点击@CV计算机视觉,关注更多CV干货
论文已打包,点击进入—>下载界面
点击加入—>CV计算机视觉交流群
1.【基础网络架构:Transformer】Aggregate, Decompose, and Fine-Tune: A Simple Yet Effective Factor-Tuning Method for Vision Transformer
-
论文地址:https://arxiv.org//pdf/2311.06749
-
开源代码(即将开源):https://github.com/Dongping-Chen/EFFT-EFfective-Factor-Tuning

2.【缺陷检测】Self-supervised Context Learning for Visual Inspection of Industrial Defects
-
论文地址:https://arxiv.org//pdf/2311.06504
-
开源代码(即将开源):https://github.com/wangpeng000/VisualInspection

3.【目标检测、分割】CD-COCO: A Versatile Complex Distorted COCO Database for Scene-Context-Aware Computer Vision
-
论文地址:https://arxiv.org//pdf/2311.06976
-
开源代码:https://github.com/Aymanbegh/CD-COCO

4.【视频分割】Sketch-based Video Object Segmentation: Benchmark and Analysis
-
论文地址:https://arxiv.org//pdf/2311.07261
-
开源代码(即将开源):https://github.com/YRlin-12/Sketch-VOS-datasets

5.【多模态】SPHINX: The Joint Mixing of Weights, Tasks, and Visual Embeddings for Multi-modal Large Language Models
-
论文地址:https://arxiv.org//pdf/2311.07575
-
开源代码:https://github.com/Alpha-VLLM/LLaMA2-Accessory

6.【多模态】To See is to Believe: Prompting GPT-4V for Better Visual Instruction Tuning
-
论文地址:https://arxiv.org//pdf/2311.07574
-
开源代码(即将开源):https://github.com/X2FD/LVIS-INSTRUCT4V

7.【多模态】GPT-4V in Wonderland: Large Multimodal Models for Zero-Shot Smartphone GUI Navigation
-
论文地址:https://arxiv.org//pdf/2311.07562
-
开源代码(即将开源):https://github.com/zzxslp/MM-Navigator

8.【多模态】GPT-4V(ision) as A Social Media Analysis Engine
-
论文地址:https://arxiv.org//pdf/2311.07547
-
开源代码(即将开源):https://github.com/VIStA-H/GPT-4V_Social_Media

9.【多模态】InfMLLM: A Unified Framework for Visual-Language Tasks
-
论文地址:https://arxiv.org//pdf/2311.06791
-
开源代码:https://github.com/mightyzau/InfMLLM

10.【多模态】Q-Instruct: Improving Low-level Visual Abilities for Multi-modality Foundation Models
-
论文地址:https://arxiv.org//pdf/2311.06783
-
工程主页:Q-Instruct | [IQA, Low-level Vision, MLLM] Low-level visual instruction tuning, with a 200K dataset and a model zoo for fine-tuned checkpoints.
-
开源代码:https://github.com/Q-Future/Q-Instruct/

11.【多模态】ChatAnything: Facetime Chat with LLM-Enhanced Personas
-
论文地址:https://arxiv.org//pdf/2311.06772
-
工程主页:ChatAnything
-
开源代码:https://github.com/zhoudaquan/ChatAnything

12.【多模态】Monkey: Image Resolution and Text Label Are Important Things for Large Multi-modal Models
-
论文地址:https://arxiv.org//pdf/2311.06607
-
开源代码(即将开源):https://github.com/Yuliang-Liu/Monkey

13.【多模态】An LLM-free Multi-dimensional Benchmark for MLLMs Hallucination Evaluation
-
论文地址:https://arxiv.org//pdf/2311.07397
-
开源代码(即将开源):https://github.com/junyangwang0410/AMBER

14.【多模态】Volcano: Mitigating Multimodal Hallucination through Self-Feedback Guided Revision
-
论文地址:https://arxiv.org//pdf/2311.07362
-
开源代码(即将开源):https://github.com/kaistAI/Volcano

15.【多模态】ViLMA: A Zero-Shot Benchmark for Linguistic and Temporal Grounding in Video-Language Models
-
论文地址:https://arxiv.org//pdf/2311.07022
-
工程主页:ViLMA - Video Language Model Assessment
-
开源代码:https://github.com/ilkerkesen/ViLMA

16.【数字人】(WACV2024)CVTHead: One-shot Controllable Head Avatar with Vertex-feature Transformer
-
论文地址:https://arxiv.org//pdf/2311.06443
-
开源代码(即将开源):https://github.com/HowieMa/CVTHead

17.【深度估计】MonoDiffusion: Self-Supervised Monocular Depth Estimation Using Diffusion Model
-
论文地址:https://arxiv.org//pdf/2311.07198
-
开源代码(即将开源):https://github.com/ShuweiShao/MonoDiffusion

18.【深度估计】(ICCV2023)NDDepth: Normal-Distance Assisted Monocular Depth Estimation and Completion
-
论文地址:https://arxiv.org//pdf/2311.07166
-
开源代码(即将开源):https://github.com/ShuweiShao/NDDepth

19.【自动驾驶:BEV】Detecting As Labeling: Rethinking LiDAR-camera Fusion in 3D Object Detection
-
论文地址:https://arxiv.org//pdf/2311.07152
-
开源代码:https://github.com/HuangJunJie2017/BEVDet

20.【自动驾驶:BEV】Deep Perspective Transformation Based Vehicle Localization on Bird's Eye View
-
论文地址:https://arxiv.org//pdf/2311.06796
-
开源代码(即将开源):https://github.com/IPM-HPC/Perspective-BEV-Transformer

21.【Diffusion】Sampler Scheduler for Diffusion Models
-
论文地址:https://arxiv.org//pdf/2311.06845
-
开源代码:https://github.com/Carzit/sd-webui-samplers-scheduler

