1.repository
几乎所有的APP,从简单的到最复杂的,在它们的架构里几乎都包括状态管理和数据源这两部分。状态管理常见的有Bloc、Cubit、Provider、ViewModel等,数据源则是一些直接和数据库或者网络客户端进行交互,取得相应的数据,并将其解析为模型的类。
一般地,状态管理器直接和数据源通信。当只有一个数据源的时候,事情比较简单。但是当有多个数据源,譬如说APP需要缓存数据的时候,事情就变得复杂起来了。
缓存也就是将你的API请求结果备份在本地数据库中。这允许你后面可以在网络异常的时候,仍然能获得该数据。这也能帮助你在下次打开这个页面的时候,可以更快地进行响应和节省带宽。
当你为特定页面的数据缓存数据的时候,状态管理器负责直接和数据源进行交互,协调数据库和网络数据源。
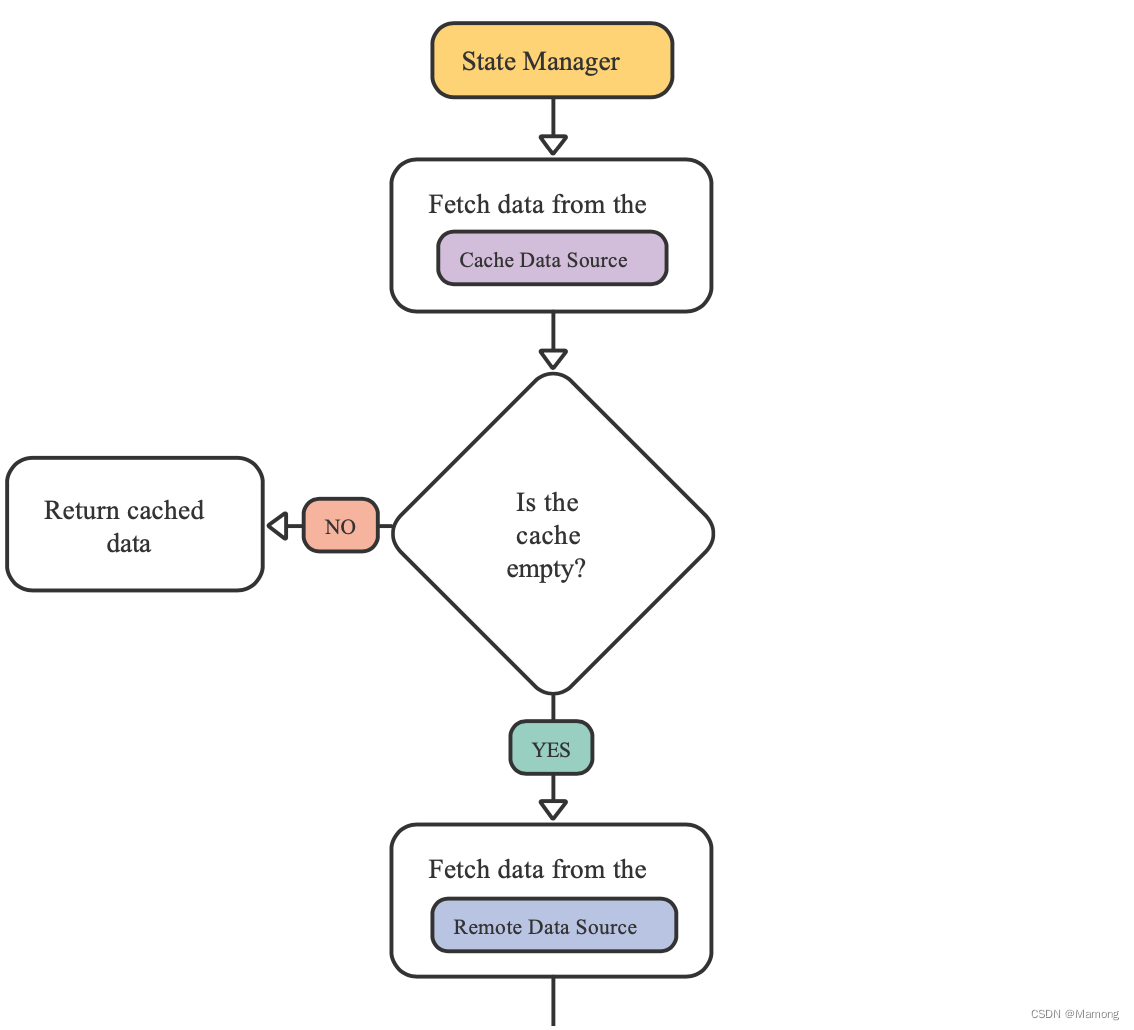
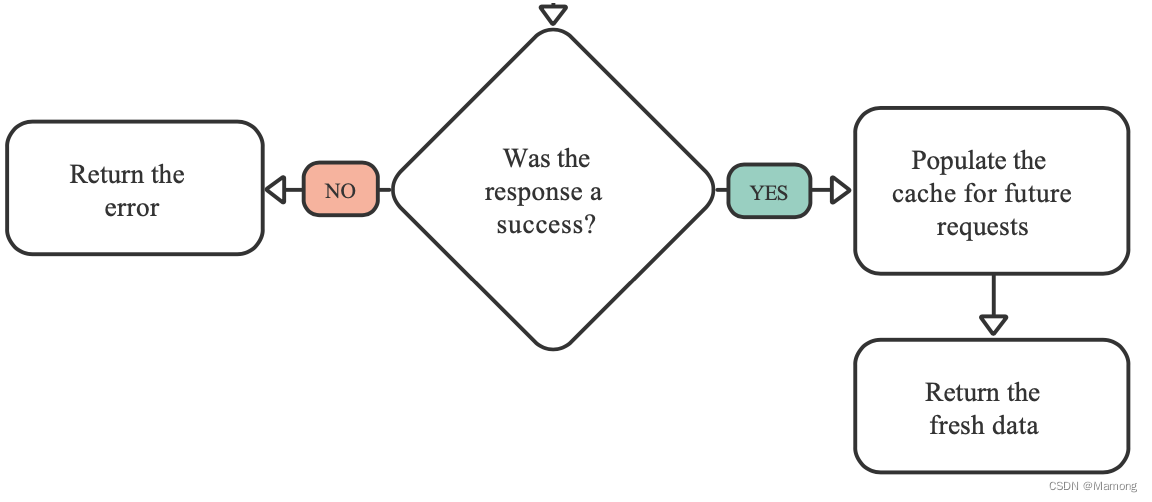
repository模式中repository类位于状态管理器和数据源之间,接管原本由状态管理器负责的数据协调工作,也就意味着你的状态管理器不需要关心数据的来源。
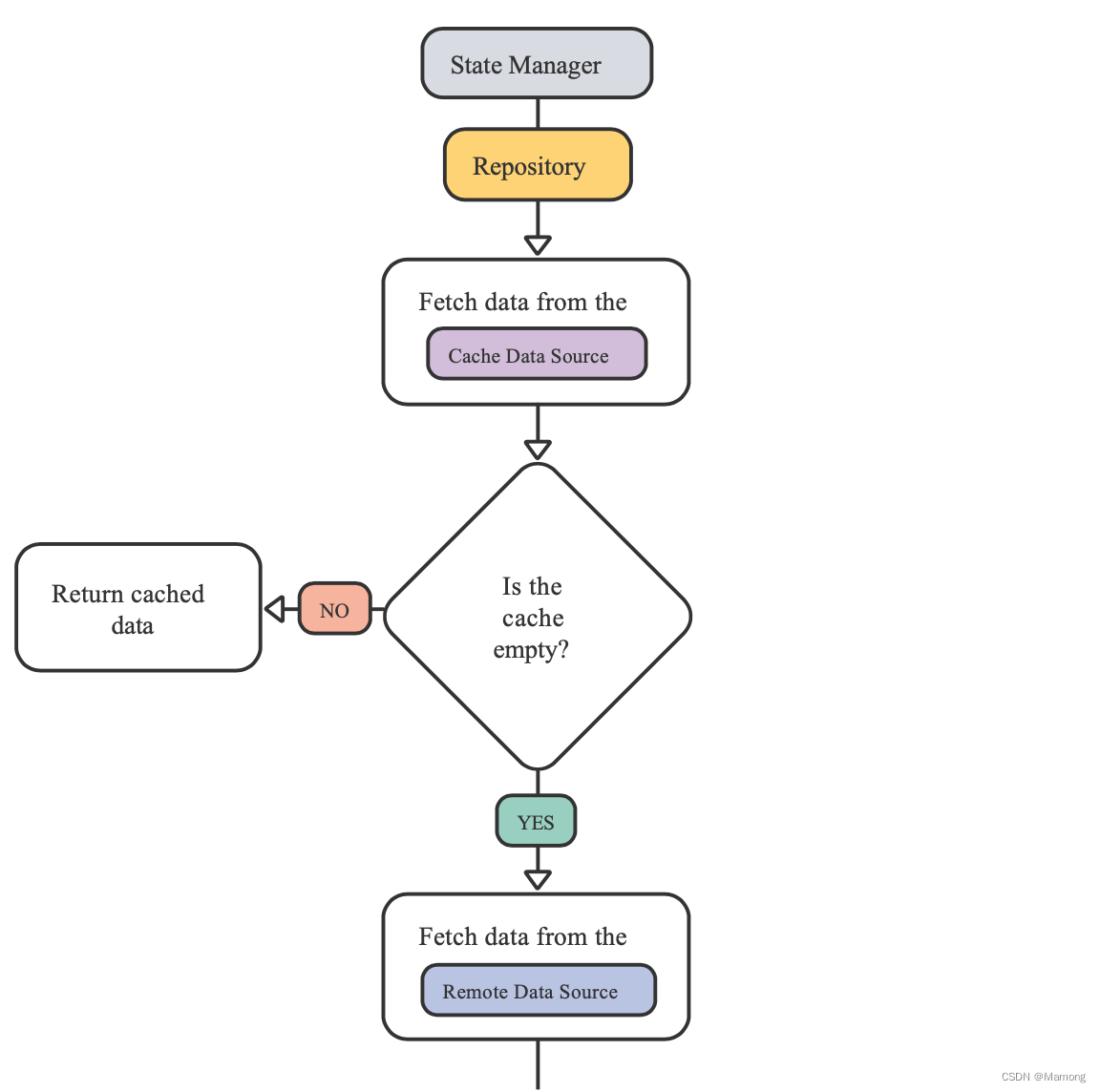
repository允许你在不同状态管理器之间共享数据协调的逻辑。repository本身很简单,但是对代码库具有非常深远的价值。
2.class dependency
类依赖指的是一个类依赖另一个类来实现它的工作。例如QuoteRepository依赖FavQsApi来获取数据,这样就使得FavQsApi成为了QuoteRepository的类依赖。有两种方式来获取一个类的类依赖实例:
1.自己实例化:你可以在构造函数、属性声明等地方实例化依赖的类,例如:

好处是你不必暴露内部的依赖给类的用户。坏处是如果其他repository也依赖同一个类,你不能在不同repository之间共享同一个依赖类实例,并且你要在所有地方重复这个实例化逻辑。
2.构造函数要求传入一个实例:例如:

这种方式的优劣点与前面一种刚好相反。哪种更好的呢?这个视情况而定。
3.处理类依赖
