一、简介

1.Shard(分片)
数据分散集群的架构模式,Elasticsearch 将一个 Index(索引)中的数据切为多个 Shard(分片),分布在不同服务器节点上。
默认每个索引会分配5个主分片和1个副本分片,可根据需要调整主分片和副本分片的数量。
2.Replica(副本)
主从架构模式,每个Shard(分片)创建多个备份——Replica副本,保证数据不丢失。
1.主分片和副本分片数量的调整
PUT /my-index/_settings
{
"number_of_shards": 3,
"number_of_replicas": 2
}2.新建索引时设置分片
PUT /my-index
{
"settings": {
"number_of_shards": 3,
"number_of_replicas": 2
}
}
1.1、数据类型
1.1.1、常见数据类型
字符串型:text(分词)、keyword(不分词)
数值型:long、integer、short、byte、double、float、half_float、scaled_float
日期类型:date
布尔类型:boolean
二进制类型:binary
范围类型:integer_range、float_range、long_range、double_range、date_range
1.1.2、复杂数据类型
数组类型:array
对象类型:object
嵌套类型:nested object
1.1.3、特殊数据类型
地理位置数据类型:geo_point(点)、geo_shape(形状)
记录IP地址ip
实现自动补全completion
记录分词数:token_count
记录字符串hash值murmur3
多字段特性multi-fields
1.2、工作流程
1.2.1、路由
ES采用 hash 路由算法,对 document 的 id 标识进行计算,产生 shard 序号,通过序号可立即确定shard。
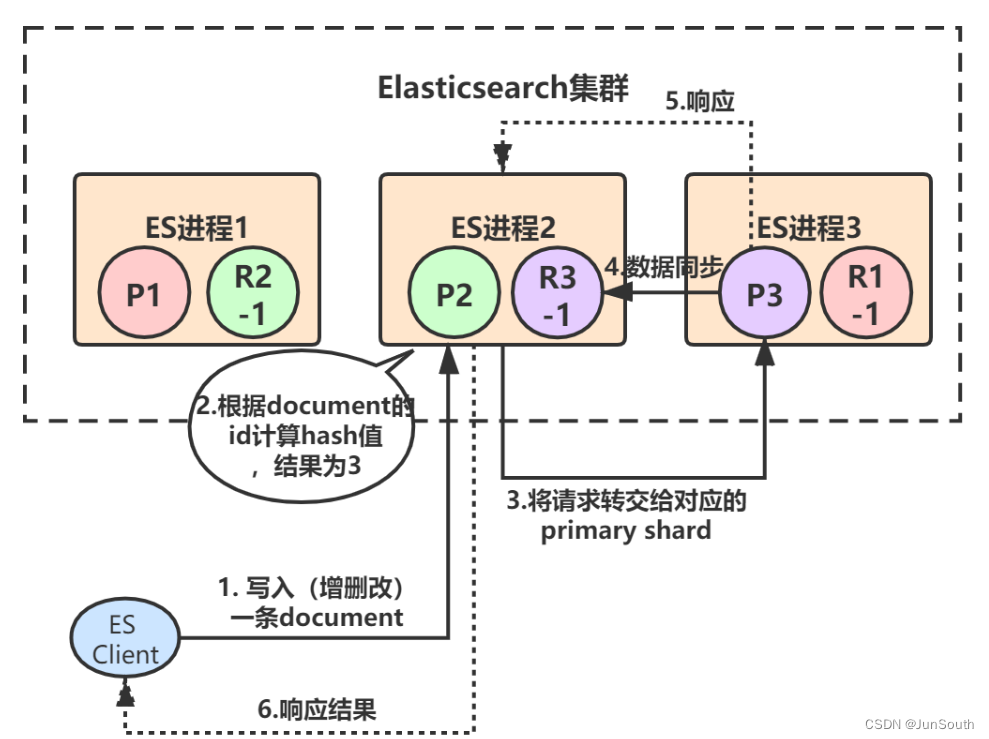
1.2.2、写入流程
1.A节点接到请求,计算路由,转发"对应节点"。
2."对应节点"处理完数据后,数据同步到副本节点。
3.A节点收到"对应节点"的响应,将结果返回给调用者。
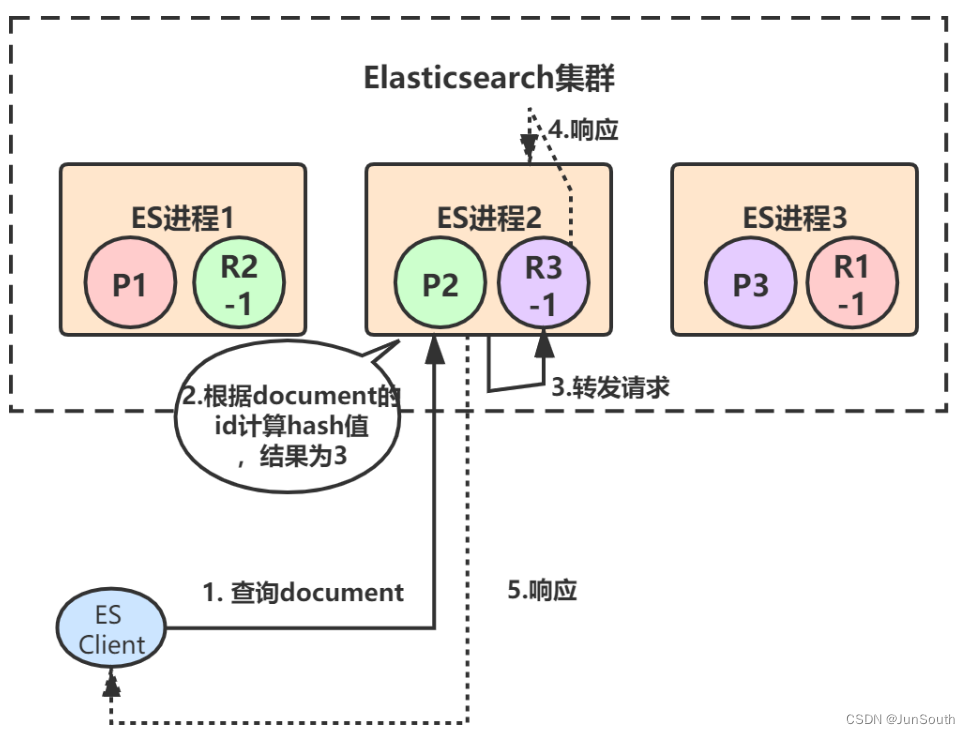
1.2.3、读取流程
1.协调节点接到请求,计算路由,用round-robin算法,在对应的primary shard及其所有replica中随机选择一个发送请求。
3.协调节点收到"对应节点"的响应,将结果返回给调用者。
二、工作原理
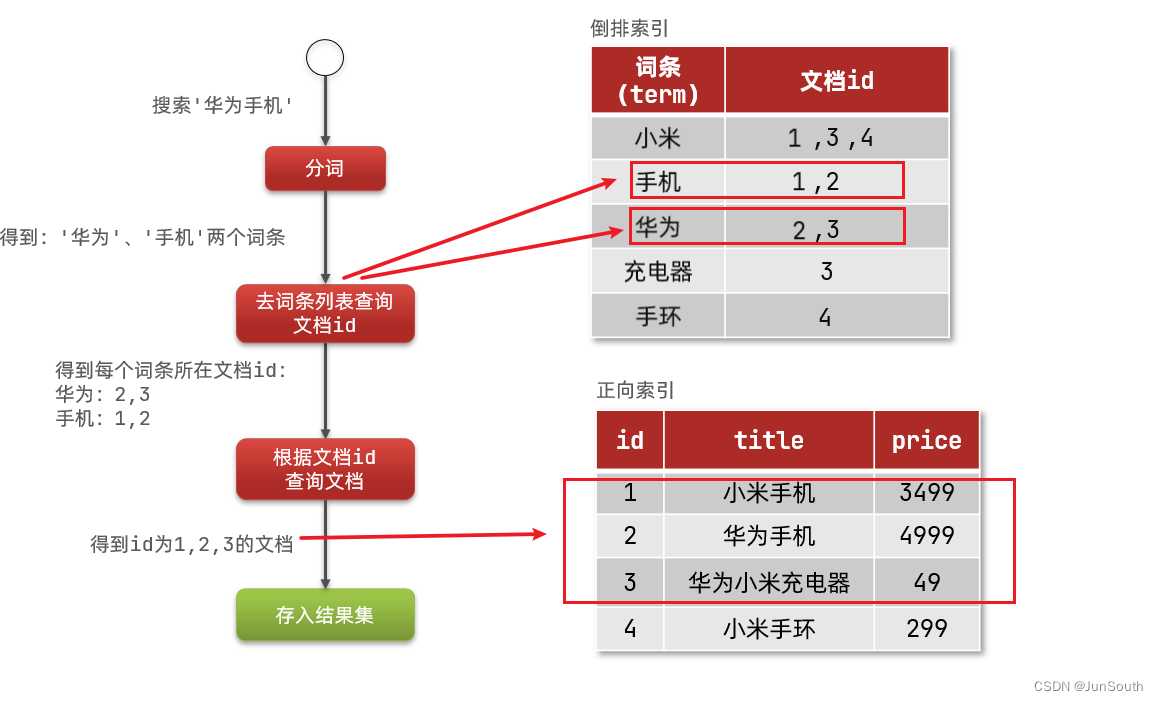
2.1、到排序索引
2.2、分词器
ES内置分词器:standard analyzer、simple analyzer、whitespace analyzer、language analyzer
对于document中的不同字段类型,ES采用不同的分词器进行处理,如date类型不会分词要完全匹配,text类型会分词。
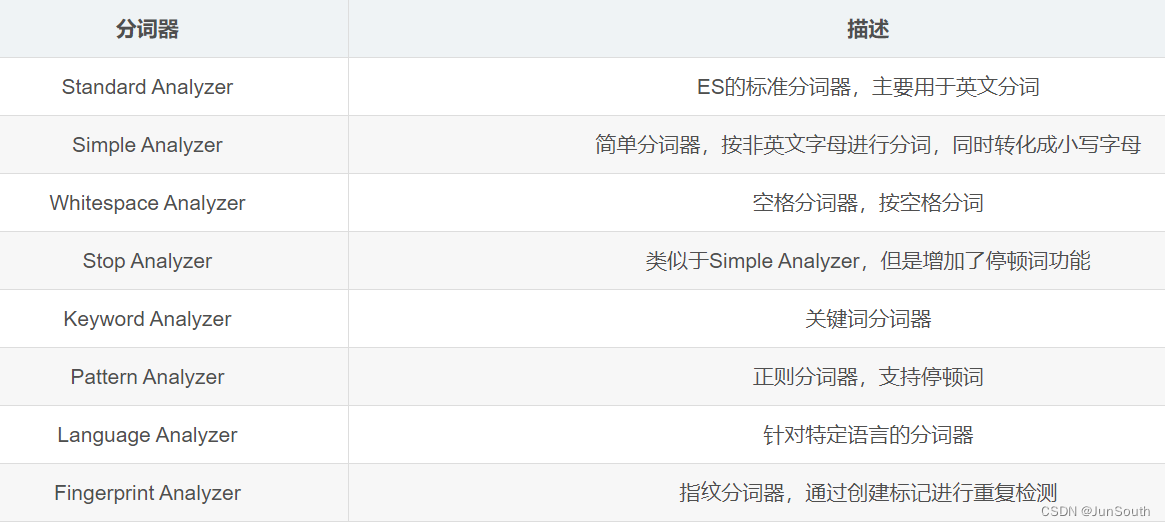
2.2.1、常用的中文分词器:IK分词器
7.6.0版本的IK:https://github.com/medcl/elasticsearch-analysis-ik/releases
解压缩放到YOUR_ES_ROOT/plugins/ik/目录下,重启Elasticsearch即可。
1、IK分词器的两种分词模式(一般用 ik_max_word)
ik_max_word:会将文本做最细粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,中华人民,中华,华人,人民共和国,人民,人,民,共和国,共和,和,国国,国歌”等等,会穷尽各种可能的组合。
ik_smart:只做最粗粒度的拆分,比如会将“中华人民共和国国歌”拆分为“中华人民共和国,国歌”。
PUT /my_index
{"mappings": {"properties": {"text": {"type": "text","analyzer": "ik_max_word"}}}
}2、配置文件
IK的配置文件存在于YOUR_ES_ROOT/plugins/ik/config目录下
main.dic: IK原生内置的中文词库,总共有27万多条,只要是这些单词,都会被分在一起;
quantifier.dic: 放了一些单位相关的词;
suffix.dic: 放了一些后缀;
surname.dic: 中国的姓氏;
stopword.dic: 英文停用词。
2.3、数据同步机制
one、all、quorum(默认),可在请求时带上consistency参数表明采用哪种模式。
one 模式
有一个primary shard是active活跃可用,操作算成功。
all 模式
必须所有的primary shard和replica shard都是活跃的,操作算成功。
quorum 模式
确保大多数shard可用,不满足条件时,会默认等1分钟,超间就报timeout错,可在写时加timeout
PUT /index/type/id?timeout=30
2.4、数据持久化策略
1.数据先写入 in-memory buffer(应用内存)中,同时写入 translog 日志文件(日志内存每5秒刷到磁盘)。
2.每隔1秒,ES会执行一次 refresh 操作:将buffer中的数据refresh到filesystem cache的(os cache系统内存)中的segment file中(可被检索到)。
3 每隔30分钟将内存数据flush到磁盘,或者translog大到一定程度时,会触发 flush 操作。
可设置index的index.translog.durability参数,使每次写入一条数据,都写入buffer,同时fsync写入磁盘上的translog文件。

三、使用
2.1、语法规则
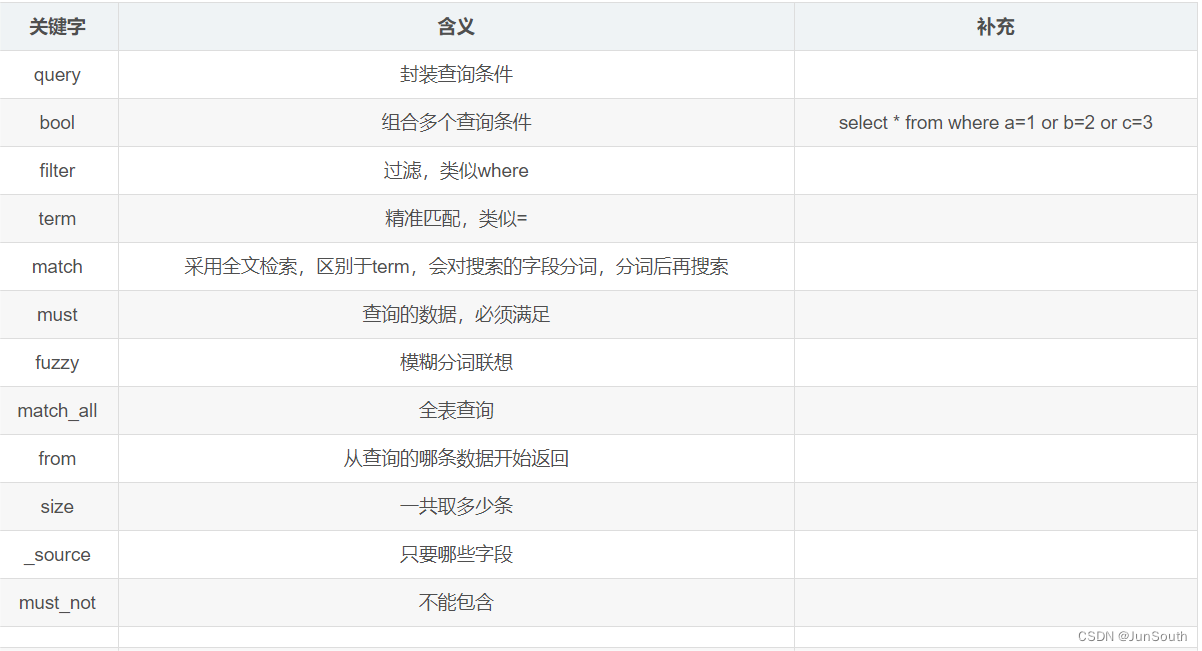
2.2、ES的 DSL 语法
1、创建索引(HTTP请求)
shopping:索引名称
# 1.创建索引(等于创建数据库,PUT请求)
http://127.0.0.1:9200/shopping# 2.获取索引(GET请求)
http://127.0.0.1:9200/shopping# 3.删除索引(DELETE请求)
http://127.0.0.1:9200/shopping2、文档数据的创建
# 1.往索引里新增数据(不自定义ID:POST,传JSON)
http://127.0.0.1:9200/shopping/_doc/# 2.往索引里新增数据(自定义ID:POST、PUT,传JSON)
http://127.0.0.1:9200/shopping/_doc/123
http://127.0.0.1:9200/shopping/_create/1233.修改
# 1.全量修改(PUT、POST)
http://127.0.0.1:9200/shopping/_doc/123
{"name":"haige","age",123
}
