一、python爬取WOS总体思路
(一)拟实现功能描述
wos里面,爬取论文的名称,作者名称,作者单位,引用数量
要求:英文论文、期刊无论好坏
检索关键词:zhejiang academy of agricultural sciences、 xianghu lab
(二)操作思路介绍
在Python中,有多种思路可以用来爬取Web of Science(WOS)上的信息。以下是其中几种常见的思路:
-
使用HTTP请求库和HTML解析库:这是最常见的爬取网页数据的方法之一。你可以使用Python的
requests库发送HTTP请求获取网页内容,然后使用BeautifulSoup或其他HTML解析库对网页进行解析和提取所需的信息。 -
使用API:有些网站提供API接口,允许开发者通过API直接获取数据。如果WoS提供API,你可以通过调用API进行数据获取,通常这种方式更加稳定和高效。
-
使用自动化工具:有些情况下,使用传统的HTTP请求和HTML解析方式难以实现数据的完整爬取,例如需要登录或执行JavaScript等情况。此时,你可以使用自动化工具,如
Selenium,来模拟用户操作浏览器,实现完整的页面渲染和数据提取。
无论选择哪种思路,都需要先了解目标网站的页面结构和数据提取的逻辑。可以通过分析网页源代码、使用浏览器开发者工具等方式来理解网页的结构和数据的位置。
(三)操作步骤分解
以操作思路三为例,在WOS上爬取英文论文的名称、作者名称、作者单位和引用数量,以满足给定的检索关键词(zhejiang academy of agricultural sciences和xianghu lab)的操作步骤:
-
确定使用的爬虫库:可以使用Python的Selenium库进行网页自动化操作,实现模拟浏览器操作的效果。
-
安装必要的依赖库:需要安装Selenium库,以及用来管理Chrome浏览器驱动的webdriver-manager库。可以使用pip命令安装相关依赖库。
-
导入必要的模块:需要导入Selenium库的Webdriver和Service类,webdriver_manager库的ChromeDriverManager类,以及time库,用于实现等待页面元素加载的效果。
-
设置Chrome浏览器驱动并启动浏览器:通过创建ChromeDriverManager实例来管理Chrome浏览器驱动,并使用webdriver的Chrome类来启动浏览器。
-
打开Web of Science网站:使用driver.get()方法打开Web of Science网站,并使用time库实现等待页面加载,确保可以正常爬取相关信息。
-
在搜索框中输入关键词并进行搜索:使用find_element()方法找到搜索框的元素,并使用send_keys()方法输入需要搜索的关键词。然后,使用find_element()方法找到搜索按钮的元素,并使用click()方法点击搜索按钮,实现对关键词的检索。
-
切换到结果列表视图:使用find_element()方法找到结果列表视图下拉框的元素,并使用click()方法切换到结果列表视图。使用time库实现等待视图切换,确保可以正常爬取相关信息。
-
循环遍历每个检索结果,提取所需信息:使用find_elements()方法找到每个检索结果的元素列表,循环遍历列表中每一个元素,使用find_element()方法分别找到论文名称、作者名称、作者单位和引用数量的元素,并使用text属性来获取对应的文本信息。(整理格式成我们所需要的样子)
-
关闭浏览器:使用quit()方法关闭浏览器,释放相关系统资源。
备注:在实际操作中,需要注意遵守相关法律法规和网站的规定,以确保合规的操作。
二、python爬取实战步骤
(一)导入必要的库
import requests
from bs4 import BeautifulSoup
import csv
import time,random(二)存储和处理从HTML页面中提取的数据。
class HtmlData:def __init__(self, soup):self.title = '' # 存储文章标题self.author = '' # 存储文章作者self.abstract = '' # 存储文章摘要self.keywords = '' # 存储文章关键词self.author_data = '' # 存储作者信息self.author_unit = '' # 存储作者单位self.citation_count = '' # 存储引用数量self.data = '' # 存储数据信息self.soup = soup # 存储BeautifulSoup对象
# 第二步,HtmlData类的构造函数初始化了存储文章标题、作者、摘要、关键
# 词等信息的实例变量,并通过BeautifulSoup解析HTML文本提取这些信息。print(soup.prettify())self.title = soup.title.text# self.title = soup.find(attrs={'class':'title'}).text.replace('\n','') # 提取文章标题try:self.data = soup.find(attrs={'class':'block-record-info block-record-info-source'}).text # 提取数据信息except:passitems = soup.find_all(attrs={'class':'block-record-info'}) # 提取所有block-record-info元素for item in items:if len(item.attrs['class']) > 1:continueif 'By:' in item.text: # 提取作者信息和作者单位author_info = item.text.replace('By:', '').replace('\n', '').replace(' ', '').replace(' ]', ']')author_info_parts = author_info.split(',')if len(author_info_parts) > 1:self.author = author_info_parts[0].strip()self.author_unit = author_info_parts[1].strip()else:self.author = author_info_parts[0].strip()elif 'Times Cited:' in item.text: # 提取引用数量self.citation_count = item.text.replace('Times Cited:', '').strip()elif 'Abstract' in item.text: # 提取摘要信息self.abstract = item.textcontinueelif 'Keywords' in item.text: # 提取关键词信息self.keywords = item.textcontinueelif 'Author Information' in item.text: # 提取作者信息self.author_data = item.text continue
(三)提取html文本并保存到csv文件
scrape_data函数接收一个URL作为参数,发送HTTP请求获取页面内容,使用BeautifulSoup解析HTML文本,创建HtmlData对象提取数据,并将数据写入CSV文件。