在实践一中,我们为每个repository创建了各自的包。因为一个repository经常被多个功能所使用。这使得将它们放在某个功能包里变得不可行,因为功能之间不能相互依赖。因此,你不能在多个功能里使用同一个repository。
一种选择是创建单个包来存放所有的repository,让所有的功能都能访问。但是包被认为是经常会一起使用的东西,单个功能不大可能需要用到全部的repository。那么最终只剩下一种选择:为每个repository创建各自的包。
在packages文件夹下创建一个quote_repository包。在quote_repository.dart中
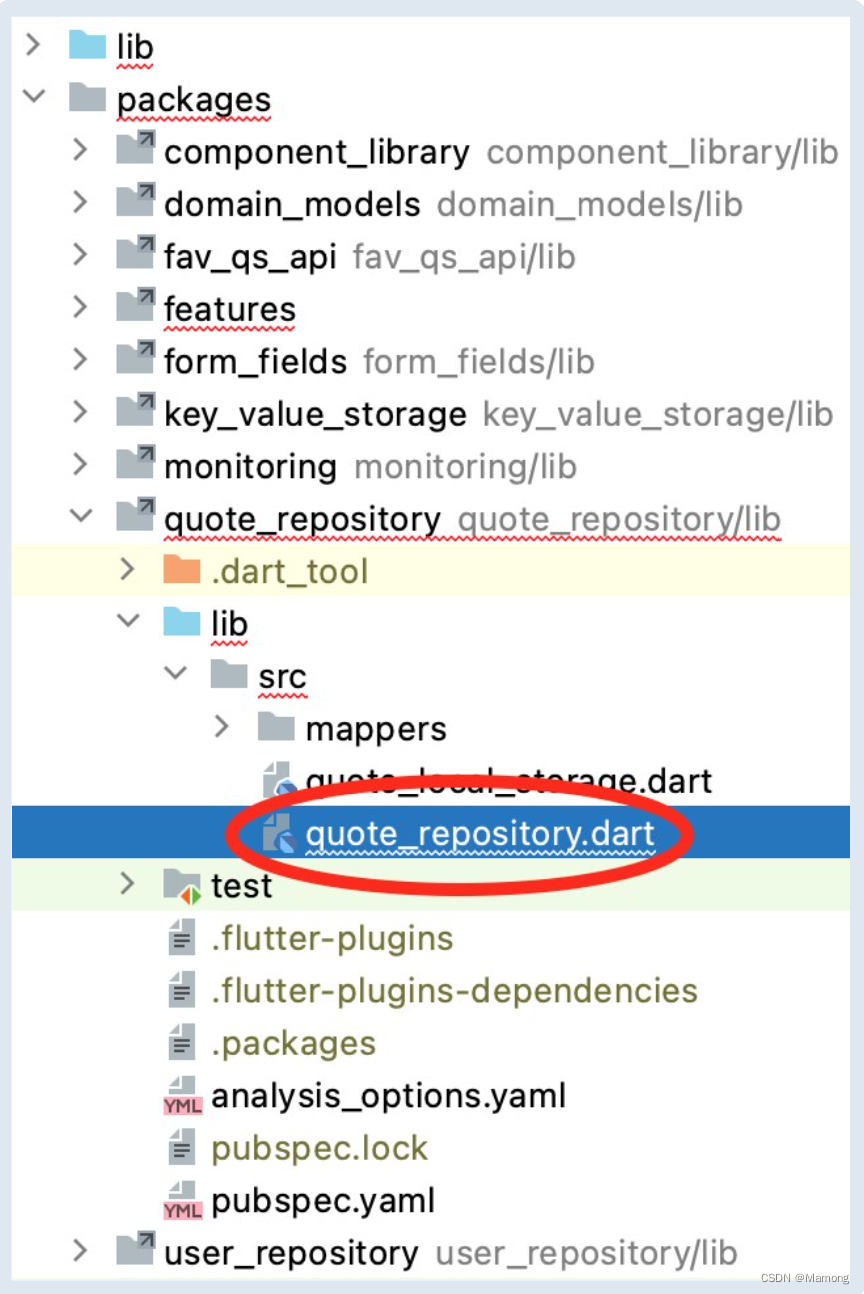
加入下列代码:
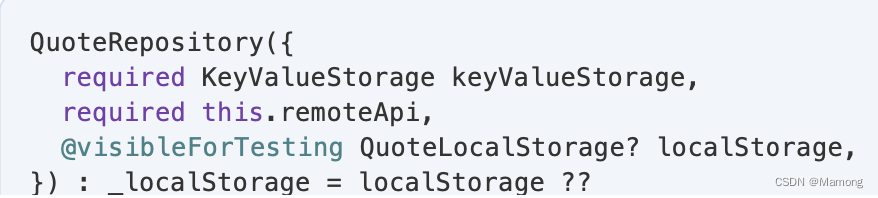
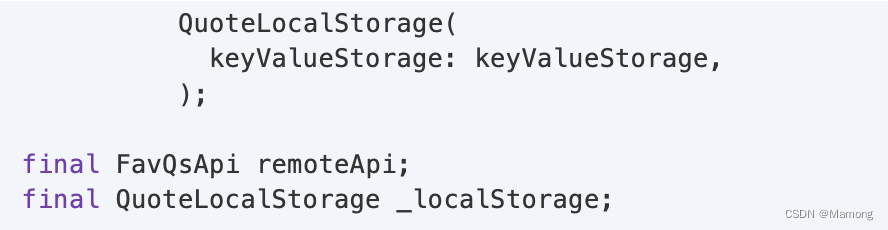
1.remoteApi是FavQsApi,用于向远程API发送和请求数据。FavQsApi来自另一个fav_qs_api包:
2.QuoteLocalStorage用于从设备本地存储获取和保存名言。QuoteLocalStorage来自当前的包:
因为QuoteLocalStorage只和名言打交道,出了quote_repository包就没啥用途。而FavQsApi更通用,因为它同时处理名言和身份验证调用。这使得它也适用于user_repository包。如您所知,当您需要在两个包之间共享代码时,在本例中为两个存储库 — 您必须创建第三个存储库。
QuoteLocalStorage依赖KeyValueStorage,它来自单独的key_value_storage包:
将 KeyValueStorage 视为 WonderWords 的本地数据库。它是流行的 Hive包的包装器。它必须成为内部包,才能将所有 Hive 配置集中在一个地方。
回到QuoteRepository构造函数,你是需要在构造函数里要求类依赖,还是自己在内部实例化依赖的类?
其文件位于您正在处理的同一包中的类依赖项应在构造函数中实例化。QuoteLocalStorage 就是这种情况。
