©PaperWeekly 原创 · 作者 | 王金元
单位 | 上海交通大学
研究方向 | 大模型微调及应用

论文标题:
Self-prompted Chain-of-Thought on Large Language Models for Open-domain Multi-hop Reasoning
模型&代码地址:
https://github.com/noewangjy/SP-CoT
在开放域问答(ODQA)中,大多数现有问题仅要求基于常识的单跳推理。为了进一步扩展这项任务,我们正式引入了开放域多跳推理(ODMR),通过在开放域设置中使用显式推理步骤回答多跳问题。
最近,大型语言模型(LLM)在无需外部语料库的情况下促进 ODQA 方面发现了显着的效用。此外,思想链(CoT)提示通过手动或自动范式更大程度地提高了大模型的推理能力。然而,现有的自动化方法缺乏质量保证,而手动方法的可扩展性有限且多样性差,阻碍了大模型的零样本能力。
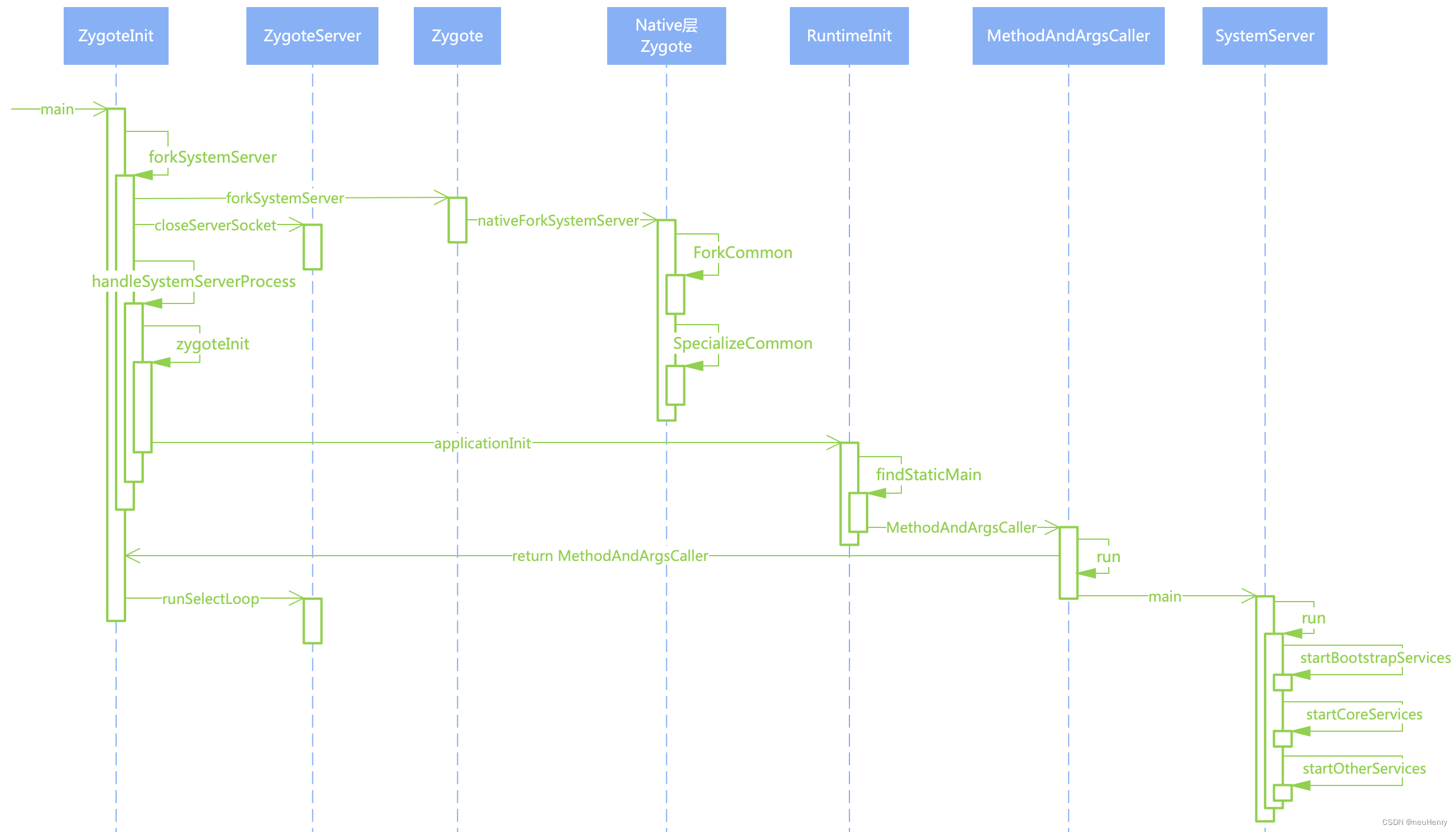
在本文中,我们提出了自我提示的思想链(SP-CoT),这是一种自动化框架,可以由大模型通过自我提示方法大规模生产高质量的 CoT。SP-CoT 引入了高质量 ODMR 数据集的自动生成管道、用于上下文 CoT 选择的自适应采样器以及通过上下文学习进行自我提示推理。
在四个多跳问答基准的大量实验表明,我们提出的 SP-CoT 不仅在大规模(175B)LLM 上显着超越了之前的 SOTA 方法,而且将小规模(13B)LLM 的零样本性能提高了近一倍。 进一步的分析揭示,SP-CoT能够召回 MuSiQue-Ans 数据集上约 50% 的中间答案,具备产生直接和简洁的中间推理步骤的卓越能力。

介绍
开放领域问题回答(ODQA)是一个长久以来的挑战性任务,主要解决在没有特定上下文提供的情况下的事实性常识问题。尽管现有的 ODQA 工作主要集中在解决大多需要单跳推理的问题上,但学界对多跳问题回答(MHQA)的兴趣日益浓厚,这项任务的目标是通过在一系列候选文章上进行多步推理来得出正确答案。然而,这样的情境与真实世界的应用之间存在着显著的差异,因为后者往往缺乏用户提供的明确的候选文章集。
鉴于此,我们正式引入开放领域多跳推理(ODMR)作为 ODQA 的进阶任务,要求在开放领域环境中(不借助任何外部知识)使用明确的推理依据进行多跳问题回答。
对于 ODMR 任务,一个新兴的方法是利用大型语言模型(LLMs),因为它们的众多参数中存储了大量的知识。近年来,LLMs 已经展现出了强大的推理和指令执行能力,如 GPT-3、PaLM 和 InstructGPT。经过在大量文本数据上的广泛训练后,LLMs 证明了它们在复杂的推理任务上的零样本推理者身份,它们可以将多步骤的问题分解为中间的问题,然后进行逐步推理,最后产生最终答案。这种中间推理步骤被称为思维链(CoTs)。
