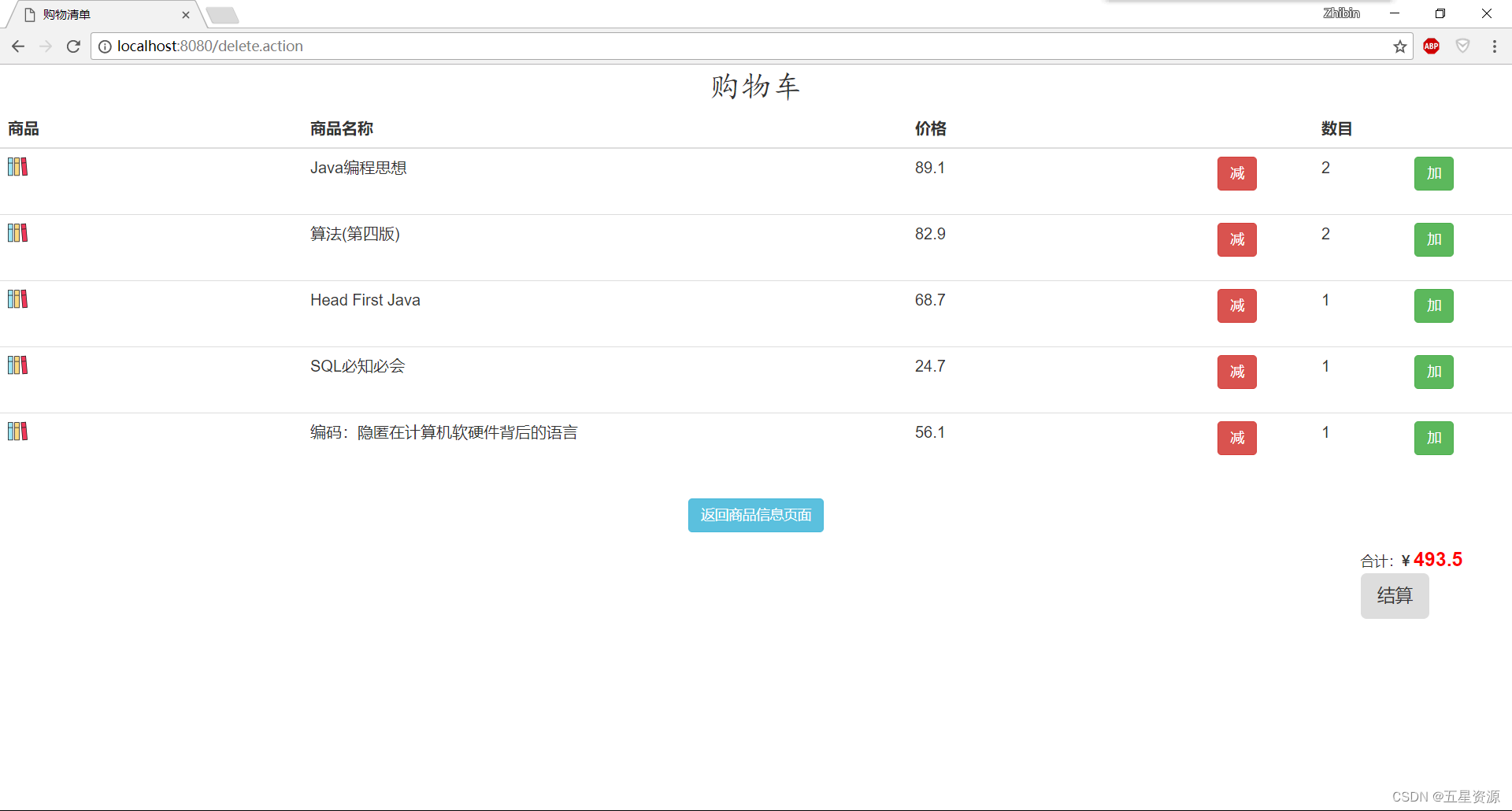
因为时间的原因,没法写一个详细的教程,但是我可以提供一个基本的框架。你需要根据实际情况进行修改和扩展。以下是使用Python的requests库和BeautifulSoup库来爬取网页内容的基本步骤:

# 导入所需的库
import requests
from bs4 import BeautifulSoup# 定义爬虫IP
proxy_host = 'duoip'
proxy_port = 8000
proxy = f'http://{proxy_host}:{proxy_port}'
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.3'
}# 发送GET请求
response = requests.get('91hometextile/', proxies=proxy, headers=headers)# 使用BeautifulSoup解析网页
soup = BeautifulSoup(response.text, 'lxml')# 找到所有需要的数据