def scrape_data(url):headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",}response = requests.get(url, headers=headers) # 发送HTTP请求获取页面内容if response.status_code == 200: # 检查请求的状态码是否为200(成功)html = response.text # 获取响应的HTML文本soup = BeautifulSoup(html, 'lxml') # 使用BeautifulSoup解析HTML文本html_data = HtmlData(soup) # 创建HtmlData对象进行数据提取和存储# 获取对象信息title = html_data.title # 获取标题authors = html_data.author # 获取作者author_unit = html_data.author_unit # 获取作者单位citation_count = html_data.citation_count # 获取引用数量abstract = html_data.abstract # 获取摘要keywords = html_data.keywords # 获取关键词# 存储数据到csvcsv_data = [title, authors, author_unit, citation_count, abstract, keywords, url] # 构建CSV行数据print(csv_data)with open('1.csv', encoding='utf-8', mode='a', newline='') as f:csv_writer = csv.writer(f) # 创建CSV写入器csv_writer.writerow(csv_data) # 将数据写入CSV文件(四)生成url列表,开始爬虫
第四步,main函数生成URL列表,遍历URL列表调用scrape_data函数进行数据爬取和处理。
def main():url_list = []search_keywords = 'zhejiang academy of agricultural sciences'#xianghu labfor i in range(1, 3218): # 构建URL列表url = f"http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=GeneralSearch&qid=1&SID=5BrNKATZTPhVzgHulpJ&page=1&doc={i}&cacheurlFromRightClick=no"url += f"&field=Author&value={search_keywords}"url_list.append(url)time.sleep(1+random.random())# print(url_list) for url in url_list:scrape_data(url) # 遍历URL列表,爬取并处理数据if __name__ == '__main__':main()
(1) 备注:根据搜索完成页面进行爬取。
# 定义一个函数来获取单个页面的数据。这个函数将接受一个URL作为参数,
# 并返回一个包含论文名称、作者名称、作者单位和引用数量的字典列表。
def get_page_data(url):headers = {'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/104.0.5112.79 Safari/537.36'}response = requests.get(url, headers=headers)soup = BeautifulSoup(response.text, 'html.parser')# Find the target elements based on their HTML tags and attributes# The actual tags and attributes might need to be adjusted based on the website's structurepapers = soup.find_all('div', attrs={'class': 'paper'})data = []for paper in papers:name = paper.find('div', attrs={'class': 'name'}).textauthor = paper.find('div', attrs={'class': 'author'}).textaffiliation = paper.find('div', attrs={'class': 'affiliation'}).textcitations = paper.find('div', attrs={'class': 'citations'}).textdata.append({'name': name,'author': author,'affiliation': affiliation,'citations': citations})return data# 定义一个函数来获取多个页面的数据。这个函数将接受一个基础URL和页面数量作为参数,
# 并返回一个包含所有页面数据的字典列表。
def get_multiple_pages(base_url, num_pages):all_data = []for i in range(1, num_pages+1):url = base_url + str(i)all_data.extend(get_page_data(url))time.sleep(1) # Add a delay between requests to avoid overloading the serverreturn all_data
(五)总体代码
# 导入必要的库
import requests
from bs4 import BeautifulSoup
import csv
import time,random# 第一步,定义HtmlData类,用于存储和处理从HTML页面中提取的数据。
class HtmlData:def __init__(self, soup):self.title = '' # 存储文章标题self.author = '' # 存储文章作者self.abstract = '' # 存储文章摘要self.keywords = '' # 存储文章关键词self.author_data = '' # 存储作者信息self.author_unit = '' # 存储作者单位self.citation_count = '' # 存储引用数量self.data = '' # 存储数据信息self.soup = soup # 存储BeautifulSoup对象
