前言:大数据相关的技术名词特别多,这些技术栈之间的关系是什么,对初学者来说很难找到抓手。我一开始从后端转大数据的时候有点懵逼,整体接触了一遍之后才把大数据技术栈给弄明白了。
一、大数据技术栈
做大数据开发,无非要干四件事情,采集、存储、计算、查询。此外,一些开发必备的基础语言能力是需要的。按照这几个维度,对大数据常见技术栈做了下划分。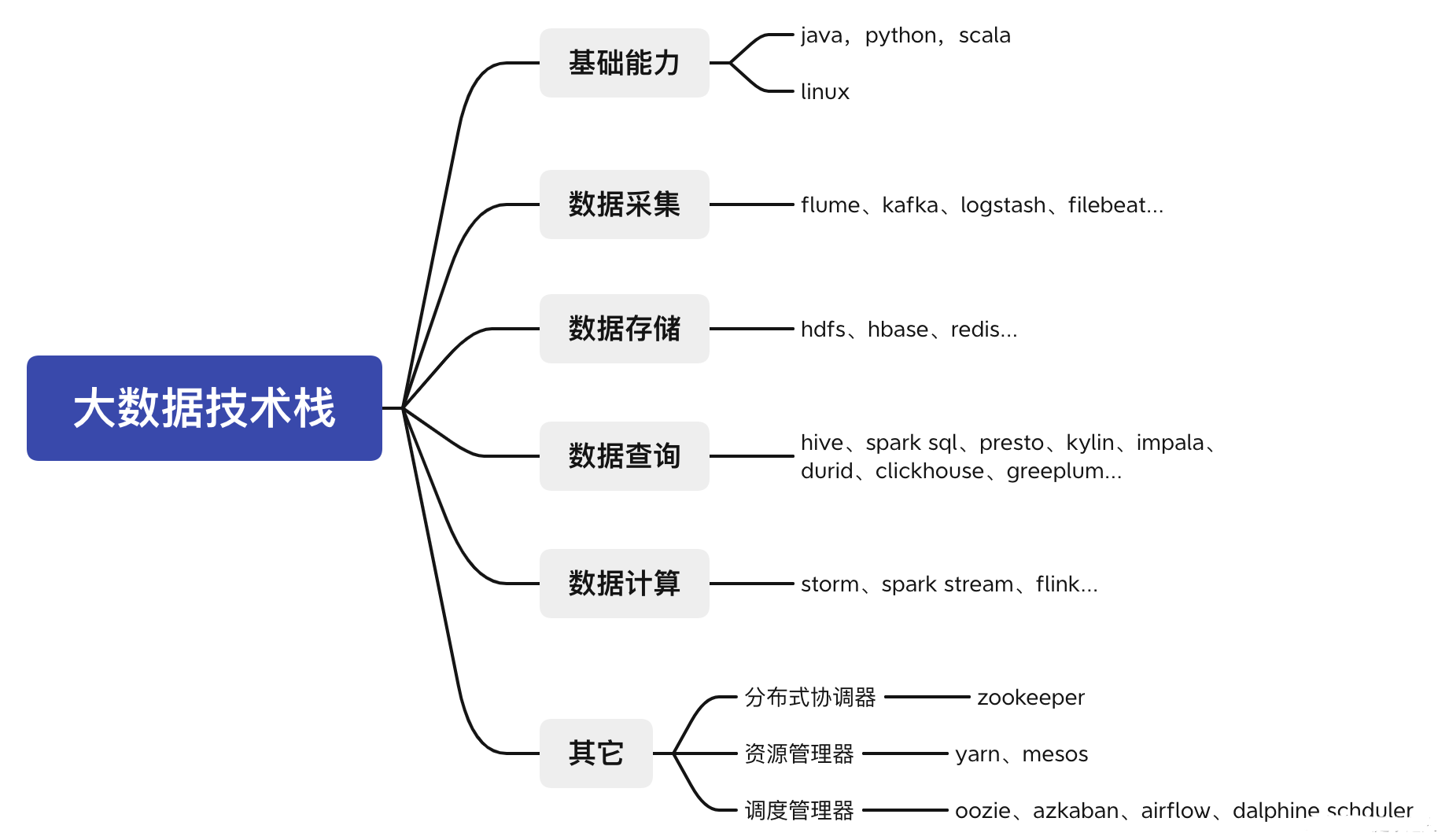
1.1、基础编程语言
大数据框架大多采用 Java 语言进行开发,并且几乎全部的框架都会提供 Java API 。python通常用在爬虫,数据分析,机器学习上,部分大数据组件是python开发的,例如airflow。scala底层还是Java,Scala 是一门综合了面向对象和函数式编程概念的静态类型的编程语言,它运行在 Java 虚拟机上,可以 与所有的 Java 类库无缝协作,著名的 Kafka 就是采用 Scala 语言进行开发的。 为什么需要学习 Scala 语言 ? 这是因为当前最火的计算框架 Flink 和 Spark 都提供了 Scala 语言的接口,使用它进行开发,比使用 Java 8 所需要的代码更少,且 Spark 就是使用 Scala 语言进行编写的, 学习 Scala 可以帮助你更深入的理解 Spark。这里说明一下,如果你的时间有限,不一定要学完 Scala 才去学习大数据框架。