引言:
Word2Vec 是一种强大的词向量表示方法,通常通过训练神经网络来学习词汇中的词语嵌入。它可以捕捉词语之间的语义关系,对于许多自然语言处理任务,包括情感分析,都表现出色。
代码:
重点代码:
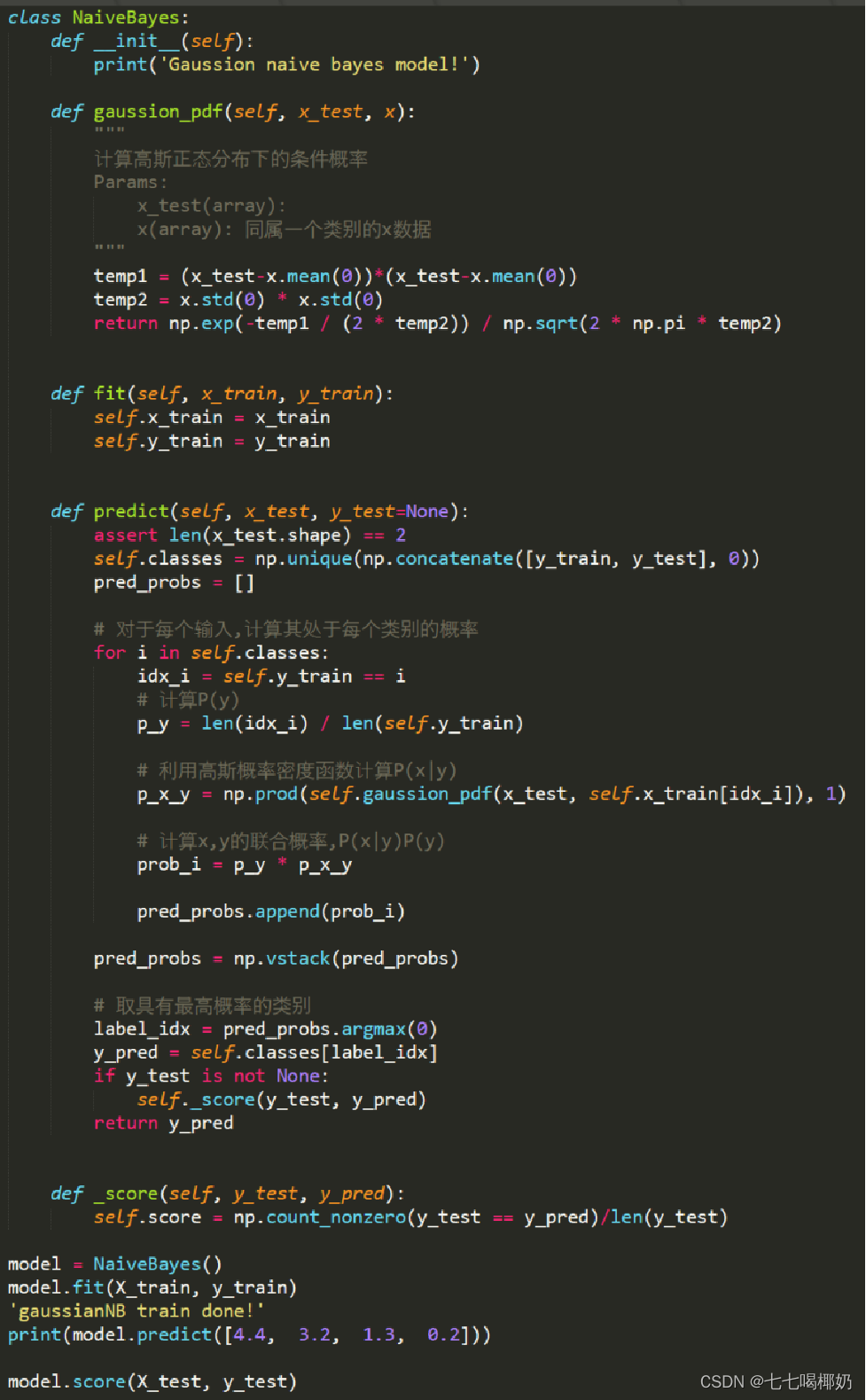
# 将文本转换为Word2Vec向量表示
def text_to_vector(text):vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeX_train_w2v = [text_to_vector(text) for text in X_train]
X_test_w2v = [text_to_vector(text) for text in X_test]
处理后的词向量:
完整代码 :
import jieba
from gensim.models import Word2Vec
from sklearn.model_selection import train_test_split
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score# 假设你有一个包含文本和标签的数据集
# 数据集格式:[(文本1, 标签1), (文本2, 标签2), ...]
data = [("这是一条正面的评论", 1),("这是一条负面的评论", 0),# ... 其他样本]# 分词
def chinese_word_cut(text):return list(jieba.cut(text))# 对文本进行分词处理
data_cut = [(chinese_word_cut(text), label) for text, label in data]# 划分训练集和测试集
X, y = zip(*data_cut)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)# 训练Word2Vec模型
word2vec_model = Word2Vec(sentences=X, vector_size=100, window=5, min_count=1, workers=4)# 将文本转换为Word2Vec向量表示
def text_to_vector(text):vector = [word2vec_model.wv[word] for word in text if word in word2vec_model.wv]return sum(vector) / len(vector) if vector else [0] * word2vec_model.vector_sizeX_train_w2v = [text_to_vector(text) for text in X_train]
X_test_w2v = [text_to_vector(text) for text in X_test]# 创建SVM分类器
svm_classifier = SVC(kernel='linear')# 训练模型
svm_classifier.fit(X_train_w2v, y_train)# 预测
y_pred = svm_classifier.predict(X_test_w2v)# 评估模型
accuracy = accuracy_score(y_test, y_pred)
print(f"Accuracy: {accuracy}")
注意:
这里的训练数据和预测数据只有1条,模型并不能训练。如需训练需要提供完整训练数据或提供预训练模型。