近日,计算机系统领域的国际顶级学术会议USENIX ATC 2023在美国波士顿市举行。凭借在规模化部署和应用模型上的创新,阿里云存储团队发表的技术论文《Deploying User-space TCP at Cloud Scale with LUNA》被顶会收录,这是继NSDI 21、SIGCOMM 22之后,阿里云又一篇被全球A类顶会收录的存储网络技术论文。

USENIX ATC全称为USENIX年度技术大会(USENIX Annul Technical Conference),是计算机系统结构方向最重要的国际会议之一,也是中国计算机学会CCF推荐的A类会议。自1992年以来,已成功举办30多届,吸引了来自全球的顶级名校及科技巨头投稿。本届顶会共收到353篇论文投稿,其中录用65篇,录用率约为18.41% ,极为严苛。
云计算时代下,基于内核TCP的数据中心网络已无法满足系统对性能和可用性的要求,在《Deploying User-space TCP at Cloud Scale with LUNA》论文中,全面介绍了阿里云是如何用自研技术解决这一难题的。

具体来说,围绕飞天云计算操作系统核心组件之一的盘古存储系统,阿里云存储团队自主研发了名为“Luna”的用户态网络。通过核间资源不共享、数据链路分层融合、全栈零拷贝,Luna极大提高了存储性能、降低存储延迟,可在超大规模的前提下承载不同的应用负载, 覆盖低延迟、高吞吐、高并发等多种复杂场景。
在相同负载下,Luna的延迟比内核TCP降低了55% 以上,吞吐提升了100% ,尤其在短连接场景下,每秒请求数提升了3.5倍。
在多项创新技术的加持下,阿里云将云盘的IOPS提升了3倍,并不断推出满足用户不同需求的存储产品,包括性能和容量解耦、性能秒级弹性突发的云盘新规格ESSD AutoPL,以及延迟低至40微秒、IOPS高达300万的ESSD PL-X。
此外,全系列云盘规格还大幅减少了网络异常引入的I/O抖动,长尾I/O毛刺下降至毫秒级,提供更优的性能SLO,满足从数据库、在线交易系统到高性能计算等多种业务形态的需求。
过去十年,阿里云将计算的成本降低了80%,存储的成本降低了近90%,并持续提升云上用户体验。目前Luna网络技术已在阿里云上大规模应用,配合块存储、对象存储、文件存储、表格存储、备份容灾等云产品服务云上数百万客户,覆盖政企、互联网、金融、零售、制造、医疗等千行百业。
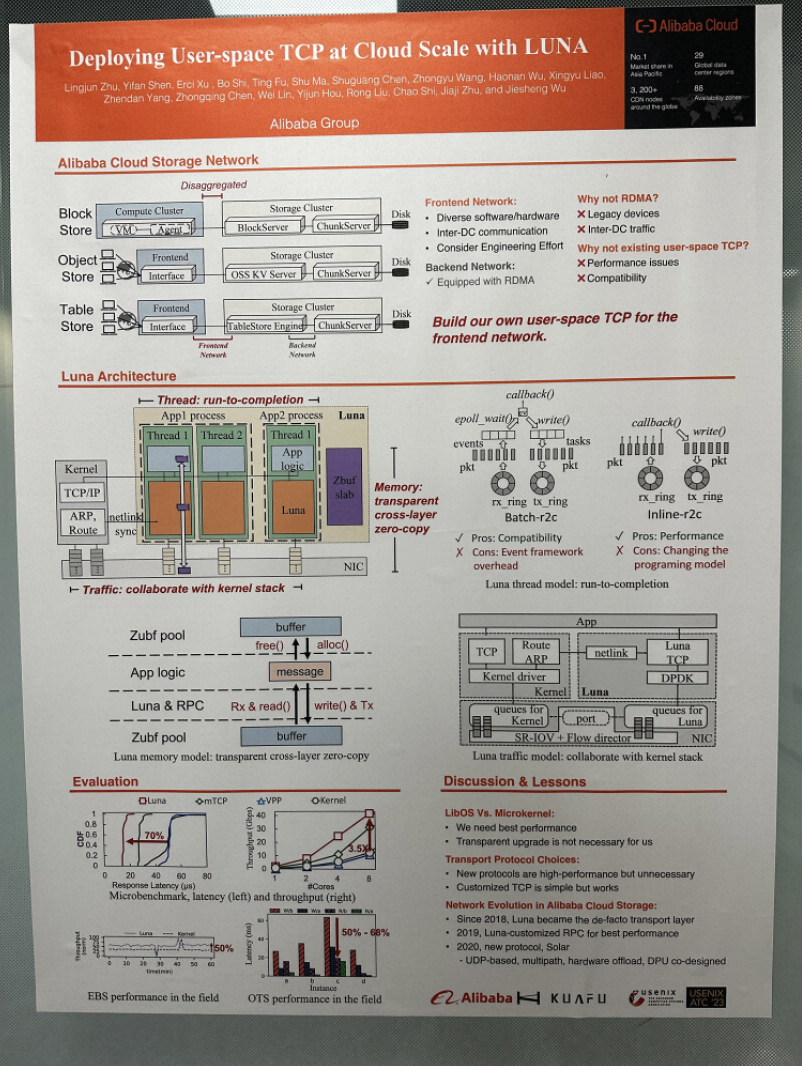
Deploying User-space TCP at Cloud Scale with Luna是今年阿里在USENIX ATC 2023中的一篇文章,介绍了它们的用户态协议栈

