一、本文介绍
本篇文章给大家带来的是利用我个人编写的架构进行TCN时间序列卷积进行时间序列建模(专门为了时间序列领域新人编写的架构,简单不同于市面上大家用GPT写的代码),包括结果可视化、支持单元预测、多元预测、模型拟合效果检测、预测未知数据、以及滚动长期预测功能。该结构是一个通用架构任何模型嵌入其中都可运行。下面来介绍一下TCN时间序列卷积的基本原理:时间序列卷积(Temporal Convolutional Network, TCN)通过一系列卷积层处理数据,每个层都能捕捉到不同时间范围内的模式,其主要通过以下三个操作因果卷积、扩张卷积、残差链接,三个操作来进行预测功能的实现。
专栏目录:时间序列预测目录:深度学习、机器学习、融合模型、创新模型实战案例
专栏: 时间序列预测专栏:基础知识+数据分析+机器学习+深度学习+Transformer+创新模型
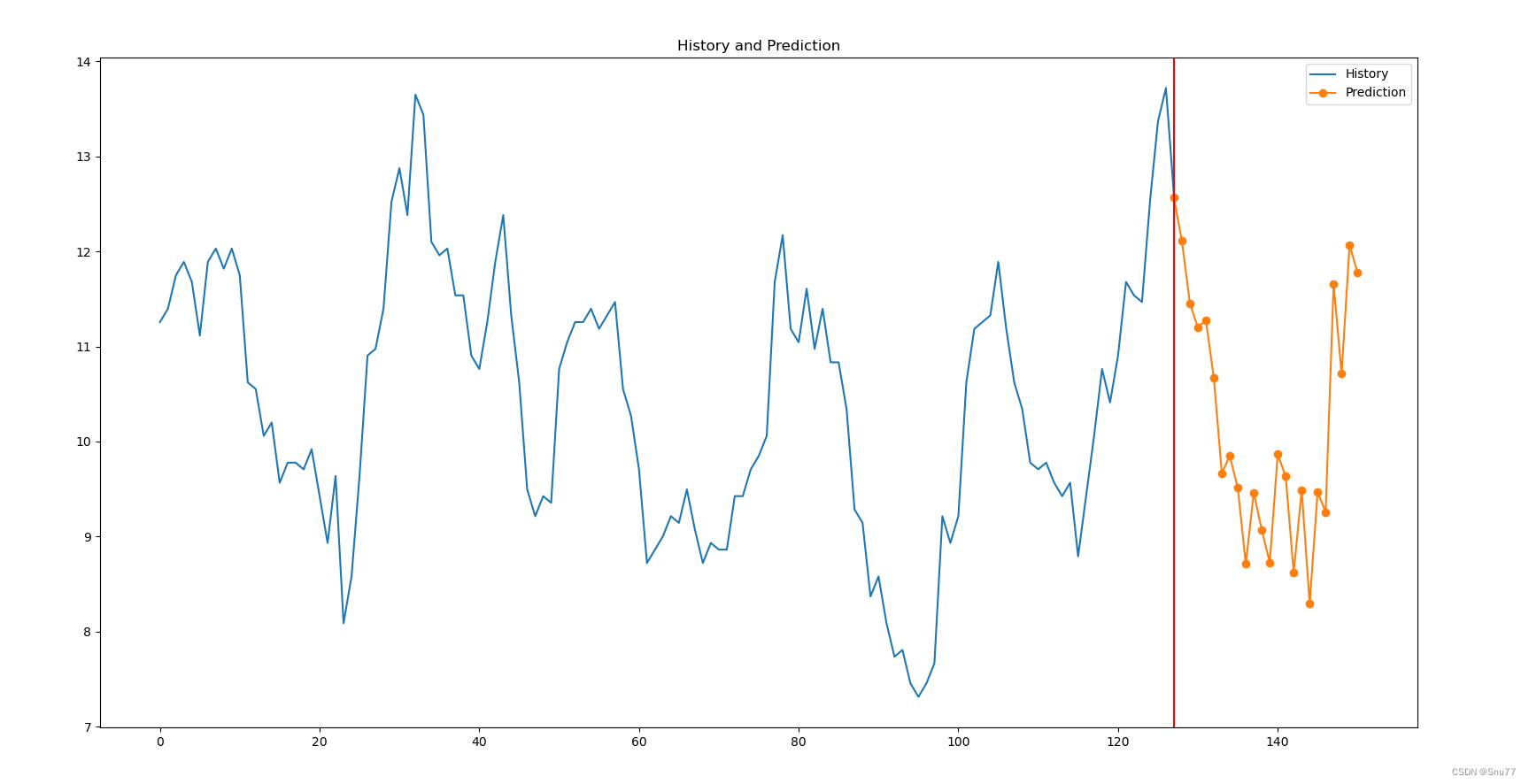
预测功能效果展示(不是测试集是预测未知数据)->
损失截图(损失这里我就没有画图直接打印下来了很直观)->
根据损失来看模型的拟合效果还是很好的,但后面还是做了检验模型拟合效果的功能让大家真正的评估模型的效果。

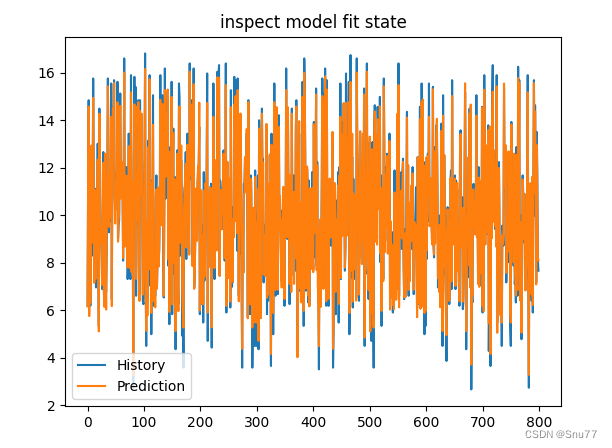
检验模型拟合情况->
(从下面的图片可以看出模型拟合的情况很好)
目录
一、本文介绍
二、TCN的框架原理
2.1 TCN的主要思想
2.2 因果卷积
2.3 扩张卷积
2.4 无便宜填充
三、数据集介绍
四、参数讲解
五、完整代码
六、训练模型
七、预测结果
7.1 预测未知数据效果图
7.2 测试集效果图
7.3 CSV文件生成效果图
7.4 检验模型拟合效果图
八、全文总结
二、TCN的框架原理

2.1 TCN的主要思想
TCN,即Temporal Convolutional Network,是一种专门用于时间序列数据处理的神经网络架构。TCN的关键特点包括:
1. 因果卷积:TCN使用因果卷积来确保在预测未来值时,只会使用当前和过去的信息,而不会出现信息泄露。
2. 扩张卷积:通过扩张卷积,TCN可以在不丢失时间分辨率的情况下增加感受野(即模型可以观察到的历史信息范围)。扩张卷积通过间隔地应用卷积核来实现。
3. 无偏移填充:为了保持输出的时间长度与输入相同,TCN在卷积操作前使用了一种特殊的填充方式。
下图是时间序列卷积的示意图

下面我来分别介绍这几种机制->
2.2 因果卷积
什么是因果卷积?首先我们来确定这个问题
- 因果关系意味着输出序列中的元素只能依赖于输入序列中它前面的元素。
- 为了确保输出张量与输入张量具有相同的长度,我们需要进行零填充。
- 如果我们只用零填充输入张量的左侧,那么因果卷积是有保证的。
在下图中是通过组合生成的
,
,
确保不会泄露信息。

此操作生成和
它们是无关的,应该在将输出传递到下一层之前删除。
TCN有两个基本原则:
- 序列的输入和输出长度保持不变。
- 过去不能有任何泄漏。
为了达到第一点,TCN利用了第二点,TCN利用了因果卷积。1D FCN ( Fully Convolutional Network)
2.3 扩张卷积
扩张卷积的工作原理
-
增加感受野:在标准的卷积中,卷积核覆盖的区域是连续的。扩张卷积通过在卷积核的各个元素之间插入空格(称为“扩张”)来扩大其覆盖区域。例如,一个扩张率为2的3x3卷积核实际上会覆盖一个5x5的区域,但只使用9个权重。
-
保持时间分辨率:与池化操作不同,扩张卷积不会减少数据的时间维度。这意味着输出数据在时间上的分辨率保持不变,这对于时间序列分析和音频处理等领域至关重要。
-
间隔应用:扩张卷积通过间隔地应用卷积核来实现其效果。这种间隔方式意味着卷积核可以跨越更大的区域,而不是只聚焦于紧邻的输入单元。
扩张卷积在TCN中的应用
在时间卷积网络(TCN)中,扩张卷积允许模型有效地处理长时间序列。通过增大感受野,TCN可以捕捉到更长范围内的依赖关系,这对于许多序列预测任务(如语音识别、自然语言处理等)非常有用。此外,扩张卷积的使用使得TCN在处理长序列时计算效率更高,因为它避免了重复计算和不必要的参数增加。
2.4 无便宜填充
无偏移填充在时间卷积网络(TCN)中的使用是为了保持输出序列的时间长度与输入序列相同,从而允许模型在处理序列数据时保持时间对齐。在传统的卷积操作中,通常会因为卷积核覆盖的范围而导致输出序列的长度减少。为了解决这个问题,TCN采用了无偏移填充的策略。
无偏移填充(Zero Padding)的工作原理
填充操作:无偏移填充是指在输入序列的开始部分添加适量的零值,以使得卷积操作后的输出序列长度不减少。这种填充方式通常用于时间序列的处理中,确保经过卷积后,时间维度上的长度保持不变。
保持时间对齐:在处理时间序列数据时,保持时间上的对齐非常重要,尤其是在预测未来事件或者在时间序列上做分类任务时。无偏移填充确保了输入和输出在时间维度上保持对齐。
防止信息丢失:在没有填充的情况下,卷积操作可能会导致序列边缘的信息丢失,因为卷积核无法完全覆盖这些区域。通过使用无偏移填充,可以保证序列的每个部分都被卷积核等同地处理。
在TCN中的应用
