提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言:回顾顺序表的优缺点:
- 为什么要引入链式结构的线性表?
- 一、什么是链表?
- 二、链表的分类
- ①为什么要设置头节点?
- ②那头节点的info数据域可以放什么信息吗?
- ③链表有什么特点?从物理和逻辑上。
- 第一条:物理不连续,逻辑连续
- 第二条:只能由头指针去访问某一个数据,不能直接下标访问
- 第三条:增删容易,查改困难
- 三、单链表的代码语言表达和元素操作
- (1)代码语言怎么表示一个单链表呢?
- (2)基本操作之:求单链表的表长
- (3)基本操作之:获取单链表中第i个元素的内容
- (4)基本操作之:在单链表中插入一个新元素
- ①如果先执行p->next=s;再执行s->next=p->next;会怎么样?
- ②插入后示意图
- (5)基本操作之:单链表删除某一个节点
- (6)基本操作之:单链表的整表创建(头插法、尾插法)
- ①头插法(把新节点插入到尾节点之前)
- ②尾插法(把新节点插入到尾节点之后)
- 四、单链表与顺序表的比较与优缺点总结
- 五、循环链表
- (1)为什么要引出循环链表?
- (2)循环链表的定义:循环链表(Circular Linked List)是一种特殊的链表结构,其中最后一个节点的next指针指向链表的头节点,形成一个闭环。
- (3)如果要用O(1)的时间来访问尾节点,需要:指向终端节点的尾指针
- (4)如果要将两个均含有尾指针的循环链表合并成一个链表,应该怎么做?
- 七、双向链表
- (1)为什么要引入双向链表?
- (2)双向链表是什么?
- (3)双向链表的插入和删除结点操作
- 八、线性表这一大块的总结
前言:回顾顺序表的优缺点:
优点:
随机访问:由于元素在数组中是连续存储的,可以通过下标直接访问任意位置的元素,具有快速的随机访问速度。
空间效率高:顺序存储结构只需要额外的一个数组来存储元素,不需要额外的指针等辅助空间,因此空间利用率高。
索引操作简单:通过下标索引即可访问和修改元素,操作简单明了。
缺点:
插入和删除操作耗时:在顺序存储结构中,插入和删除操作需要将插入或删除位置后面的元素依次后移或前移,需要移动大量元素,因此耗时较长。
动态扩容困难:顺序存储结构的数组大小是固定的,如果线性表的元素个数超过了数组的容量,需要重新分配更大的数组并将元素复制到新数组中,麻烦。
内存浪费:如果线性表的元素个数远小于数组的容量,会造成内存的浪费,因为数组的大小是固定的。
所以,我认为顺序表的最大特点:物理连续,逻辑连续。随机存取,直接访问。查改容易,增删困难。由于随机存取的特点可以快速定位和修改元素,但是要插入或者删除元素需要整体前后移动其他元素,很浪费时间。
为什么要引入链式结构的线性表?
由于顺序表的最大特点:随机存取,下标直接访问元素。查改容易,增删困难。顺序表插入和删除元素时要移动大量的元素,我们需要用一种新的结构来实现容易增删。而链表可以解决这个问题。
一、什么是链表?
链表是一种常见的数据结构,用于存储和组织数据。它由一系列节点组成,每个节点包含一个数据元素和一个指向下一个节点的指针。链表中的节点不一定是连续存储的,而是通过指针链接在一起。
链表分为单向链表和双向链表两种形式。
单向链表:每个节点包含一个数据元素和一个指向下一个节点的指针。最后一个节点的指针为空,表示链表的结束。
双向链表:每个节点包含一个数据元素、一个指向前一个节点的指针和一个指向下一个节点的指针。双向链表可以向前或向后遍历。
这里举一个例子:
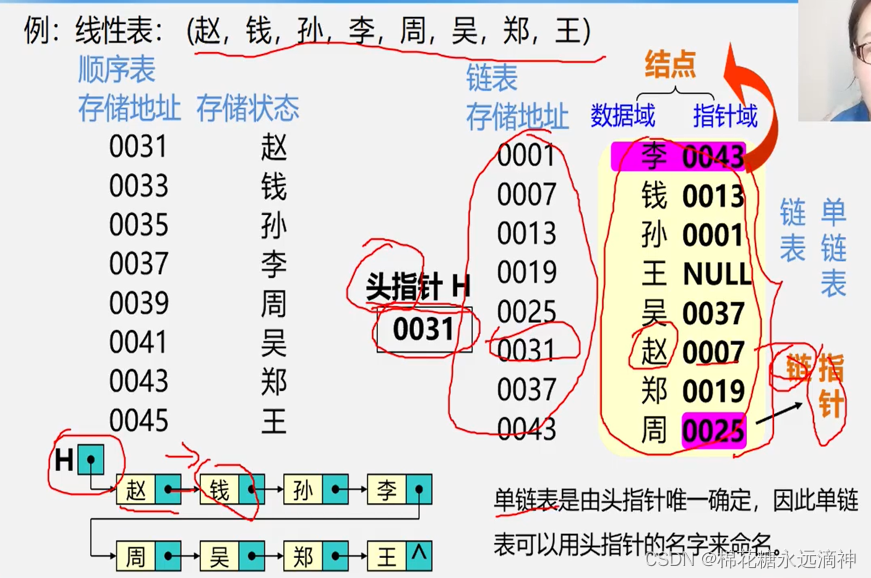
顺序表存储八个姓氏的话,是按照物理地址依次递增存储的,要找哪个姓,就直接查找位置下标索引即可。但是如果存入链表中,第一个元素是赵,在内存的31号位置,但是下一个元素钱却不是33,而是随机的7号位置,这8个姓氏的物理内存位置是随机排布的。那么如何表现这些元素的逻辑关系呢?
每个节点包含两个部分:一个数据元素和一个指向下一个节点的指针,用指针来指向下一个节点的位置关系。

