最终实现效果如下
包含增加复选框 设置公式 设置背景颜色等,代码实在太多 有需要可留言

第一步:创建表头 请使用官网提供的网址:在线 Excel 编辑器 | SpreadJS 在线表格编辑器


1.点击下方+号,创建一个新的sheet页 默认新创建的sheet页名字是sheet8,这个县不用管,后续会修改
2.把你需要的表头粘贴进来
3.点击左上方的文件 ,接着按照图示例操作,就会得到一个js文件,我这里命名为aaa.js
第二步:
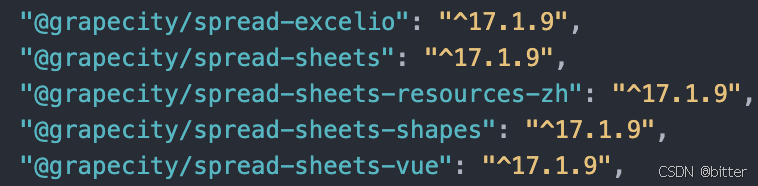
在vue文件install葡萄城必要的包,我引入的仅做为参考,此处根据项目需求进行增删包
第三步:
1.创建.vue文件,并引入包
<template><div class="spread-container"><gc-spread-sheetshost-class="work-sheet"@workbookInitialized="initWorkbook"><gc-worksheet /></gc-spread-sheets></div>
</template>
<script>
import '@grapecity/spread-sheets/styles/gc.spread.sheets.excel2016colorful.css'
import '@grapecity/spread-sheets-vue'
import * as GC from '@grapecity/spread-sheets'
import { IO } from '@grapecity/spread-excelio'
import { saveAs } from 'file-saver'
const spreadNS = GC.Spread.Sheets
import layoutData from './aaa.js'
</script>2.修改aaa.js
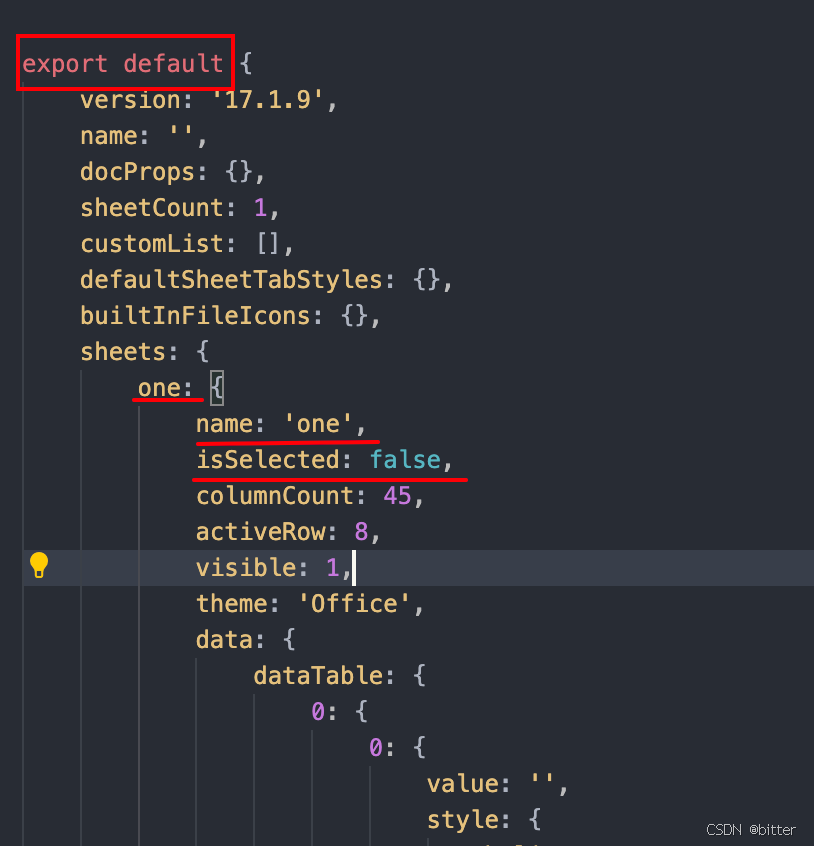
因为要import引入,所以需要修改原有的aaa.js的格式,变成图上示例的格式,具体需要修改的地方已用红色标记,其余不用修改,需要注意:one为原来的sheet8,此处可根据项目需要修改任意值
第四步:在methods中增加需要的方法
1.initWorkbook初始化工作簿
initWorkbook(spread) {this.loading = true// 设置spread基础样式this.ininSpreadStyle(spread)// 请求数据,渲染shetthis.renderFn(spread)},2.初始设施spread基础样式
// 初始设施spread基础样式ininSpreadStyle(spread) {this.spread = spreadspread.removeSheet(0)// 不允许修改表单名spread.options.tabEditable = false// 不允许用户通过点击“+”按钮(默认是显示)添加工作表。spread.options.newTabVisible = false// 不允许拖拽调整那个表单顺序spread.options.allowSheetReorder = false// 设置背景色为白色spread.options.grayAreaBackColor = '#fff'// 设置滚动条宽度spread.options.tabStripRatio = 0.6// 右键菜单清空spread.contextMenu.menuData = []// 绑定点击单元格事件 spread.bind(spreadNS.Events.SelectionChanged, (e, args) => {this.checkedCellInfo.axis = args.newSelections[0]this.checkedCellInfo.nameCode = args.sheet.nameCode})},3.请求数据 渲染sheet








![[读书日志]8051软核处理器设计实战(基于FPGA)第七篇:8051软核处理器的测试(verilog+C)](https://i-blog.csdnimg.cn/direct/edc900b7262f404891068de2db820922.png#pic_center)



![gesp(C++五级)(4)洛谷:B3872:[GESP202309 五级] 巧夺大奖](https://i-blog.csdnimg.cn/direct/2bdfd2bc374c4457b4dda267ce709a8e.png#pic_center)





