目录
- 一、介绍
- 二、HDFS设计原理
- 2.1 HDFS 架构
- 2.2 数据复制
- 复制的实现原理
- 三、HDFS的特点
- 四、图解HDFS存储原理
- 1. 写过程
- 2. 读过程
- 3. HDFS故障类型和其检测方法
- 故障类型和其检测方法
- 读写故障的处理
- DataNode 故障处理
- 副本布局策略
一、介绍
HDFS (Hadoop Distributed File System)是 Hadoop 下的分布式文件系统,具有高容错、高吞吐量等特性,可以部署在低成本的硬件上。
二、HDFS设计原理
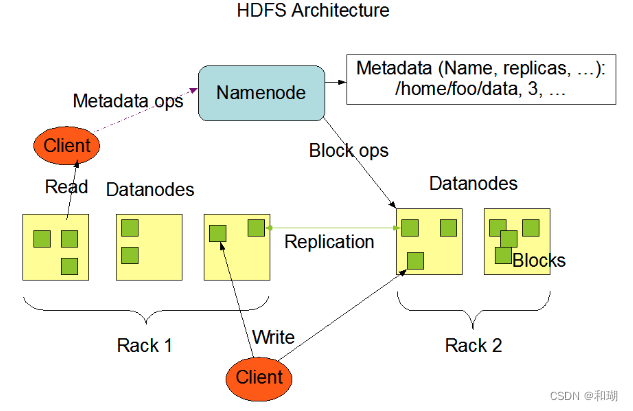
2.1 HDFS 架构
HDFS 遵循主/从架构,由单个 NameNode(NN) 和多个 DataNode(DN) 组成:
