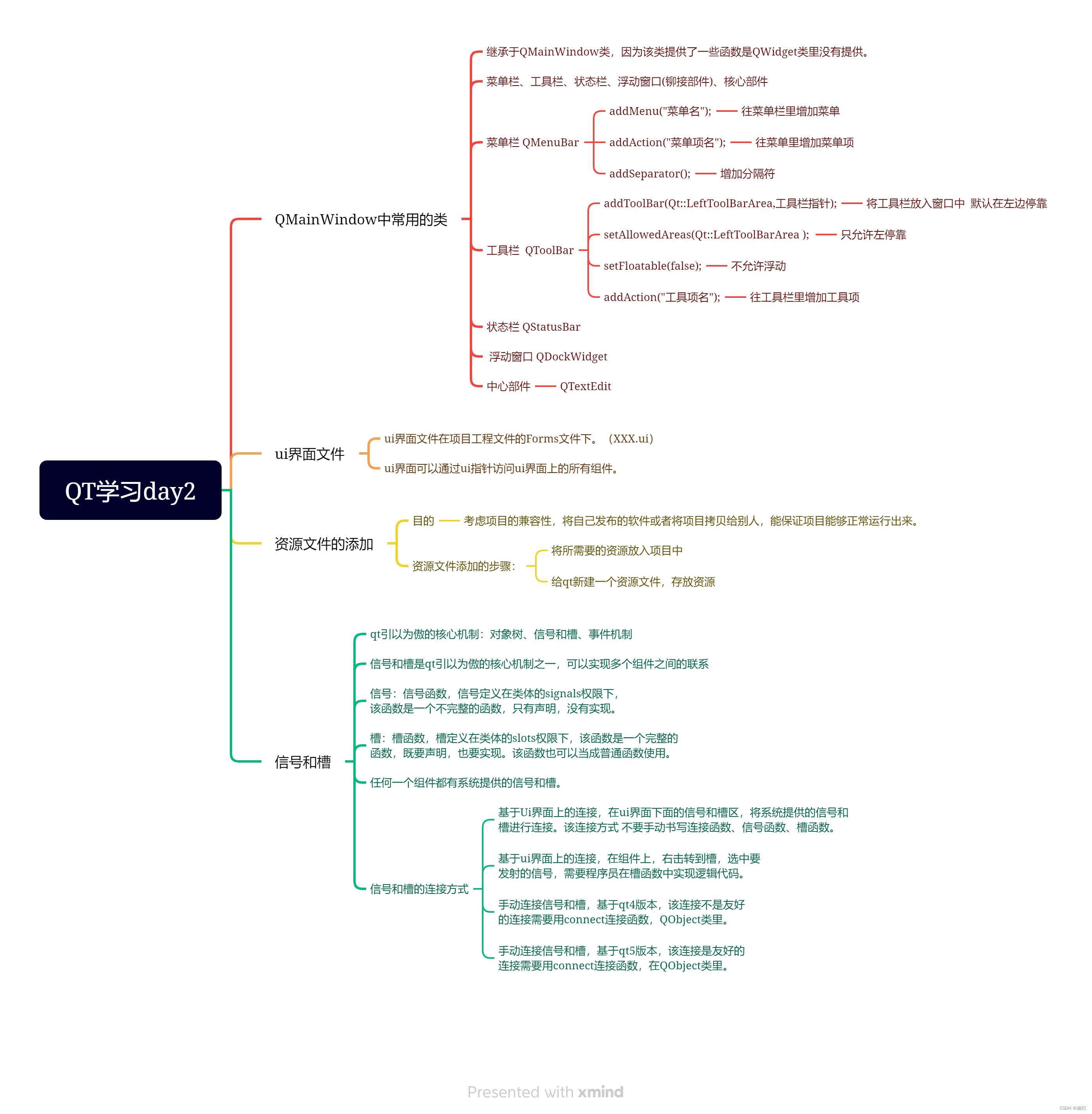
Learning Memory-guided Normality for Anomaly Detection
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
- 3.1网络架构
- 3.1.1 Encoder and decoder
- 3.1.2 Memory
- 3.2. Training loss
- 3.3. Abnormality score
- 4.实验
- 5.总结
- 总结&代码复现:
文章信息:

发表于:cvpr2020
原文:https://arxiv.org/abs/2003.13228
代码:https://github.com/cvlab-yonsei/MNAD
摘要
我们致力于解决异常检测的问题,即在视频序列中检测异常事件。基于卷积神经网络(CNNs)的异常检测方法通常利用代理任务,比如重建输入视频帧,以在训练时学习描述正常情况的模型,而不在训练时接触异常样本,并在测试时利用重建误差来量化异常的程度。这些方法的主要缺点是它们未明确考虑正常模式的多样性,而CNNs强大的表示能力允许其重建异常视频帧。为了解决这个问题,我们提出了一种无监督学习方法来进行异常检测,明确考虑了正常模式的多样性,同时减小了CNNs的表示能力。为此,我们建议使用一个具有新的更新方案的memory module,其中memory module中的项目记录正常数据的典型模式。我们还提出了新颖的特征紧凑性和分离性损失来训练memory module,增强了memory module项目和从正常数据中深度学习特征的判别能力。在标准基准测试上的实验结果表明,我们的方法的效果和效率是显著的,优于当前领域的最新技术。
1.介绍
针对视频序列中异常事件的无监督学习方法,并探讨了现有方法的挑战和局限性。主要观点和贡献如下:
挑战与现有方法的局限性:
- 异常事件的定义在不同情境下有所不同,手动标注异常事件是一项耗时的任务。
- 收集异常数据集需要大量努力,因为在真实场景中很少发生异常事件。
- 基于卷积神经网络(CNNs)的方法利用代理任务进行异常检测,如重建输入帧或预测未来帧,但这些方法并不直接检测异常。
提出的方法:
- 引入了一个无监督学习方法,考虑正常模式的多样性,假设单一的典型特征无法表示正常数据的各种模式。
- 提出了一种memory module,其中每个memory module项对应于正常模式的典型特征,用于减小CNNs的表示能力。
- 引入了特征紧凑性和分离性损失,用于训练memory module,确保memory module项的多样性和判别能力。
- 提出了一种新的memory module更新策略,以防止在测试时记录异常样本的特征。
实验结果:
在标准基准测试上,包括UCSD Ped2、CUHK Avenue和ShanghaiTech等,实验证明了方法的有效性和效率。
与现有技术水平相比,提出的方法表现出色,成为无监督视频序列异常检测领域的最新技术。
主要贡献:
- 提出使用多个原型来表示正常视频帧的多样性模式,引入了一个记录正常数据典型模式的memory module。