CoTs 通常作为上下文学习(ICL)的上下文演示,使 LLMs 能够通过一些作为提示的参考例子生成与目标任务形式一致的输出。Manual-CoT 采用人工设计的 CoTs 作为上下文演示来提高 LLMs 的推理性能。但是,它需要人类精细和细致的设计,而且对于每个问题,演示都是相同的,这可能是次优的。
Zero-shot-CoT 被提议用于触发自动化的 CoTs,例如使用 "\texttt{Let's think step by step:}" 这样的特定提示技术。前者提出了 Auto-CoT,一个自动化框架,用于大规模生产 CoTs 和建立上下文演示。然而,之前的工作并没有充分利用 LLMs 强大的指令执行和零样本推理能力。
在本文中,我们提出了自提示思维链(SP-CoT),这是一个仅用于 LLM 的框架,用于大规模生产 ODMR 的高质量 CoTs。总体上,SP-CoT 引入了一个自动化生成 ODMR 数据集的管道,一个适应性的用于 CoT 选择的采样器,以及通过情景学习的自提示推理。
这些自动化的 ODMR 数据集是没有候选上下文的 MHQA 数据集,但包括了六种类型的复杂推理链和逐步分解的多跳问题。每个中间 QA 步骤都配备了一个简短的解释来证明答案的正确性。通过利用 LLMs 的 ICL 能力,我们的方法对不同规模的 LLMs 都通常有效。
我们在开放领域环境的四个 MHQA 数据集上评估了我们的方法:ComplexWebQuestions(CWebQ)、HotpotQA、2WikiMultiHopQA (2Wiki)和 MuSiQue-Ans (MSQ)。
广泛的实验表明,我们提出的 SP-CoT 不仅在大规模(175B)LLMs 上显著超过了之前的 SOTA 方法,而且在 ODMR 中几乎使小规模(13B)LLMs 的零样本性能翻倍。进一步的分析揭示了 SP-CoT 在 MSQ 数据集上回调约 50% 的中间答案,从而显著地激发了直接和简洁的中间推理步骤的出色能力。
我们的贡献可以总结如下:
我们引入了一个自动化流程,利用 LLMs 生成高质量的 ODMR 数据集,其中包括 2-4 跳问题和六种复杂的推理链。
我们提出了 SP-CoT,一个自动化框架,用于大规模生产 CoTs,作为演示池来进行采样,同时确保质量和多样性。
我们进行了广泛的实验,确认了 SP-CoT 在四个 ODMR 基准上的有效性。在 ODMR 设置中,我们的方法通过引出高质量的中间推理步骤显著提高了性能。

方法
我们提出的 SP-CoT 分为三个阶段(如图 1 所示):在第一阶段,我们提示 LLM 逐步生成包括上下文、问题、答案和解释的 2 跳常识 QA 四元组。在第二阶段,我们通过连接 2 跳 QA 四元组来构建多跳推理链,并通过组合构建 ODMR 数据集。在最后一个阶段,我们采用基于聚类的采样方法,动态地选择并构造上下文示范用于推断。