来自其他内部包(如 KeyValueStorage 和 FavQsApi)的类依赖项必须在构造函数中接收。
请注意,即使 QuoteLocalStorage 在 QuoteRepository 的构造函数中实例化,您仍然允许通过可选参数在构造函数中接收它。此可选参数背后的意图不是向 QuoteRepository 的用户公开类依赖项。相反,它的存在只是为了允许您在自动化测试中提供模拟实例,这就是您使用 @visibleForTesting 对其进行注释的原因。
4.创建桶文件
QuoteRepository代码都在src目录下,那么状态管理器无法导入QuoteRepository,因为它们被视作是私有的。dart包布局约定中建议将所有代码放在src目录里,通过从直接放置在 lib 下的“导出器”文件中导出它们,有意识地公开要公开的文件。这个导出文件也被称作桶文件。约定的一部分是为 barrel 文件指定与包相同的名称。
在桶文件quote_repository.dart中插入如下代码:
export 'src/quote_repository.dart'5.分页
分页是将一个API的结果分割成多个批次,每个批次叫做分页。这能让用户无需等待太久,就能取得数据,与APP进行交互,同时也减少了蜂窝数据的消耗。用户可以按需渐进式地加载更多分页的数据。
6.Stream
Dart中有两种异步编程类型:Future和Stream。Future代表你不能立刻获得的值,例如getQuote()返回Future<Quote>,而不是Quote。因为需要花费一些网络请求的时间来获得Quote。getQuote函数立即返回一个通道--Channel给调用者。随后当请求成功时,会通过这个通道发送真实数据。
Stream是Future的复杂形式。Future每次发送一个数据,而Stream可以发送多个数据。getQuoteListPage()返回一个Stream,而不是Future。这和下面的数据获取策略有关。
7.数据获取策略
当你决定缓存网络调用的结果时,你需要考虑后面采取哪种策略来传递这些数据。
是否总是返回缓存的数据?万一它们过期了呢?