data = soup.find_all(name='div', attrs={'class': 'post-item'})# 遍历数据并打印
for item in data:print(item.text)
注意:以上代码需要根据实际情况进行修改,例如,网页的HTML结构可能会改变,需要找到正确的标签和属性来提取数据。此外,这个例子没有处理可能出现的网络错误或爬虫IP问题。
在实际使用中,可能需要安装requests库和BeautifulSoup库,可以使用pip来安装:
pip install requests beautifulsoup4
关于爬虫IP,这里使用的是一个爬虫IP服务器服务,可能不稳定或速度较慢。在实际应用中,可能需要使用更稳定的付费爬虫IP服务,或者使用更复杂的爬虫IP管理工具。
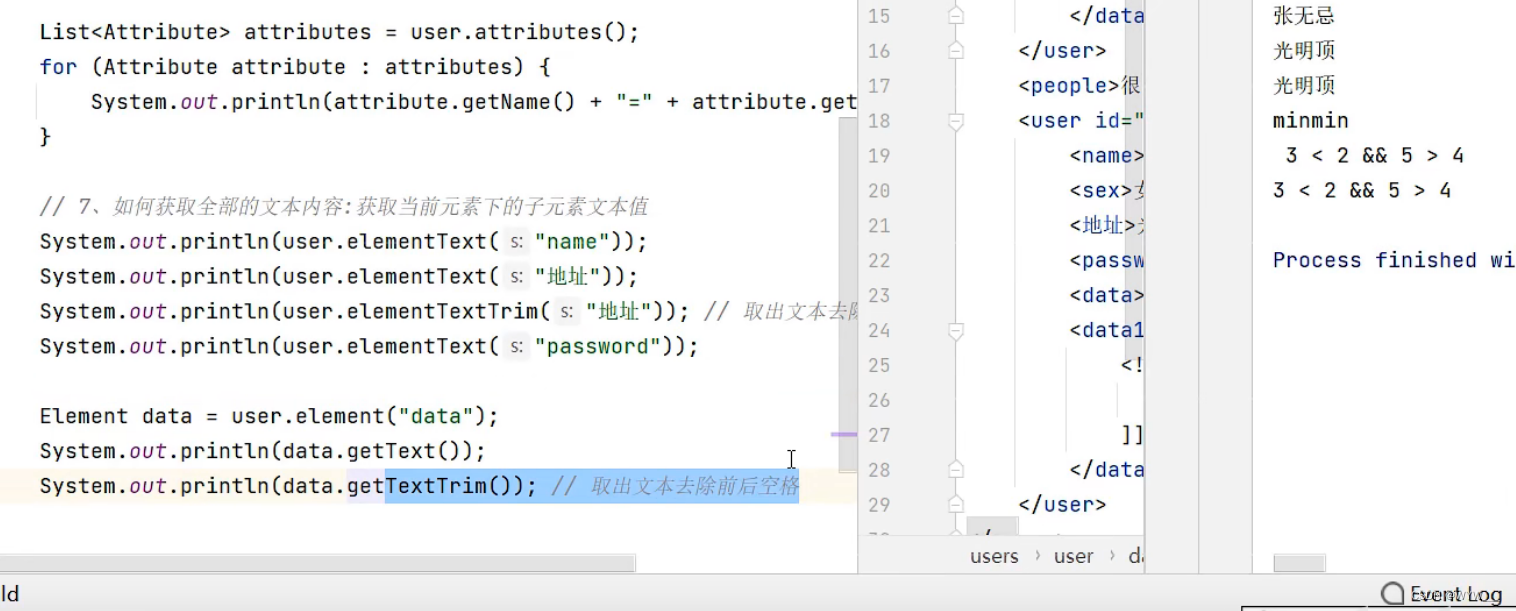
![[算法训练营] 贪心算法专题(二)](https://img-blog.csdnimg.cn/a4450e2e6d304b86aa8ad7b3700aa50f.png)