# 第二步,HtmlData类的构造函数初始化了存储文章标题、作者、摘要、关键
# 词等信息的实例变量,并通过BeautifulSoup解析HTML文本提取这些信息。print(soup.prettify())self.title = soup.title.text# self.title = soup.find(attrs={'class':'title'}).text.replace('\n','') # 提取文章标题try:self.data = soup.find(attrs={'class':'block-record-info block-record-info-source'}).text # 提取数据信息except:passitems = soup.find_all(attrs={'class':'block-record-info'}) # 提取所有block-record-info元素for item in items:if len(item.attrs['class']) > 1:continueif 'By:' in item.text: # 提取作者信息和作者单位author_info = item.text.replace('By:', '').replace('\n', '').replace(' ', '').replace(' ]', ']')author_info_parts = author_info.split(',')if len(author_info_parts) > 1:self.author = author_info_parts[0].strip()self.author_unit = author_info_parts[1].strip()else:self.author = author_info_parts[0].strip()elif 'Times Cited:' in item.text: # 提取引用数量self.citation_count = item.text.replace('Times Cited:', '').strip()elif 'Abstract' in item.text: # 提取摘要信息self.abstract = item.textcontinueelif 'Keywords' in item.text: # 提取关键词信息self.keywords = item.textcontinueelif 'Author Information' in item.text: # 提取作者信息self.author_data = item.text continue# 第三步,scrape_data函数接收一个URL作为参数,发送HTTP请求获取页面内容,使用BeautifulSoup解析HTML文本,创建HtmlData对象提取数据,并将数据写入CSV文件。
def scrape_data(url):headers = {'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/118.0.0.0 Safari/537.36",}response = requests.get(url, headers=headers) # 发送HTTP请求获取页面内容if response.status_code == 200: # 检查请求的状态码是否为200(成功)html = response.text # 获取响应的HTML文本soup = BeautifulSoup(html, 'lxml') # 使用BeautifulSoup解析HTML文本html_data = HtmlData(soup) # 创建HtmlData对象进行数据提取和存储# 获取对象信息title = html_data.title # 获取标题authors = html_data.author # 获取作者author_unit = html_data.author_unit # 获取作者单位citation_count = html_data.citation_count # 获取引用数量abstract = html_data.abstract # 获取摘要keywords = html_data.keywords # 获取关键词# 存储数据到csvcsv_data = [title, authors, author_unit, citation_count, abstract, keywords, url] # 构建CSV行数据print(csv_data)with open('1.csv', encoding='utf-8', mode='a', newline='') as f:csv_writer = csv.writer(f) # 创建CSV写入器csv_writer.writerow(csv_data) # 将数据写入CSV文件# 第四步,main函数生成URL列表,遍历URL列表调用scrape_data函数进行数据爬取和处理。
def main():url_list = []search_keywords = 'zhejiang academy of agricultural sciences'#xianghu labfor i in range(1, 3218): # 构建URL列表url = f"http://apps.webofknowledge.com/full_record.do?product=UA&search_mode=GeneralSearch&qid=1&SID=5BrNKATZTPhVzgHulpJ&page=1&doc={i}&cacheurlFromRightClick=no"url += f"&field=Author&value={search_keywords}"url_list.append(url)time.sleep(1+random.random())# print(url_list) for url in url_list:scrape_data(url) # 遍历URL列表,爬取并处理数据if __name__ == '__main__':main()三、python爬取过程中可能遇到的问题及解决方案
(一)代码运行问题排除
Q1:ModuleNotFoundError: No module named 'webdriver_manager'
参考:使用ChromeDriverManager自动更新Chromedriver_Richard.sysout的博客-CSDN博客
解决方案:(1)安装的代码除了问题,输入的是:pip install webdrivermanager,应在控制台中输入以下内容:
pip install webdriver_manager(2)安装版本不对。
这里是selenium3.x的用法
from selenium import webdriver
from webdriver_manager.chrome import ChromeDriverManager
#安装并返回安装成功的path
driver_path=ChromeDriverManager().install()
#使用对应path下的driver驱动Chrome
driver = webdriver.Chrome(executable_path=driver_path)当然如果使用的是selenium4.x:
# selenium 4
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from webdriver_manager.chrome import ChromeDriverManagerdriver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))
通过它的源码,我们可以得知,基本的逻辑是将Chromedriver安装在某个目录下,将driver的目录返回给我们,创建对象的时候,将path 作为参数传入。
Q2:用soup.find()时出现错误AttributeError NoneType object has no attribute?