在TCN中,无偏移填充通常与扩张卷积结合使用。通过在卷积层之前适当地添加零值,可以保证即使在使用较大扩张率的情况下,输出序列的长度也与输入序列的长度相同。这样不仅保留了时间序列数据的完整性,还允许模型捕捉到长距离的依赖关系,提高模型对时间序列数据的处理能力。
三、数据集介绍
本文是实战讲解文章,上面主要是简单讲解了一下网络结构比较具体的流程还是很复杂的涉及到很多的数学计算,下面我们来讲一讲模型的实战内容,第一部分是我利用的数据集。
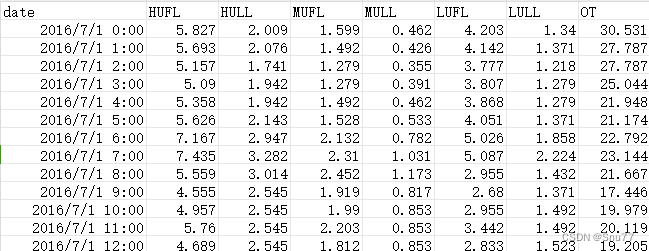
本文我们用到的数据集是ETTh1.csv,该数据集是一个用于时间序列预测的电力负荷数据集,它是 ETTh 数据集系列中的一个。ETTh 数据集系列通常用于测试和评估时间序列预测模型。以下是 ETTh1.csv 数据集的一些内容:
数据内容:该数据集通常包含有关电力系统的多种变量,如电力负荷、价格、天气情况等。这些变量可以用于预测未来的电力需求或价格。
时间范围和分辨率:数据通常按小时或天记录,涵盖了数月或数年的时间跨度。具体的时间范围和分辨率可能会根据数据集的版本而异。
以下是该数据集的部分截图->
四、参数讲解
parser.add_argument('-model', type=str, default='TCN', help="模型持续更新")parser.add_argument('-window_size', type=int, default=128, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-output_size', type=int, default=1, help='输出特征个数只有两种选择和你的输入特征一样即输入多少输出多少,另一种就是多元预测单元')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')parser.add_argument('-model_dim', type=list, default=[64, 128, 256], help='这个地方是这个TCN卷积的关键部分,它代表了TCN的层数我这里输''入list中包含三个元素那么我的TCN就是三层,这个根据你的数据复杂度来设置''层数越多对应数据越复杂但是不要超过5层')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=32, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden_size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel_sizes', type=int, default=3)parser.add_argument('-laryer_num', type=int, default=1)# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)为了大家方便理解,文章中的参数设置我都用的中文,所以大家应该能够更好的理解。下面我在进行一遍讲解。
| 参数名称 | 参数类型 | 参数讲解 | |
|---|---|---|---|
| 1 | model | str | 模型名称 |
| 2 | window_size | int | 时间窗口大小,用多少条数据去预测未来的数据 |
| 3 | pre_len | int | 预测多少条未来的数据 |
| 4 | shuffle | store_true | 是否打乱输入dataloader中的数据,不是数据的顺序 |
| 5 | data_path | str | 你输入数据的地址 |
| 6 | target | str | 你想要预测的特征列 |
| 7 | input_size | int | 输入的特征数不包含时间那一列!!! |
| 8 | output_size | int | 输出的特征数只可以是1或者是等于你输入的特征数 |
| 9 | feature | str | [M, S, MS],多元预测多元,单元预测单元,多元预测单元 |
| 10 | model_dim | list | 这个地方是这个TCN卷积的关键部分,它代表了TCN的层数我这里输入list中包含三个元素那么我的TCN就是三层,这个根据你的数据复杂度来设置层数越多对应数据越复杂但是不要超过5层!!!!重点部分 |
| 11 | lr | float | 学习率大小 |
| 12 | drop_out | float | 丢弃概率 |
| 13 | epochs | int | 训练轮次 |
| 14 | batch_size | int | 批次大小 |
| 15 | svae_path | str | 模型的保存路径 |
| 16 | hidden_size | int | 隐藏层大小 |
| 17 | kernel_size | int | 卷积核大小 |
| 18 | layer_num | int | lstm层数 |
| 19 | use_gpu | bool | 是否使用GPU |
| 20 | device | int | GPU编号 |
| 21 | train | bool | 是否进行训练 |