一个链表是由许多个节点构成的,节点之间用指针(链)来逻辑相连(物理不相连)。一条链表包含一个头节点和一个尾节点,中间是许多普通节点。
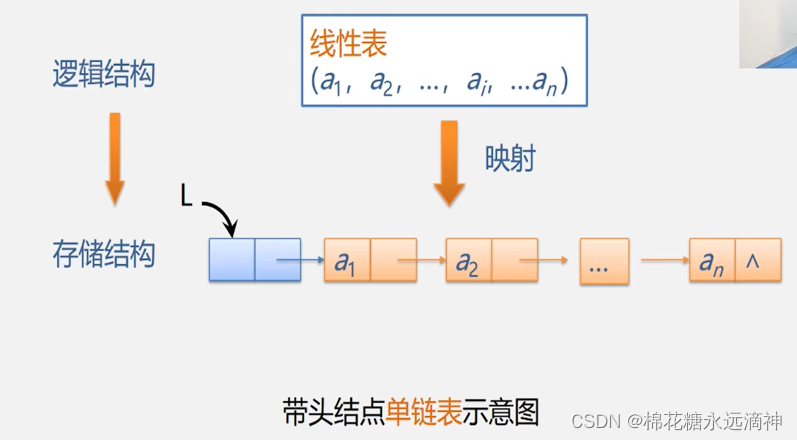
二、链表的分类
就是单链表、双链表、循环链表
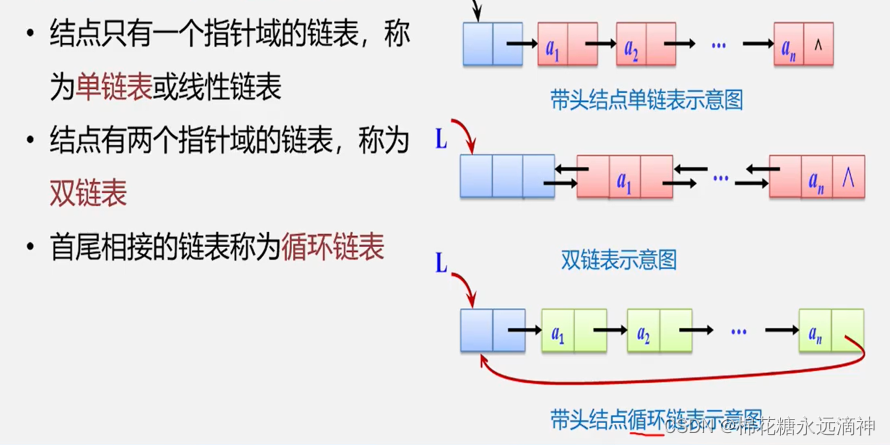
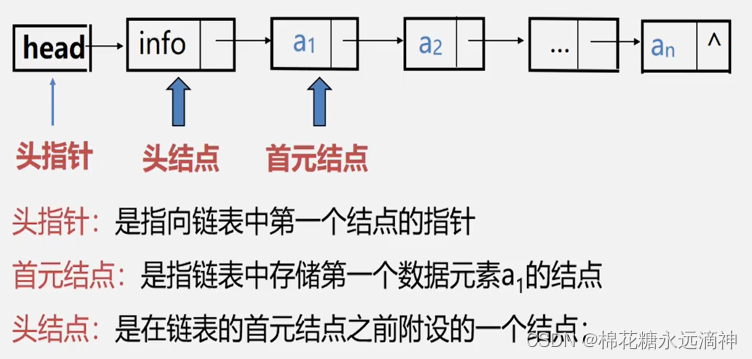
这里首先明确几个概念:
头指针:指向头节点的指针
头节点:链表中不存储数据的第一个节点。(存储数据前的一个节点)
首元节点:首元节点是指链表中第一个存储有效数据的节点。
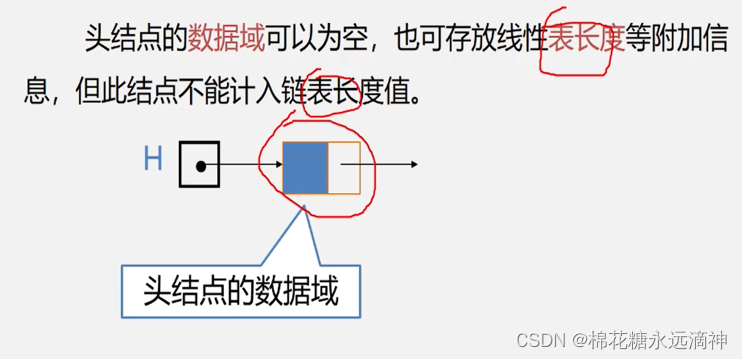
①为什么要设置头节点?

