文章目录
- 内存分布
- new/delete
- 基本用法
- malloc/free和new/delete的区别
- 进一步理解
- new和delete的实现原理
- 定位new(了解)
内存分布

栈(stack):栈是由编译器自动管理的内存区域,用于存储局部变量,函数参数和函数调用信息等。栈的特点是后进先出,它的生命周期与函数的调用关系密切联系。当函数调用结束后,栈上的局部变量会被自动销毁。
堆(heap):堆是由程序员手动管理的动态内存区域,用于存储动态分配的对象。通过使用new/delete等操作符来手动申请和释放堆上的内存。堆上的内存生命周期由程序员来负责控制,需要手动释放以避免内存泄漏。
全局存储区(data):全局存储区用于存储全局变量和静态变量。全局变量在程序运行期间一直存在,静态变量具有生命周期,即从声明到程序结束都存在。全局存储区的内存由编译器在程序开始时进行分配,在程序结束时进行自动释放。
常量存储区(cost):常量存储区用于存储常量值,例如字符串常量,数字等。这部分内存通常是只读的,不可修改。
new/delete
在C语言中,我们是用malloc和free来进行动态内存管理的,而在C++中,我们习惯使用new/delete来进行动态内存管理。
基本用法
class A
{
private:int _a;
public:A(int a=0):_a(a){cout << "A()" << endl;}~A(){cout << "~A()" << endl;}
};
int main()
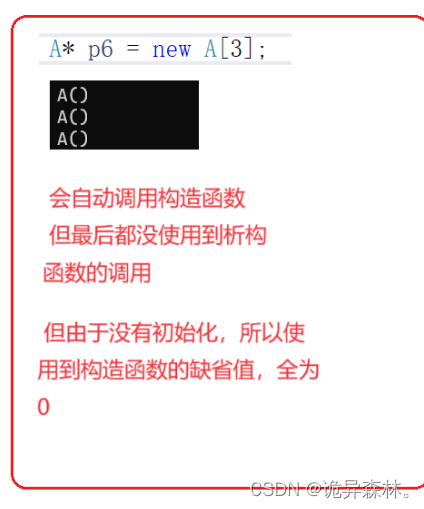
{//newint* p1 = new int;*p1 = 20;int* p2 = new int[10];p2[0] = 1;p2[1] = 2;int* p3 = new int(4);int* p4 = new int[10] {1, 2, 3};delete p1;delete[] p2;delete p3;delete[] p4;//对于自定义类型来说//new的本质:开空间+使用构造函数A aa1;A aa2;A aa3;A* p5 = new A[3]{ aa1,aa2,aa3 };A* p6 = new A[3];A* p7 = new A[3]{ A(1),A(2),A(3) };A* p8 = new A[3]{ 1,2,3 };delete[] p5;delete[] p6;delete[] p7;delete[] p8;return 0;
}
基本用法:
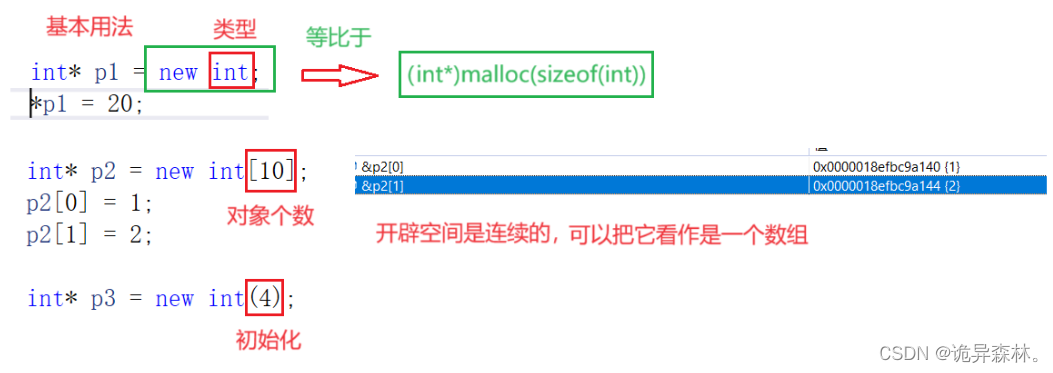