- 引入了特征紧凑性和分离性损失,以训练memory module并增强memory module项的多样性和判别能力。
- 在无监督视频序列异常检测方面取得了新的技术水平,提供了详尽的实验分析和消融研究。
2.相关工作
传统方法与CNNs:
- 传统的异常检测方法通常利用重构模型,如卷积自编码器(Conv-AE)、3D Conv-AE、循环神经网络(RNN)和生成对抗网络(GAN)等,但由于CNNs的表示能力,它们往往会用正常样本的组合来重构异常样本。
- 预测性或判别性模型的引入,如Deep SVDD,尝试通过将正常数据映射到超球体中心,将异常样本排除在球体外,取得了一定效果。
作者提出的方法
- 减小了CNNs的表示能力,通过使用memory module中的项目的组合来重建或预测视频帧,而不是直接使用编码器中的CNN特征,从而考虑了正常数据的各种模式。
- 与DeepCascade等方法相比,该方法通过memory module项明确记录正常模式,而不仅仅是检测正常图像的各个区域。
- 与Gong等人提出的Memory-augmented Autoencoder(MemAE)相比,该方法更好地使用CNNs作为映射函数,通过特征紧凑性和分离性损失显式分离memory module项,记录多样性和判别力较强的正常模式。
- 与MemAE相比,该方法使用更少的memory module项(10 vs 2,000),同时在测试时更新memory module,具有更好的性能。
memory module网络:
- 文中提到了传统的长短时记忆(LSTM)和引入全局记忆的memory module网络,用于处理顺序数据中的长期依赖性。
作者的方法
- 也利用了memory module,但采用了不同的更新策略,通过记录各种正常数据模式并考虑每个memory module项作为原型特征。
总结:在视频序列异常检测方面提出了一种新颖的思路,通过memory module和特定的训练损失,成功地捕捉了正常模式的多样性和判别力,相较于现有方法表现更为优越。
3.方法
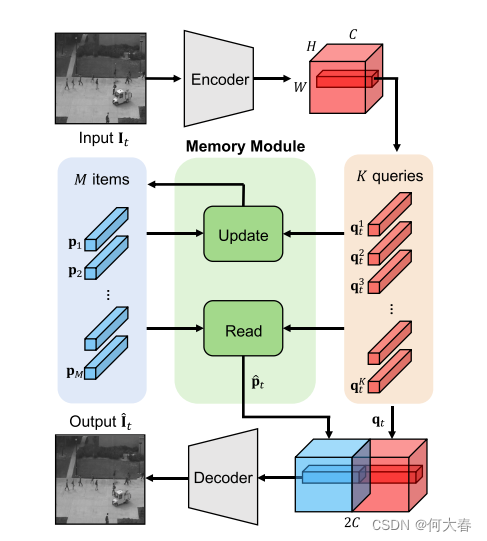
见图2:我们用于重建视频帧的框架概述。我们的模型主要由三个部分组成:一个编码器,一个memory module和一个解码器。编码器从时间t的输入视频帧 I t I_t It中提取尺寸为H×W×C的查询映射 q t q_t qt。memory module使用尺寸为1×1×C的查询 q t k q^k_t qtk,执行读取和更新尺寸为1×1×C的项 p m p_m pm,其中项和查询的数量分别为M和K,而K = H×W。查询映射 q t q_t qt与聚合的(即读取的)项 p ^ t \widehat{p}_t p t进行串联。然后,解码器将它们输入以重建视频帧 I ^ t \widehat{I}_t I t。对于预测任务,我们输入连续的四个视频帧来预测第五帧。)
