垂直领域对话系统是指针对特定领域或行业的需求而构建的对话系统。这种系统通常需要具备高度的专业知识和对特定领域的知识库进行深入的学习和训练,以便能够提供准确、高效、实用的服务。
垂直领域对话系统的构建通常包括以下步骤:
- 确定目标领域或行业:首先需要明确所要构建的对话系统所针对的领域或行业,例如医疗、金融、教育、旅游等。
- 数据收集和处理:收集和处理相关领域或行业的数据,包括文本、语音、图像等各类信息,建立相应的数据集。
- 模型训练:利用深度学习等技术对数据集进行训练,构建自然语言理解、自然语言生成等模型,提高系统的性能和表现。
- 构建对话系统:根据实际需求和目标,设计并构建对话系统,包括自然语言理解、对话管理、自然语言生成等模块。
- 测试和优化:对构建好的对话系统进行测试和优化,确保系统的稳定性和性能。
垂直领域对话系统的优势在于能够针对特定领域的需求进行优化,提供更加专业、高效、实用的服务。同时,由于专注于特定领域,系统的构建难度和成本相对较低,能够更好地满足实际需求。但是需要注意的是,垂直领域对话系统在面对不同领域或行业时,需要重新进行数据收集和模型训练,以便更好地适应和满足特定领域的需求。
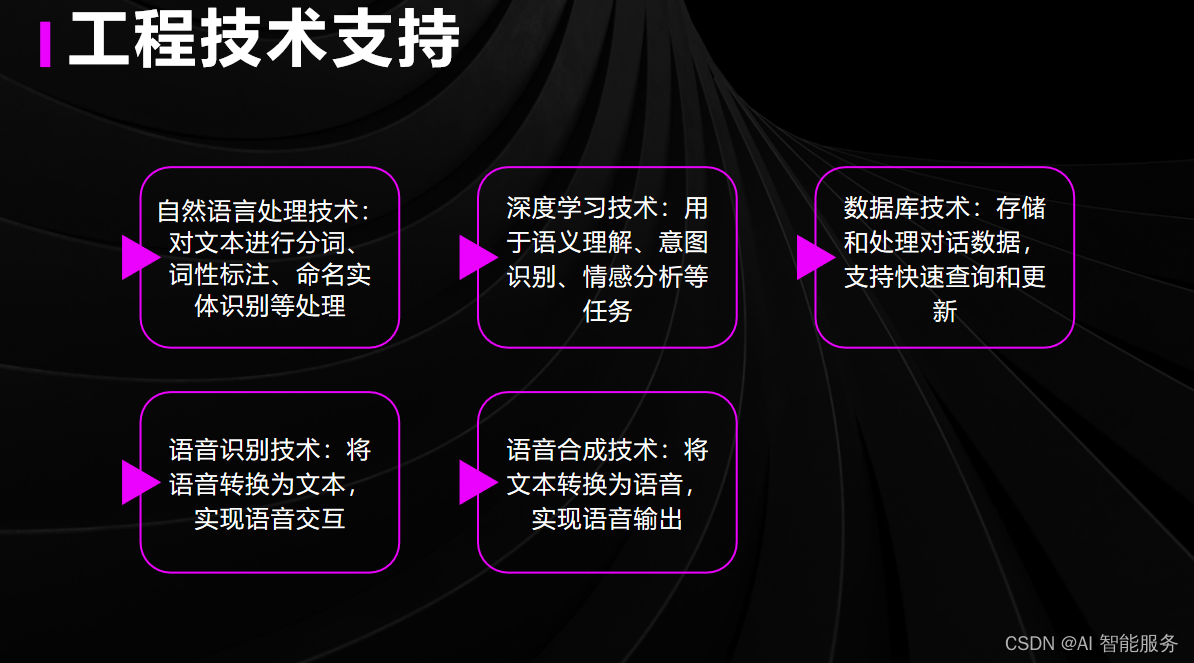
1.系统组成
垂直领域对话系统架构的核心是三个模块:自然语言理解模块、对话管理模块和自然语言生成模块。
- 自然语言理解模块:这个模块主要负责对用户的问题在句子级别进行分类,明确意图识别;同时在词级别找出用户问题中的关键实体,进行实体槽填充。
- 对话管理模块:这个模块主要负责对当前对话状态和决定系统反应的管理。
- 自然语言生成模块:这个模块主要负责反馈给用户信息。
以上三个模块联合作用,共同实现垂直领域对话系统的架构。


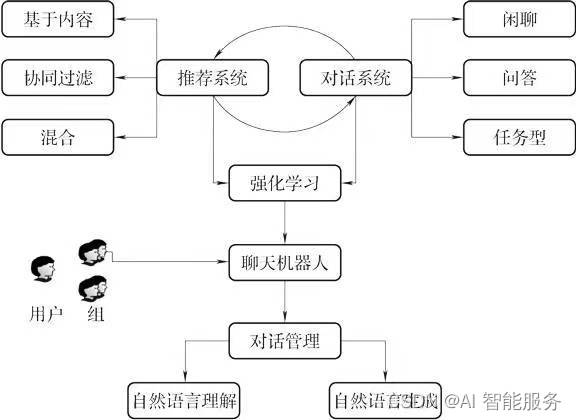
2.以电商为例搭建垂直领域对话系统
垂直电商领域对话系统可以举个例子:假设某电商公司希望构建一个智能客服系统来提高客户服务的效率和质量。该公司的垂直电商领域对话系统可以包括以下模块:
- 自然语言理解模块:这个模块可以用来理解客户的问题和需求,例如产品信息、订单状态、售后服务等。通过自然语言处理技术,可以识别客户的意图,并从大量的产品信息和历史数据中提取相关信息,以回答客户的问题。
- 对话管理模块:这个模块可以用来管理对话的状态和流程,例如对话的上下文、历史记录、推荐的解决方案等。通过机器学习和人工智能技术,可以建立对话流程模型,并根据客户的问题和需求,推荐合适的解决方案,引导客户解决问题。
- 自然语言生成模块:这个模块可以用来生成自然语言的回答和反馈,例如针对客户的问题进行回答、根据对话流程生成合适的反馈等。通过自然语言生成技术,可以生成流畅、自然、符合语法规则的回答和反馈,提高客户满意度和服务质量。
