JVM
- 1. JVM 的内存划分
- 2. JVM 类加载机制
- 2.1 类加载的大致流程
- 2.2 双亲委派模型
- 2.3 类加载的时机
- 3. 垃圾回收机制
- 3.1 为什么会存在垃圾回收机制?
- 3.2 垃圾回收, 到底实在做什么?
- 3.3 垃圾回收的两步骤
- 第一步: 判断对象是否是"垃圾"
- 第二步: 如何回收垃圾
1. JVM 的内存划分
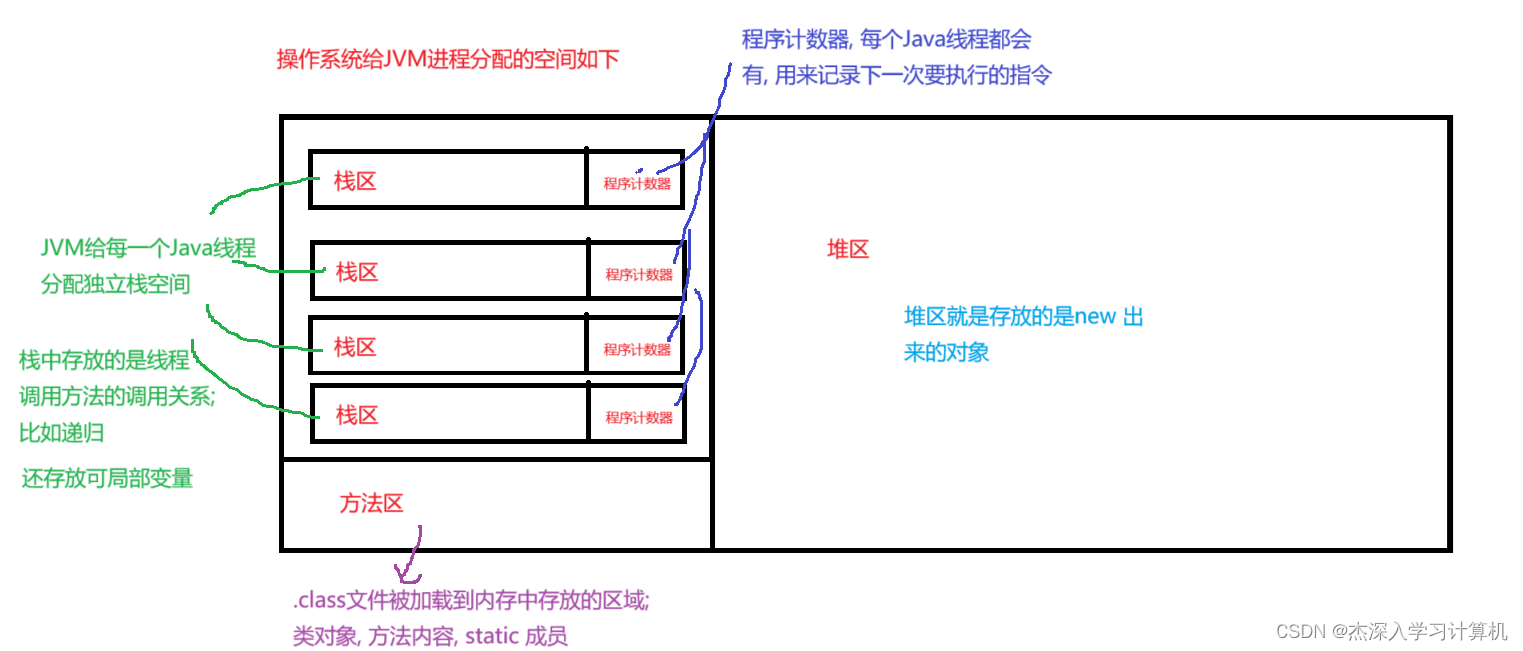
- JVM 其实就是一个Java的进程
- 一个进程运行过程中, 就要从操作系统这里申请到一些内存资源, JVM当然也是如此, 搞一大块内存, 供Java代码执行时使用
- JVM把这一块内存, 又划分出几个区域来, 作为不同的用途
例题

2. JVM 类加载机制
- 类加载机制就是将类从磁盘加载到内存当中
- Java 程序, 最开始写的是一个 .java 文件, 编译成 .class 文件 (字节码)
- 运行 java 程序, JVM就会读取 .class 文件, 把文件的内容, 放到内存中, 并且构造成 class 对象 (类对象)
2.1 类加载的大致流程
- 加载 找到 .class 文件, 打开并读取文件内容, 并且尝试解析格式
- 验证, 检验一下当前 .class 文件是否符合格式要求
- 准备 给对象分配内存
- 最终目标, 是构造出完整的类对象, 分配内存 + 初始化
- 分配出来的空间, 内容都是 0 此时此刻, 类对象上static也是0
- 解析
- 主要是初始化类对象中涉及到的一些字符串常量
- 其实字符串常量已经在 .class 文件中有了, 直接读到内存中就行了
- 将常量池内的符号引用替换为直接引用的过程,也就是初始化常量的过程。
- 符号引用: 此时.class 文件中, 不知道字符串真实的内存地址在哪里的, 只能知道一个相对偏移量, 知道字符串的内容在 .class 文件的哪个地方, 等到把字符串内容加载到内存中之后, 就可以把 真实的地址, 替换 到刚才的符号引用这里了
- 初始化 堆类对象进行更具体的初始化操作, 初始化静态成员, 执行静态代码块, 加载父类 …
2.2 双亲委派模型
什么是双亲委派模型
- 类加载的时候, 需要先找到 .class 文件
- 双亲委派模型就是用来描述找 .class 文件的过程的
JVM 中的三个类加载器

- 此处的"父子" 不是父类, 子类的继承关系, 而是一种组合关系