- NameNode : 文件系统的管理节点,维护整个系统的元数据,包括文件目录树、文件/目录信息,以及每个文件对应的block列表等
- DataNode:文件系统的数据节点,提供真实文件数据的存储服务。
注:
- HDFS在存储时,以block的形式存储数据,默认大小为128M(2.x和3.x版本)
- 如果文件超过128M,就会被切分为多个block存储
- 如果文件不足128M,则只产生一个block(只占用实际大小的磁盘空间)
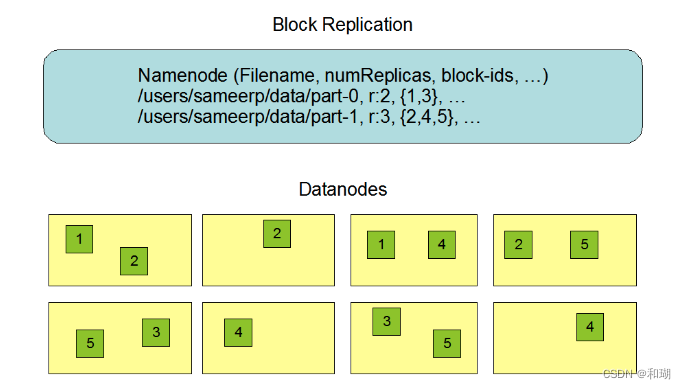
2.2 数据复制
为了保证容错性,HDFS 提供了数据复制机制。HDFS 将每一个文件存储为一系列block,每个块由多个副本来保证容错,块的大小和复制因子可以自行配置(默认情况下,块大小是 128M,默认复制因子是 3)