接着你是否需要每次从server获取数据,而只是将缓存的数据作为网络请求失败时的回退?是的话,频繁的加载时间是否会让用户感到不安?假设数据不经常更改,进行不必要的网络调用会浪费蜂窝流量吗?
这些问题没有明确的答案。你必须考虑每种情况。数据过期的频率如何?在这种情况下,你是否应该优先考虑速度或准确性?
因此,是时候更具体地决定 WonderWords 主页面的最佳策略是什么了。
当用户打开 WonderWords 时,他们可能希望每次都能看到新的名言。如果他们非常喜欢一句话,想再看一遍,他们总是可以收藏这句话。
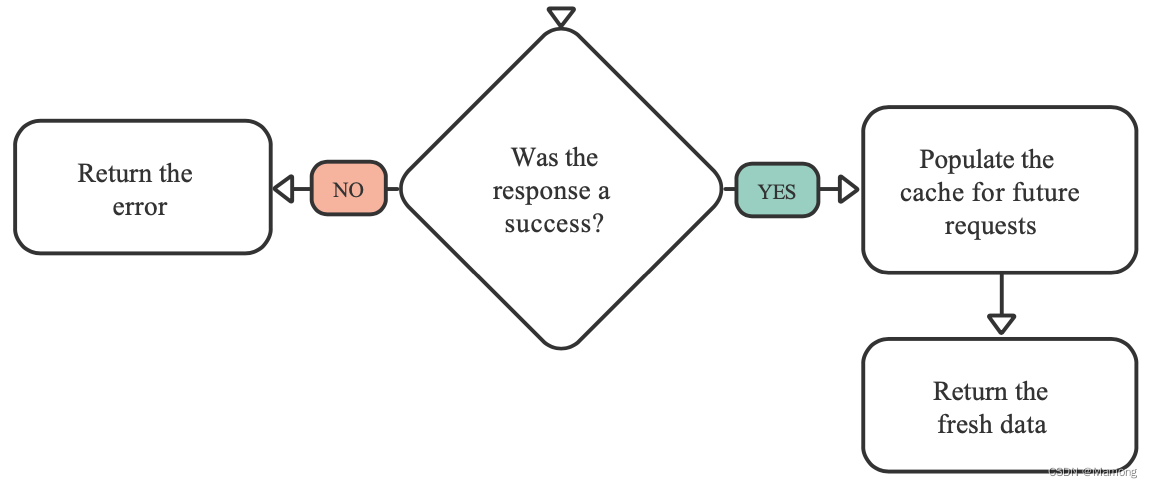
到目前为止,可以肯定的是,最好的策略是每次都从服务器获取名言,而不用担心缓存。但是,如果网络调用失败怎么办?在这种情况下,最好将显示缓存的数据作为回退。
好了,你现在有了一个政策。你将继续每次从服务器获取名言,但随后缓存这些名言,以便将来在网络调用失败时可以使用它们。
你的新策略非常可靠,但仍然有一个巨大的缺陷:每次都从 API 获取项目意味着用户的加载时间频繁且漫长。当用户打开应用时,他们希望尽快开始与应用交互。
你无法让服务器更快地给你返回数据。但是,既然你无论何时都会缓存名言,那么你可以进行一个主要操作:你可以显示缓存的名言,而不是在用户每次打开应用程序时都显示加载页面,同时在后台获取新的名言。
注意:使用此新策略时,从存储库返回 Future 已不满足需求。当状态管理器要求第一个页数据时,你将首先发送缓存的数据(如果有的话),然后发送来自API的数据。处理多次发送数据时,你需要使用 Stream。
你现在拥有了为 WonderWords 主页面量身定制的策略。坏消息是,即使仅考虑了主屏幕,这个设计的策略并不适合所有的情况。
8.考虑额外的情况
考虑这些边界情况:
如果用户想要通过下拉列表来有目的地刷新列表,该怎么办?在这种情况下,您不能先返回“旧”数据。此外,用户不介意看到加载页面;毕竟,他们清楚自己刚才请求了新数据。
如果用户搜索特定名言,但随后清除了搜索框,以便他们可以返回到之前看到的名言,该怎么办?在这种情况下,最好只显示缓存的数据。后面你不需要展示新数据,因为用户只想返回到以前的状态。