- "子类"对象中存储了"父类"的引用
双亲委派模型描述找 .class 文件具体过程
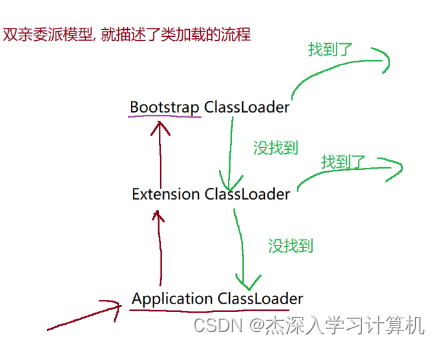
- 从 Application ClassLoader 开始
- 不会立即就搜索第三方库的目录, 而是先把加载任务委派给父亲, 让父亲先尝试加载
- 到了 Extendsion ClassLoader
- 也不会立即就搜索扩展库的目录, 也是把加载任务委派给父亲, 让父亲先尝试加载
- 到了 Bootstrap ClassLoader
- 也不想立即搜索标准库, 而是也想把任务委派给父亲, 但是 Bootstrap ClassLoader 没有父亲, 就只能自己动手来搜索了
- 如果找到了诶这个类, 就会进行后续的加载(也就是和 Extension 和 Application 都没关系了)
- 如果没有找到这个类, 任务就会仍然交回给 孩子 完成
- 任务回到了 Extend ClassLoader
- 就要搜索扩展库的目录, 看有没有匹配的 .Class 文件
- 如果找到了诶这个类, 就会进行后续的加载(也就是和 Extension 没关系了)
- 如果没有找到这个类, 任务就会仍然交回给 在 孩子 完成
- 任务回到了 Application ClassLoader
- 就要搜索第三方库的目录 (往往就是你项目目录, 以及和JVM 的一些配置项有关 -classpath 有关)
- 如果找到类, 就进行后续加载;
- 如果没找到, 就会抛出一个异常
双亲委派的目的
- 明确了优先级
- 标准库的类最先加载, 扩展库其次, 第三方库最低
- 避免了程序的代码对标准库产生的负面影响
2.3 类加载的时机
- 创建类的实例
- 使用了类的静态方法/静态属性
- 子类的加载就会触发父类
类加载的之后, 就不需要再次加载了;
所以类加载是以懒汉模式进行加载的~
类卸载 (把类对象干掉)
-
特殊情况
-
一般来说类加载了之后, 就不必考虑卸载, 一直保持到程序运行结束
-
有特定的场景, 可能需要用到 卸载 操作
- 有的服务器, 需要打 “热补丁”
- 代码有bug, 正常操作应该是修改代码, 重新编译, 用新版本的程序替代就版本 – 重启服务器
- 有些情况, 服务器不方便重启, 就可以 “打补丁”, 通过一些特殊手段, 把需要提黄的类给卸载掉, 直接用加载好的 类 替换 (新版代码), 这样不重启也能更新代码
3. 垃圾回收机制
3.1 为什么会存在垃圾回收机制?