该电商公司的垂直电商领域对话系统可以基于云计算平台构建,利用大量的历史数据和机器学习算法进行训练和优化,以提高系统的性能和准确性。同时,该系统可以根据实际需求进行定制化开发,以适应不同领域和行业的特定需求。通过垂直电商领域对话系统的应用,可以提高客户服务效率和质量,降低客户流失率,提高公司的竞争力和市场占有率。

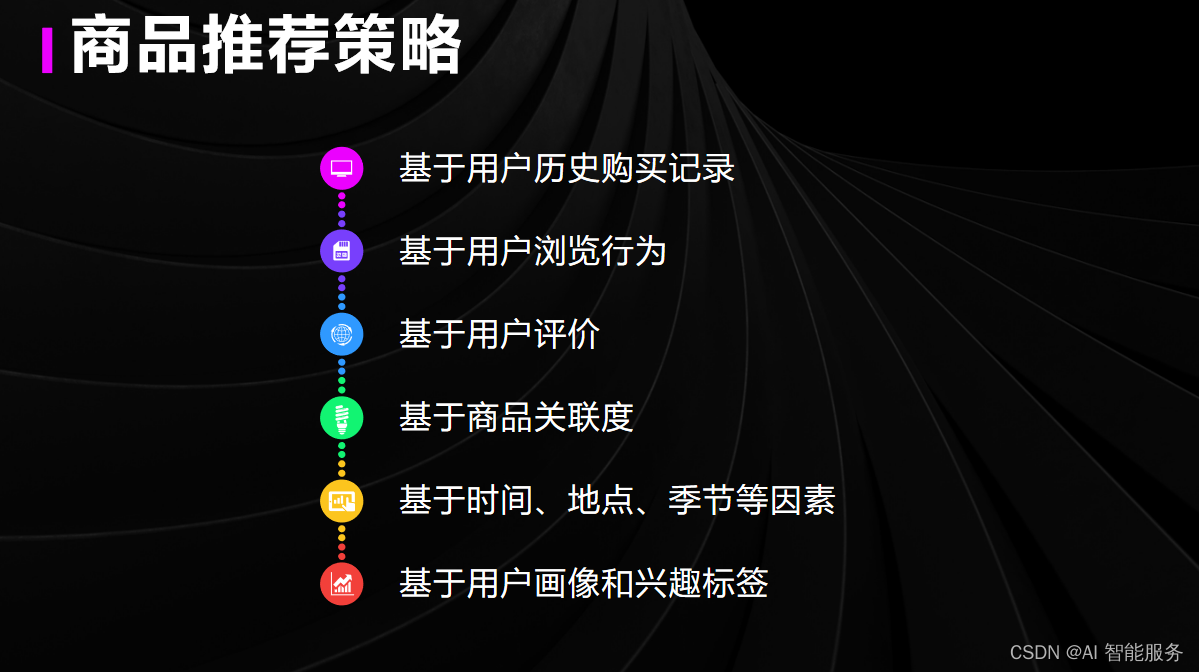
2.1用户行为特征考虑



2.2.推荐导购功能实现


2.3用python搭建一个电商智能客服
要使用Python搭建一个电商智能客服,需要以下几个步骤:
1.数据收集与处理
首先需要收集电商平台的客户咨询数据,并对数据进行处理和分析。可以使用Python中的爬虫技术来抓取电商平台的咨询数据,使用自然语言处理技术对数据进行清洗和预处理,以便后续的模型训练和智能客服的搭建。
2.模型训练
使用处理后的数据训练一个自然语言处理模型,用于识别用户的意图和问题,并生成相应的回答和建议。可以使用深度学习框架如TensorFlow或PyTorch来构建模型,并使用大量的数据来训练模型,以提高模型的准确性和泛化能力。
3.智能客服搭建
基于训练好的模型,可以搭建一个智能客服系统。可以使用Python中的Web框架如Django或Flask来构建系统,并使用自然语言处理技术来实现用户与系统的交互。系统可以根据用户的意图和问题生成相应的回答和建议,以提供智能化的服务和支持。
4.集成到电商平台
最后,可以将智能客服系统集成到电商平台上,以便用户可以直接在平台上与智能客服进行交互。可以使用电商平台提供的API或插件来实现集成,同时也可以考虑与电商平台的用户认证系统进行集成,以便更好地管理和保护用户数据。
代码展示
import nltk
from nltk.corpus import stopwords
from nltk.tokenize import word_tokenize, sent_tokenize
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import linear_kernel # 读取数据
data = []
with open('customer_inquiries.txt', 'r') as f: for line in f: data.append(line.strip()) # 数据预处理
stop = set(stopwords.words('english'))
exclude = set(['not', 'no', 'and', 'or', 'the', 'a', 'an'])
