什么是人工智能中的检索增强生成(RAG)?
检索增强生成 (RAG),与你的文档聊天的超级英雄,架起信息检索和文本生成世界的桥梁! 这就像福尔摩斯和莎士比亚联手解决需要大量知识的复杂任务。 RAG 突然介入,从维基百科或公司知识库等外部来源获取最相关的信息,将其与输入混合,瞧! 它生成带有参考的综合输出。如果你还想对 RAG 有更多的了解,请详细阅读我之前的文章 “Elasticsearch:什么是检索增强生成 - RAG?”。
🔍 解开 RAG:RAG 将从庞大数据库中检索信息的能力与生成类人文本的艺术无缝地结合起来。 这就像图书管理员取到了合适的书,而讲故事的人则完美地讲述它! RAG 在最终生成过程之前添加了中间信息检索步骤。

在我之前的文章 “Elasticsearch:与多个 PDF 聊天 | LangChain Python 应用教程(免费 LLMs 和嵌入)”,我有一个实现:
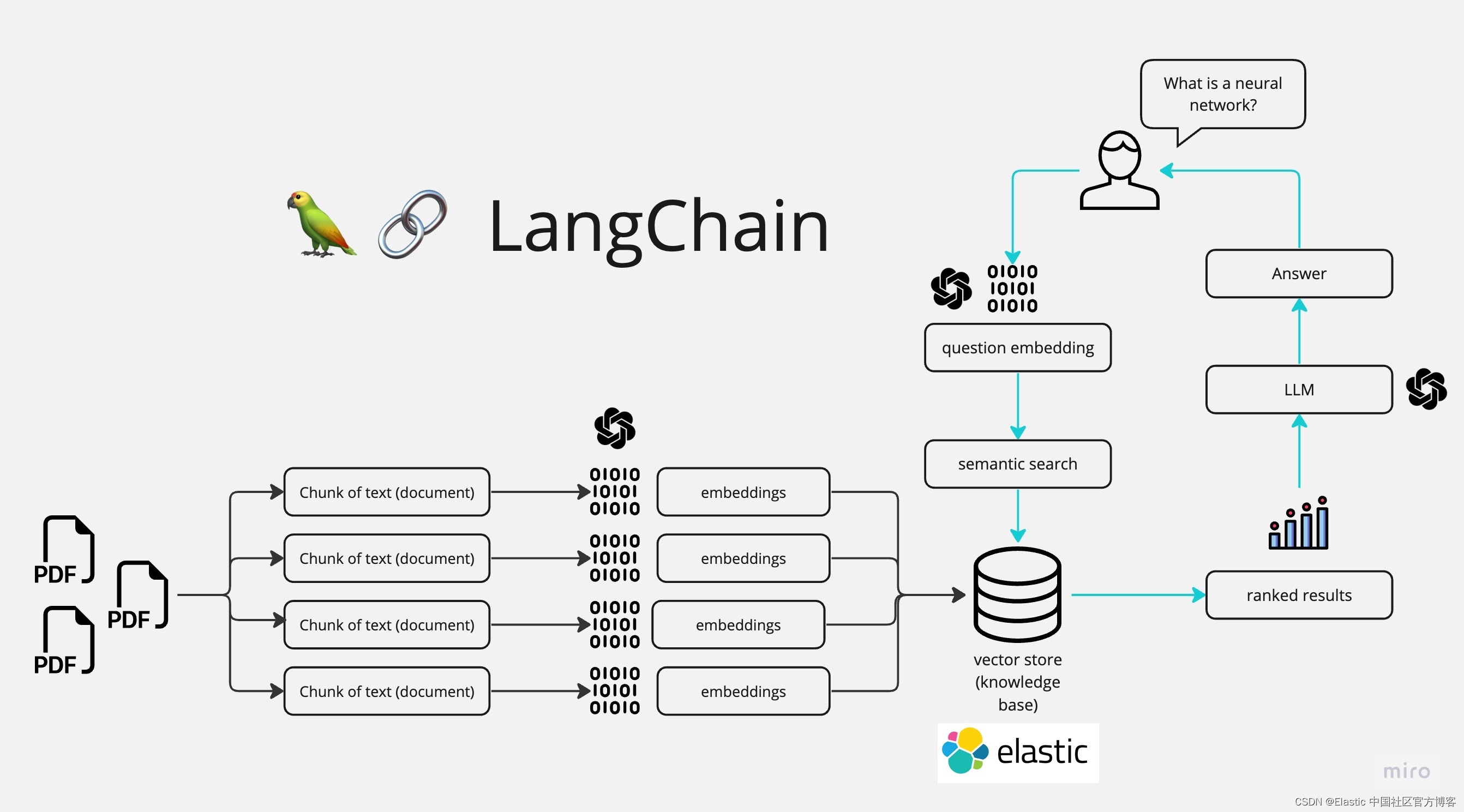
请详细参阅那篇文章进行详细的阅读。
RAG 解决了什么问题?
- 它为大型语言模型提供了在生成响应时要考虑的最重要的上下文。
- 通过检索有用的信息,它提供了一种避免幻觉的方法,因为提示中给出了所需的信息。
- 它为 LLM 提供了无限的上下文窗口以提供有用的输出。
- 为非结构化数据提供对话接口。
利用 Langchain 和 GPT4ALL 来利用 RAG:深入探讨
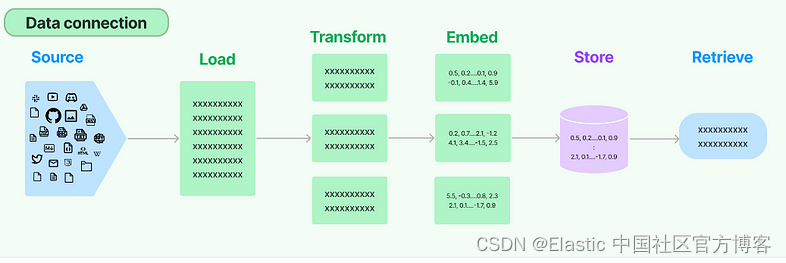
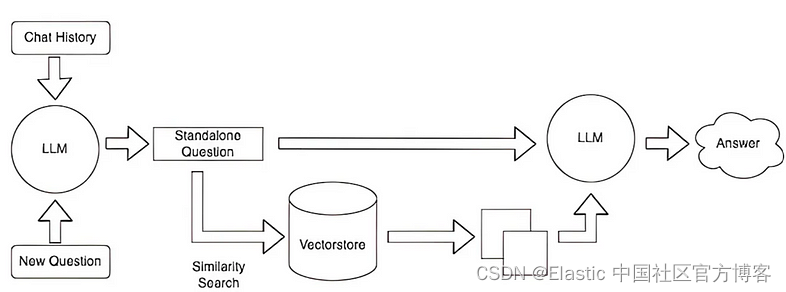
- 加载你的数据:首先加载你的文本文档,无论是研究论文、博客还是商业报告。 Langchain Lib 提供了无缝集成各种数据源的工具。 即使你有 PDF,Langchain 也可以将其内容转换为可处理的格式。
- 分割和存储:加载后,文档被分割成可管理的块(chunks)。 然后,这些块被转换为嵌入、文本的数字表示,并存储在向量数据库中,无论是本地数据库还是基于云的数据库。 你的文档可能分为 “Introduction”、“Method” 和 “Results” 等部分。 然后将每个部分转换为嵌入并存储。
- 为你的数据建立索引:( Elasticsearch ) 在检索之前,对你的数据建立索引非常重要。 通过创建索引,你可以制作一张地图,以便根据相似性等标准快速定位向量。 将其视为书中的索引,引导你找到特定信息
- 询问和检索:提出问题,系统会在向量数据库中搜索与你的查询最相关的嵌入。 示例:询问“ 这篇研究论文基于什么概念/甚至你自己的文档中的本地详细信息(财务/任何特定领域)?” 可能会从 “Introduction” 或特定的 “Applications” 部分检索嵌入。
- 生成响应:有了相关块,高级语言模型甚至使用 GPT4ALL 的本地语言模型(如果你不希望数据离开你的场所)或其他本地/云 LLM 都会制作出连贯的、类似人类的响应。