这意味着根据页面的复杂程度,单个数据获取策略可能还不够。在这种情况下,你能做的就是让状态管理器为用户体验旅程的每一步决定最佳策略。这就是getQuoteListPage() 具有fetchPolicy 参数的原因。
fetchPolicy 的类型为 QuoteListPageFetchPolicy ,这是你正在处理的文件末尾的枚举。以下是枚举的值:
cacheAndNetwork:如果 HTTP 调用成功,则首先发出缓存的名言(如果有),然后从服务器发出名言。在用户首次打开应用时很有用。
networkOnly:在任何情况下都不要使用缓存。如果服务器请求失败,请告知用户。当用户有意识地刷新列表时很有用。
networkPreferably:首选使用服务器。如果请求失败,请尝试使用缓存。如果缓存中没有任何内容,则让用户知道发生了错误。当用户请求后续页面时很有用。
cachePreferably:首选使用缓存。如果缓存中没有任何内容,请尝试使用服务器。当用户清除标签或搜索框时很有用。
注意:只有cacheAndNetwork能发送两次数据,其他策略返回类型用Future就足够了。
9.填充缓存
四个受支持的策略中的每一个都可能需要在某个时间点从服务器获取数据;毕竟,没有 cacheOnly 策略。所以第一步是创建一个实用程序函数,用于从服务器获取数据并用它填充缓存。这样,您就可以为所有策略重用 getQuoteListPage()中的该函数。
打开lib/quote_repository/src/quote_repository.dart,添加代码:
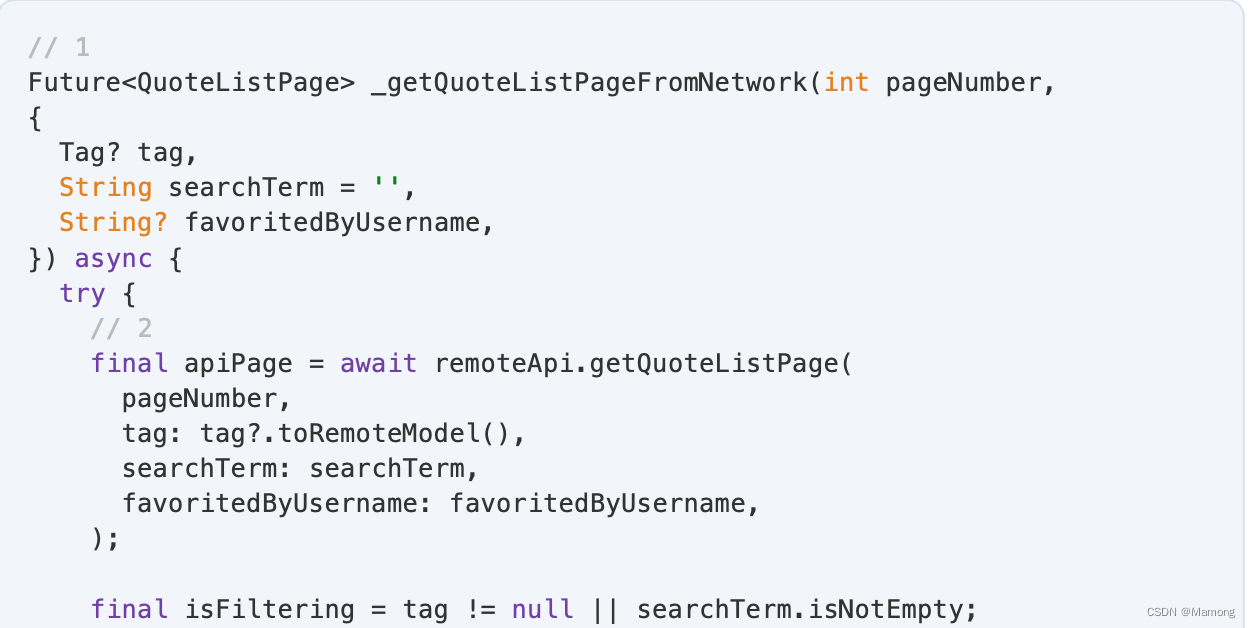
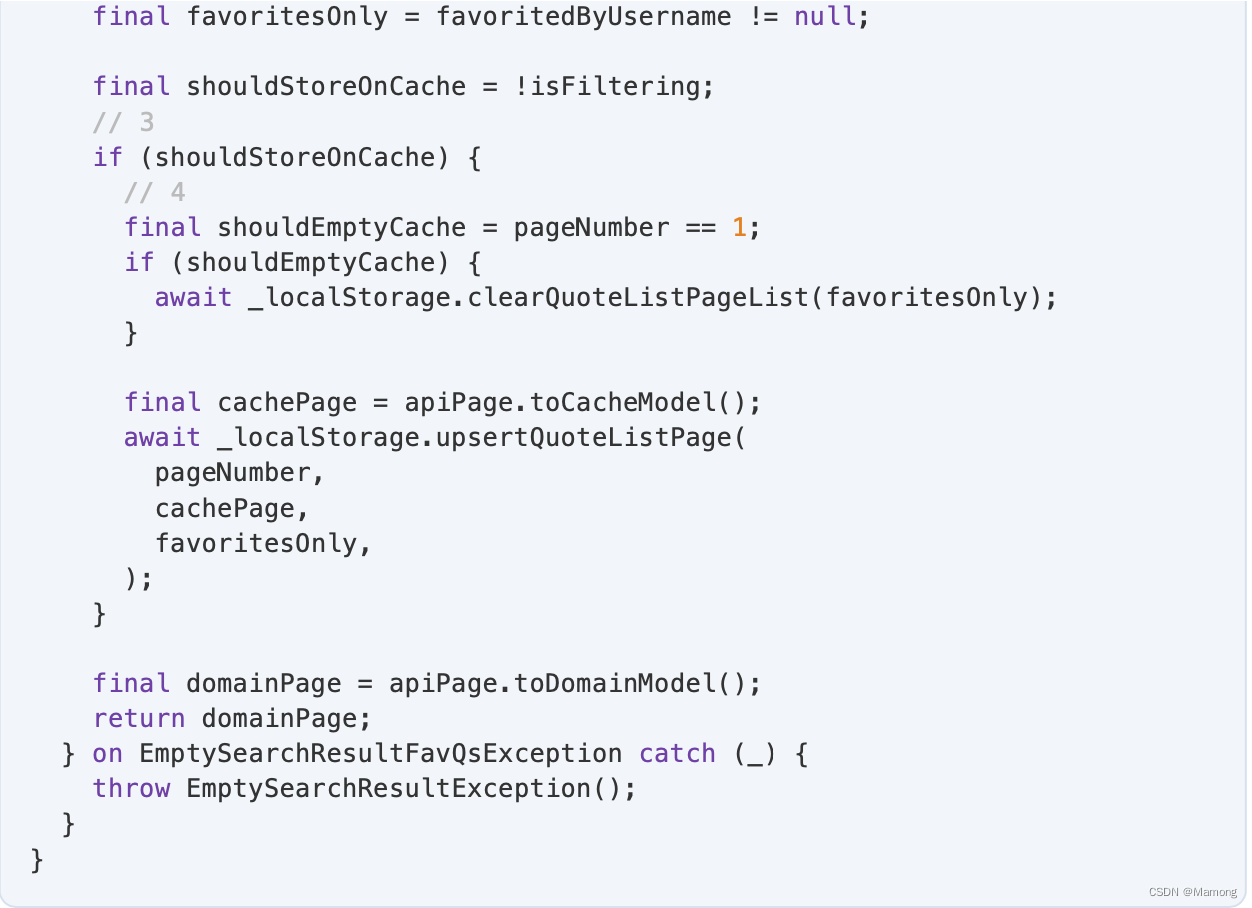
1.返回类型为Future。
2.从远端API获取新的分页。
3.不应该缓存过滤的结果。
4.每次获得新的第一页时,都必须从缓存中删除之前存储的所有后续分页。这迫使将来从网络获取后面的分页,因此您不会冒着混合更新和过时分页的风险。不这样做会带来问题,例如,如果曾经位于第二页上的名言移至第一页,如果将缓存页面和新页面混合在一起,则可能会显示该名言两次。
10.模型分离
通过调用remoteApi.getQuoteListPage()从API获取的对象是QuoteListPageRM类型的,RM表示为Remote Model。
