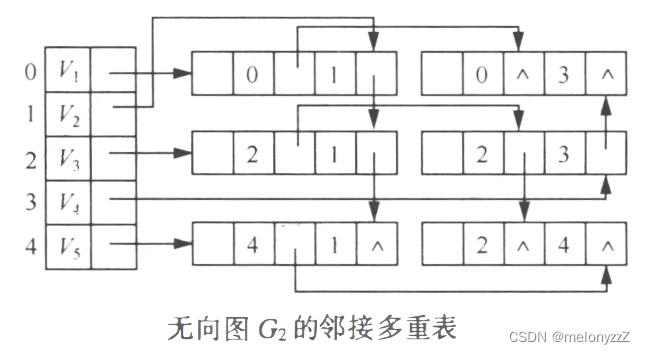
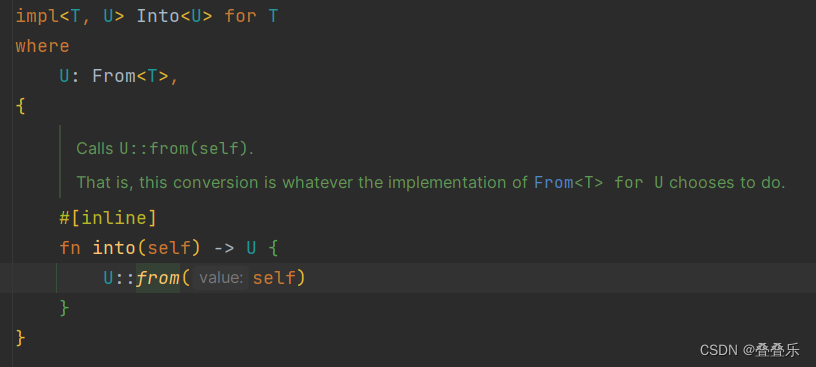
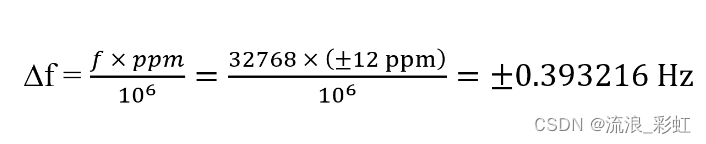语言是一种压缩媒介,人们通过它来提炼和传达他们对世界的知识和经验。大型语言模型(LLMs)已成为一种有前景的方法,通过将世界投影到语言空间中来捕捉这种抽象。虽然这些模型被认为在文本形式中内化了可概括的知识,但如何利用这种可概括的知识使具身代理能够在现实世界中进行物理行动仍然是一个问题。
该工作研究了将抽象语言指令(例如“摆放桌子”)与机器人行动相结合的问题。之前的研究利用词汇分析来解析指令,而最近的研究利用语言模型将指令分解为文本序列的步骤。然而,为了能够与环境进行物理交互,现有方法通常依赖于手动设计或预训练的运动基元(即技能),这些基元可以由LLM或规划器调用。由于缺乏大规模的机器人数据,这种依赖于单个技能的获取常常被认为是系统的一个主要瓶颈。因此,问题就出现了:如何在细粒度的行动层面上利用LLMs内部化的丰富知识,而不需要费力的数据收集或为每个单独的基元手动设计?
为了解决这个挑战,该工作首先注意到LLMs直接输出文本形式的控制动作是不可行的,因为这些动作通常由高维空间中的高频控制信号驱动。然而,该工作发现LLMs擅长推断受语言条件约束的可行性和限制,并通过利用它们的编码能力,可以通过编排感知调用(例如通过CLIP 或开放词汇检测器和数组操作(例如通过NumPy )来组合密集的3D体素图,将它们在视觉空间中进行关联。例如,给定指令“打开顶层抽屉,注意花瓶”,LLMs可以被提示推断出:1)应该抓住顶层抽屉的把手,2)把手需要向外移动,3)机器人应该远离花瓶。虽然这些信息是以文本形式表达的,但LLMs可以生成Python代码来调用感知API以获取相关对象或部件(例如“把手”)的空间几何信息,然后操纵3D体素图,在观察空间中的相关位置处为目标位置指定高值,同时为花瓶周围指定低值。最后,组合的值图可以作为运动规划器的目标函数,直接合成实现给定指令的机器人轨迹,而无需为每个任务或LLM进行额外的训练数据。
相关成果以“VoxPoser: Composable 3D Value Maps for Robotic Manipulation with Language Models ”为题发表。
主要贡献
该工作的贡献总结如下:
• 该工作提出了VoxPoser,一种从预训练的语言模型中提取机器人操作的可行性和约束的方法,无需额外的训练,并且可以推广到开放指令。
• 利用VoxPoser来表示任务目标,该工作展示了合成轨迹可以在模拟和真实环境中以闭环方式通过MPC进行鲁棒执行的能力,适用于各种操作任务。
• 该工作展示了VoxPoser适用于仅有有限数量的在线交互,通过高效学习动力学模型的应用性,例如,在不到3分钟内学习使用杠杆把手打开门。
方法简介
考虑一个给定的操作问题,以自由形式语言指令L来描述(例如,“打开顶层抽屉”)。然而,根据L生成机器人轨迹可能很困难,因为L可能具有任意长的时间跨度或不完全规定(即需要上下文理解)。相反,该工作将重点放在问题的各个阶段(子任务)ℓi上,这些阶段明确指定了一个操作任务(例如,“抓住抽屉把手”,“拉开抽屉”),其中分解由高级规划器(例如LLM或基于搜索的规划器)给出。本工作中研究的核心问题是为机器人生成运动轨迹。