Scala 确实足够的精简和灵活,但其在语言复杂度上略大于 Java,例如隐式转换和隐式参数等概念在初次涉及时会 比较难以理解,所以你可以在了解 Spark 后再去学习 Scala,因为类似隐式转换等概念在 Spark 源码中有大量的运用。
1.2、数据采集
一般通过filebeat,logstash,kafka,flume做日志采集。一些应用系统的数据,也会通过kafka或者binlog的方式同步到大数据组件做存储。
1.3、数据存储
这里的数据存储引擎和传统的关系型数据库有很大的区别。常见分布式存储文件系统有hdfs。此外,对于一些非结构化的数据会通过nosql的方式做存储,常见的nosql存储组件有hbase,Click House、redis。
1.4、数据查询
常见的有hive、spark sql、presto、kylin、impala、durid、clickhouse、greeplum,每个组件都有自己的查询特性和使用场景。
1.5、数据计算
常见的计算方式有流计算和批处理,按实效性又称为离线计算和实时计算。对应的计算组件有storm,spark stream,flink。
1.6、大数据辅助中间件
-
分布式协调器:大数据组件为了提高可靠性通常是分布式存储的,这样就涉及到各个组件之间的协调同步。最常见的协调器就是zookeeper。
-
资源管理器:为了提高计算能力,会对计算资源(CPU,内存,磁盘)做分配,常见的组件有yarn,mesos。
-
调度管理器:调度管理器管理任务何时执行,周期执行,是否重试等。常见的有airflow,dalphine schduler,oozie,azkaban。
二、大数据框架分类
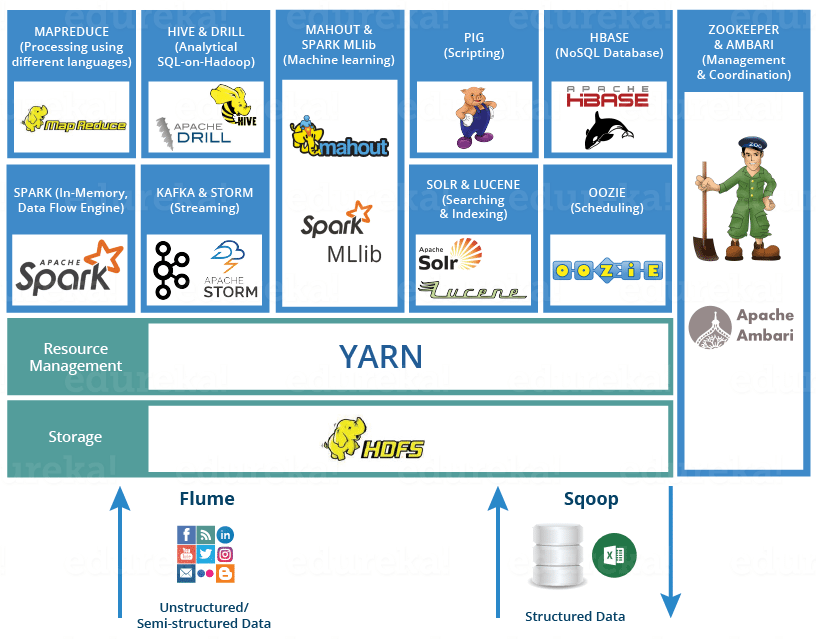
三、大数据应用
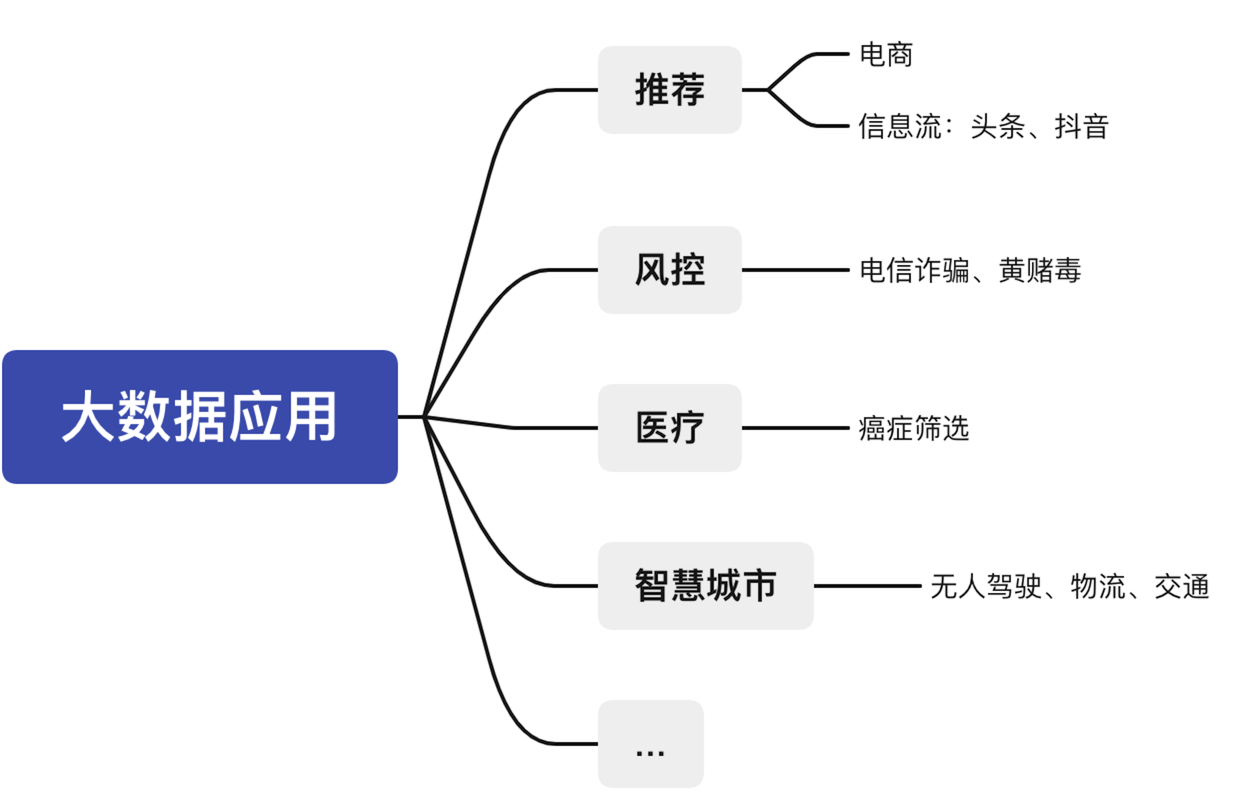 推荐领域:电商购物,猜你喜欢。信息流方面,像头条文章推荐,抖音视频推荐。
推荐领域:电商购物,猜你喜欢。信息流方面,像头条文章推荐,抖音视频推荐。
风控:仿电信诈骗,黄赌毒识别,反洗钱等等。
医疗:通过用户一些医疗信息做疾病的识别。
智慧城市:自动驾驶,智慧物流,城市交通管理等等。




![[报错]记录IDEA远程开发报错:java: Cannot run program.....](https://img-blog.csdnimg.cn/direct/c42b89a25c5f45e599eb90696c45c44f.png)

![[Linux] 用LNMP网站框架搭建论坛](https://img-blog.csdnimg.cn/direct/ef63a1bd94014f63b6283a533ca65254.png)