内存泄漏
- 垃圾就是进程向操作系统申请内存, 使用完后没有释放, 导致内存泄漏
- 内存泄漏是一件很危险的事情, 短时间看起来程序运行正常, 而内存泄漏一段时间后, 服务器就会出现明明正在使用的内存挺少的, 但是就是无法再次申请内存了!
- 内存泄漏就像一个不定时的定时炸弹一样, 十分的危险
各个语言的解决方法
- C语言: 完全靠程序员手动释放(不靠谱)
- C++: 引入了只能指针问题
- java / Python / Ruby / PHP / Go: 引入了垃圾回收 (GC)
- 最大程度释放了程序员
- 但是需要消耗额外的系统资源, 消耗一定的时间, 可能会带有 STW 问题
- Rust 另辟蹊径, 强编译期检查
- 号称是能够做到更高效, 更强大的释放内存的效果, 内存安全
- 但是语法复杂, 与C++的语法有过犹而不及, 上手困难
3.2 垃圾回收, 到底实在做什么?
对于java来说, 回收其实是 “对象” 而不是 “字节”, GC 并非判定几个字节是不是垃圾, 进一步的进行回收的
JVM 中有好几个内存区域, GC 回收的是哪里的对象?
- 栈空间不需要 GC 回收, 栈里面包含很多 “栈帧”, 每个栈帧对应一个方法, 该方法执行结束, 此时这个栈帧就销毁了; 栈帧上的局部变量是啥的自然销毁;
- 程序计数器同理, 线程销毁, 自然跟着销毁
- 方法区, 类对象, 很少会涉及到对象的卸载
- 所以, 堆是GC的主要战场!!