texts = [[word for word in sent_tokenize(line) if word not in stop and word not in exclude] for line in data] # 构建TF-IDF模型
vectorizer = TfidfVectorizer(tokenizer=word_tokenize)
vectors = vectorizer.fit_transform(texts) # 计算余弦相似度
sim = linear_kernel(vectors, vectors) # 定义客服函数
def customer_service(query): # 查询TF-IDF模型 vector = vectorizer.transform([query]) sim_scores = list(enumerate(sim[vector.toarray()])) sim_scores = sorted(sim_scores, key=lambda x: x[1], reverse=True) response = [] for i, score in sim_scores: response.append((data[i], score)) # 返回最匹配的几个回答和得分 return response[:5]3.挑战与展望
垂直领域对话系统在实现过程中面临许多挑战,例如:
- 数据收集和处理:在垂直领域中,数据的收集和处理需要针对特定领域或行业的需求进行定制化处理,这需要大量的时间和精力。同时,由于数据的复杂性和多样性,数据预处理和标注也需要耗费大量的人力物力。
- 模型训练:垂直领域对话系统的模型训练需要基于大量的数据集进行,同时需要采用先进的深度学习技术,这需要强大的计算资源和专业的技术人员。
- 鲁棒性:由于垂直领域对话系统针对的是特定领域或行业,因此系统的鲁棒性需要得到保障。这意味着系统需要能够处理各种异常情况,并且能够持续地进行优化和改进。(鲁棒性是英文robustness一词的音译,也可意译为稳健性。它是在异常和危险情况下系统生存的能力。在控制理论中,鲁棒性是指控制系统在一定(结构,大小)的参数摄动下,维持其它某些性能的特性。根据对性能的不同定义,可分为稳定鲁棒性和性能鲁棒性。)
- 隐私和安全:垂直领域对话系统在处理用户数据时需要保护用户的隐私和安全,这需要采取严格的数据保护措施和技术手段,以确保用户数据的安全性和保密性。
尽管面临这些挑战,垂直领域对话系统仍然具有广阔的发展前景。随着技术的不断进步和应用的不断深化,垂直领域对话系统将更加智能化、自动化、个性化,能够更好地满足用户的需求和服务质量的要求。未来,垂直领域对话系统将在各个行业得到广泛应用,例如金融、医疗、教育、旅游等,为人们提供更加便捷、高效、智能的服务体验。