2.1 阶段 1:通过自我生成的2跳QA
在第一阶段,我们提示 LLM 逐步生成包括上下文、问题、答案和解释的 2 跳 QA 四元组,如图 2 所示。受之前工作的启发,我们设计了一个 2 跳常识 QA 生成流程,包括以下 4 个步骤:

步骤1:第一跳段落生成
为了确保常识知识的全面覆盖,我们根据 TriviaQA 的统计数据手工设计了 29 个不同的主题。对于每个主题,我们要求 LLM 命名一定数量的关键词。对于每个收集到的关键词 ,我们要求 LLM 生成一个类似维基的段落 。尽管存在一些事实错误,这些生成的段落包含了足够的事实信息,可用作 QA 生成的上下文。
步骤2:第一跳QA生成
考虑到常识问题的答案很可能是命名实体,我们使用 Spacy 和 NLTK 库从段落 中提取命名实体作为候选答案。对于每一个候选答案 ,我们要求 LLM 根据段落 提出一个问题 ,其答案是 。
为了确保 的质量,我们采用了双重检查的过程,其中我们要求 LLM 给定上下文 来回答生成的问题 ,以检查生成的答案 是否与 一致。一旦生成的 QA 对通过了双重检查,我们就提示 LLM 为其写一个简短的解释 。需要注意的是,候选答案必须排除关键词(),因为第一跳中的答案会成为第二跳的关键词(, )。除此之外,有效的解释必须包含答案()。
步骤3:第二跳段落生成
在第一跳的答案被用作第二跳段落生成的关键词之前,我们使用 Spacy 过滤出带有某些标签的答案(QUANTITY、ORDINAL、CARDINAL、PERCENT、MONEY、DATE、TIME),这些答案不适合生成类似维基的段落。给定一个关键词 ,我们重复在步骤 1 中描述的相同提示来生成段落 。
步骤4:第二跳QA生成
我们首先从生成的段落 中提取候选答案,同时屏蔽第一跳 QA 中的关键词 和答案 (也称为 )以避免循环图。对于每个候选答案 ,我们要求 LLM 生成一个包含第一跳答案 的问题 ,该问题可以由候选答案 来回答。我们使用步骤 2 中的相同双重检查来检查 的质量,并确保第二跳问题 包含第一跳答案 ()以进行连续推理。然后我们重复步骤 2 中的相同提示来生成解释 。
到目前为止,我们已经指导了 LLM 生成一个 2 跳常识 QA 四元组对,即(, , , ) (, , , ),其中 。
2.2 阶段 2:通过组合实现多跳问答
在第二阶段,我们通过连接的 2 跳 QA 四元组构建多跳推理链,如图 3 所示。我们提出了一个自动化的数据集构建流程,用 2-4 跳来构建 ODMR 数据集,流程如下:

步骤1:推理链组合