# 2.局部修改(POST)
http://127.0.0.1:9200/shopping/_update/123
{"doc" :{"name":"haige",}
}4、主键查询 & 全查询
# 查询主键单数据(GET)
http://127.0.0.1:9200/shopping/_doc/123
# 查询全部数据(GET)
http://127.0.0.1:9200/shopping/_search5.多条件查询,范围查询
http://127.0.0.1:9200/shopping/_search
{"query":{"bool" :{"should" :[{"match" :{"name":"测试"}}],"filter" :{"range":{"age":{"gt" : 20}}}}}
}6.分页查询、排序(且只显示name字段)
http://127.0.0.1:9200/shopping/_search
{"query":{"match":{"name":"哈喽"}},"from":0,"size":2,"_source" : ["name"],"sort" : {"age" : {"order" : "desc"}}
}2.3、org.elasticsearch.client 客户端
2.3.1、引入依赖
<dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-high-level-client</artifactId><version>7.5.0</version><exclusions><exclusion><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId></exclusion><exclusion><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId></exclusion></exclusions>
</dependency><dependency><groupId>org.elasticsearch.client</groupId><artifactId>elasticsearch-rest-client</artifactId><version>7.5.0</version>
</dependency>
<dependency><groupId>org.elasticsearch</groupId><artifactId>elasticsearch</artifactId><version>7.5.0</version>
</dependency>2.3.2、SearchRequest 、SearchSourceBuilder 、QueryBuilder 、SearchResponse 、SearchHit组件常用设置
public static void testRequest()throws Exception{// 创建请求对象,设置查询多个文档库,也可指定单个文档库。SearchRequest request = new SearchRequest("index01","index02","index03");// 也可通过 indices 方法指定文档库中request.indices("posts01","posts02", "posts03");// 设置指定查询的路由分片request.routing("routing");// 指定优先去某个分片上去查询(默认的是随机先去某个分片)request.preference("_local");// 设置缓存request.requestCache();// 取出查询语句request.toString();
}public static void testSource()throws Exception{//创建源SearchSourceBuilder source= new SearchSourceBuilder();// 第几页source.from(0);// 每页多少条数据(默认是10条)source.size(100);// 设置排序规则source.sort(new ScoreSortBuilder().order(SortOrder.DESC));source.sort(new FieldSortBuilder("id").order(SortOrder.ASC));//获取的字段(列)和不需要获取的列String[] includeFields = new String[]{"birthday","name"};String[] excludeFields = new String[]{"age","address"};source.fetchSource(includeFields,excludeFields);// 设置超时时间source.timeout(new TimeValue(60, TimeUnit.SECONDS));source.highlighter();// 高亮source.aggregation(AggregationBuilders.terms("by_company"));// 聚合//分词查询source.profile(true);source.query();
}public static void testBuilder()throws Exception{//全匹配(查出全部)MatchAllQueryBuilder matchAllQuery = QueryBuilders.matchAllQuery();//匹配查询MatchQueryBuilder matchQuery = QueryBuilders.matchQuery("","").analyzer("");//匹配文本查询MatchPhraseQueryBuilder matchPhraseQuery = QueryBuilders.matchPhraseQuery("","");//匹配文本前缀查询MatchPhrasePrefixQueryBuilder matchPhrasePrefixQuery = QueryBuilders.matchPhrasePrefixQuery("","");//判断莫子是否有值(String)ExistsQueryBuilder existsQuery = QueryBuilders.existsQuery("");//前缀查询PrefixQueryBuilder prefixQuery = QueryBuilders.prefixQuery("","");//精确查询TermQueryBuilder termQuery = QueryBuilders.termQuery("","");//范围查询RangeQueryBuilder rangeQuery = QueryBuilders.rangeQuery("birthday").from("2016-01-01 00:00:00");QueryStringQueryBuilder queryBuilder009 = QueryBuilders.queryStringQuery("");QueryBuilders.disMaxQuery();HighlightBuilder highlightBuilder = new HighlightBuilder();HighlightBuilder.Field highlightTitle =new HighlightBuilder.Field("title");highlightTitle.highlighterType("unified");highlightBuilder.field(highlightTitle);HighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");highlightBuilder.field(highlightUser);// 组合器BoolQueryBuilder builder = QueryBuilders.boolQuery();//过滤builder.filter();//且builder.must();//非builder.mustNot();//或builder.should();