我们的模型主要由三个组件组成:一个编码器,一个memory module,以及一个解码器。编码器接收正常的视频帧并提取查询特征。这些特征然后用于检索memory module项中的典型正常模式,并更新memory module。我们将查询特征和memory module项的聚合(即读取)馈送给解码器,以重建输入视频帧。我们使用端到端的重建、特征紧凑性和特征分离性损失对模型进行训练。在测试时,我们使用加权正则分数以防止memory module被异常视频帧更新。我们计算输入帧及其重建之间的差异,以及查询特征与memory module中最近项之间的距离,以量化视频帧中异常的程度。
3.1网络架构
3.1.1 Encoder and decoder
我们利用了广泛用于重建和未来帧预测任务的U-Net架构[34],以从输入视频帧中提取特征表示并用这些特征重建帧。不同的是,我们在编码器中移除了最后的批量归一化层[12]和ReLU层[18],因为ReLU会截断负值,从而限制了多样性的特征表示。我们相反地添加了一个L2归一化层,使特征具有共同的尺度。U-Net架构中的跳跃连接可能无法从视频帧中提取出用于重建任务的有用特征,我们的模型可能会学习复制输入以进行重建。因此,我们在重建任务中移除了跳跃连接,但在预测未来帧时保留了它们。我们用 I t I_t It和 q t q_t qt分别表示时间t时的视频帧和对应的来自编码器的特征(即查询)。编码器接收视频帧 I t I_t It并生成大小为H × W × C的查询映射 q t q_t qt,其中H、W、C分别为高度、宽度和通道数。我们用 q t k q^k_t qtk ∈ R C R^C RC(k = 1,… K),其中K = H × W,表示查询映射 q t q_t qt中大小为1 × 1 × C的个别查询。然后,将这些查询输入到memory module以读取memory module中的项或更新项,使其记录典型的正常模式。memory module的详细描述将在以下部分中提供。解码器接收查询和检索到的memory module项,并重建视频帧 I ^ t \widehat{I}_t I t。
3.1.2 Memory
memory module包含记录正常数据的各种原型模式的M个项目。我们用 p m p_m pm∈ R C R^C RC(m=1,…,M)表示存储器中的项。存储器执行读取和更新项目。
Read
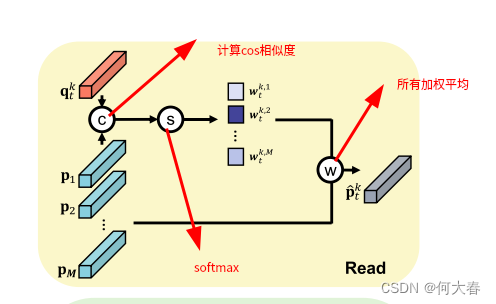
为了读取项目,我们计算每个查询 q t k q^k_t qtk和所有记忆项目 p m p_m pm之间的余弦相似性,得到大小为M×K的二维相关图。然后,我们沿着垂直方向应用softmax函数,并获得匹配概率 w t k , M w^{k,M}_t wtk,M,如公式1所示:
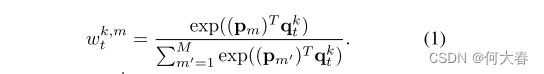
对于每个查询 q t k q^k_t qtk,我们通过具有相应权重 w t k , M w^{k,M}_t wtk,M的项目 p m p_m pm的加权平均来读取存储器,并获得特征 p ^ t k \widehat{p}_t^k p tk∈ R C R^C RC
如公式2所示:
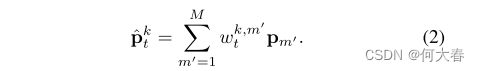