为了连接更多的问题,我们遵循 Trivedi 等人提出的可组合性标准,即两个单跳 QA 对 和 可以组成一个多跳问题 ,如果 是一个命名实体并且它在 中被提及。由于我们的 2 跳 QA 对已经满足这一条件,所以我们使用这一标准来连接更多的问题。
我们采用 6 个具有 2-4 跳的推理图来构建 6 种类型的多跳推理链 ,并确保在每个推理链中:1) 中间问题 的答案 将出现并且仅出现在其下一跳问题 中,以避免快捷方式;2) 最后一个问题的答案不会出现在任何中间问题中。
步骤2:重复控制
由于基于规则的组合构建,我们的新数据集有相当相似的推理链,其中有重复的中间问题。为了确保我们数据集的多样性和简单性,我们通过预设的重复度来过滤推理链,该重复度由在同一推理类型中与其他链共存的问题的数量来定义。
步骤3:二进制问题生成
我们注意到 MHQA 数据集还包括应该由 “Yes” 或 “No”,而不是命名实体来回答的普通疑问句。因此,我们利用 LLM 重新构造一些推理链的最后 QA 为二进制问题,并使用 4 个手工设计的上下文演示。对于每种推理类型,我们随机抽样 10% 的推理链生成正面问题,10% 生成负面问题。然后,我们通过生成的二进制问题及其之前的问题步骤来重新构造一个新的推理链,并将其添加到数据集中。
步骤4:多跳问题生成
现在我们需要生成多跳问题,之前生成的问题链将作为它们的中间推理步骤。对于每个问题链,我们迭代地将中间问题 的答案 在下一跳问题 中替换为 ,直到最后一个问题 被替换,这表示一个相关的从句。然后,我们利用 LLM 利用 4 个手工设计的上下文演示将其重新构造为一个自然的多跳问题。
经过上述流程,我们构建了一个高质量的 2-4 跳 ODMR 数据集,其中包括整体的多跳问题、带有详细 QA 四元组的分解推理链。凭借生成中的双重检查和可组合性标准,我们自动构建了一个高质量的新数据集。
图 6 为我们基于自提示算法自动化构建的 6 种 2-4 条推理链。

2.3 阶段 3:自适应上下文演示构建
在这个阶段,我们从生成的 ODMR 数据集中抽取多跳问题作为上下文演示。一些先前的工作已经表明,基于聚类的方法从演示的多样性中受益。我们采用基于聚类的检索方法,为输入问题自适应地抽取上下文演示。
首先,通过使用 Sentence-BERT 编码,所有的问题都被投影到一个高维隐藏空间。假设我们需要 个上下文演示。对于一个测试问题 ,我们使用 k-means 算法将问题嵌入分成 个簇,并从每个簇中自适应地检索与 余弦相似度最高的问题。对于每个抽样的例子,我们依次连接每一跳的解释,前面加上 "Step :",以构建一个推理链。一个完整的思维链如下:


实验
我们的研究问题(RQs)是:
RQ1: 与其他仅基于 LLM 的方法相比,SP-CoT 能在我们的四个 ODMR 基准测试中,对 LLMs 有多大的提升?
RQ2: SP-CoT 对近期流行的遵循指令的 LLMs 普遍有效吗?