}public static void testResponse()throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user");// 同步SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);RestStatus status = response.status();TimeValue took = response.getTook();Boolean terminatedEarly = response.isTerminatedEarly();boolean timedOut = response.isTimedOut();int totalShards = response.getTotalShards();int successfulShards = response.getSuccessfulShards();int failedShards = response.getFailedShards();for (ShardSearchFailure failure : response.getShardFailures()) {// failures should be handled here}// 异步ActionListener<SearchResponse> listener = new ActionListener<SearchResponse>() {@Overridepublic void onResponse(SearchResponse searchResponse) {}@Overridepublic void onFailure(Exception e) {}};client.searchAsync(searchRequest, RequestOptions.DEFAULT, listener);
}public static void testHits()throws Exception {RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user");// 同步SearchResponse response = client.search(searchRequest, RequestOptions.DEFAULT);SearchHits hits = response.getHits();TotalHits totalHits = hits.getTotalHits();//总数long numHits = totalHits.value;//TotalHits.Relation relation = totalHits.relation;float maxScore = hits.getMaxScore();SearchHit[] searchHits = hits.getHits();for (SearchHit hit : searchHits) {String index = hit.getIndex();String id = hit.getId();float score = hit.getScore();String sourceAsString = hit.getSourceAsString();Map<String, Object> sourceAsMap = hit.getSourceAsMap();String documentTitle = (String) sourceAsMap.get("title");List<Object> users = (List<Object>) sourceAsMap.get("user");Map<String, Object> innerObject =(Map<String, Object>) sourceAsMap.get("innerObject");}// 高亮获取for (SearchHit hit : response.getHits()) {Map<String, HighlightField> highlightFields = hit.getHighlightFields();HighlightField highlight = highlightFields.get("title");Text[] fragments = highlight.fragments();String fragmentString = fragments[0].string();}// 获取聚合结果Aggregations aggregations = response.getAggregations();Terms byCompanyAggregation = aggregations.get("by_company");Terms.Bucket elasticBucket = byCompanyAggregation.getBucketByKey("Elastic");Avg averageAge = elasticBucket.getAggregations().get("average_age");double avg = averageAge.getValue();// 获取大量聚合结果Map<String, Aggregation> aggregationMap = aggregations.getAsMap();Terms companyAggregation = (Terms) aggregationMap.get("by_company");List<Aggregation> aggregationList = aggregations.asList();for (Aggregation agg : aggregations) {String type = agg.getType();if (type.equals(TermsAggregationBuilder.NAME)) {Terms.Bucket elasticBucket2 = ((Terms) agg).getBucketByKey("Elastic");long numberOfDocs = elasticBucket2.getDocCount();}}
}2.3.3、 增删改
//单条增
