps
12158 DataNode
问题排查如下,核对这4个core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml文件的配置;再就是检查jdk版本与hadoop版本是否兼容,我就是jdk11和hadoop3.1.3不兼容,哭死。
风卷江湖雨暗村,四山声作海涛翻。溪柴火软蛮毡,我与狸奴不出门。——《十一月四日风雨大作》陆游
君不见,青海头,古来白骨无人收。——《兵车行》杜甫