为此,我们对需要复杂多步推理的四个 MHQA 数据集进行了实验,并比较了不同方法在不同 LLMs 上的差异。
3.1 基准测试和评估指标
多跳问答(MHQA)数据集旨在通过要求模型阅读多个段落来回答给定问题来测试推理和推理技能。我们选择以下四个 MHQA 数据集:HotpotQA、2WikiMultiHopQA(下简称:2Wiki)、MuSiQue-Ans(下简称:MSQ)和ComplexWebQuestions(下简称:CWebQ)。为了使他们作为 ODMR 基准,我们仅使用每个示例中的问题和答案,不使用其提供的多个段落作为上下文。
我们采用精确匹配(EM)和 F1 分数作为评估指标。基于 Karpukhin 等人在 DPR 工作中的评估脚本,我们添加了一个预处理步骤,该步骤忽略“()”内的内容并通过某些分隔符分割答案字符串以提取多个答案。
3.2 实验设置
作为参考,我们使用额外的语料库进行微调方法的实验,这些方法是基于 NQ 数据集的训练分割进行微调的,并且其中大多数采用 Wikipedia dump 作为额外的语料库。我们还测试了我们对最近 LLMs 的检索方法的实现。具体来说,我们使用微调的 DPR 从 Wikipedia 检索前 5 个文档作为上下文,并雇用 LLM 作为 Reader 来根据上下文回答问题。
除非另有说明,我们会按照之前的工作,使用 Sentence-BERT 进行问题编码。默认的上下文演示数量为 8,这些演示通过每个集群中问题的最大余弦相似度进行采样。
对于 RQ1,我们采用 ChatGPT(gpt-3.5-turbo-0301)作为 LLM 来进行以下实验。根据 OpenAI,gpt-3.5-turbo-0301 是对 InstructGPT(text-davinci- 003)模型的改进,其性能与text-davinci-003 的推断能力相当。我们在实验中使用了每个数据集的整个开发集。
对于 RQ2,我们不仅测试 InstructGPT(text-davinci-003),还使用了三个较小规模(13B)的 LLMs:Alpaca、Vicuna 和 WizardLM,这些是在不同大规模遵循指令的数据集上微调的 LLaMA 模型。为了节省计算成本,我们对这四个数据集的子集进行了此实验,随机选择了测试集中的 1000 个样本。