public static void addDocment()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));//Map提供供文档源Map<String, Object> jsonMap = new HashMap<>();jsonMap.put("name", "小红");jsonMap.put("sex", "女");jsonMap.put("age", 22);jsonMap.put("birthDay", new Date());jsonMap.put("message", "测试");IndexRequest indexRequest1 = new IndexRequest("user2", "doc", "5").source(jsonMap);// 同步执行IndexResponse indexResponse1 =client.index(indexRequest1,RequestOptions.DEFAULT);client.close();//XContentBuilder提供供文档源XContentBuilder builder = XContentFactory.jsonBuilder();builder.startObject();{builder.field("name", "South");builder.timeField("birthDay", new Date());builder.field("message", "第二个小demo");}builder.endObject();IndexRequest indexRequest2 = new IndexRequest("user", "doc", "2").source(builder);// 同步执行IndexResponse indexResponse2 =client.index(indexRequest2,RequestOptions.DEFAULT);String index = indexResponse1.getIndex();String type = indexResponse1.getType();String id = indexResponse1.getId();long version = indexResponse1.getVersion();RestStatus restStatus = indexResponse1.status();DocWriteResponse.Result result = indexResponse1.getResult();ReplicationResponse.ShardInfo shardInfo = indexResponse1.getShardInfo();client.close();
}//删
public void deleteTest()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));DeleteRequest request = new DeleteRequest("posts","1");DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
}//单个改
public static void updateDocment()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));Map<String, Object> jsonMap = new HashMap<>();jsonMap.put("name", "JunSouth");UpdateRequest updateRequest = new UpdateRequest("user","doc","6").doc(jsonMap);UpdateResponse updateResponse =client.update(updateRequest,RequestOptions.DEFAULT);String index = updateResponse.getIndex();String type = updateResponse.getType();String id = updateResponse.getId();long version = updateResponse.getVersion();System.out.println("index:"+index+" type:"+type+" id:"+id+" version:"+version);if(updateResponse.getResult() == DocWriteResponse.Result.CREATED) {System.out.println("文档已创建");}else if(updateResponse.getResult() == DocWriteResponse.Result.UPDATED) {System.out.println("文档已更新");}else if(updateResponse.getResult() == DocWriteResponse.Result.DELETED) {System.out.println("文档已删除");}else if(updateResponse.getResult() == DocWriteResponse.Result.NOOP) {System.out.println("文档不受更新的影响");}client.close();
}//批量操作
public static void bulkDocment()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));BulkRequest bulkRequest = new BulkRequest();bulkRequest.add(new IndexRequest("user","doc","5").source(XContentType.JSON,"name", "test")); // 将第一个 IndexRequest 添加到批量请求中bulkRequest.add(new IndexRequest("user","doc","6").source(XContentType.JSON,"name","test")); // 第二个BulkResponse bulkResponse = client.bulk(bulkRequest,RequestOptions.DEFAULT);boolean falgs = bulkResponse.hasFailures(); // true 表示至少有一个操作失败System.out.println("falgs: "+falgs);for (BulkItemResponse bulkItemResponse : bulkResponse) { // 遍历所有的操作结果DocWriteResponse itemResponse = bulkItemResponse.getResponse(); // 获取操作结果的响应,可以是 IndexResponse,UpdateResponse or DeleteResponse,它们都可以惭怍是 DocWriteResponse 实例。