而调用_localStorage.upsertQuoteListPage()从缓存获取的对象是QuoteListPageCM类型的,CM表示为cache Model。
两者类型不一致。而repository的getQuoteListPage()返回的是QuoteListPage类型。
当涉及到其模型时,应用的每一层都有自己的规范。例如,您的远程模型复制了 JSON 的结构,并且充满了 JSON 解析注释。另一方面,缓存模型中充满了数据库内容,具体取决于您使用的数据库包。更不用说某些属性类型也可能不同;例如,有些内容在API里是字符串类型,而在数据库里是枚举类型。
最后,由于存储库的数据有时来自数据库,有时来自网络,因此您需要一个中立、公正的模型来返回给repository的用户。这被称为领域模型,在这个例子中是QuoteListPage。
换句话说,领域模型是与它们的来源无关的模型。
WonderWords 在单独的 domain_models 包中定义了领域模型,所有repository的包都依赖于该模型。这样做允许不同的repository共享相同的领域模型。
WonderWords 还遵循了另一个良好的做法:除了域模型之外,它还在同一包中定义了领域异常。就像在一切正常时返回中性/领域模型一样,当出现问题时,也可以抛出中性/领域异常。
你可以看到这发生在你刚刚写的那个 catch 块中。每当你捕获到来自 fav_qs_api 包的 EmptySearchResultFavQsException 时,你就用来自 domain_models 的 EmptySearchResultException 替换它。
拥有这些领域异常似乎没有必要,但这是状态管理器根据发生的异常执行自定义逻辑的唯一方法。例如,由于quote_list功能不依赖于 fav_qs_api 包,QuoteListBloc 无法检查异常是否是
EmptySearchResultFavQsException ,仅仅是因为它不知道该类型。但是,由于 quote_list 包确实依赖于 domain_models,因此 QuoteListBloc 可以毫无问题地验证异常是否为 EmptySearchResultException,并使用它来向用户显示自定义消息。
