目录
00 预告
01 课程安排
02 深度学习介绍
03 安装
本地安装
04 数据操作+数据预处理
数据操作
数据类型
创建数组
访问元素
数据操作实现
入门
运算符
广播机制
索引和切片
节省内存
转换为其他Python对象
数据预处理实现
读取数据集
处理缺失值
转换为张量格式
小结
00 预告
《动手学深度学习》![]() https://github.com/d2l-ai/d2l-zh
https://github.com/d2l-ai/d2l-zh
01 课程安排

02 深度学习介绍
03 安装
本地安装
· 使用conda/miniconda环境
conda env remove d2l-zh
conda create -n -y d2l-zh python=3.8 pip
conda activate d2l-zh
· 安装需要的包
pip install -y jupyter d2l torch torchvision
pip install jupyter d2l torch torchvision -i https://pypi.tuna.tsinghua.edu.cn/simple使用上面这个命令行可以极大程度的提高下载速度
· 下载代码并执行
wget https://zh-v2.d2l.ai/d2l-zh.zip
unzip d2l-zh.zip
jupyter notebook
DIVE INTO DEEP LEARNING![]() https://zh.d2l.ai/chapter_installation/index.html
https://zh.d2l.ai/chapter_installation/index.html
04 数据操作+数据预处理
数据操作
数据类型

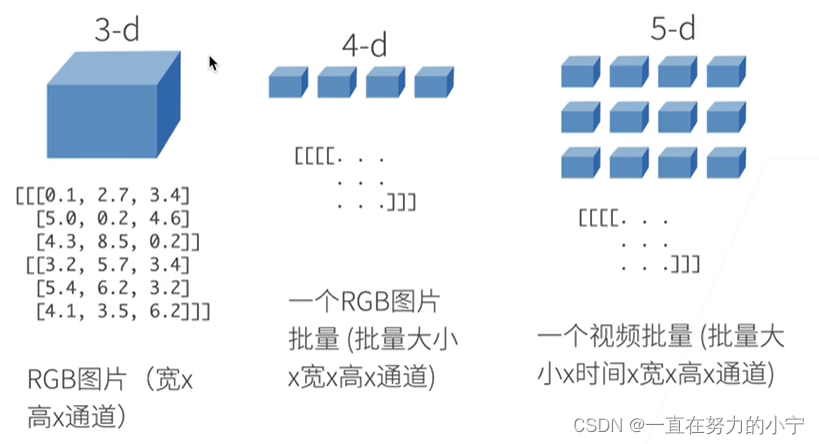
0一个标量
1一个特征向量
2一个样本-特征矩阵
3RGB图片(widthxheightxchannel)
4RGB图片批量(batch x width x height x channel)
5视频批量(batch x time x width x height x channel)
创建数组
形状、数据类型、元素的值
访问元素
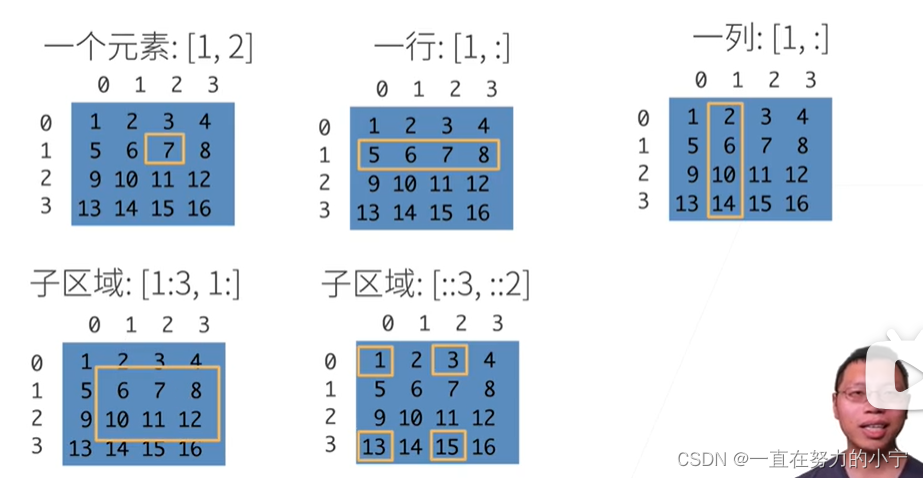
数据操作实现
入门
import torchx = torch.arange(12) xx.shapex.numel()X = x.reshape(3, 4) Xtorch.zeros((2, 3, 4))torch.ones((2, 3, 4))torch.randn(3, 4)torch.tensor([[2, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]])
运算符
x = torch.tensor([1.0, 2, 4, 8]) y = torch.tensor([2, 2, 2, 2]) x + y, x - y, x * y, x / y, x ** y # **运算符是求幂运算torch.exp(x)X = torch.arange(12, dtype=torch.float32).reshape((3,4)) Y = torch.tensor([[2.0, 1, 4, 3], [1, 2, 3, 4], [4, 3, 2, 1]]) torch.cat((X, Y), dim=0), torch.cat((X, Y), dim=1)X == YX.sum()
广播机制
a = torch.arange(3).reshape((3, 1)) b = torch.arange(2).reshape((1, 2)) a, b
索引和切片
X[-1], X[1:3]X[1, 2] = 9 XX[0:2, :] = 12 X
节省内存
before = id(Y) Y = Y + X id(Y) == before
转换为其他Python对象
A = X.numpy() B = torch.tensor(A) type(A), type(B)a = torch.tensor([3.5]) a, a.item(), float(a), int(a)
数据预处理实现
读取数据集
import osos.makedirs(os.path.join('..', 'data'), exist_ok=True)
data_file = os.path.join('..', 'data', 'house_tiny.csv')
with open(data_file, 'w') as f:f.write('NumRooms,Alley,Price\n') # 列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n')f.write('4,NA,178100\n')f.write('NA,NA,140000\n')# 如果没有安装pandas,只需取消对以下行的注释来安装pandas
# !pip install pandas
import pandas as pddata = pd.read_csv(data_file)
print(data)处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
inputs = inputs.fillna(inputs.mean())
print(inputs)inputs = pd.get_dummies(inputs, dummy_na=True)
print(inputs)转换为张量格式
from mxnet import npX, y = np.array(inputs.to_numpy(dtype=float)), np.array(outputs.to_numpy(dtype=float)) X, y
小结
-
pandas软件包是Python中常用的数据分析工具中,pandas可以与张量兼容。 -
用
pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。




![[PyTorch][chapter 63][强化学习-QLearning]](https://img-blog.csdnimg.cn/933bd586568f494fa86a22caa39a6652.png)