if (bulkItemResponse.getOpType() == DocWriteRequest.OpType.INDEX || bulkItemResponse.getOpType() == DocWriteRequest.OpType.CREATE) {IndexResponse indexResponse = (IndexResponse) itemResponse;System.out.println("index 操作后的响应结果");}else if(bulkItemResponse.getOpType() == DocWriteRequest.OpType.UPDATE) {UpdateResponse updateResponse = (UpdateResponse) itemResponse;System.out.println("update 操作后的响应结果");}else if(bulkItemResponse.getOpType() == DocWriteRequest.OpType.DELETE) {DeleteResponse deleteResponse = (DeleteResponse) itemResponse;System.out.println("delete 操作后的响应结果");}}for (BulkItemResponse bulkItemResponse : bulkResponse) {if (bulkItemResponse.isFailed()) { // 检测给定的操作是否失败BulkItemResponse.Failure failure = bulkItemResponse.getFailure();System.out.println("获取失败信息: "+failure);}}client.close();
}2.3.4、查
//查询某索引下全部数据
public static void searchAll()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user"); // 设置搜索的 index 。QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(queryBuilder); //设置搜索,可以是任何类型的 QueryBuilder.searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();float maxScore = hits.getMaxScore();for (SearchHit hit : hits.getHits()) {System.out.println("hit: "+hit);String sourceAsString = hit.getSourceAsString();Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");System.out.println("name: "+name);}client.close();//匹配查询器QueryBuilder matchQueryBuilder = QueryBuilders.matchQuery("user", "kimchy").fuzziness(Fuzziness.AUTO).prefixLength(3).maxExpansions(10);searchSourceBuilder.query(matchQueryBuilder);//高亮HighlightBuilder highlightBuilder = new HighlightBuilder();HighlightBuilder.Field highlightTitle = new HighlightBuilder.Field("name"); // title 字段高亮highlightTitle.highlighterType("unified"); // 配置高亮类型highlightBuilder.field(highlightTitle); // 添加到 builderHighlightBuilder.Field highlightUser = new HighlightBuilder.Field("user");highlightBuilder.field(highlightUser);searchSourceBuilder.highlighter(highlightBuilder);
}//普通条件查询
public static void search01()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user"); // 设置搜索的 index 。// 查询器QueryBuilder queryBuilder01 = QueryBuilders.termQuery("name", "test"); //完全匹配QueryBuilder queryBuilder02 =QueryBuilders.fuzzyQuery("name", "t"); //模糊查询QueryBuilder queryBuilder03 =QueryBuilders.prefixQuery("name", "小"); //前缀查询QueryBuilder queryBuilder04 =QueryBuilders.matchQuery("name", "小"); //匹配查询WildcardQueryBuilder queryBuilder = QueryBuilders.wildcardQuery("name","*jack*");//搜索名字中含有jack文档(name中只要包含jack即可)// 搜索器(排序、分页...)。SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(queryBuilder04); // 设置搜索条件searchSourceBuilder.from(0); // 起始 indexsearchSourceBuilder.size(5); // 大小 size// searchSourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS)); // 设置搜索的超时时间// searchSourceBuilder.sort(new ScoreSortBuilder().order(SortOrder.DESC)); // 根据分数 _score 降序排列 (默认行为)// searchSourceBuilder.sort(new FieldSortBuilder("_uid").order(SortOrder.ASC)); // 根据 id 降序排列searchRequest.source(searchSourceBuilder); // 将 SearchSourceBuilder 添加到 SeachRequest 中。SearchResponse searchResponse = client.search(searchRequest,RequestOptions.DEFAULT);SearchHits hits = searchResponse.getHits();float maxScore = hits.getMaxScore();for (SearchHit hit : hits.getHits()) {String sourceAsString = hit.getSourceAsString();Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");System.out.println("hit: "+hit);System.out.println("name: "+name);}client.close();