| 22 | predict | bool | 是否进行预测 |
| 23 | inspect_fit | bool | 是否进行检验模型 |
| 24 | lr_schduler | bool | 是否使用学习率计划 |
五、完整代码
复制粘贴到一个文件下并且按照上面的从参数讲解配置好参数即可运行~(极其适合新手和刚入门的读者)
import argparse
import time
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
from sklearn.preprocessing import StandardScaler, MinMaxScaler
from torch.utils.data import DataLoader
from torch.utils.data import Dataset
from tqdm import tqdm
import torch
import torch.nn as nn
from torch.nn.utils import weight_norm
# 随机数种子
np.random.seed(0)def plot_loss_data(data):# 使用Matplotlib绘制线图plt.plot(data)# 添加标题plt.title("loss results Plot")# 显示图例plt.legend(["Loss"])class TimeSeriesDataset(Dataset):def __init__(self, sequences):self.sequences = sequencesdef __len__(self):return len(self.sequences)def __getitem__(self, index):sequence, label = self.sequences[index]return torch.Tensor(sequence), torch.Tensor(label)def create_inout_sequences(input_data, tw, pre_len, config):# 创建时间序列数据专用的数据分割器inout_seq = []L = len(input_data)for i in range(L - tw):train_seq = input_data[i:i + tw]if (i + tw + pre_len) > len(input_data):breakif config.feature == 'MS':train_label = input_data[:, -1:][i + tw:i + tw + pre_len]else:train_label = input_data[i + tw:i + tw + pre_len]inout_seq.append((train_seq, train_label))return inout_seqdef calculate_mae(y_true, y_pred):# 平均绝对误差mae = np.mean(np.abs(y_true - y_pred))return maedef create_dataloader(config, device):print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<")df = pd.read_csv(config.data_path) # 填你自己的数据地址,自动选取你最后一列数据为特征列 # 添加你想要预测的特征列pre_len = config.pre_len # 预测未来数据的长度train_window = config.window_size # 观测窗口# 将特征列移到末尾target_data = df[[config.target]]df = df.drop(config.target, axis=1)df = pd.concat((df, target_data), axis=1)cols_data = df.columns[1:]df_data = df[cols_data]# 这里加一些数据的预处理, 最后需要的格式是pd.seriestrue_data = df_data.values# 定义标准化优化器scaler_train = StandardScaler()scaler_valid = StandardScaler()scaler_test = StandardScaler()train_data = true_data[int(0.3 * len(true_data)):]valid_data = true_data[int(0.15 * len(true_data)):int(0.30 * len(true_data))]test_data = true_data[:int(0.15 * len(true_data))]print("训练集尺寸:", len(train_data), "测试集尺寸:", len(test_data), "验证集尺寸:", len(valid_data))# 进行标准化处理train_data_normalized = scaler_train.fit_transform(train_data)test_data_normalized = scaler_test.fit_transform(test_data)valid_data_normalized = scaler_valid.fit_transform(valid_data)# 转化为深度学习模型需要的类型Tensortrain_data_normalized = torch.FloatTensor(train_data_normalized).to(device)test_data_normalized = torch.FloatTensor(test_data_normalized).to(device)valid_data_normalized = torch.FloatTensor(valid_data_normalized).to(device)# 定义训练器的的输入train_inout_seq = create_inout_sequences(train_data_normalized, train_window, pre_len, config)test_inout_seq = create_inout_sequences(test_data_normalized, train_window, pre_len, config)valid_inout_seq = create_inout_sequences(valid_data_normalized, train_window, pre_len, config)# 创建数据集train_dataset = TimeSeriesDataset(train_inout_seq)test_dataset = TimeSeriesDataset(test_inout_seq)valid_dataset = TimeSeriesDataset(valid_inout_seq)# 创建 DataLoadertrain_loader = DataLoader(train_dataset, batch_size=args.batch_size, shuffle=True, drop_last=True)test_loader = DataLoader(test_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)valid_loader = DataLoader(valid_dataset, batch_size=args.batch_size, shuffle=False, drop_last=True)print("通过滑动窗口共有训练集数据:", len(train_inout_seq), "转化为批次数据:", len(train_loader))print("通过滑动窗口共有测试集数据:", len(test_inout_seq), "转化为批次数据:", len(test_loader))print("通过滑动窗口共有验证集数据:", len(valid_inout_seq), "转化为批次数据:", len(valid_loader))print(">>>>>>>>>>>>>>>>>>>>>>>>>>>>创建数据加载器完成<<<<<<<<<<<<<<<<<<<<<<<<<<<")return train_loader, test_loader, valid_loader, scaler_train, scaler_test, scaler_validclass Chomp1d(nn.Module):def __init__(self, chomp_size):super(Chomp1d, self).__init__()self.chomp_size = chomp_sizedef forward(self, x):return x[:, :, :-self.chomp_size].contiguous()class TemporalBlock(nn.Module):def __init__(self, n_inputs, n_outputs, kernel_size, stride, dilation, padding, dropout=0.2):super(TemporalBlock, self).__init__()self.conv1 = weight_norm(nn.Conv1d(n_inputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp1 = Chomp1d(padding)self.relu1 = nn.ReLU()self.dropout1 = nn.Dropout(dropout)self.conv2 = weight_norm(nn.Conv1d(n_outputs, n_outputs, kernel_size,stride=stride, padding=padding, dilation=dilation))self.chomp2 = Chomp1d(padding)self.relu2 = nn.ReLU()self.dropout2 = nn.Dropout(dropout)self.net = nn.Sequential(self.conv1, self.chomp1, self.relu1, self.dropout1,self.conv2, self.chomp2, self.relu2, self.dropout2)self.downsample = nn.Conv1d(n_inputs, n_outputs, 1) if n_inputs != n_outputs else Noneself.relu = nn.ReLU()self.init_weights()def init_weights(self):self.conv1.weight.data.normal_(0, 0.01)self.conv2.weight.data.normal_(0, 0.01)if self.downsample is not None:self.downsample.weight.data.normal_(0, 0.01)def forward(self, x):out = self.net(x)res = x if self.downsample is None else self.downsample(x)return self.relu(out + res)class TemporalConvNet(nn.Module):def __init__(self, num_inputs, outputs, pre_len, num_channels, kernel_size=2, dropout=0.2):super(TemporalConvNet, self).__init__()layers = []self.pre_len = pre_lennum_levels = len(num_channels)for i in range(num_levels):dilation_size = 2 ** iin_channels = num_inputs if i == 0 else num_channels[i-1]out_channels = num_channels[i]layers += [TemporalBlock(in_channels, out_channels, kernel_size, stride=1, dilation=dilation_size,padding=(kernel_size-1) * dilation_size, dropout=dropout)]self.network = nn.Sequential(*layers)self.linear = nn.Linear(num_channels[-1], outputs)def forward(self, x):x = x.permute(0, 2, 1)x = self.network(x)x = x.permute(0, 2, 1)x = self.linear(x)return x[:, -self.pre_len:, :]def train(model, args, device):start_time = time.time() # 计算起始时间lstm_model = modelloss_function = nn.MSELoss()optimizer = torch.optim.Adam(lstm_model.parameters(), lr=0.005)epochs = args.epochslstm_model.train() # 训练模式results_loss = []for i in tqdm(range(epochs)):losss = []for seq, labels in train_loader:optimizer.zero_grad()lstm_model.train()optimizer.zero_grad()y_pred = lstm_model(seq)single_loss = loss_function(y_pred, labels)single_loss.backward()optimizer.step()losss.append(single_loss.detach().cpu().numpy())tqdm.write(f"\t Epoch {i + 1} / {epochs}, Loss: {sum(losss) / len(losss)}")results_loss.append(sum(losss) / len(losss))save_loss = []if save_loss:valid_loss = valid(model, args, scaler_valid, valid_loader)# 尚未引入学习率计划后期补上torch.save(lstm_model.state_dict(), 'save_model.pth')time.sleep(0.1)# 保存模型print(f">>>>>>>>>>>>>>>>>>>>>>模型已保存,用时:{(time.time() - start_time) / 60:.4f} min<<<<<<<<<<<<<<<<<<")# plot_loss_data(results_loss)test(model, args, scaler_test, test_loader)return