RAG 的优势:
- 效率优于微调:绕过传统模型训练。 RAG 直接从你的向量数据库中提取详细信息,确保准确、上下文感知的答案。有关 RAG 及微调之间的区别,请参考文章 “Elasticsearch:RAG vs Fine-tunning (大语言模型微调)”。

- 你的数据,你的规则:将你的数据转换为嵌入并将其存储在向量数据库中,确保控制和隐私。 你并不是把你的数据推出去;而是你正在引入人工智能!
- 本地还是云?:RAG 的优点在于其灵活性。 无论你使用本地 LLMs 还是 OpenAI 等云。 像 Elasticsearch 这样的本地向量数据库,底层的魔力仍然是 RAG 模型。
为什么令人兴奋?:想象一下与你的文档聊天,释放新的可能性,并简化吗的交互。 从专业人士到学生,应用无穷无尽!
想象一下:企业的知识任务生产力提高了 50%,这一切都归功于 RAG! 这不仅仅是公司优化资源的问题; 正如高盛预测的那样,GDP 可能增长 7%。 RAG 迎来了知识助手时代,前景令人激动。 想象一下,人工智能盟友可以简化企业数据、与企业系统联络并提高团队士气。 RAG 和大型语言模型 (LLM) 是推动我们走向未来的动态组合,我们正在加速进入人工智能驱动的未来。 准备好参与这场革命了吗? 搭乘 RAG 快车!
更多关于如何使用 Elasticsearch 结合 LLMs 的示例,请参阅链接 AI。







![[开源]企业级在线办公系统,基于实时音视频完成在线视频会议功能](https://img-blog.csdnimg.cn/img_convert/7d5a07a3d4e524f20c4ea3d5243129c8.png)