}// 聚合查询
public static void search02()throws Exception{RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user2");SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();// 根据 sex 字段分组TermsAggregationBuilder aggregation = AggregationBuilders.terms("my_sex").field("sex.keyword");aggregation.subAggregation(AggregationBuilders.avg("avg_age").field("age")); // age(统计的字段)需是数值型aggregation.subAggregation(AggregationBuilders.max("max_age").field("age"));aggregation.subAggregation(AggregationBuilders.min("min_age").field("age"));searchSourceBuilder.aggregation(aggregation);searchRequest.source(searchSourceBuilder);SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);Aggregations aggregations = searchResponse.getAggregations();Terms sexTerms = aggregations.get("my_sex");//获取每组的信息for (Terms.Bucket bucket : sexTerms.getBuckets()) {System.out.println("分组的字段名: " + bucket.getKeyAsString());System.out.println("每组数量: " + bucket.getDocCount());}//求平均Terms.Bucket elasticBucket1 = sexTerms.getBucketByKey("女");Avg averageAge1 = elasticBucket1.getAggregations().get("avg_age");double avg1 = averageAge1.getValue();System.out.println("女性平均年龄:"+avg1);Terms.Bucket elasticBucket2 = sexTerms.getBucketByKey("男");Avg averageAge2 = elasticBucket2.getAggregations().get("avg_age");double avg2 = averageAge2.getValue();System.out.println("男性平均年龄:"+avg2);//求最大最小Terms.Bucket elasticBucket3 = sexTerms.getBucketByKey("女");Max maxAge3 = elasticBucket3.getAggregations().get("max_age");double maxAge = maxAge3.getValue();System.out.println("女性最大年龄:"+maxAge);Terms.Bucket elasticBucket4 = sexTerms.getBucketByKey("女");Min maxAge4 = elasticBucket4.getAggregations().get("min_age");double minAge = maxAge4.getValue();System.out.println("女性最大年龄:"+minAge);client.close();
}// 多查询
public static void multiSearch()throws Exception{MultiSearchRequest multiSearchRequest = new MultiSearchRequest(); // 查两个张索引SearchRequest firstSearchRequest = new SearchRequest("user"); SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("name", "大黑"));firstSearchRequest.source(searchSourceBuilder);multiSearchRequest.add(firstSearchRequest);SearchRequest secondSearchRequest = new SearchRequest("car"); searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(QueryBuilders.matchQuery("weight", "3T"));secondSearchRequest.source(searchSourceBuilder);multiSearchRequest.add(secondSearchRequest);// 取值1MultiSearchResponse multiSearchResponse = client.msearch(multiSearchRequest,RequestOptions.DEFAULT);MultiSearchResponse.Item firstResponse = multiSearchResponse.getResponses()[0]; SearchResponse firstSearchResponse = firstResponse.getResponse(); for (SearchHit hit : firstSearchResponse.getHits()) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");}MultiSearchResponse.Item secondResponse = response.getResponses()[1]; SearchResponse secondSearchResponse = secondResponse.getResponse();for (SearchHit hit : secondSearchResponse.getHits()) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("weight");}// 取值2for (MultiSearchResponse.Item item : multiSearchResponse.getResponses()) {SearchResponse response = item.getResponse();for (SearchHit hit : response.getHits()) {String index=hit.getIndex();//根据不同索引名作不同的处理。