参考:AttributeError NoneType object has no attribute_soup.find 未找着-CSDN博客
原因及分析:我使用的soup.find()没有找到这个class为"ArticlePicBox Aid43 "的div中有空格。
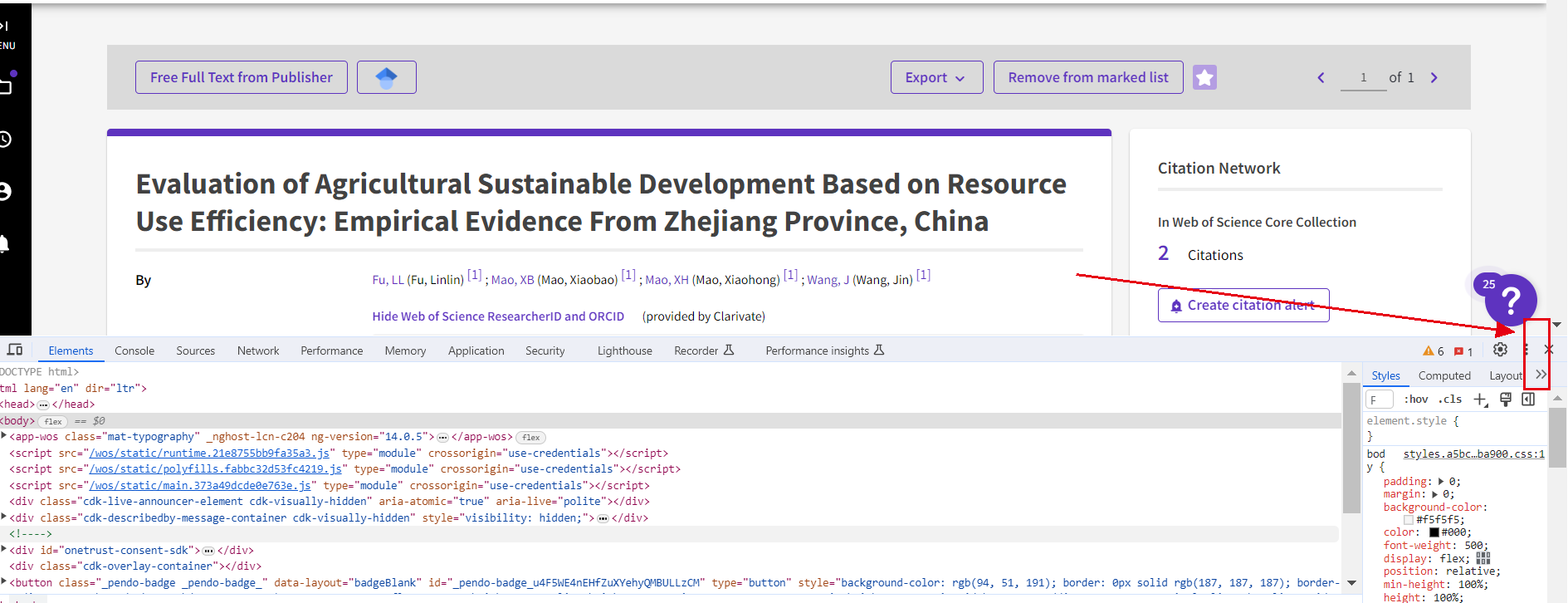
Q3:如何更改浏览器内开发工具的位置?