11.Mappers
现在你明白了为什么每个数据源需要不同的模型,并且需要一个中立的模型才能最终从repository返回。但是,如何从一种模型类型转到另一种模型类型?您可能已经猜到您需要某种转换器。这些转换器称为Mappers。
映射器只是从一个模型中获取对象,并返回另一个模型的对象的函数。任何必要的转换逻辑都发生在中间。例如:
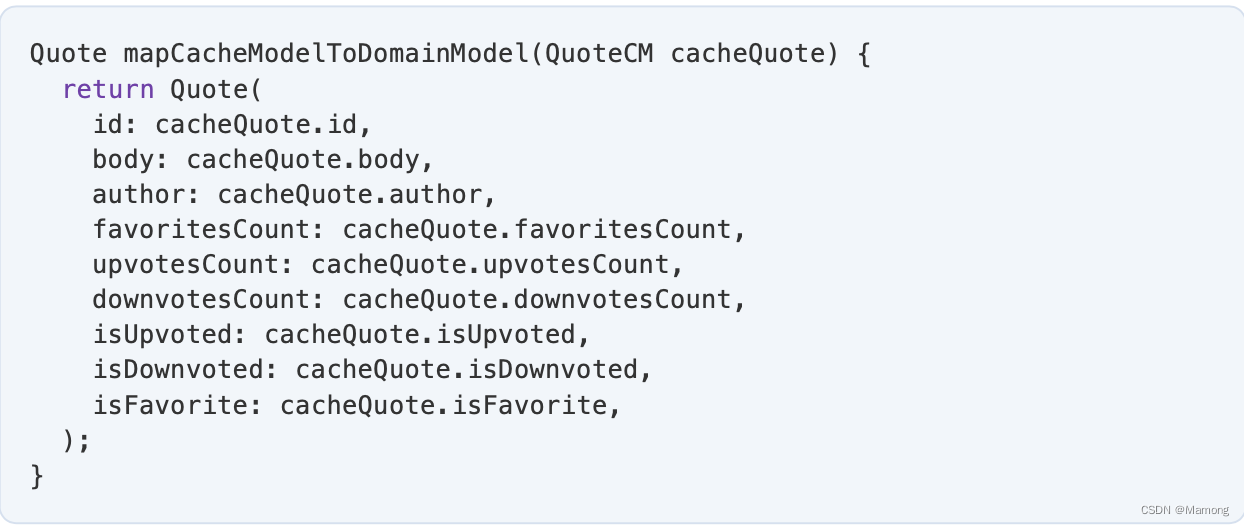
您所要做的就是使用收到的 QuoteCM 对象中的值实例化一个新的 Quote 对象。
然后,要使用此映射器函数,您只需执行以下操作:
![]()
你也可以使用dart的扩展函数来实现mapper:
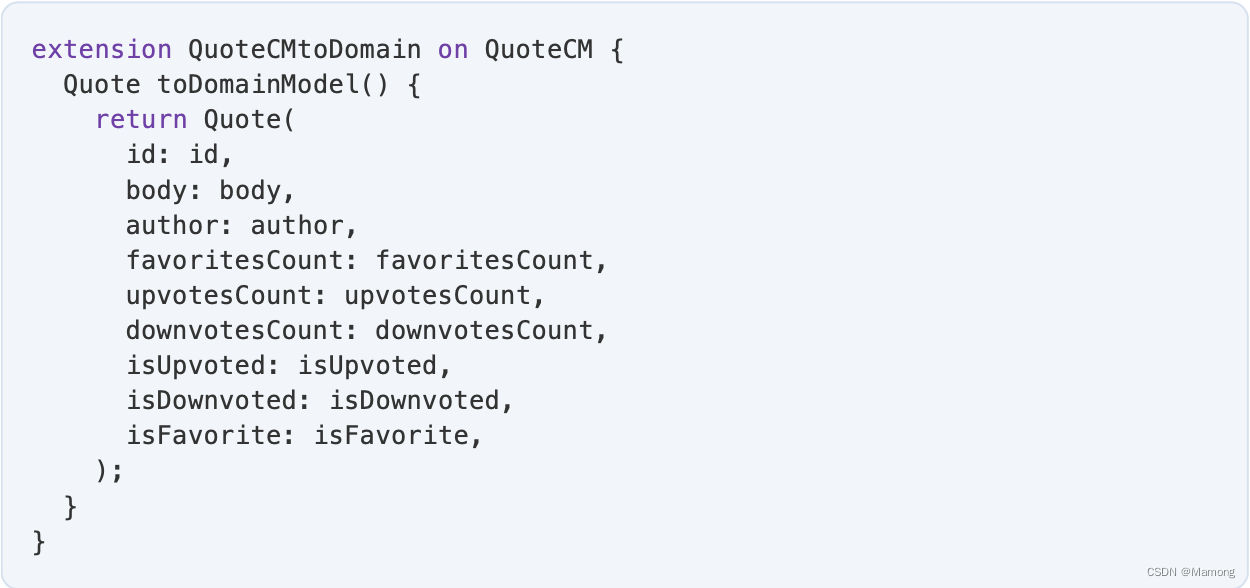
现在,您不必再接收QuoteCM对象。使用 Dart 扩展函数可以创建一个函数,该函数的工作方式就像你在 QuoteCM 中声明它一样。请注意,您只需键入 id 或 body ,就能访问 QuoteCM 中的属性。
调用mapper就变成下面这样:
![]()
12.支持不同的数据策略
现在你终于理解了 _getQuoteListPageFromNetwork() 中发生的一切。来到上面getQuoteListPage()中,加入以下实现:

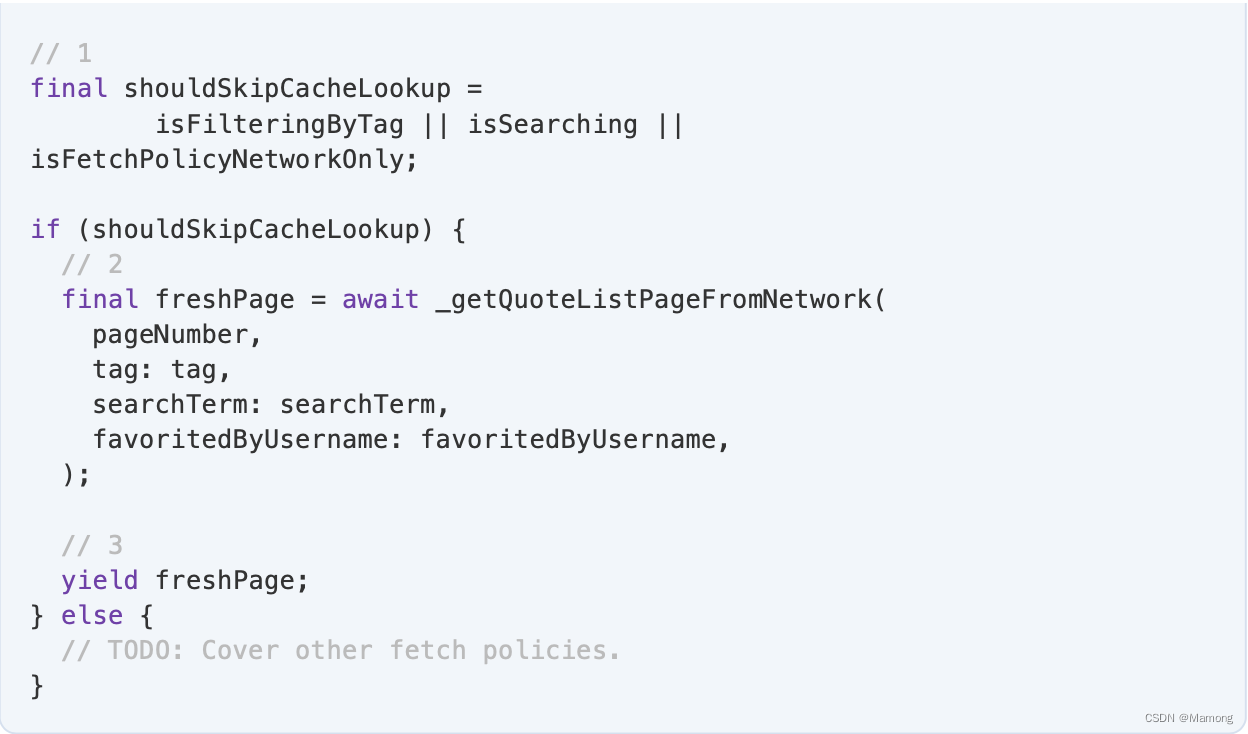
1.有三种情况,其中你想跳过缓存查找并直接从网络返回数据:如果用户选择了标签,如果他们正在搜索,或者函数的调用方显式指定了networkOnly 策略。
2.早先创建的函数
3.在 Dart 函数中生成 Stream 的最简单方法是将 async* 添加到函数的头部,然后在想要发出新项时使用 yield 关键字。
现在,你已经涵盖了不需要缓存查找的所有方案,即当用户具有筛选器或策略为 networkOnly 时。现在,您将处理强制执行缓存查找的方案。
替换上述代码中的“// TODO: Cover other fetch policies.”:
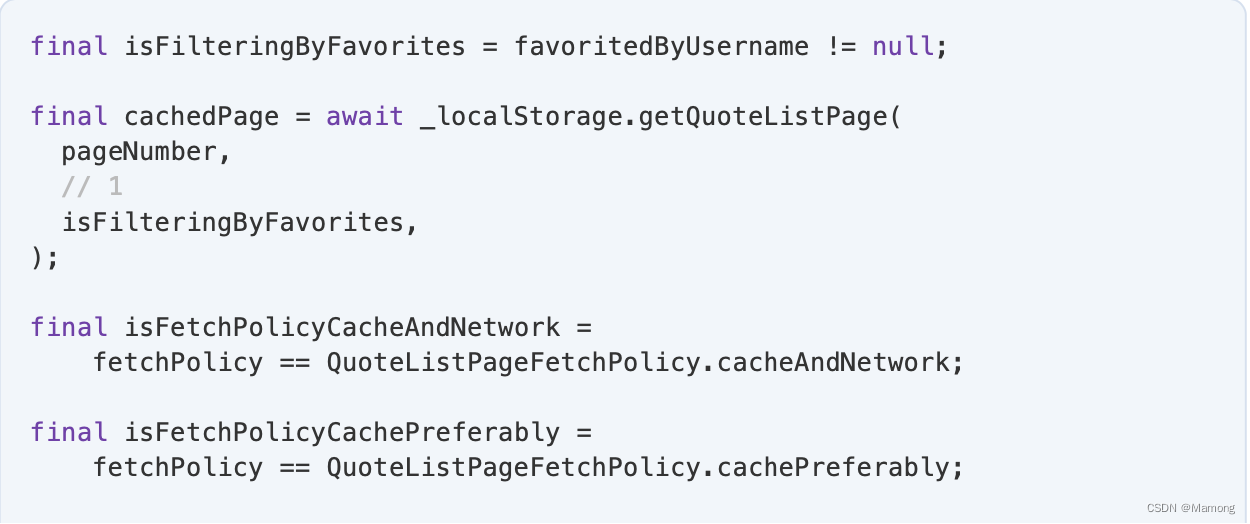