有自定义类型时:



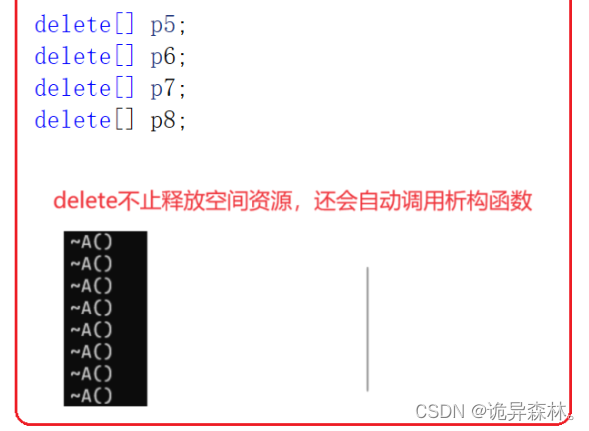
malloc/free和new/delete的区别

进一步理解
class Stack
{
private:int* _a;int _top;int _capacity;
public:Stack(int capacity = 4):_a(new int[capacity]),_top(0),_capacity(capacity){cout << "Stack(int capacity):" << endl;}~Stack(){cout << "~Stack()" << endl;delete[] _a;_a = nullptr;_top = 0;_capacity = 0;}
};
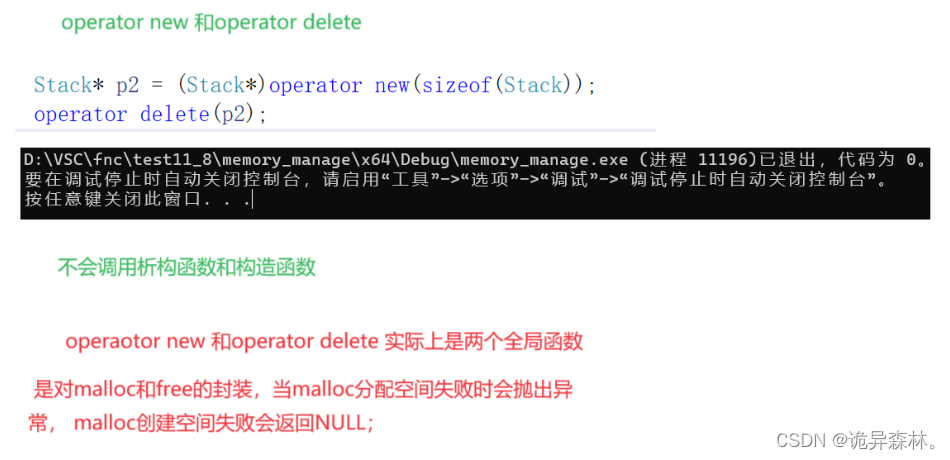
int main()
{Stack* p1 = new Stack;delete p1;Stack* p2 = (Stack*)operator new(sizeof(Stack));operator delete(p2);Stack* p3 = new Stack[10];//delete[] p3;delete p3;A* p4 = new A[10];delete p4;return 0;
}
空间的开辟:

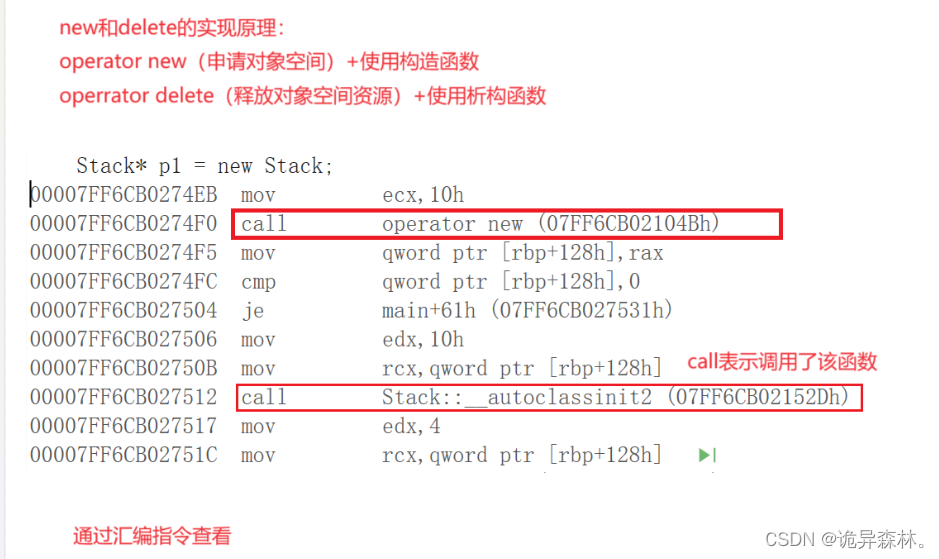
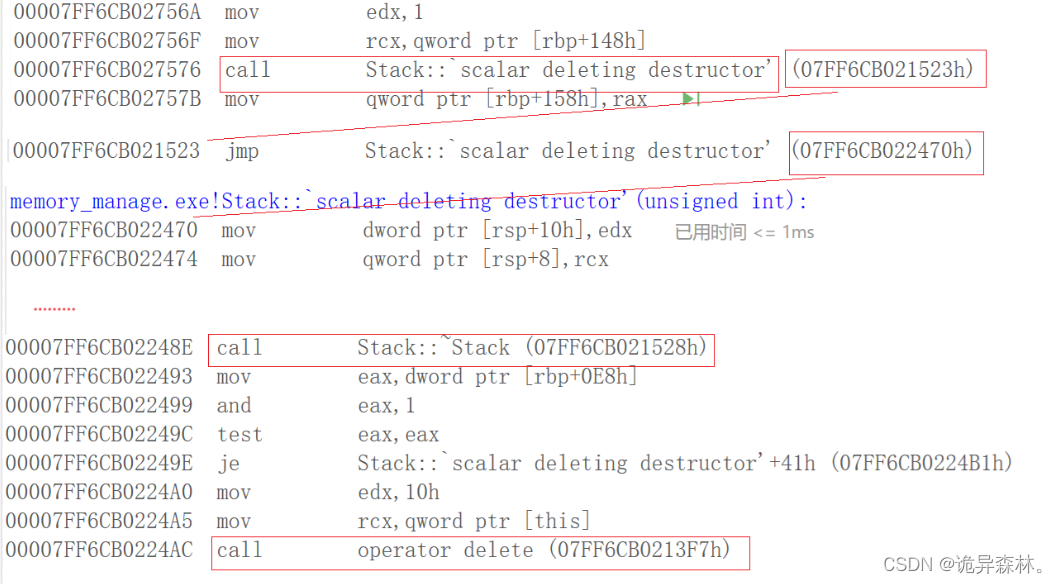
操作数new和delete:
当把析构函数屏蔽了,使用delete p3,为什么可以通过编译:
*


new和delete的实现原理

定位new(了解)
定位new是一种特殊的用法,用于在指定的内存位置上创建对象。通常情况下,使用new关键字会在堆内存中动态分配一块适当的空间大小,并在该内存上构造一个对象。而定位new则允许我们预先分配一块内存,并在该内存上构造对象。
语法形式:new(address)Type(arguments)
int main()
{A* p1 = (A*)operator new(sizeof(A));//不能显示调用构造函数//p1->A(1);//可以这样操作new(p1)A(1);//析构函数可以显示调用p1->~A();operator delete(p1);}