使用所有项而不仅仅是最接近的项,使得我们的模型能够理解多样的正常模式,考虑到整体的正常特征。换句话说,我们用memory module中的项 p m p_m pm的组合来表示查询 q t k q^k_t qtk。我们对各个查询应用读取运算符,得到一个转换后的特征图 p ^ t k \widehat{p}_t^k p tk∈ R H × W × C R^{H×W×C} RH×W×C(即,聚合的项)。我们沿着通道维度将其与查询映射 q t q_t qt连接在一起,并将它们输入到解码器。这使解码器能够使用memory module中的正常模式重建输入帧,减小了CNNs的表示能力,同时理解了正常性。
Update
对于每个memory module项,我们通过使用公式(1)中的匹配概率,选择声明该项是最近项的所有查询。注意,可以将多个查询分配给memory module中的单个项。请参见例如第4.3节中的图5。我们用 U m t U^t_m Umt表示与memory module中第m项对应的查询的索引集合。我们仅使用由集合 U t m U^m_t Utm索引的查询来更新该项,更新方式如下:
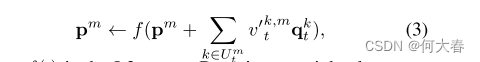
其中f(·)是L2范数。通过使用查询的加权平均值,而不是简单地将它们相加,我们可以更集中地关注靠近该项的查询。为此,我们计算类似于(1)的匹配概率 v t k , m v^{k,m}_t vtk,m,但通过对大小为M×K的相关图在水平方向上应用softmax函数进行,如公式4所示:
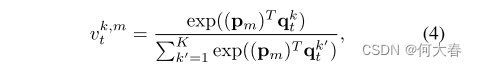
将其重新归一化,以考虑由集合 U t m U^m_t Utm索引的查询,方法如下:
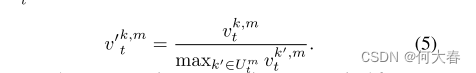
我们在训练和测试时都更新记录原型特征的memory module项,因为训练集和测试集中的正常模式可能不同,并且可能会因各种因素而变化,例如光照和遮挡。由于在测试时同时存在正常和异常帧,我们建议使用加权的正则分数,以防止memory module项记录异常帧中的模式。给定视频帧 I t I_t It,我们使用 I t I_t It与 I ^ t \widehat{I}_t I t之间的加权重建误差作为正则分数 ϵ t \epsilon_t ϵt:
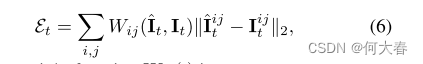
其中权重函数 W i j ( ⋅ ) W_{ij}(·) Wij(⋅)为:
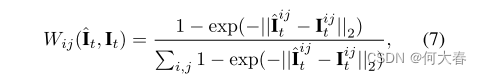
i和j是空间索引。当得分 ϵ t \epsilon_t ϵt高于阈值 γ \gamma γ时,我们将帧 I t I_t It视为异常样本,不将其用于更新memory module项。请注意,我们仅在更新memory module时使用此分数。权重函数允许更多地关注具有大重建误差的区域,因为异常活动通常出现在视频帧的小部分内。
3.2. Training loss
损失函数共分为三个部分:
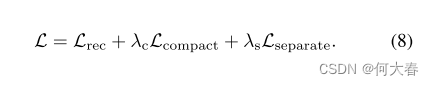
分别是重构损失、特征聚合损失、特征分离损失。
重构损失:
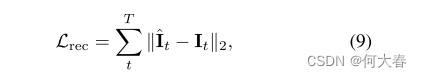
聚合损失:
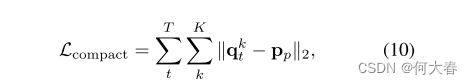
p p p_p pp为与 q t k q_t^k qtk最相近的项,让他们越近越好
分离损失:
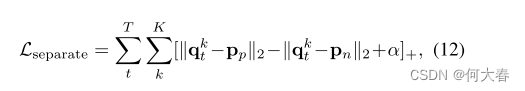
p n p_n pn为与 q t k q_t^k qtk第二相近的项,让他们有差距 α \alpha α,目的是为了不同的 p p p之间是不同的。
3.3. Abnormality score
共两个组成部分,一部分是Memory moudle的loss:
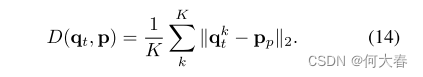
一部分是重构的损失:
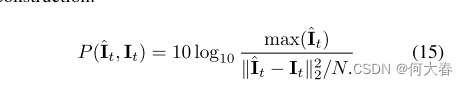
合起来的分数评估就是:
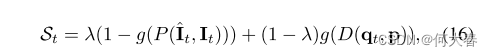
在这,作者对异常分数做了归一化:
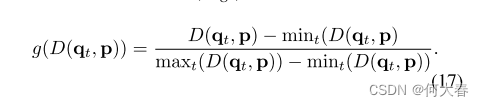
4.实验
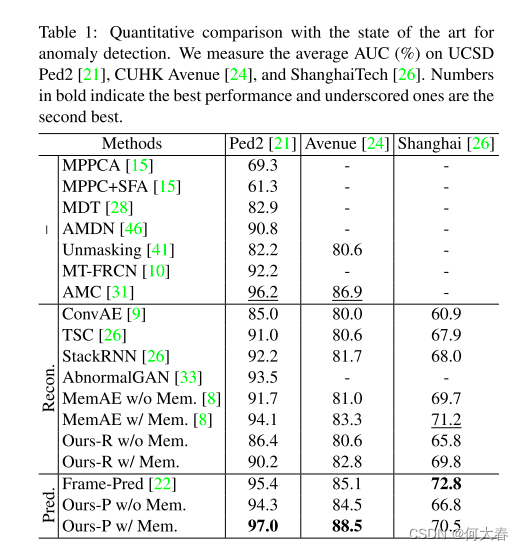
5.总结
我们引入了一种无监督学习方法来检测视频序列中的异常,该方法利用多个原型来考虑正常数据的各种模式。
为此,我们建议使用memory module模块将原型模式记录到memory module中的项目中。我们已经证明,使用特征紧凑性和分离性损失来训练memory module可以分离项目,从而实现对memory module的稀疏访问。
我们还提出了一种新的memory module更新方案,当正常和异常样本都存在时,它显著提高了异常检测的性能。对标准基准的广泛实验评估表明,我们的模型优于现有技术。
总结&代码复现:
主要是一个ae+memory的结构,作者提出了一个新的memory更新策略。
Learning Normal Dynamics in Videos with Meta Prototype Network这篇论文和这个是很像的,应该在这个代码的基础上进行修改创新的。
复现:
这篇论文的代码拿来就可以用,代码方面没问题,下载一下包就好了,比较友好。
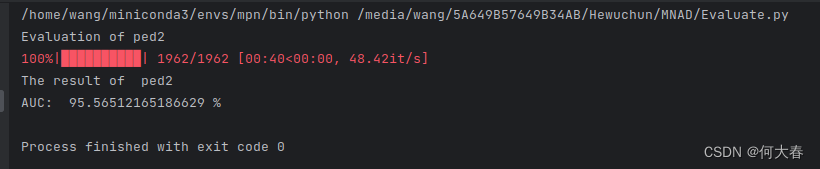
和原论文97个点差别不大。






![[二分查找双指针]LeetCode881: 救生艇](https://img-blog.csdnimg.cn/f95ddae62a4e43a68295601c723f92fb.gif#pic_center)
![[足式机器人]Part2 Dr. CAN学习笔记-数学基础Ch0-5Laplace Transform of Convolution卷积的拉普拉斯变换](https://img-blog.csdnimg.cn/direct/b4b7f97d69d345758e3e7218bc4a7f5f.png)