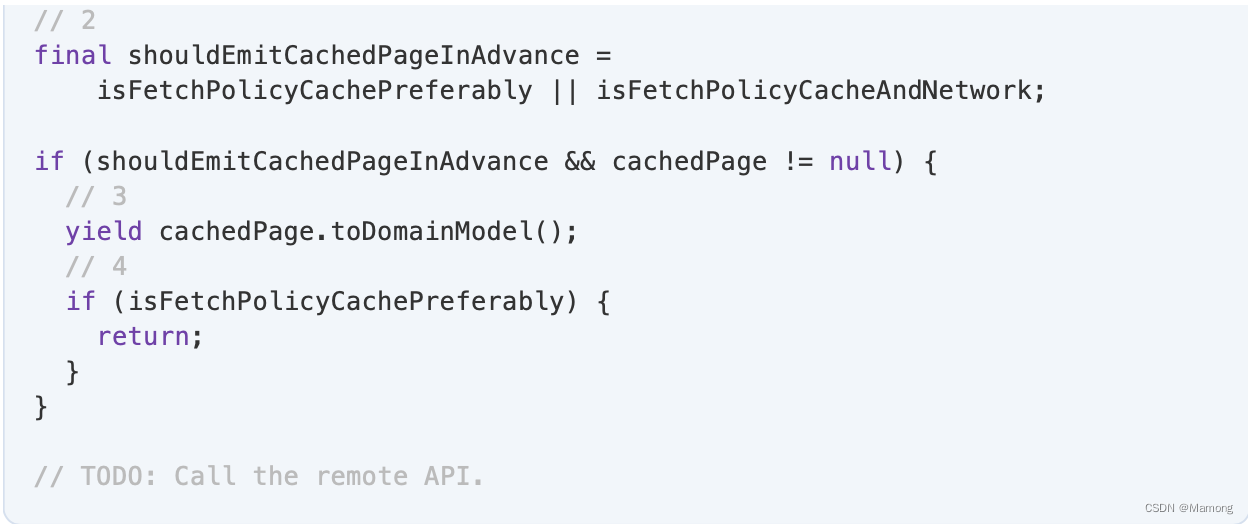
1. 你的本地存储将收藏夹列表保存在单独的存储桶中,因此您必须指定是存储常规列表还是收藏夹列表。
2. fetchPolicy 是 cacheAndNetwork 还是 cachePreferably,都必须发送缓存的分页。这两种策略之间的区别在于,对于cacheAndNetwork ,你稍后还会发送服务器的分页。
3.要返回缓存的页面,即 QuoteListPageCM ,必须调用mapper 函数将其转换为领域模型QuoteListPage 。
4. 如果策略是 cachePreferably,并且您已成功发出缓存的分页,则无需执行其他操作。您可以在此处返回并关闭Stream。
下一步是从 API 获取页面,以完成其余三个场景:
1.当策略为cacheAndNetwork时。你已经介绍了缓存部分,但是 AndNetwork部分还没有。
2.当策略是cachePreferably时,你无法从缓存中获取分页。
3.当策略是networkPreferably。
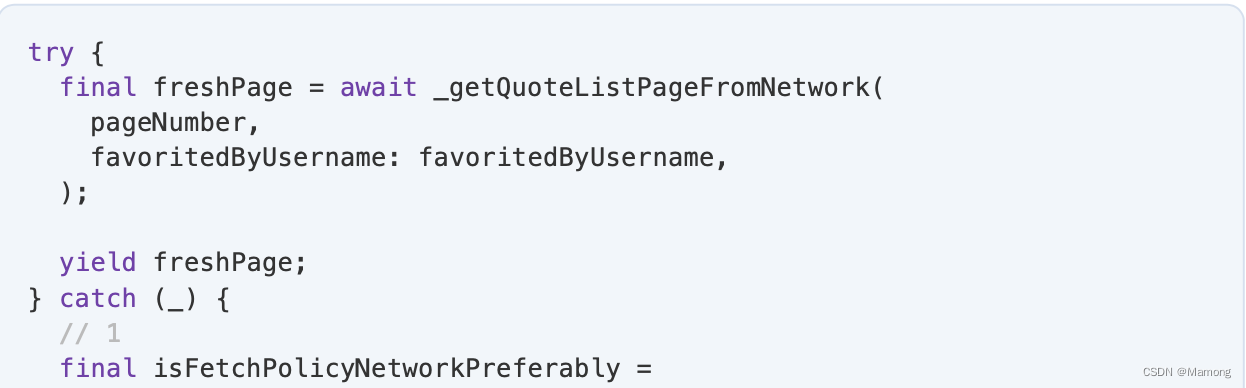
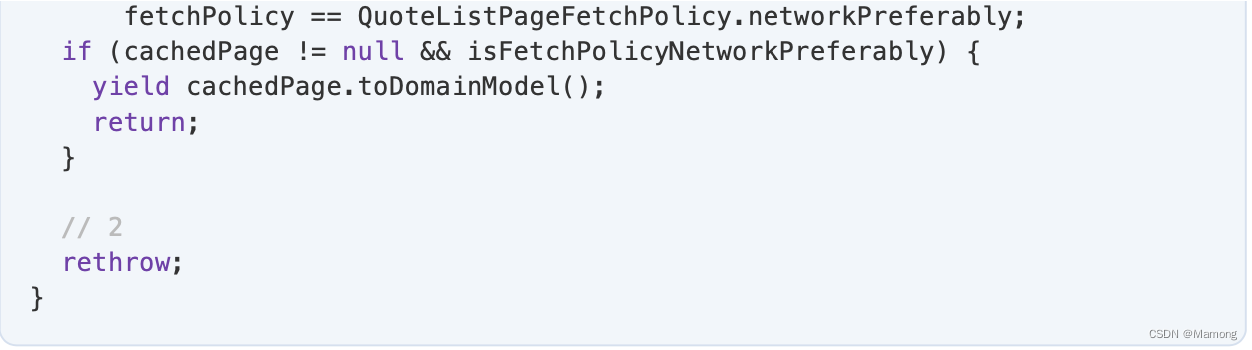
1.如果策略是 networkPreferably,并且你在尝试从网络获取分页时遇到错误,则尝试通过发出缓存的分页来恢复错误(如果有)。
2.如果策略是 cacheAndNetwork 或 cachePreferably ,则你之前已经发出了缓存的分页,因此你现在唯一的选择是如果网络调用失败,rethrow错误。这样,状态管理器就可以通过向用户显示错误来正确处理它。
在你的设备上使用该应用程序,并注意它如何利用不同的获取策略。例如,当你通过下拉列表来刷新列表时,加载屏幕需要更长的时间;这是正在使用的 networkOnly 策略。当你添加标签然后将其删除时,应用程序会很快恢复到以前的状态;这是由于 cachePreferably 策略。当你关闭应用程序并重新打开它时,数据几乎会立即加载,但随后你可以在几秒钟后看到它是如何换出的;这是 cacheAndNetwork 的实际应用。
参考:
《Real-World Flutter by Tutorials》