复制的实现原理
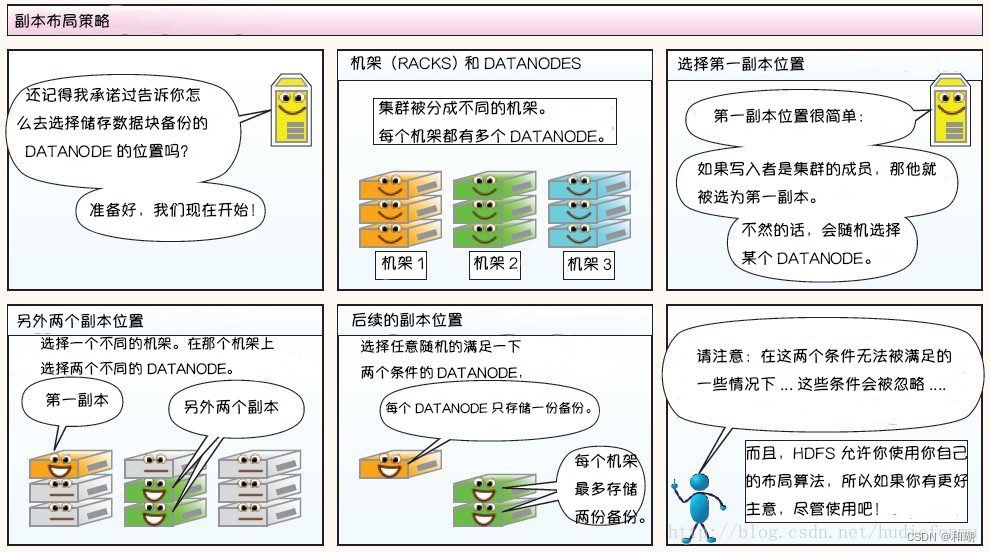
大型的 HDFS 实例在通常分布在多个机架的多台服务器上。在大多数情况下,同一机架中的服务器间的网络带宽大于不同机架中的服务器之间的带宽。因此 HDFS 采用机架感知副本放置策略,对于常见情况,当复制因子为 3 时,HDFS 的放置策略是:
- 在写入程序位于 datanode 上时,就优先将写入文件的一个副本放置在该 datanode 上,否则放在随机 datanode 上
- 之后在另一个远程机架上的任意一个节点上放置另一个副本
- 并在该机架上的另一个节点上放置最后一个副本
此策略可以减少机架间的写入流量,从而提高写入性能。
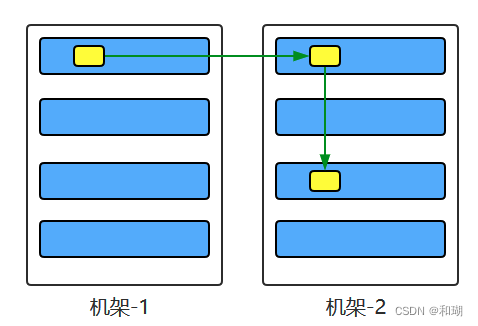