②那头节点的info数据域可以放什么信息吗?
③链表有什么特点?从物理和逻辑上。
先来总结:物理不连续,逻辑连续。只能由头指针去访问数据,不能直接访问。增删容易,查改困难
第一条:物理不连续,逻辑连续
链表中的节点通过指针链接在一起,每个节点存储着数据以及指向下一个节点的指针。在内存中,这些节点可以存储在任意的地址上,它们的物理存储位置是不连续的。这也是链表相对于顺序表的一个主要区别,顺序表中的元素是连续存储的。
然而,从逻辑上看,链表的节点是按照一定的顺序链接在一起的,通过节点之间的指针可以顺序访问链表中的每个节点。这种逻辑上的连续性使得链表可以依次访问或遍历链表中的所有元素。
第二条:只能由头指针去访问某一个数据,不能直接下标访问
链表的节点通过指针链接在一起,每个节点包含一个数据元素和一个指向下一个节点的指针。我们只能通过头指针来找到链表的入口,然后通过遍历链表中的节点,依次访问每个节点的数据。
这是因为链表中的节点是按照一定顺序链接在一起的,没有像数组那样可以通过索引直接访问特定位置的元素。要访问链表中的某个数据,需要从头节点开始,通过指针依次遍历链表中的节点,直到找到目标节点。
因此,链表的访问操作需要从链表的头指针开始,逐个遍历节点,直到找到目标数据。这也是链表相对于数组的一个局限性,链表的访问速度相对较慢,时间复杂度为O(n)。
第三条:增删容易,查改困难
由于链表的节点通过指针链接在一起,插入和删除节点只需要改变指针的指向,而不需要移动节点本身。因此,链表在插入和删除操作上具有较好的时间复杂度,通常为O(1)。
然而,链表在查找和修改操作上相对困难。由于链表中的节点是按照一定顺序链接在一起的,要查找或修改特定的数据,需要从头节点开始遍历链表中的节点,直到找到目标节点。这导致查找和修改操作的时间复杂度较高,通常为O(n)。
另外,由于链表的节点是通过指针链接在一起的,链表的访问是单向的,只能从头节点开始依次遍历。如果需要在链表中进行反向遍历或直接访问某个特定位置的节点,需要进行额外的操作。
三、单链表的代码语言表达和元素操作