3.3 实验结果
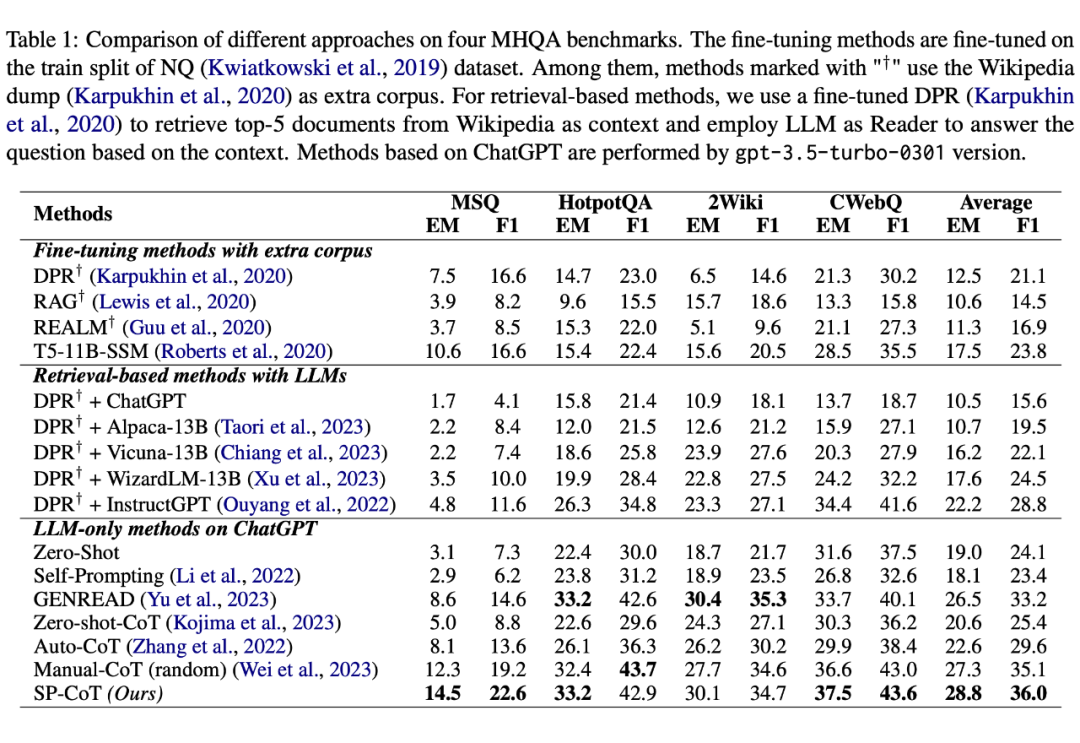
RQ1 的主要结果如表 1 所示。即使有额外的语料库,由于 MHQA 的固有挑战,基于 NQ 微调的模型表现不佳。在使用相同的检索模型的情况下,基于检索的方法的性能在很大程度上取决于 LLM 阅读器。与之前仅基于 LLM 的工作
相比,我们的 SP-CoT 在平均水平上明显优于 Auto-CoT,EM 得分高出 ,F1 得分高出 ,并超过之前的 SOTA 方法 GENREAD,平均 EM 得分高出 ,F1 得分高出 。在最具挑战性的基准测试 MSQ上,SP-CoT 使 ChatGPT 明显超过了其他仅基于 LLM 的方法。
我们注意到,在 MSQ 上,SP-CoT 显著优于 GENREAD,证实了为复杂的多跳问题提供高质量 CoTs 作为上下文示范的有效性。在其他三个数据集上,SP-CoT 与 GENREAD 的性能相当。然而,GENREAD 严重依赖于 LLMs 的生成忠实度,这对小规模的 LLMs 来说是具有挑战性的。通过将要求苛刻的指令分解为逐步简单的指令,我们的方法更适用于小规模的 LLMs,这一点在表2中得到了验证。
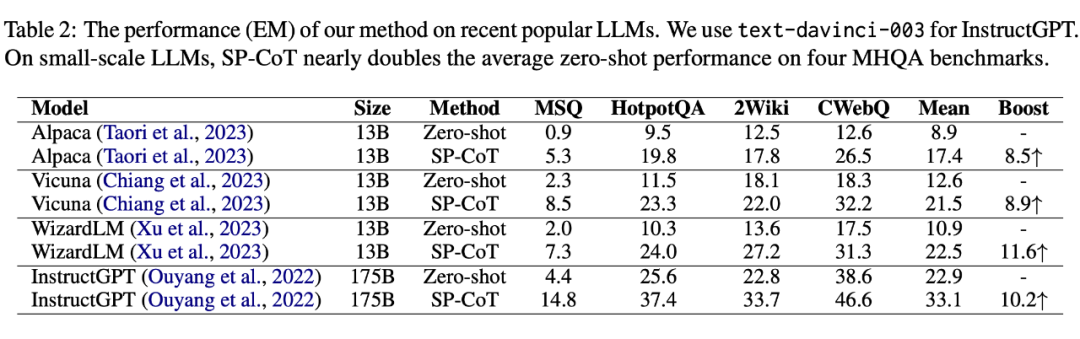
表 2 展示了 RQ2 的结果。我们提出的 SP-CoT 经验证,通过显著提升这四个 LLMs 在所有四个基准测试上的性能,证明了其普遍有效性。使用 SP-CoT,小规模(13B)LLMs 的性能可以被提升,与直接提示的 LLMs 相当,这些 LLMs 的大小超过了 10 倍,在不考虑由 SP-CoT 引出的高质量的中间推理步骤的情况下。

分析
在这一部分,我们探讨了抽样方法和示范数量的选择。然后我们检查了由 SP-CoT 引出的中间推理步骤的质量,以及自生成数据的质量。除非另有说明,我们使用 ChatGPT(gpt-3.5-turbo-0301)在 RQ2 设置中提到的相同子集上进行分析。