文章是概要的介绍了下他们之前的工作
要解决了还是100G网络下,内核协议栈性能比较差的问题,用户态协议栈减少中断,内存拷贝的开销能大幅度的提升系统的效率,但目前常见的用户态协议栈不太能满足他们的需求,例如像mtcp(好古老的开山用户态协议栈)要进行拷贝操作,IX单个应用独占了网卡,常见的用户态协议栈没能好好的利用内核态的鲁棒性等等,所以他们决定自己搞事情
另外文章也同时提到,像RDMA这种高性能的传输方法在一个数据中心内部还挺好用,但跨数据中心就很难部署,所以还是离不开TCP/IP

背景说明
作为背景,以及需求介绍,主要跟着他们的系统结构图来提
主要2点还是,RDMA不合适,同时旧的一些环境还需要内核tcp/ip,所以要兼容

luna目前是这样一个架构,使用了r2c结构,协议栈和APP在一个thread下处理,下层用网卡多队列分流,一部分流走内核态协议栈,即用户态和内核态同时支持

总之三个大的特征
1)r2c
2)零拷贝到传输
3)基于网卡分流的独特的流量分流
r2c
r2c有两套接口,inline-r2c通过事件驱动,一次处理一批包,另外对BSD接口,还有batch-r2c,这种模式下每个包都有自己的call back函数实现,一个一个包进行处理(猜测例如某些要立刻送往内核态的ARP请求包啥的)

2)零拷贝的内存
mbuf采用索引值,记录使用次数,猜测用的dpdk rte_mbuf的refcnt值,这样可以和驱动保持一致,驱动释放时内存不会释放
mbuf找物理地址的方法,先通过虚地址找所属哪一个2MB,然后看offset是啥,驱动用的物理地址就是2MB的物理地址+offset
只要用的是同一块物理地址,就能实现不拷贝的前提下,全程访问同一块内存。同时为了方式内存被以外释放,用索引值记录使用次数,多一个部分用就+1,释放就-1,只有释放一直减为0才能说这块内存被真正释放

3)流量分流
目前用的端口号+flow director分流
flow director可以通过配置,将固定源/目的IP,源/目的端口号,包类型(大至TCP/UDP,小到SYN包和普通包)分流到特定网卡上。
luna会将某非tcp流送入到内核态中处理,tcp流则按照端口送往特定的thread上,thread和网卡队列是绑定关系
luna保留了61440~65530这部分的端口号
flow director一个很大的问题是,网卡的流表项是有限的,记得intel 82599是4K条表项,目前阿里单个服务器按照论文上是160条流表,还算够用

性能测试
然后是一些测试,luna一定是比其他的协议栈在吞吐与延迟要更好一些

同时还有些分析,例如拷贝到底带来多少开销(99分位也只有25%左右延迟开销,似乎也不是非常大)

最后是一些在部署上的教训
例如要好用,API的编写要符合用户APP的原始逻辑
TCP协议栈要可定制,不同环境用需要特定的工作模型
要能快速恢复等等
总的来说算是用户态协议栈如何在工业界使用的一个说明



![[C++]关键字,类与对象等——喵喵要吃C嘎嘎2](https://img-blog.csdnimg.cn/530b9a7e0a634b81bfe44228d5ff8023.png)