【大家好,我是爱干饭的猿,本文重点介绍Spark的定义、发展、扩展阅读:Spark VS Hadoop、四大特点、框架模块、运行模式、架构角色。
后续会继续分享其他重要知识点总结,如果喜欢这篇文章,点个赞👍,关注一下吧】
上一篇文章:《【YOLOv5入门】目标检测》
1. Spark 框架概述
1.1 Spark 是什么
定义:Apache Spark是用于大规模数据(large-scala data)处理的统一(unified)分析引擎。
Spark 最早源于一篇论文 Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing,该论文是由加州大学柏克莱分校的 Matei Zaharia 等人发表的。论文中提出了一种弹性分布式数据集(即 RDD)的概念。
翻译过来就是:RDD 是一种分布式内存抽象,其使得程序员能够在大规模集群中做内存运算,并且有一定的容错方式。而这也是整个 Spark 的核心数据结构,Spark 整个平台都围绕着RDD进行。

简而言之,Spark 借鉴了 MapReduce 思想发展而来,保留了其分布式并行计算的优点并改进了其明显的缺陷。让中间数据存储在内存中提高了运行速度、并提供丰富的操作数据的API提高了开发速度。
为什么是统一分析引擎?
Spark是一款分布式内存计算的统一分析引擎。
其特点就是对任意类型的数据进行自定义计算。
Spark可以计算:结构化、半结构化、非结构化等各种类型的数据结构,同时也支持使用Python、Java、Scala、R以及SQL语言去开发应用
程序计算数据。
Spark的适用面非常广泛,所以,被称之为 统一的(适用面广)的分析引擎(数据处理)
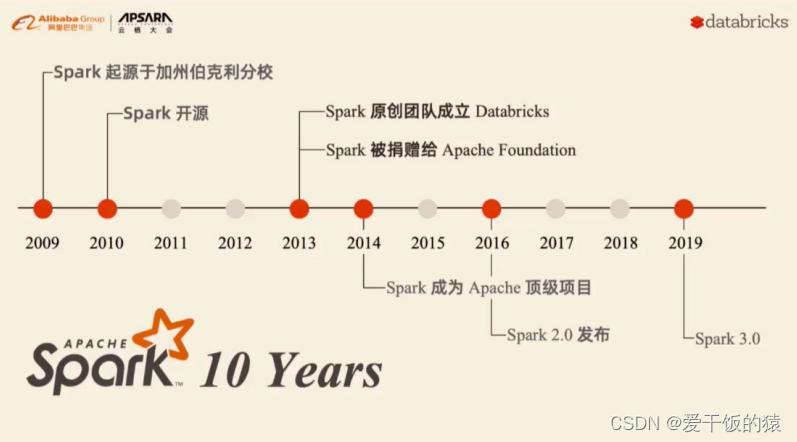
1.2 Spark风雨十年
Spark 是加州大学伯克利分校AMP实验室(Algorithms Machines and People Lab)开发的通用大数据处理框架。
Spark的发展历史,经历过几大重要阶段,如下图所示:
1.3 扩展阅读:Spark VS Hadoop
Spark和前面学习的Hadoop技术栈有何区别呢?

尽管Spark相对于Hadoop而言具有较大优势,但Spark并不能完全替代Hadoop
- 在计算层面,Spark相比较MR(MapReduce)有巨大的性能优势,但至今仍有许多计算工具基于MR构架,比如非常成熟的Hive
- Spark仅做计算,而Hadoop生态圈不仅有计算(MR)也有存储(HDFS)和资源管理调度(YARN),HDFS和YARN仍是许多大数据体系的核心架构。
面试题:Hadoop的基于进程的计算和Spark基于线程方式优缺点?
答案:Hadoop中的MR中每个map/reduce task都是一个java进程方式运行,好处在于进程之间是互相独立的,每个task独享进程资源,没有互相干扰,监控方便,但是问题在于task之间不方便共享数据,执行效率比较低。比如多个map task读取不同数据源文件需要将数据源加
载到每个map task中,造成重复加载和浪费内存。而基于线程的方式计算是为了数据共享和提高执行效率,Spark采用了线程的最小的执行单位,但缺点是线程之间会有资源竞争。
1.4 Spark 四大特点
1. 速度快
由于Apache Spark支持内存计算,并且通过DAG(有向无环图)执行引擎支持无环数据流,所以官方宣称其在内存中的运算速度要比Hadoop的MapReduce快100倍,在硬盘中要快10倍。
Spark处理数据与MapReduce处理数据相比,有如下两个不同点:
- 其一、Spark处理数据时,可以将中间处理结果数据存储到内存中;
- 其二、Spark 提供了非常丰富的算子(API), 可以做到复杂任务在一个Spark 程序中完成.