3.3 垃圾回收的两步骤
第一步: 判断对象是否是"垃圾"
"垃圾"的定义
- 如果一个对象, 在后续代码中, 不会被继续使用到了, 就可以视为是垃圾了
- 也就是说, 一个对象, 如果没有任何引用指向他, 就可以认为是垃圾了
- 所以, 判断一个对象是否是垃圾的关键, 就是看这个对象是否有引用指向它
判读是否是垃圾的思路一: 引用计数
-
原理
- 给对象里面安排一个计数器, 每次有引用指向它, 就把计数器 +1, 每次引用被销毁, 计数器 -1, 当计数器 为0 的时候, 意味着该对象就是垃圾了
-
缺点
- 空间利用率比较低, 浪费更多个内存空间
- 如果引用计数分配了 2 哥字节, 对象本体才 4 个字节的话, 引用计数就浪费了 50 % 的空间, 如果代码中都是这种小对象, 并且数量众多, 此时浪费就非常明显了
- 存在循环引用的问题, 导致对象不能正确识别为垃圾
- 空间利用率比较低, 浪费更多个内存空间
-
注意: 该思路不是JVM采用的方案
判读是否是垃圾的思路二: 可达性分析 – JVM 采用的方案
- 原理
- JVM 首先会从现有代码中的能直接访问到的引用出发, 尝试遍历所有能够访问的对象, 只要对象能访问到, 就会标记成 “可达”, 完成整个遍历之后, 可达之外的对象, 也就是不可达, 也就相当于是垃圾了
- 直接访问到的引用:
- 栈上的局部变量
- 常量池里的引用
- 方法区中的静态成员
- 缺点
- 存在遍历扫描, 所以需要消耗一定的时间, 但是不会引入额外的空间
- 代码执行过程中, 一个对象是否是垃圾, 这件事, 往往是 “动态变化” 的;
- 上述可达性分析的扫描,是持续的, 周期性的
第二步: 如何回收垃圾
方法一: 标记清除(直接释放)
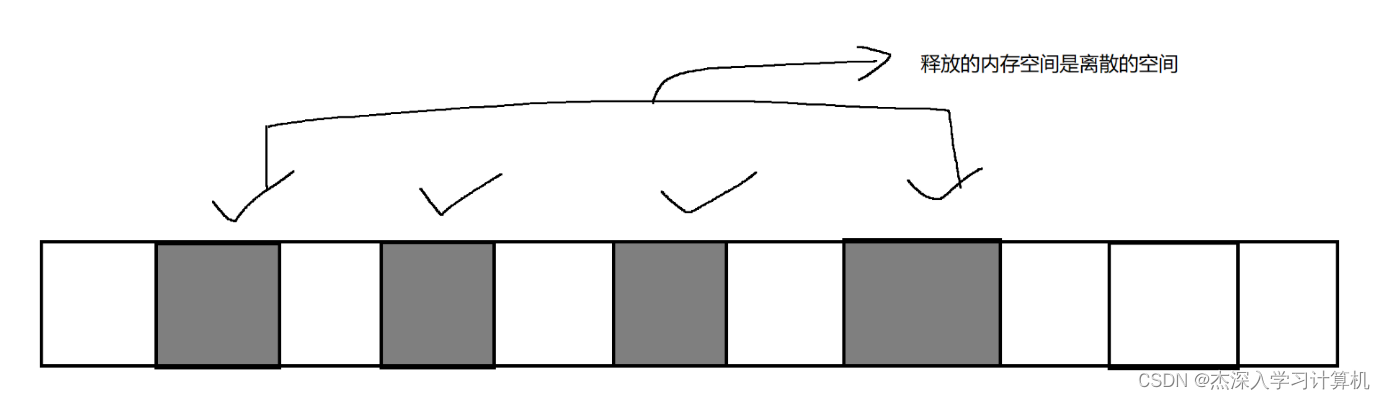
- 直接释放对象, 就可能引起 “内存碎片化”
- 申请内存的时候, 都是申请的 “连续” 内存空间
- 释放内存, 就可能会破坏原有的连续性 – 导致 “有内存, 但是申请不了”
- 这种问题, 还是挺严重的, 内存碎片化随着程序的运行越来越多, 越来越碎片化, 内存就更难申请了
方法二: 复制算法
- 通过冗余的内存空间, 把有效对象复制到另一部分空间, 避免内存碎片化
- 把一个对象, 分成两份, 用一份, 丢一份
- 把左侧区域中, 有效的对象, 复制到右侧