注意:同一个 dataNode 上不允许有同一个块的多个副本
三、HDFS的特点
- 优点
- 通透性:即使有通过网络访问文件的操作,但在程序和用户看来就像是在访问本地磁盘
- 高容错:多副本保证即使部分硬件损坏也不会导致全部数据的丢失
- 性价比高:可以运行在大量的廉价机器上,节约成本
- 缺点
- 不适合低延时数据访问:数据延时无法支持“毫秒”级别的数据存储
- 不适合小文件存储:主节点的内存是有限的,不论大小文件都会在主节点中保存元信息,存储大量小文件没有意义,违背HDFS的设计理念
- 不支持文件并发写入和随机修改:一个文件同时只能有一个线程执行写操作。只支持文件追加,不支持数据的随机访问和修改
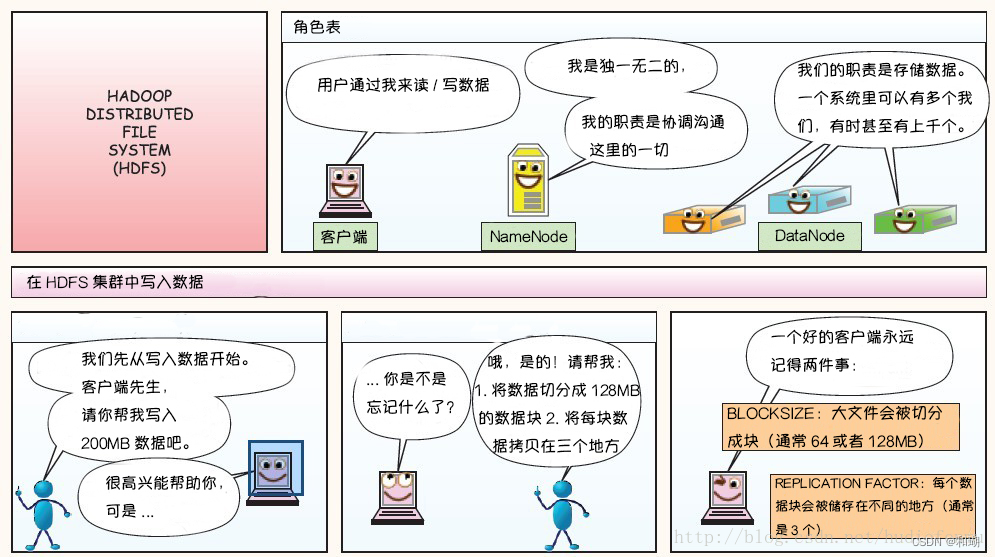
四、图解HDFS存储原理
以下图片引用自博客:翻译经典 HDFS 原理讲解漫画