if(index.equals("user")){Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("name");}else if(index.equals("car")){Map<String, Object> sourceAsMap = hit.getSourceAsMap();String name = (String) sourceAsMap.get("weight");}}}//滚动查询
public static void scrollSerach()throws Exception{System.out.print("11111111111111111");RestHighLevelClient client = new RestHighLevelClient(RestClient.builder(new HttpHost("127.0.0.1", 9200, "http")));SearchRequest searchRequest = new SearchRequest("user"); // 设置搜索的 index 。QueryBuilder queryBuilder = QueryBuilders.matchAllQuery();SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();searchSourceBuilder.query(queryBuilder); //设置搜索,可以是任何类型的 QueryBuilder.//设置每次查询数量searchSourceBuilder.size(3);//设置滚动等待时间final Scroll scroll = new Scroll(TimeValue.timeValueMinutes(1));searchRequest.scroll(scroll);searchRequest.source(searchSourceBuilder);//第一次获取查询结果SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);String scrollId = searchResponse.getScrollId();SearchHit[] searchHits = searchResponse.getHits().getHits();for (SearchHit hit : searchHits) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();System.out.print("第一次获取查询结果,此处可做一些操作。");String name = (String) sourceAsMap.get("name");System.out.println("name: "+name);}//遍历剩余结果while (searchHits != null && searchHits.length > 0) {SearchScrollRequest scrollRequest = new SearchScrollRequest(scrollId);scrollRequest.scroll(scroll);searchResponse = client.scroll(scrollRequest, RequestOptions.DEFAULT);scrollId = searchResponse.getScrollId();searchHits = searchResponse.getHits().getHits();for (SearchHit hit : searchHits) {Map<String, Object> sourceAsMap = hit.getSourceAsMap();System.out.print("遍历剩余结果,此处可做一些操作。");String name = (String) sourceAsMap.get("name");System.out.println("name: "+name);}}// 清除游标ClearScrollRequest clearScrollRequest = new ClearScrollRequest();clearScrollRequest.addScrollId(scrollId);ClearScrollResponse clearScrollResponse = client.clearScroll(clearScrollRequest, RequestOptions.DEFAULT);boolean succeeded = clearScrollResponse.isSucceeded();client.close();}
}四、性能调优
4.1、生产部署
1.ES对于CPU的要求比较低,对内存磁盘要求较高。一般64G内存,8~16核CPU,SSD固态硬盘即可。
2.ES内存主要两部分—os cache、jvm heap,ES官方建议,ES默认jvm heap分配2G内存,可通过jvm.options配置文件设置。50%内存给jvm heap,50%的内存给os cache。os cache的内存会被Lucene用光,来缓存segment file。
3.不对任何分词field聚合操作,就不使用fielddata(用jvm heap),可给os cache更多内存。更多的内存留给了lucene用os cache提升索引读写性能。
4.给ES的heap内存最好不要超过32G,当heap内存小于32G时,JVM才会用一种compressed oops技术来压缩对象指针(object pointer),解决object pointer耗费过大空间的问题。
5.禁止swapping,因为swapping会导致GC过程从毫秒级变成分钟级,在GC的时候需要将内存从磁盘swapping到内存里,特别耗时,这会导致es节点响应请求变得很慢,甚至导致ES node跟cluster失联。
4.1.2、ES目录

ES升级时,目录会被覆盖掉,导致之前plugin、log、data、config信息丢失,可通过elasticsearch.yml改变目录位置:
path.logs: /var/log/elasticsearch
path.data: /var/data/elasticsearch
path.plugins: /var/plugin/elasticsearch