2. 易于使用
Spark 的版本已经更新到 Spark 3.2.0(截止日期2021.10.13),支持了包括 Java、Scala、Python 、R和SQL语言在内的多种语言。为了兼容Spark2.x企业级应用场景,Spark仍然持续更新Spark2版本。
3. 通用性强
在 Spark 的基础上,Spark 还提供了包括Spark SQL、Spark Streaming、MLib 及GraphX在内的多个工具库,我们可以在一个应用中无缝地使用这些工具库。

4. 运行方式
Spark 支持多种运行方式,包括在 Hadoop 和 Mesos 上,也支持 Standalone的独立运行模式,同时也可以运行在云Kubernetes(Spark 2.3开始支持)上。
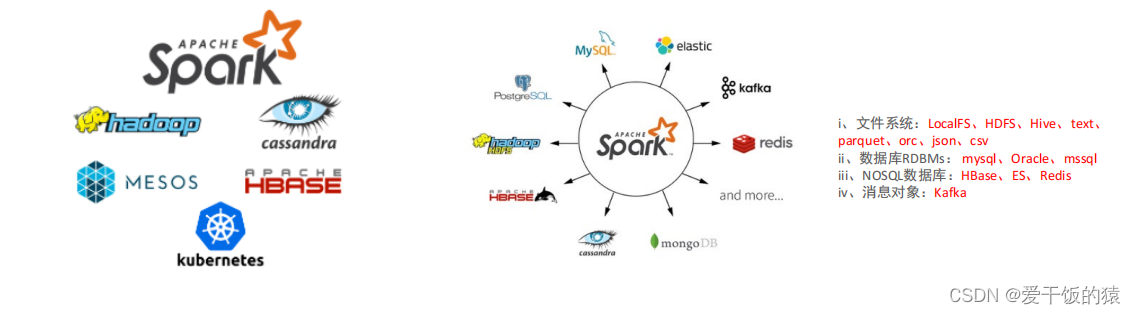
对于数据源而言,Spark 支持从HDFS、HBase、Cassandra 及 Kafka 等多种途径获取数据。
1.5 Spark 框架模块-了解
整个Spark 框架模块包含:Spark Core、 Spark SQL、 Spark Streaming、 Spark GraphX、 Spark MLlib,而后四项的能力都是建立在核心引擎之上
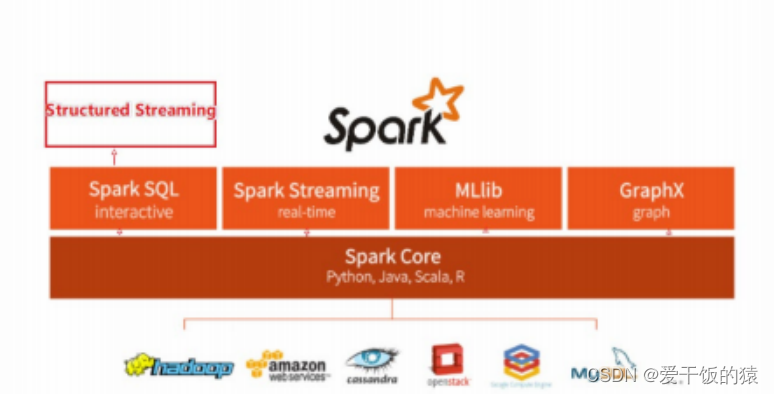
- Spark Core:Spark的核心,Spark核心功能均由Spark Core模块提供,是Spark运行的基础。Spark Core以RDD为数据抽象,提供Python、Java、Scala、R语言的API,可以编程进行海量离线数据批处理计算。
- SparkSQL:基于SparkCore之上,提供结构化数据的处理模块。SparkSQL支持以SQL语言对数据进行处理,SparkSQL本身针对离线计算场景。同时基于SparkSQL,Spark提供了StructuredStreaming模块,可以以SparkSQL为基础,进行数据的流式计算。
- SparkStreaming:以SparkCore为基础,提供数据的流式计算功能。
- MLlib:以SparkCore为基础,进行机器学习计算,内置了大量的机器学习库和API算法等。方便用户以分布式计算的模式进行机器学习计算。
- GraphX:以SparkCore为基础,进行图计算,提供了大量的图计算API,方便用于以分布式计算模式进行图计算。