解决办法:
1.打开浏览器,点击F12,打开开发工具;
2.点击开发工具右上角的三个竖点;
3.出现若干个选项如图所示,可选择适合自己的排版(左右下或新增页);
Q4:如何获取一个网页的User-Agent?
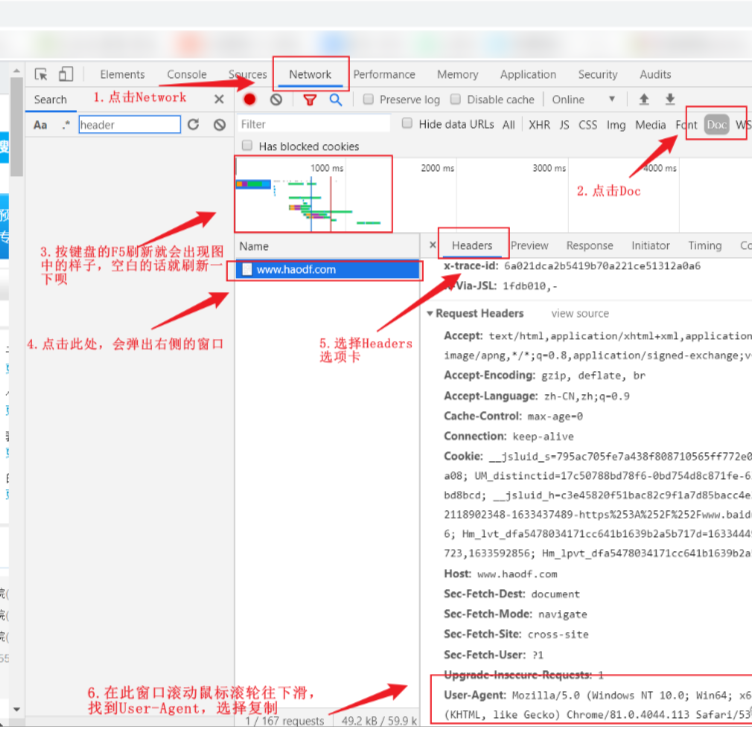

(二)相关知识补充
爬虫项目处理的一般步骤:1.找数据所在的地址(ur)是哪个? (网页性质分析<静态网页/动态网页>)<你要的/你不需要的》2.通过代码发送地址的请求(文本数据\js数据\css<祥式层叠表,数据\围片\...)3.数据的解析,解析你要的数据(正则表达式\css选择器 \xpath节点提取)4.数据保存(本地,数据库)。
(1)页面解析
# 据解析步聚# 1.转换数据类型(selector = parsel.Selector(html) # html字符串--> 对象# print(selector)# 2.css提取数据(# p = selector.css('p').get())。解析网页有三种方法:Xpath和正则表达式(re)及BeautifulSoup。
1)css选择器


2)Xpath
XPath 使用路径表达式在 XML 文档中选取节点。节点是通过沿着路径或者 step 来选取的

3)正则表达式(re)
可参考引用4。
(2)HTML元素




备注:html解析工具:HTML格式化 、HTML压缩- 站长工具 (sojson.com)
(3)多页面爬取url
典型的两段式爬取,每个页面有20篇文件,一共38页,分析页面url发现规律之后,只需要改变page={i},通过i的变化获取总url。在网页源代码中发现每篇文件单独的url都可以获取,任务相对比较简单。编写代码获取每篇文件的url,之后提取文字内容即可。
可参照参考三,其介绍的两类囊括了大部分提取方式。


四、参考引用
[1]Web of science文章信息爬取_爬取web of science数据
[2]User-Agent||如何获取一个网页的User-Agent?-CSDN博客
[3]Python爬虫——爬取网站多页数据_爬虫多页爬取-CSDN博客
[4]Xpath和正则表达式及BeautifulSoup的比较-CSDN博客