(1)代码语言怎么表示一个单链表呢?
typedef struct Node
{ElemType data: struct Node *next ;
) Node;
typedef struct Node *LinkList; //定义 LinkList
首先使用 typedef 定义了一个结构体 Node,其中包含了数据部分 data 和指向下一个节点的指针 next。然后,我们使用 typedef 定义了一个 LinkList 类型,它是一个指向 Node 结构体的指针。
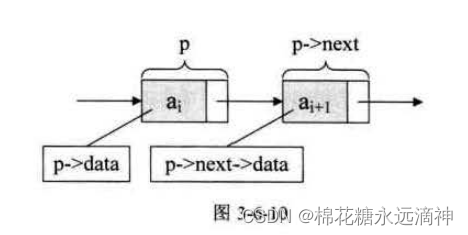
从这个结构定义中,我们也就知道,结点由存放数据元素的数据域和存放后继结点地址的指针域组成。假设p是指向线性表第i个元素的指针,则该结点a的数据域我们可以用p->data来表示,p->data的值是一个数据元素,结点a的指针域可以用p->next来表示,p->next的值是一个指针。p->next 指向谁呢?当然是指向第t1个元素,即指向a+1的指针。也就是说,如果p->data=ai,那么p->next->data=ai+1(如图)
(2)基本操作之:求单链表的表长
思路:我的思路是声明一个节点P,让P指向链表的第一个节点,然后每次让p指向下一个节点,计数值+1,直到最后指向空了,就遍历完了链表
代码:
int getLength(Node* head) {int count = 0;Node* p = head;while (p != NULL) {count++;p = p->next;}return count;
}
定义了一个结构体 Node 来表示单链表的节点,其中 data 表示节点的数据,next 是指向下一个节点的指针。然后通过遍历链表的每个节点来递增计数器的值,直到遍历到链表的最后一个节点。
(3)基本操作之:获取单链表中第i个元素的内容
思路:参数无需修改原链表内容,所以是值传递。由于没办法直接按照序号获取,只能从头节点向后遍历,定义一个指针p,不断指向后一个节点,直到第i个节点,提取数据域内容。
方法一:

由于单链袤的结构中没有定义表长,所以不能事先知道要循环多少次,因此也就不方便使用 for来控制循环。其主要核心思想就是 操作指针后移 ,这其实也是很多算法的常用技术。
方法二:
int getNthElement(Node* head, int n) {int count = 0;Node* current = head;while (current != NULL) {if (count == n) {return current->data;}count++;current = current->next;}printf("索引超出链表范围\n");exit(1);
}
函数 getNthElement 用于获取单链表中第 i 个元素的内容。它使用一个计数器 count 来记录当前遍历到的节点位置。通过遍历链表,当计数器 count 等于目标位置 n 时,返回当前节点的数据。如果遍历完链表都没有找到对应位置的节点,则打印错误信息并退出程序。
(4)基本操作之:在单链表中插入一个新元素
思路: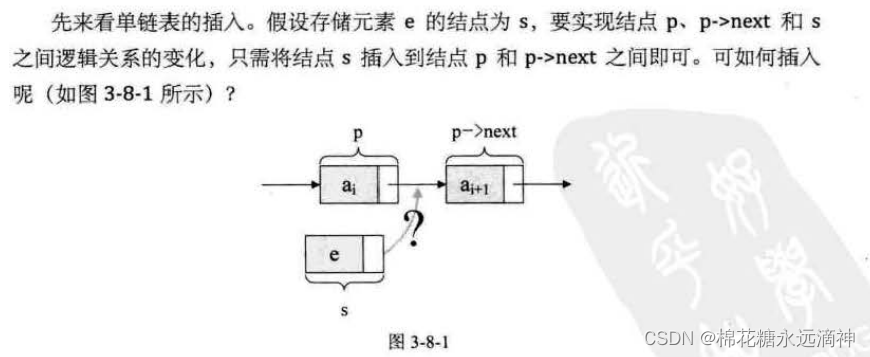
很简单:让p的指针指向s,s的指针指向p->next即可。
代码表述为:s->next=p->next; p->next=s;
重点是怎么理解呢?先让p的后继节点变为s的后继节点,再让s变为p的后继节点。简单地说,把p、s、p->next三个节点,必须先让s与p的后继变换,然后s再与前驱变换,这个顺序一定不能改变。
①如果先执行p->next=s;再执行s->next=p->next;会怎么样?
答:先执行p->next=s,相当于把s赋给p的后继节点,这一步就类似于把p的后继节点的数据域覆盖成了s节点内的内容,成了单纯的替换。再执行s->next=p->next;,其实就等于 s->next=s ,也没有意义。
②插入后示意图
所以:

代码:
核心点是:创建两个链表结构体的变量p和s作为节点,把原链表L用p指向,然后开始遍历链表,指针每次指向下一个节点计数加一,直到指针指向第i个元素,这时该指针指向的节点就代表p->next,用malloc()函数开辟一块空间用来存放s节点的数据e,再利用s->next=p->next; p->next=s;
操作完成插入。

(5)基本操作之:单链表删除某一个节点
思路:
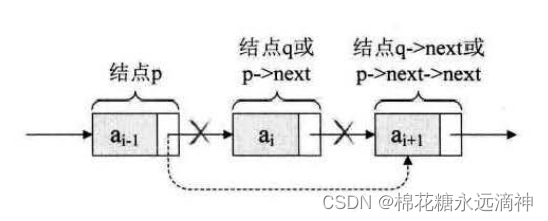
看图,让节点p的后继指针指向后继节点的后继节点即可。
p->next=p->next->next;
但是这种写法语法上不正确,所以要分成两步进行:
q=p->next;
p->next=q->next;
代码:

类似,先指针后移,遍历到i的位置,然后利用语法进行删除操作
(6)基本操作之:单链表的整表创建(头插法、尾插法)
先回顾一下顺序表的内容创建:由于顺序表里面只包含数据元素,所以结构体里面只有data,在创建顺序表时只要声明一个结构体变量Sqlist L,然后给赋值L.data[0]=20这样。但是单链表有指针,就不能这么搞了,它很散,不用一开始就预先分配好所占的空间大小,所以创建单链表的过程就是一个动态生成链表的过程。
这里就有一个不同了,我们可以建立一个空链表,每次让新的节点作为第一个节点叫做头插法。
也可以让新的节点都放在最后面,叫做尾插法。
①头插法(把新节点插入到尾节点之前)
思路:

代码:
void CreateListHead(LinkList* L, int n) {LinkList p; // 创建一个节点pint i;srand(time(0));*L = (LinkList)malloc(sizeof(Node));(*L)->next = NULL; // 头节点指针指向尾节点for (i = 0; i < n; i++) {p = (LinkList)malloc(sizeof(Node)); // 给新建的p节点开辟空间p->data = rand() % 100 + 1; // p节点数据赋值p->next = (*L)->next; // 采用单链表插入的公式,将p节点插入到尾节点之前(*L)->next = p;}
}在这个函数中,首先创建了一个头节点,并将头节点的next指针指向NULL,表示链表为空。
然后使用循环,每次创建一个新节点p,并将其数据赋值为一个随机数。
接下来,将新节点p插入到头节点之后,即将新节点的next指针指向原头节点的next指针所指向的节点,再将头节点的next指针指向新节点p,完成插入操作。
重复以上步骤,直到创建了n个节点后,头插法创建链表的过程完成。
关键点就是:先创建一个空链表L,该链表的头节点指向null(尾节点),再创建一个新节点p,根据头节点、尾节点、新节点p三者的关系,用插入公式将p插入尾节点之前。
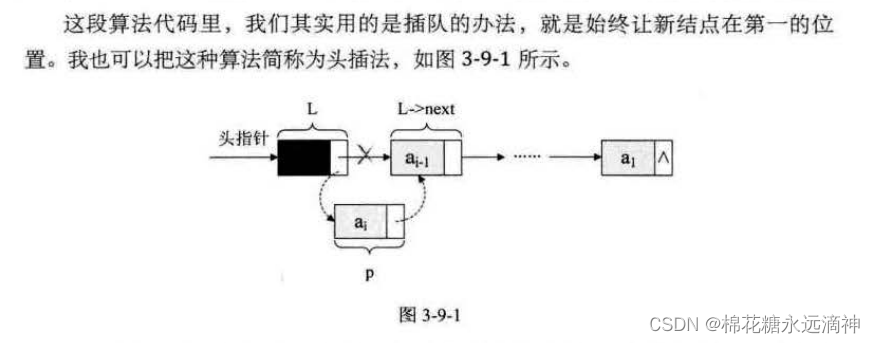
②尾插法(把新节点插入到尾节点之后)
思路:把新节点p插入到尾节点r的后面,再让节点p成为新的尾节点r
r是指向尾节点的变量,r会随着循环而不断地变化,所以每次让新的p节点插入r后面成为r->next节点后,一定要让该p节点再作为新的r节点,让p不断的代替。
r->next=p;
r = p;
代码:


四、单链表与顺序表的比较与优缺点总结

这里总结的很精炼。
通过上面的对比,我们可以得出一些经验性的结论:
(1)若线性表需要频繁查找,很少进行插入和删除操作时,宜采用顺序存储结构。若需要频繁插入和删除时,宜采用单链表结构。比如说游戏开发中,对于用户注册的个人信息,除了注册时插入数据外,绝大多数情况都是读取,所以应该考虑用顺序存储结构。而游戏中的玩家的武器或者装备列表,随着玩家的游戏过程中,可能会随时增加或删除,此时再用顺序存储就不太合适了,单链表结构就可以大展拳脚。当然,这只是简单的类比,现实中的软件开发,要考虑的问题会复杂得多。
(2)当线性表中的元素个数变化较大或者根本不知道有多大时,最好用单链表结构,这样可以不需要考虑存储空间的大小问题。而如果事先知道线性表的大致长度,比如一年12个月,一周就是星期一至星期日共七天,这种用顺序存储结构效率会高很多。
五、循环链表
(1)为什么要引出循环链表?
答:单链表有个特点:要查找某个元素,只能从首个节点开始一个个往后遍历,而不能从后往前遍历查找,所以即使已知其中某个节点,也不能查找到它的前驱节点,只能找到它的后驱节点。
比出 ,你是一业务员, 家在上海。要经常出差,行程就是上海到北京一路上的城市,找客户谈生意或分公司办理业务。你从上海出发,乘火车路经多个城市停留后,再乘飞机返回上海,以后,每隔一段时间,你基本还要按照这样的行程开展业务,如图所示

有一次,你先到南京开会,接下来要对以上的城市走 遍, 有人对你说,你得从上海开始,因为上海是第一站。你会对这人说什么?神经病。哪有这么傻的,直接回上海根本没有必要,你可以从南京开始,下一站蚌埠,直到北京,之后再考虑走完上海及苏南的几个城市。显然这表示你是从当中一结点开始遍历整个链裴这都是原来的单链表结构解决不了的问题。
事实上,连起来,形成一个环就解决了前面所面临的困难。这就是我们现在要讲的循环链表。
所以循环链表:从链表中任意一个节点开始,都可以遍历整个链表
(2)循环链表的定义:循环链表(Circular Linked List)是一种特殊的链表结构,其中最后一个节点的next指针指向链表的头节点,形成一个闭环。

