校内课复习笔记
非数值数据表示
在计算机中,只有01序列,这串01序列是什么意思,由人为定义。
西文字符
在ASCII码中,通过一个65的偏移量,使得一部分无符号数指向A-Za-z。
在C语言中,通过char类型的转换规范,可以将对应的01序列转换为英文输出。
GB2312-80
需要了解三种码之间的关系:区位码、国标码、机内码
国标码=区位码+2020H
机内码=区位码+8080H
区位码该怎么求呢?加就完了!
区是从A1开始的:第1区就是A1,第2区就是A2…第N区就是(A0+N)H
位也是从A1开始的:第1个字就是A1,第2个字就是A2…第N个字就是(A0+N)H
区位码就是区和位拼接。
比如知道了“啊”字位于第16区第1位,那么就能得到它的区位码为B0A1H。
字模点阵
如果人为指定了某个01串对应的文字含义。那么如何显示出来呢,就需要用到字库。
需要提前将字形存在机内。不同字体对应不同的字库,从字库中找到字形描述信息,然后送设备输出。
通过在字库中的位置找相应的字形信息。
大端存储和小端存储
在之前“码值”的博客中,对数据存储留了个坑。
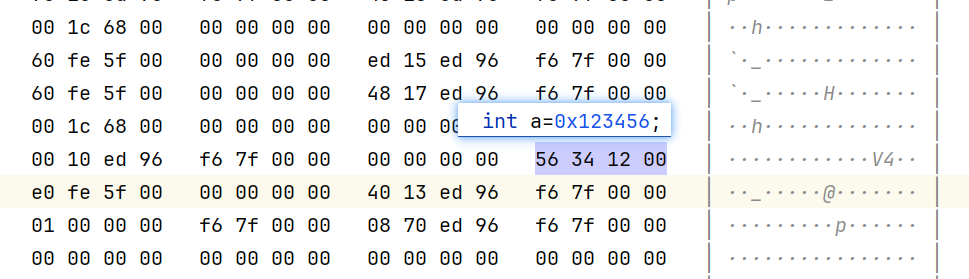
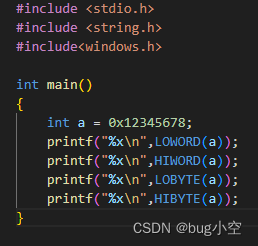
给变量a赋值0x123456,结果在内存中存储的是0x56341200
这是因为,当前编译器,采用的是“小端存储”。
比如这道题:某计算机字长为32位,按字节编址,采用小端(Little Endian)方式存放数据。假定有一个double型变量,其机器数表示为1122 3344 5566 7788H,存放在0000 8040H开始的连续存储单元中,则存储单元0000 8046H中存放的是22H。
如果是按十六进制顺序存贮,如0x00123456,此时为大端存储。
也就是说:
- 小端存储的时候,数据的表示和存储顺序是相反的。也就是低位在前。
- 大端存储的时候,数据的表示和存储顺序是相同的。也就是高位在前。
上面的例子给人的感觉不是很直观:0x123456。56在前,为什么还是小端?
这是因为,56在写数字的时候,是在低位的位置上,越往左,位权越大。
大端小端各自的优点
- 小端方式强制类型转换不需要调整
- 大端容易判断正负
小端是将低位放在低地址,高位放在高地址。在发生类型转换时,丢失的是高位的数据。因此小端方式存储,只需要知道首地址,向后裁剪或扩充就可以。
大端是将高位放在低地址,低位放在高地址。有符号数的最高位是符号位。如果采用大端存储,只需要知道首地址指向的值,也就是知道了最高位的符号位。
存储方式检测
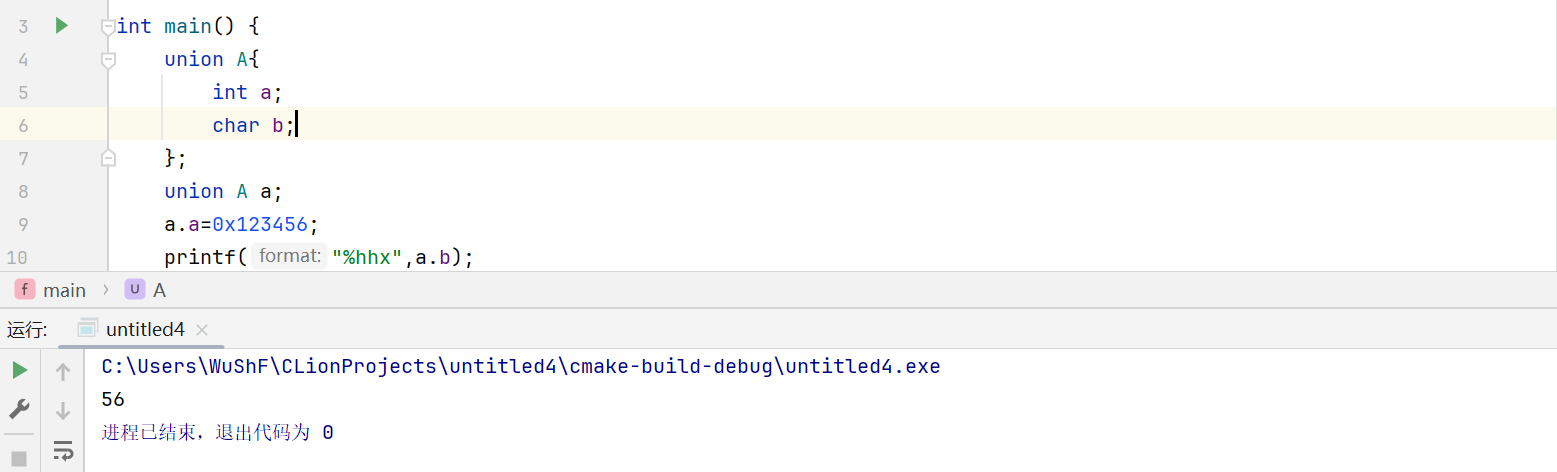
上面的配图直接截自Clion。
在C语言中可以利用联合检测。
union A{int a;char b;
};
union A a;
a.a=0x123456;
printf("%hhx",a.b);
利用联合,对a赋值。
然后利用b去除第一个字节部分的值。
内存对齐
创建一个结构体,在里面定义各种变量,变量的定义顺序会影响结构体最终占用的空间。
#include "stdio.h"struct A {char name[20]; //20 16+4int age; //4 4+上面的4double score; //8 8
};
struct B {char name[20]; //20 16+4 补4double score; //8int age; //4 补4
};
struct AB {struct A a;struct B b;
};
struct BA {struct B b;struct A a;
};int main() {struct A a;struct B b;struct AB ab;struct BA ba;printf("A的大小=%d\n", sizeof(a));printf("B的大小=%d\n", sizeof(b));printf("AB的大小=%d\n", sizeof(ab));printf("BA的大小=%d\n", sizeof(ba));return 0;
}
上面代码的运行结果:

有如下要点:
- 字符可以拆分
- 字符可以和整形变量合并
- 结构体内嵌套结构体,占用空间不变:结构体本身已经进行了内存对齐
考虑内存对齐,只需要考虑基本数据类型的对齐。
尽量把大的内存放到后面写。
联合体中各个变量共用同一段内存。选中占用空间最大的变量对齐。