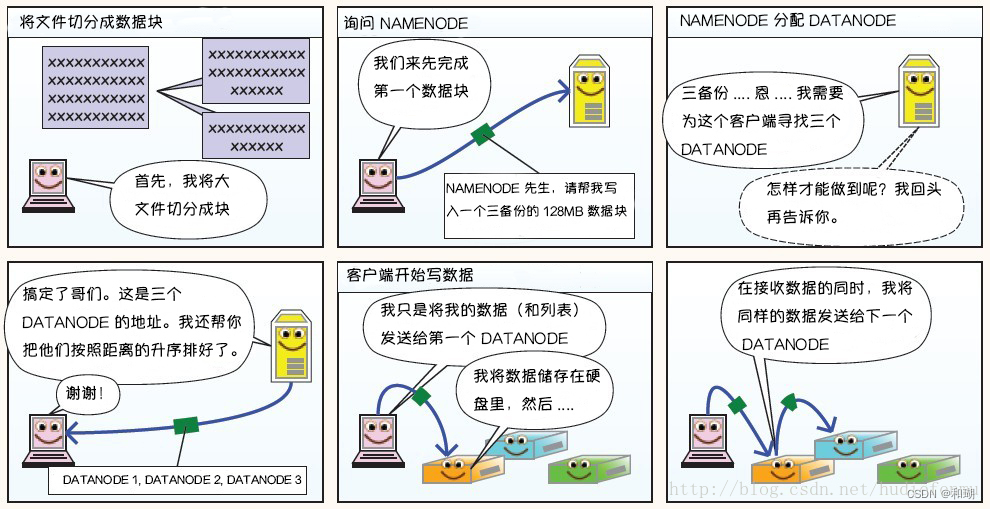
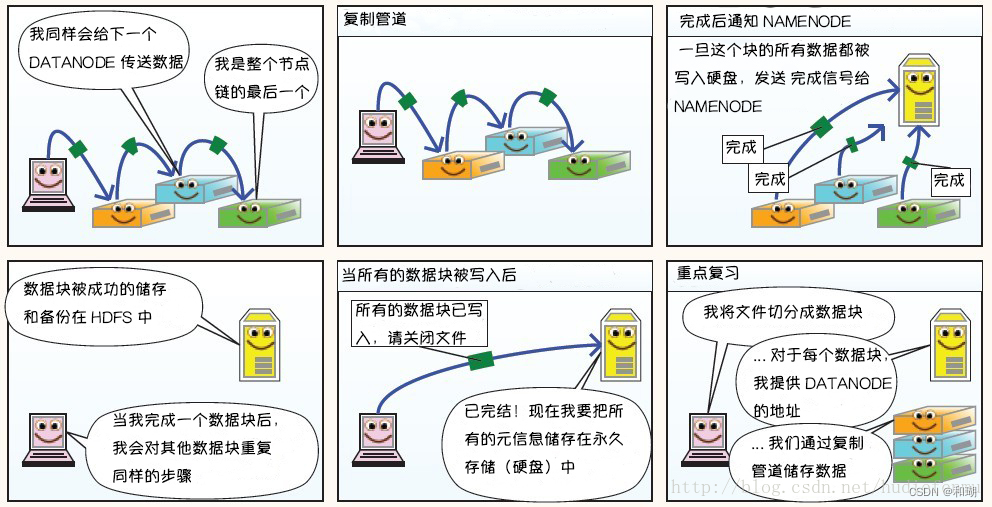
1. 写过程
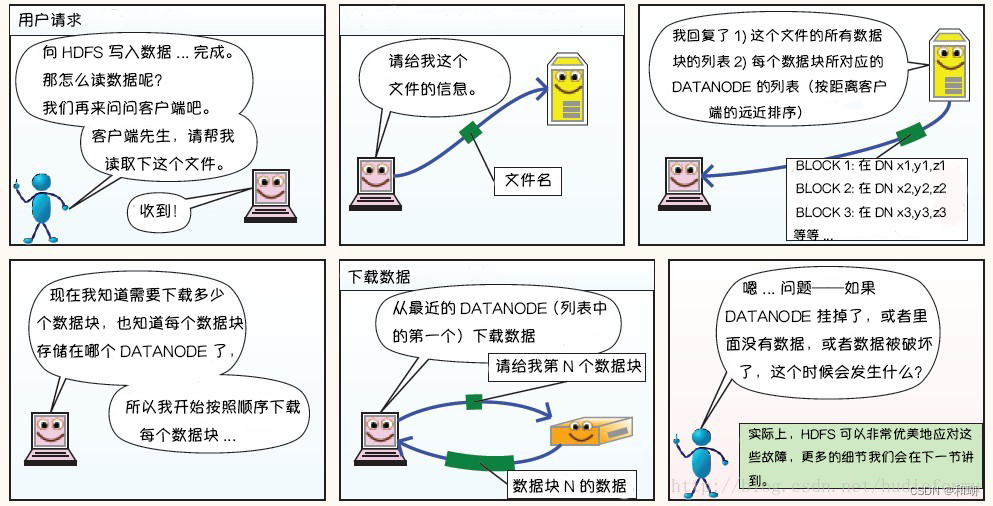
2. 读过程
3. HDFS故障类型和其检测方法
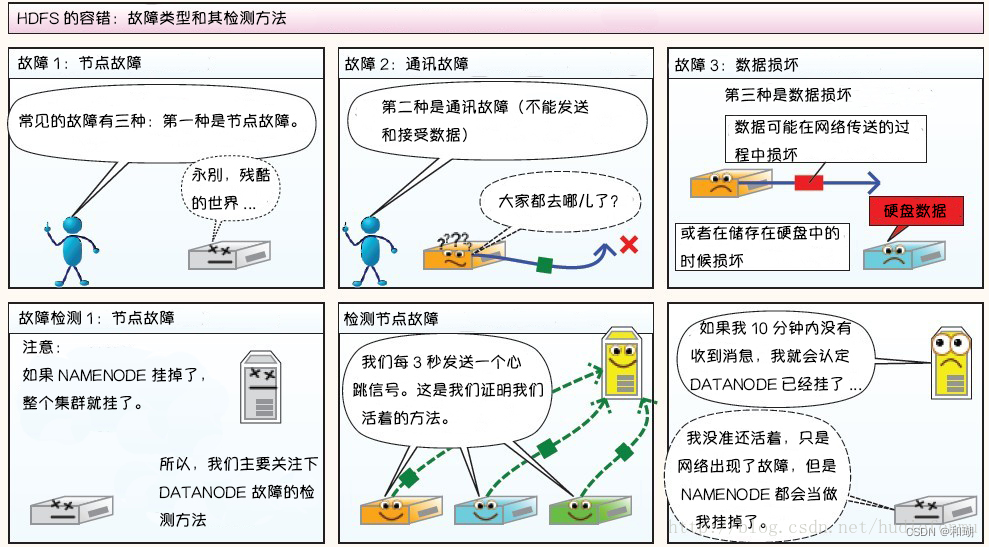
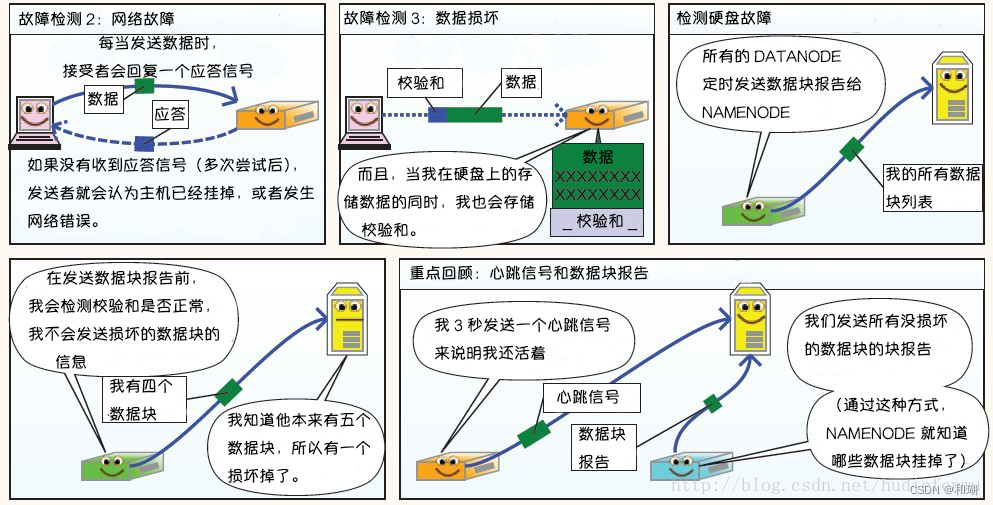
故障类型和其检测方法
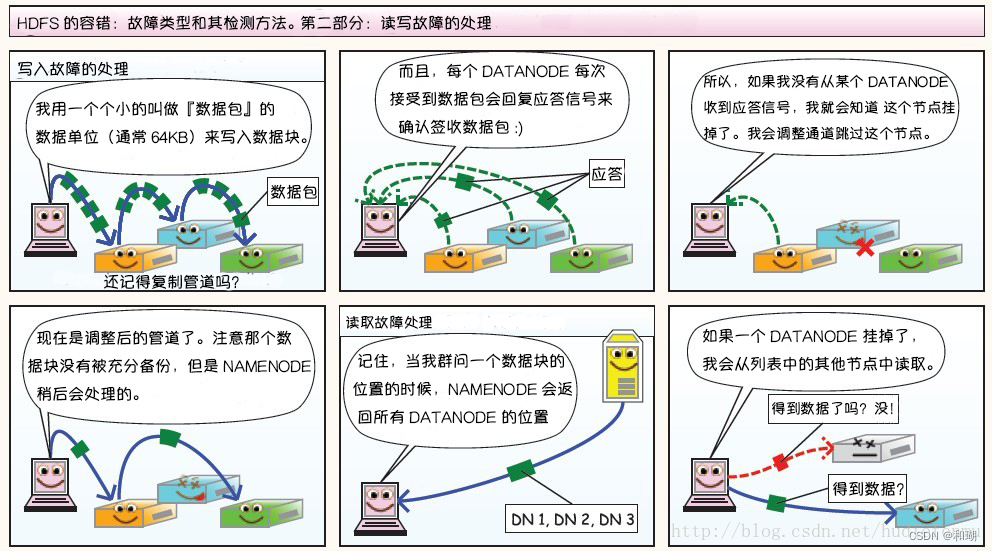
读写故障的处理
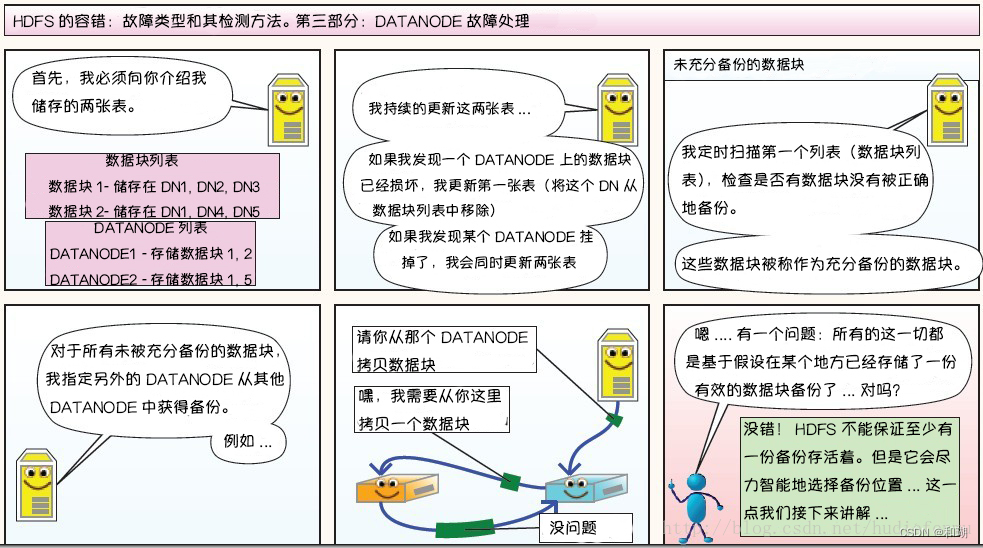
DataNode 故障处理
副本布局策略