scaler_traindef valid(model, args, scaler, valid_loader):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式losss = []for seq, labels in valid_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().numpy().cpu(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)# print("验证集误差MAE:", losss)return sum(losss)/len(losss)def test(model, args, scaler, test_loader):lstm_model = model# 加载模型进行预测lstm_model.load_state_dict(torch.load('save_model.pth'))lstm_model.eval() # 评估模式losss = []for seq, labels in test_loader:pred = lstm_model(seq)mae = calculate_mae(pred.detach().cpu().numpy(), np.array(labels.detach().cpu())) # MAE误差计算绝对值(预测值 - 真实值)losss.append(mae)# 此处缺少一个绘图功能后期补上,检验测试集情况print("测试集误差MAE:", losss)# 检验模型拟合情况
def inspect_model_fit(model, args, train_loader, scaler_train):df = pd.read_csv(args.data_path)df_inverse = df[int(0.3 * len(df)):][['OT']].reset_index(drop=True)scaler_pre = StandardScaler().fit(df_inverse)model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式results = []labels = []for i in range(len(train_loader)):for seq, label in train_loader:pred = model(seq)[:, 0, :]label = label[:, 0, :]if args.feature == 'M' or args.feature == 'S':pred = scaler_train.inverse_transform(pred.detach().cpu().numpy())label = scaler_train.inverse_transform(label.detach().cpu().numpy())else:pred = scaler_pre.inverse_transform(pred.detach().cpu().numpy())label = scaler_pre.inverse_transform(label.detach().cpu().numpy())for i in range(len(pred)):results.append(pred[i][-1])labels.append(label[i][-1])# 绘制历史数据plt.plot(labels, label='History')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(results, label='Prediction')# 添加标题和图例plt.title("inspect model fit state")plt.legend()plt.show()def predict(model, args, device, scaler):# 预测未知数据的功能df = pd.read_csv(args.data_path)scaler_data = df[[args.target]][int(0.3 * len(df)):]scaler_pre = StandardScaler().fit(scaler_data)df = df.iloc[:, 1:][-args.window_size:].values # 转换为nadarrypre_data = scaler.transform(df)tensor_pred = torch.FloatTensor(pre_data).to(device)tensor_pred = tensor_pred.unsqueeze(0) # 单次预测 , 滚动预测功能暂未开发后期补上model = modelmodel.load_state_dict(torch.load('save_model.pth'))model.eval() # 评估模式pred = model(tensor_pred)[0]if args.feature == 'M' or args.feature == 'S':pred = scaler.inverse_transform(pred.detach().cpu().numpy())else:pred = scaler_pre.inverse_transform(pred.detach().cpu().numpy())# 假设 df 和 pred 是你的历史和预测数据# 计算历史数据的长度history_length = len(df[:, -1])# 为历史数据生成x轴坐标history_x = range(history_length)# 为预测数据生成x轴坐标# 开始于历史数据的最后一个点的x坐标prediction_x = range(history_length - 1, history_length + len(pred[:, -1]) - 1)# 绘制历史数据plt.plot(history_x, df[:, -1], label='History')# 绘制预测数据# 注意这里预测数据的起始x坐标是历史数据的最后一个点的x坐标plt.plot(prediction_x, pred[:, -1], marker='o', label='Prediction')plt.axvline(history_length - 1, color='red') # 在图像的x位置处画一条红色竖线# 添加标题和图例plt.title("History and Prediction")plt.legend()if __name__ == '__main__':parser = argparse.ArgumentParser(description='Time Series forecast')parser.add_argument('-model', type=str, default='TCN', help="模型持续更新")parser.add_argument('-window_size', type=int, default=128, help="时间窗口大小, window_size > pre_len")parser.add_argument('-pre_len', type=int, default=24, help="预测未来数据长度")# dataparser.add_argument('-shuffle', action='store_true', default=True, help="是否打乱数据加载器中的数据顺序")parser.add_argument('-data_path', type=str, default='ETTh1-Test.csv', help="你的数据数据地址")parser.add_argument('-target', type=str, default='OT', help='你需要预测的特征列,这个值会最后保存在csv文件里')parser.add_argument('-input_size', type=int, default=7, help='你的特征个数不算时间那一列')parser.add_argument('-output_size', type=int, default=1, help='输出特征个数只有两种选择和你的输入特征一样即输入多少输出多少,另一种就是多元预测单元')parser.add_argument('-feature', type=str, default='MS', help='[M, S, MS],多元预测多元,单元预测单元,多元预测单元')parser.add_argument('-model_dim', type=list, default=[64, 128, 256], help='这个地方是这个TCN卷积的关键部分,它代表了TCN的层数我这里输''入list中包含三个元素那么我的TCN就是三层,这个根据你的数据复杂度来设置''层数越多对应数据越复杂但是不要超过5层')# learningparser.add_argument('-lr', type=float, default=0.001, help="学习率")parser.add_argument('-drop_out', type=float, default=0.05, help="随机丢弃概率,防止过拟合")parser.add_argument('-epochs', type=int, default=20, help="训练轮次")parser.add_argument('-batch_size', type=int, default=32, help="批次大小")parser.add_argument('-save_path', type=str, default='models')# modelparser.add_argument('-hidden_size', type=int, default=64, help="隐藏层单元数")parser.add_argument('-kernel_sizes', type=int, default=3)parser.add_argument('-laryer_num', type=int, default=1)# deviceparser.add_argument('-use_gpu', type=bool, default=False)parser.add_argument('-device', type=int, default=0, help="只设置最多支持单个gpu训练")# optionparser.add_argument('-train', type=bool, default=True)parser.add_argument('-predict', type=bool, default=True)parser.add_argument('-inspect_fit', type=bool, default=True)parser.add_argument('-lr-scheduler', type=bool, default=True)args = parser.parse_args()if isinstance(args.device, int) and args.use_gpu:device = torch.device("cuda:" + f'{args.device}')else:device = torch.device("cpu")train_loader, test_loader, valid_loader, scaler_train, scaler_test, scaler_valid = create_dataloader(args, device)# 实例化模型try:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型<<<<<<<<<<<<<<<<<<<<<<<<<<<")model = TemporalConvNet(args.input_size,args.output_size, args.pre_len,args.model_dim, args.kernel_sizes).to(device)print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型成功<<<<<<<<<<<<<<<<<<<<<<<<<<<")except:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始初始化{args.model}模型失败<<<<<<<<<<<<<<<<<<<<<<<<<<<")# 训练模型if args.train:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始{args.model}模型训练<<<<<<<<<<<<<<<<<<<<<<<<<<<")train(model, args, device)if args.inspect_fit:print(f">>>>>>>>>>>>>>>>>>>>>>>>>开始检验{args.model}模型拟合情况<<<<<<<<<<<<<<<<<<<<<<<<<<<")inspect_model_fit(model, args, train_loader, scaler_train)if args.predict:print(f">>>>>>>>>>>>>>>>>>>>>>>>>预测未来{args.pre_len}条数据<<<<<<<<<<<<<<<<<<<<<<<<<<<")predict(model, args, device, scaler_train)plt.show()
六、训练模型
我们配置好所有参数之后就可以开始训练模型了,根据我前面讲解的参数部分进行配置,不懂得可以评论区留言。
七、预测结果
7.1 预测未知数据效果图
TCN的预测效果图(这里我只预测了未来24个时间段的值为未来一天的预测值)->
7.2 测试集效果图
测试集上的表现(这个模型的测试集我还没有画图功能,如有需要请催更)->
如果补充测试集的画图功能应该如下一样。

同时我也可以将输出结果用csv文件保存,但是功能还没有做,我在另一篇informer的文章里实习了这个功能大家如果有需要可以评论区留言,有时间我会移植过来。
7.3 CSV文件生成效果图
另一篇文章链接->时间序列预测实战(十九)魔改Informer模型进行滚动长期预测(科研版本,结果可视化)
将滚动预测结果生成了csv文件方便大家对比和评估,以下是我生成的csv文件可以说是非常的直观。

我们可以利用其进行画图从而评估结果->
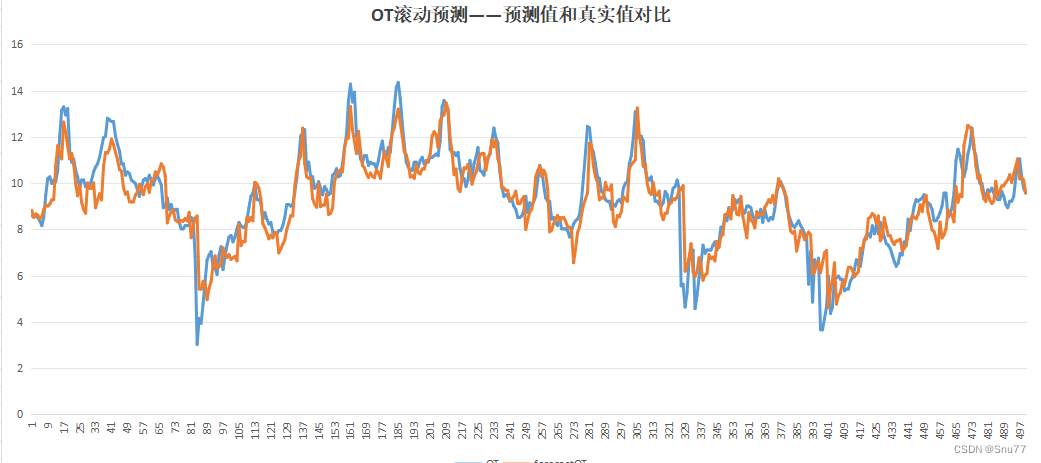
7.4 检验模型拟合效果图
检验模型拟合情况->
(从下面的图片可以看出模型拟合的情况很好)
八、全文总结
到此本文的正式分享内容就结束了,在这里给大家推荐我的时间序列专栏,本专栏目前为新开的平均质量分98分,后期我会根据各种最新的前沿顶会进行论文复现,也会对一些老的模型进行补充,目前本专栏免费阅读(暂时,大家尽早关注不迷路~),如果大家觉得本文帮助到你了,订阅本专栏,关注后续更多的更新~
专栏回顾: 时间序列预测专栏——持续复习各种顶会内容——科研必备
如果大家有不懂的也可以评论区留言一些报错什么的大家可以讨论讨论看到我也会给大家解答如何解决!最后希望大家工作顺利学业有成!