4.1 示范抽样的方法
ICL 的性能在很大程度上取决于示范抽样的质量。我们测试了以下五种策略的有效性:随机抽样(Random)、通过最大余弦相似度全局抽样(Retrieve)、在每个簇中抽样最接近中心的(ClusterCenter)、在每个簇中通过最大余弦相似度抽样(RetrieveInCluster)以及在每个簇中按某种推理类型抽样最相似的 QAs(RetrieveInTypeCluster)。
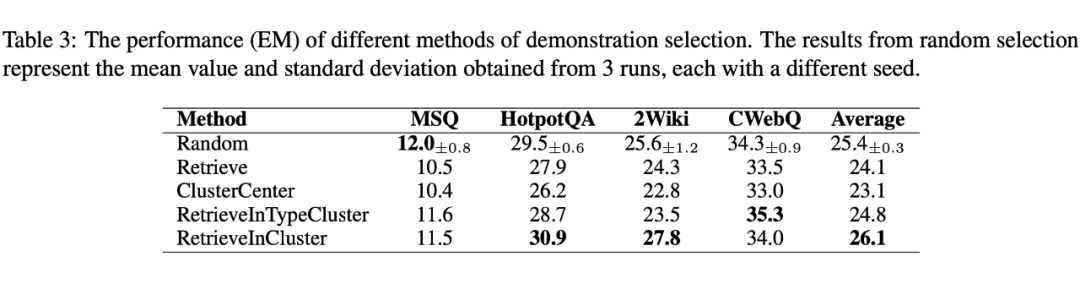
输入问题的推理类型由其 个最近邻的最频繁推理类型确定。如表 3 所示,RetrieveInCluster 是表现最好的策略,这恰恰是我们在之前的实验中采用的策略。
4.2 示范数量的影响
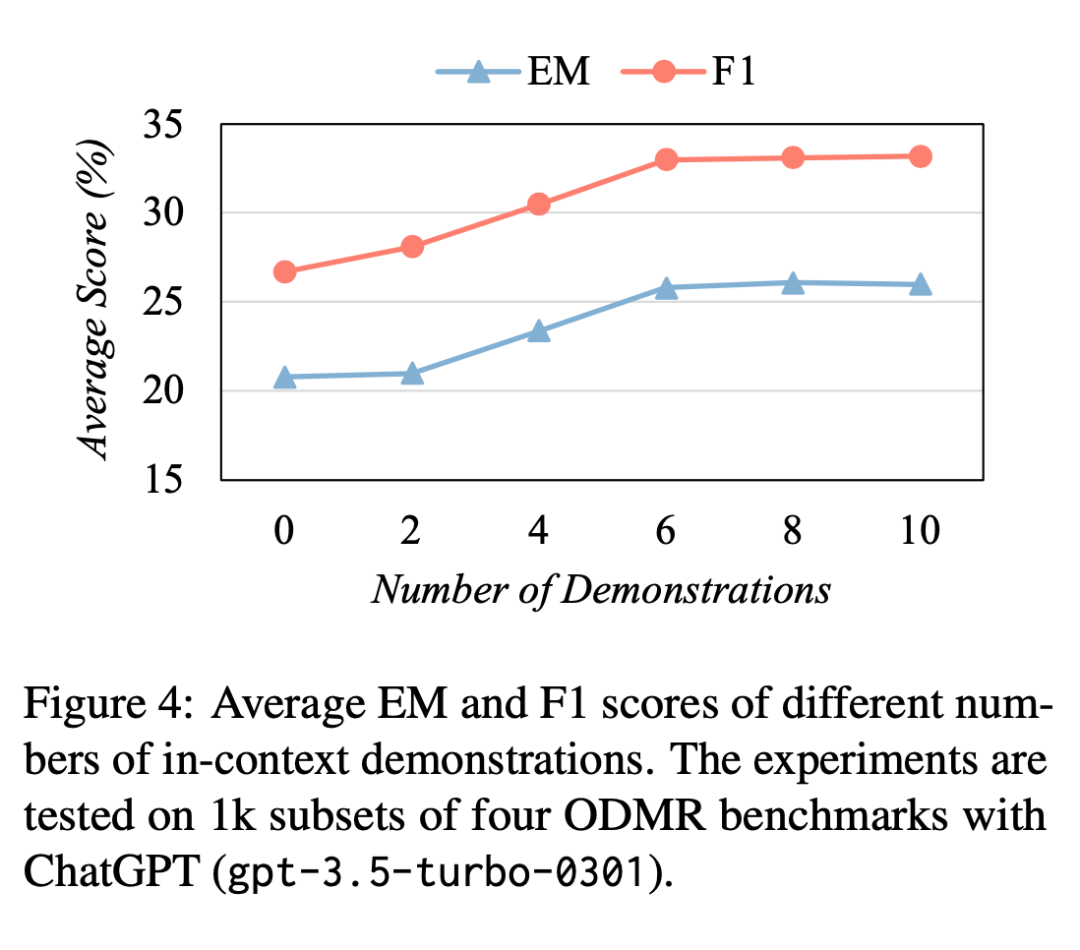
提供更多的上下文示范实证上可以改善 ICL 的性能;然而,这也会导致计算成本增加。为此,我们探究了示范数量和所得性能提升之间的权衡。我们报告了 2、4、6、8 和 10 个上下文示范在四个基准上的 EM 和 F1 分数,以及零样本设置中的分数。
如图 4 所示,当示范数量在 2 到 8 之间时,SP-CoT 的性能随着示范数量的增加而提高;但是,使用 10 个示范并没有带来进一步的性能提升。在我们的主要实验中,我们选择了 8 作为默认的示范数量,在性能和成本之间找到了一个平衡。
4.3 中间推理质量分析
鉴于我们提出的 SP-CoT 构建的高质量 CoTs,我们研究了推断过程中生成的中间推理步骤的质量。为了这个分析,我们使用了 MSQ 的开发集,因为它是四个数据集中最具挑战性的,并提供了分解的逐步 QAs。我们比较了 Zero-shot-CoT、Auto-CoT 和 SP-CoT 在推断过程中生成的 CoTs。
为了公平,我们从所有三种方法都正确回答的 59 个问题中选择了 50 个。首先,我们使用 GPT-4 评估中间推理步骤在清晰度、简洁性、可理解性和直接性上的表现,并分别在 1 到 10 的范围内打分。此外,我们计算了在每种方法的推理步骤中共同出现的中间答案的回忆准确率。