22.【NeRF】-Sampler: An Model Guided Volume Sampling for NeRF
-
论文地址:https://arxiv.org//pdf/2311.07044
-
工程主页:L0-Sampler: An L0 Model Guided Volume Sampling for NeRF
-
开源代码:https://github.com/USTC3DV/L0-Sampler-code

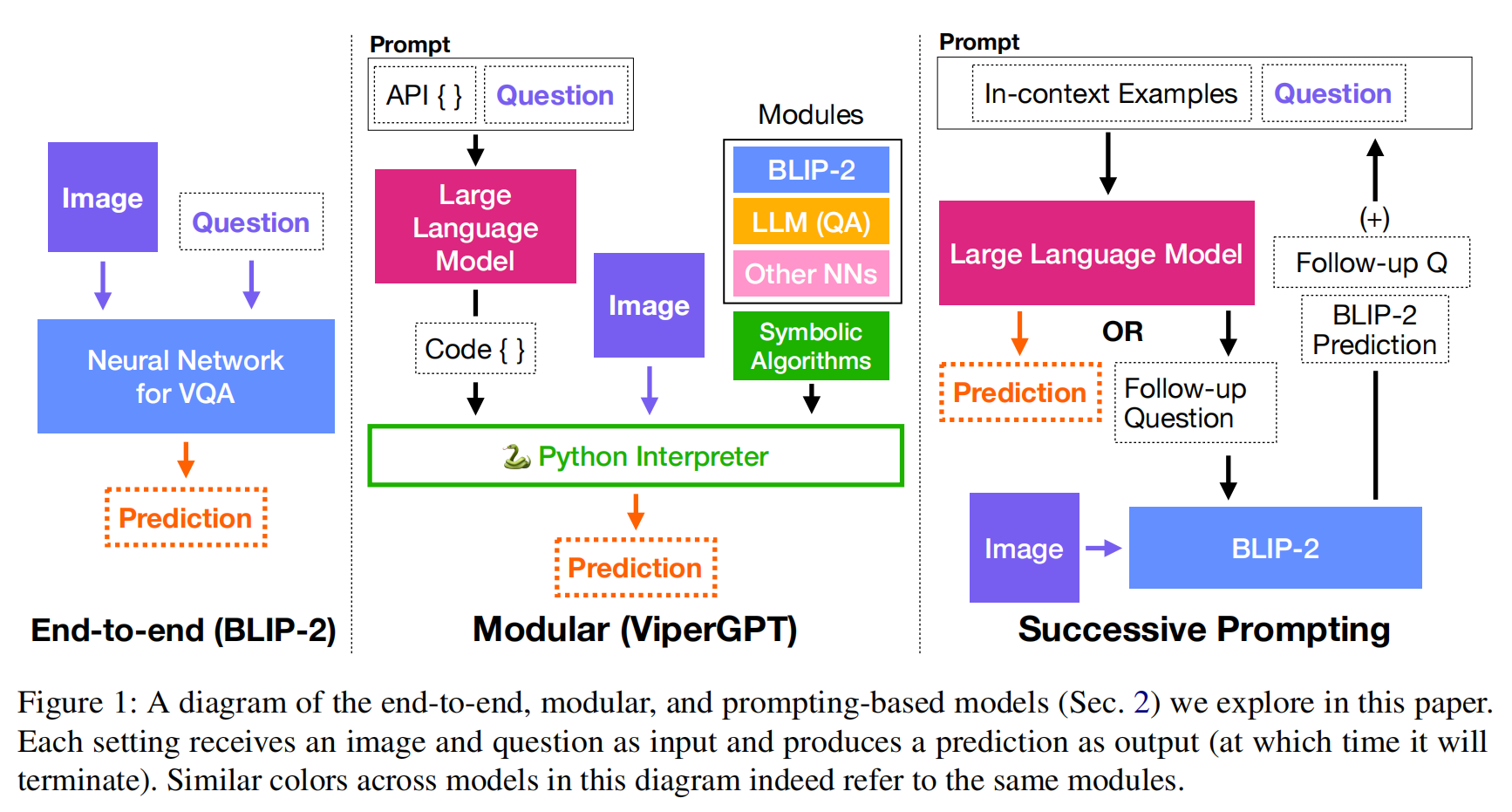
23.【Visual Question Answering】Analyzing Modular Approaches for Visual Question Decomposition
-
论文地址:https://arxiv.org//pdf/2311.06411
-
开源代码:https://github.com/brown-palm/visual-question-decomposition
论文已打包,下载链接
CV计算机视觉交流群
群内包含目标检测、图像分割、目标跟踪、Transformer、多模态、NeRF、GAN、缺陷检测、显著目标检测、关键点检测、超分辨率重建、SLAM、人脸、OCR、生物医学图像、三维重建、姿态估计、自动驾驶感知、深度估计、视频理解、行为识别、图像去雾、图像去雨、图像修复、图像检索、车道线检测、点云目标检测、点云分割、图像压缩、运动预测、神经网络量化、网络部署等多个领域的大佬,不定期分享技术知识、面试技巧和内推招聘信息。
想进群的同学请添加微信号联系管理员:PingShanHai666。添加好友时请备注:学校/公司+研究方向+昵称。
推荐阅读:
CV计算机视觉每日开源代码Paper with code速览-2023.11.13
CV计算机视觉每日开源代码Paper with code速览-2023.11.10
CV计算机视觉每日开源代码Paper with code速览-2023.11.9
CV计算机视觉每日开源代码Paper with code速览-2023.11.8
CV计算机视觉每日开源代码Paper with code速览-2023.11.7
CV计算机视觉每日开源代码Paper with code速览-2023.11.6