1.6 Spark 运行模式
Spark提供多种运行模式,包括:
- 本地模式(单机)
本地模式就是以一个独立的进程,通过其内部的多个线程来模拟整个Spark运行时环境 - Standalone模式(集群)
Spark中的各个角色以独立进程的形式存在,并组成Spark集群环境 - Hadoop YARN模式(集群)
Spark中的各个角色运行在YARN的容器内部,并组成Spark集群环境 - Kubernetes模式(容器集群)
Spark中的各个角色运行在Kubernetes的容器内部,并组成Spark集群环境 - 云服务模式(运行在云平台上)
1.7 Spark 架构角色
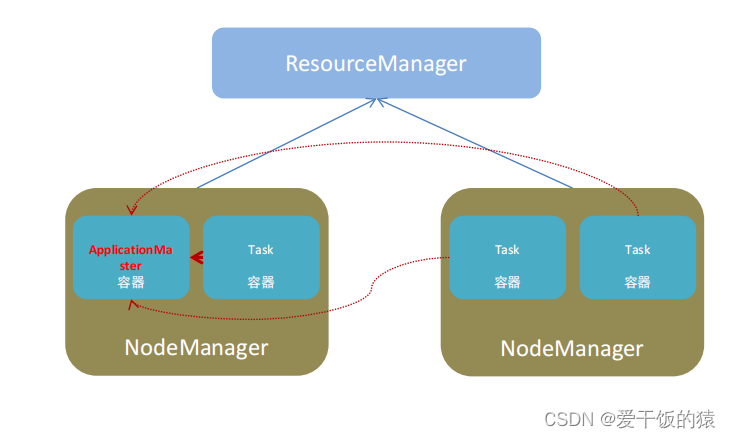
1. YARN角色回顾
YARN主要有4类角色,从2个层面去看:
- 资源管理层面
- 集群资源管理者(Master):ResourceManager
- 单机资源管理者(Worker):NodeManager
- 任务计算层面
- 单任务管理者(Master):ApplicationMaster
- 单任务执行者(Worker):Task(容器内计算框
架的工作角色)
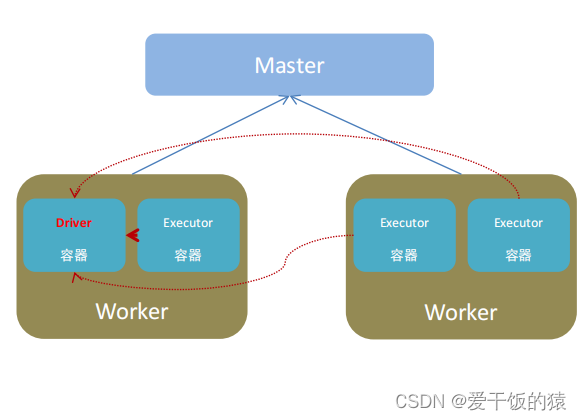
2. Spark运行角色
Spark中由4类角色组成整个Spark的运行时环境
- Master角色,管理整个集群的资源 - 类比与YARN的ResouceManager
- Worker角色,管理单个服务器的资源 - 类比于YARN的NodeManager
- Driver角色,管理单个Spark任务在运行的时候的工作 - 类比于YARN的ApplicationMaster
- Executor角色,单个任务运行的时候的一堆工作者,干活的 - 类比于YARN的容器内运行的TASK
从2个层面划分:
- 资源管理层面:
- 管理者: Spark是Master角色,YARN是ResourceManager
- 工作中: Spark是Worker角色,YARN是NodeManager
- 从任务执行层面:
- 某任务管理者: Spark是Driver角色,YARN是ApplicationMaster
- 某任务执行者: Spark是Executor角色,YARN是容器中运行的具体工作进程。