- 接下来就可以使用右侧区域了, 用了一段时间, 也会有很多对象, 也是同理, 把有效对象复制会左边, 把右侧区域统一释放
- 但是复杂的内容多, 开销很大, 而且内存利用率也不高
方法三: 标记整理
- 顺序表删除元素, 搬运
- 这样的方法, 避免了刚才复制算法内存利用率低的问题
- 但是, 搬运元素的成本, 也是比较高的
JVM 采用的方法 – 集百家之长 : 分代回收
- 结合上述方案, 做了一个综合性质的方案
- 在不同的场景下, 使用不同的回收方式, 扬长避短
分代回收
-
一个基本的"经验规律"(通过实验观察, 总结出来的规律) : 一个东西存在的越久, 继续存在的可能性就很高
-
Java 中, 对象也就分成两大类
- 生命周期特别特别短的
- 生命周期特别特别长的
- 当然也有不长不短的(出现概率更低)
-
Java中对象的年龄是依据 GC 扫描次数来增长的, 挺过一次扫描就增长一次
-
按照对象的年龄来指定不同的回收策略
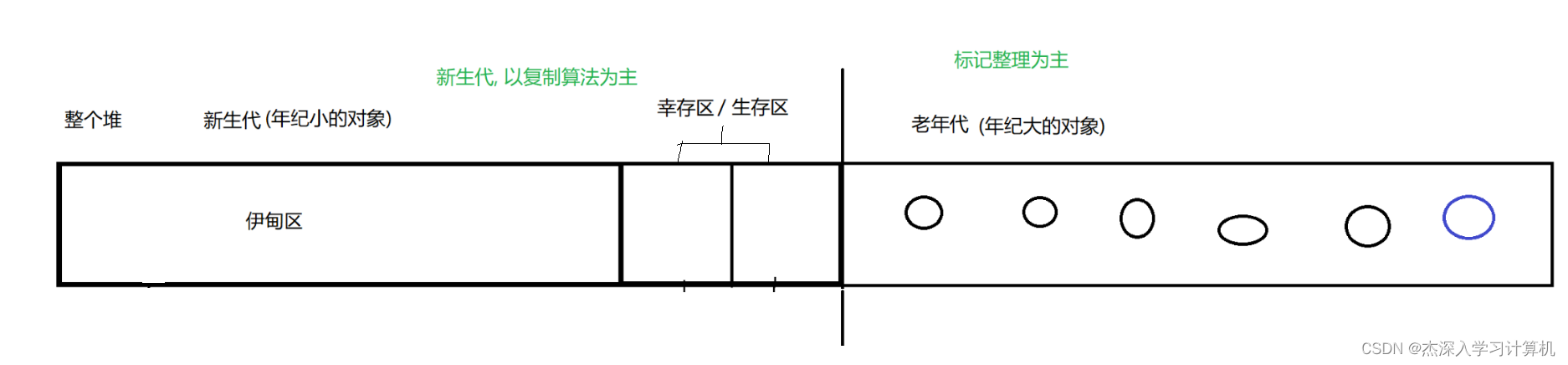
-
新生的对象
- 伊甸区
- 虽然空间看起来不小, 实际上这里的对象, 绝大部分无法活过一轮 GC – 第一轮 GC 扫描到达的时候, 这个对象就已经是垃圾了
- 第一轮 GC 经过之后, 剩下的还没挂的对象, 就会通过复制算法, 复制到 幸存区
- 幸存区
- 这里是大小相同的两部分空间, 每次只有其中一块
- 继续使用复制算法
- 如果一个对象在幸存区中, 经过了好多轮, 仍然坚挺没有挂, 则就说明这个对象应该是 "生命周期特别长"的了, 这个时候, 对象来到了老年代了
- 伊甸区
-
老年代对象
- 采用标记整理的方法来释放内存
-
新生代, 扫描频次是比较高的; 每一轮 GC 留下的有效对象都不多, 复杂算法的开销不大
-
老年代, 扫描频次就降低了; 不太会有对象真销毁, 此时标记整理的开销也不大



![[原创]Cadence17.4,win64系统,构建CIS库](https://img-blog.csdnimg.cn/3800958cf6174a19bdec33d4576ba5ae.png)
![[LeetCode] 2.两数相加](https://img-blog.csdnimg.cn/0b28e0acd1a74e1ca7a12d90a79a70bd.jpeg#pic_center)