4.2、写入优化
1.bulk批量写入
尽量采用bulk方式,每次批量写个几百条。2.多线程写入
用多线程并发的将数据bulk写入集群中,可减少每次磁盘fsync的次数和开销。3.增加refresh间隔
默认的refresh间隔是1s,可调大index.refresh_interval参数至30s,每隔30s才会创建一个segment file。4.禁止refresh和replia
如果要一次加载大批量的数据进ES,可先禁止refresh和replia复制,
将index.refresh_interval设为-1,将index.number_of_replicas设为0,此时就没refresh和replica机制了,写入速度会非常快。5.减少副本数量
ES默认副本为3个,这样提高集群的可用性,增加搜索的并发数,也会影响写入索引的效率。5.禁止swapping
将swapping内存页交换禁止,因为swapping会导致大量磁盘IO,性能很差。6.增加filesystem cache大小
filesystem cache被用来执行更多的IO操作,给filesystem cache更多内存,ES的写入性能会好很多。7.使用自动生成的id
如果手动给es document设置一个id,es每次都去确认id是否存在。用自动生成的id,那es就可跳过这个步骤,写入性能会更好。8.提升硬件
给filesystem cache更多的内存、用SSD替代机械硬盘、避免用NAS等网络存储、用RAID 0来提升磁盘并行读写效率等。9.索引缓冲 index buffer
写入并发量高,可通过indices.memory.index_buffer_size参数,将index buffer调大一些。10.尽量避免用 nested、parent/child 的字段
nested query 慢,parent/child query 更慢。在 mapping 设计阶段用大宽表设计或用比较 smart 的数据结构。
4.3、查询优化

1.慢查询日志
elasticsearch.yml中,可通过设置参数配置慢查询阈值:
PUT /_template/{TEMPLATE_NAME}
{
"template":"{INDEX_PATTERN}",
"settings" : {
"index.indexing.slowlog.level": "INFO",
"index.indexing.slowlog.threshold.index.warn": "10s",
"index.indexing.slowlog.threshold.index.info": "5s",
"index.indexing.slowlog.threshold.index.debug": "2s",
"index.indexing.slowlog.threshold.index.trace": "500ms",
"index.indexing.slowlog.source": "1000",
"index.search.slowlog.level": "INFO",
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
},
"version" : 1
}
PUT {INDEX_PAATERN}/_settings
{
"index.indexing.slowlog.level": "INFO",
"index.indexing.slowlog.threshold.index.warn": "10s",
"index.indexing.slowlog.threshold.index.info": "5s",
"index.indexing.slowlog.threshold.index.debug": "2s",
"index.indexing.slowlog.threshold.index.trace": "500ms",
"index.indexing.slowlog.source": "1000",
"index.search.slowlog.level": "INFO",
"index.search.slowlog.threshold.query.warn": "10s",
"index.search.slowlog.threshold.query.info": "5s",
"index.search.slowlog.threshold.query.debug": "2s",
"index.search.slowlog.threshold.query.trace": "500ms",
"index.search.slowlog.threshold.fetch.warn": "1s",
"index.search.slowlog.threshold.fetch.info": "800ms",
"index.search.slowlog.threshold.fetch.debug": "500ms",
"index.search.slowlog.threshold.fetch.trace": "200ms"
}
在日志目录下的慢查询日志
{CLUSTER_NAME}_index_indexing_slowlog.log
{CLUSTER_NAME}_index_search_slowlog.log
2.all、_source 字段的使用
_all 字段包含了所有的索引字段,便做全文检索,无需求,可禁用;
_source 存储原始的 document 内容,可设置 includes、excludes 属性来定义放入 _source 的字段。3.合理的配置使用 index 属性
index 属性:analyzed、not_analyzed,根据业务需求来控制字段是否分词或不分词。4.用过滤器(Filter)替代查询(Query)
Query:查询会计算相关性分数
Filter:查询只做匹配「是」或「否」,结果可以缓存。5.不要返回过大的结果集
6.避免超大的document
7.避免稀疏数据
Lucene的内核结构,跟稠密的数据配合起来性能会更好。
每个document的field为空过多,就是稀疏数据。
4.4、分页

4.4.1、from + size:普通分页
1.每个分片会查询打分排名在前面的 from+size 条数据。
2.协同节点收集每个分配的前 from+size 条数据(n*(from+size)),在总的n*(from+size)数据中排序,将其中 from 到 from+size 的数据返给客户。
优化:若文档 id 有序,以文档 id 作为分页的偏移量,先把id查出,在id结果集里取出数据。
4.4.2、滚动翻页(Search Scroll):
游标滚动式查询
4.4.3、流式翻页(Search After 仅支持向后翻页)
用上页中的一组排序值检索下页数据,搜索的查询和排序参数须保持不变。
PIT(Point In Time):存储索引数据状态的轻量级视图。
1.获取索引的pit
2.根据pit首次查询
3.根据search_after和pit进行翻页查询





![[二分查找]LeetCode2009 :使数组连续的最少操作数](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)