前言
表弟自从学会了Python,每天一回家就搁那爬视频,不知道的以为是在学习,结果我昨天好奇看了一眼,好家伙,在那爬某牙舞蹈区,太过分了!

为了防止表弟做坏事,我连忙找了个凳子坐下,跟他一起欣赏~
啊呸,不对,监督他!

当然,作为一个大公无私的人,好东西怎么能独享呢?
这不立马就给大家分享一下~

准备工作
首先我们需要准备这些
软件模块
软件
- Python 3.10 解释器
- Pycharm 编辑器
模块
- requests # 数据请求
- re # 正则表达式模块
requests是第三方模块,win + R 输入cmd 输入安装命令 pip install requests 安装即可,re 是自带的模块,无需安装。
实现思路与流程
一. 数据来源分析
1. 明确需求: 明确采集的网站以及数据内容- 网址: https://www.某牙.com/video/play/933940354.html- 数据: 视频标题 / 视频内容 <主要数据>
2. 抓包分析: 浏览器开发者工具去抓包- 打开开发者工具: F12 / 右键点击检查选择network (网络)- 刷新网页: 网页相关数据内容- 通过关键字去搜索找到对应的数据包位置搜索: M3U8 -> getMomentContent数据包地址: https://某牙.com/moment/getMomentContent
二. 代码实现步骤
1. 发送请求 -> 模拟浏览器对于url地址发送请求
2. 获取数据 -> 获取服务器返回响应数据
3. 解析数据 -> 提取视频标题 / 链接
4. 保存数据 -> 获取视频数据保存本地文件夹里面
源码展示
发送请求 -> 模拟浏览器对于url地址发送请求
headers = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36'
}
url = f'https://某牙.com/moment/getMomentContent?videoId=904494849&uid=&_=1700050245436'
# 发送请求
response = requests.get(url=url, headers=headers)
获取数据 -> 获取服务器返回响应数据
json_data = response.json() # json() 括号里面不需要加东西
解析数据 -> 提取视频标题 / 链接
# 提取标题
title = json_data['data']['moment']['title']
# 提取视频链接
video_url = json_data['data']['moment']['videoInfo']['definitions'][0]['url']
保存数据 -> 获取视频数据保存本地文件夹里面
video_content = requests.get(url=video_url, headers=headers).content
with open('video\\' + title + '.mp4', mode='wb') as f:# 写入数据f.write(video_content)
print(title, video_url)
完整源码和视频讲解我都打包好了,直接文末名片自取~

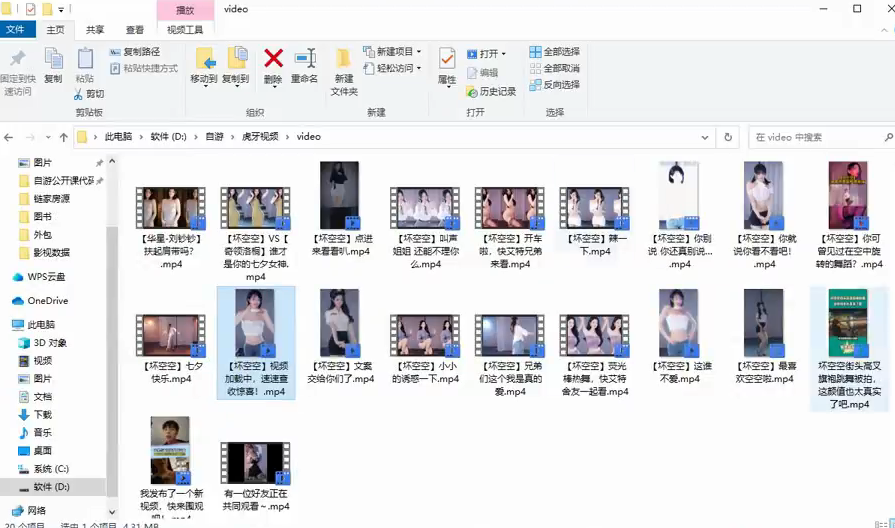
效果展示
播放效果我就不展示了,影响不好,大家自行观看~
好了,本次的分享就到这结束了,咱们下次见!