其实循环链表和单链表的主要差异就在于循环的判断条件上,原来是判断p->next是否为空,现在则是p->next不等于头结点,则循环未结束。

(3)如果要用O(1)的时间来访问尾节点,需要:指向终端节点的尾指针
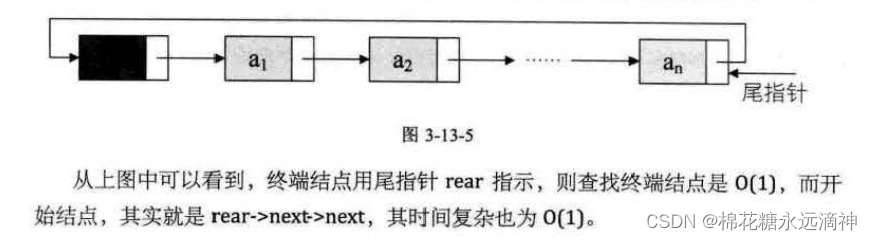
rear->next就是终端节点,它的下一个节点就是头节点。
(4)如果要将两个均含有尾指针的循环链表合并成一个链表,应该怎么做?
思路:
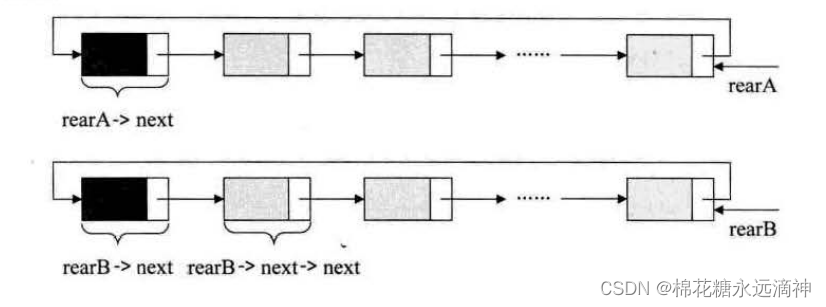
掐头去尾。把A的尾指针指向B的头节点,把B的尾指针指向A的头节点,这样就形成了一个大环。
代码:
p = rearA->next;
//让B的尾节点指向A的头节点
rearA->next = rearB->next->next;
//让A的尾节点指向B的头节点
rearB->next = p ;
free(p);
七、双向链表
(1)为什么要引入双向链表?
答:简单地说,单链表和循环链表,知道一个节点了,很容易找到其后驱节点,但是很难找到其前驱节点。

所以设计双向链表,可以快速地查找到前驱和后驱元素。
(2)双向链表是什么?

他有两个指针。双向链表的节点结构通常包含三个字段:数据域、next指针和prev指针。其中,数据域存储节点的数据,next指针指向下一个节点,prev指针指向上一个节点。头节点和尾节点分别是第一个节点和最后一个节点,它们的prev指针和next指针通常为空。但是双向链表的占据空间更大。

(3)双向链表的插入和删除结点操作
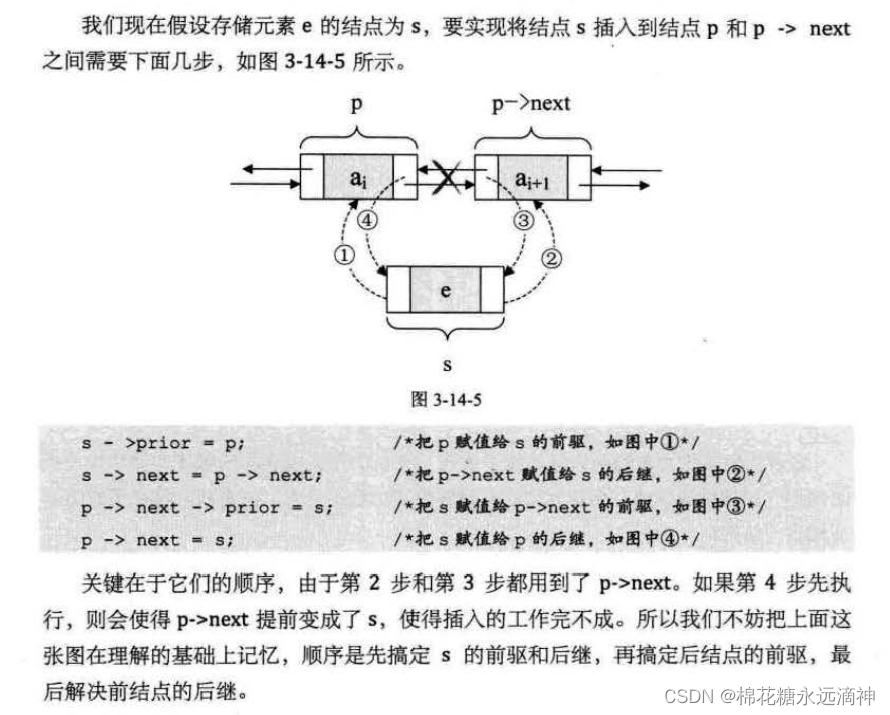
最重要是记忆顺序:先搞定S的前驱和后继,再搞定后节点的前驱,最后是前节点的后继。
八、线性表这一大块的总结