为了公平,我们只报告了每种方法正确回答的问题的中间答案回忆准确率。如图 5 所示,GPT-4 高度青睐我们的 SP-CoT,其中间答案的回忆准确率接近 50%。这表明 SP-CoT 在清晰度、简洁性、可理解性和直接性方面产生了高质量的推理步骤。


总结
在这项工作中,我们利用 LLMs 的能力,结合自我提示的 CoTs,来解决开放领域下称为 ODMR 的复杂 MHQA 任务。我们创新的 SP-CoT 不仅通过超越前面的 CoT 提示技术设定了一个新的基准,而且在开放领域的问答中也超越了过去的仅大模型 SOTA 方法。
SP-CoT 的一个显著特点是其在引导高质量中间推理步骤方面的高效能,以及其在大规模和小规模 LLMs 上的普遍有效性。我们预期我们为 ODMR 设计的创新自我生成流程不仅会成为 SP-CoT 的基础,而且还将为未来的研究铺平道路,促使研究方向转向利用 LLMs 的自我生成能力,由 LLMs 完成,为 LLMs 服务。
更多阅读




#投 稿 通 道#
让你的文字被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学术热点剖析、科研心得或竞赛经验讲解等。我们的目的只有一个,让知识真正流动起来。
📝 稿件基本要求:
• 文章确系个人原创作品,未曾在公开渠道发表,如为其他平台已发表或待发表的文章,请明确标注
• 稿件建议以 markdown 格式撰写,文中配图以附件形式发送,要求图片清晰,无版权问题
• PaperWeekly 尊重原作者署名权,并将为每篇被采纳的原创首发稿件,提供业内具有竞争力稿酬,具体依据文章阅读量和文章质量阶梯制结算
📬 投稿通道:
• 投稿邮箱:hr@paperweekly.site
• 来稿请备注即时联系方式(微信),以便我们在稿件选用的第一时间联系作者
• 您也可以直接添加小编微信(pwbot02)快速投稿,备注:姓名-投稿

△长按添加PaperWeekly小编
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
·
·