VoxPoser通过合成3D地图进行运动规划
该工作将运动轨迹表示为一系列由操作空间控制器执行的密集末端执行器路径点,其中每个路径点包括期望的6自由度末端执行器姿态、末端执行器速度和夹爪动作。然而,值得注意的是,也可以使用其他表示轨迹的方式,例如关节空间轨迹。
计算相对于自由形式语言指令的Ftask是极具挑战性的,不仅因为语言可以传达的丰富语义空间,还因为缺乏带有T和ℓ标签的机器人数据。然而,该工作提供了一个关键观察,即大量的任务可以通过机器人的观察空间中的体素值图来表征,它指导场景中的“感兴趣实体”(如机器人末端执行器、物体或物体的部分)的运动。例如,在下图中考虑任务“打开顶层抽屉”及其第一个子任务“抓住顶层抽屉把手”(由LLMs推断)。这里的“感兴趣实体”是机器人末端执行器,体素值图应该反映对抽屉把手的吸引力。通过进一步指示“注意花瓶”,该图还可以更新以反映对花瓶的排斥。该工作将“感兴趣实体”表示为e,其轨迹表示为τe。
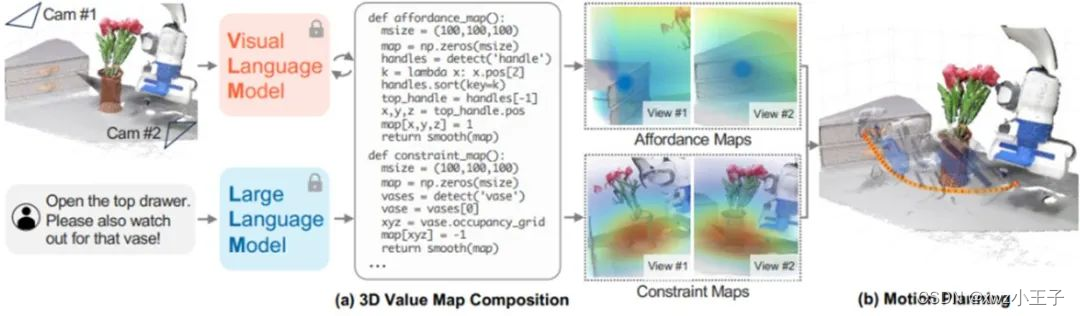
VoxPoser主要方法示意图
值得注意的是,该工作观察到,通过在互联网规模的数据上进行预训练,大型语言模型不仅能够识别“感兴趣实体”,而且可以通过编写Python程序来组合准确反映任务指令的值图。具体而言,当指令作为代码中的注释给出时,LLMs可以被提示:1)调用感知API(调用视觉语言模型(VLM),如开放词汇检测器)以获取相关对象的空间几何信息,2)生成NumPy操作以操作3D数组,3)在相关位置上指定精确的值。该工作将这种方法称为VOXPOSER。具体而言,该工作的目标是通过提示LLM并通过Python解释器执行代码来获得一个体素值图Vti = VoxPoser(ot, ℓi),其中ot是时间t时的RGB-D观察结果,ℓi是当前的指令。此外,由于V通常是稀疏的,该工作通过平滑操作使体素值图变得密集,因为它们可以鼓励由运动规划器优化的更平滑的轨迹。
在获得任务代价之后,使用简单的零阶优化方法,通过随机采样轨迹并使用提出的目标对其进行评分。进一步地,优化是在模型预测控制框架中实现的,该框架在每一步迭代地使用当前观察来重新规划轨迹,以在动态干扰下稳健地执行轨迹,可以使用学习的模型或基于物理的模型。然而,由于VoxPoser在观察空间中提供了“密集的奖励”,而且该工作能够在每一步重新规划,令人惊讶的是该工作发现,即使使用基于简单启发式模型,整个系统已经能够完成本工作中考虑的大量操作任务。由于一些值图是针对“感兴趣实体”定义的,而这个实体不一定是机器人,该工作还使用动力学模型找到所需的机器人轨迹来最小化任务代价(即机器人与环境之间的相互作用实现所需的物体运动)。
实验结果
1)操作任务结果
该工作研究VoxPoser 是否可以零样本合成机器人轨迹来执行现实世界中的日常操作任务。环境设置的详细信息可以在附录A.4 中找到。虽然所提出的方法可以推广到开放的指令集和开放的对象集,但该工作选择了 5 个代表性任务来提供表 1 中的定量评估。包括环境推出和价值图可视化在内的定性结果是 如图3所示。该工作发现VoxPoser可以有效地合成用于日常操作任务的机器人轨迹,并且平均成功率很高。由于具有快速重新规划功能,它对外部干扰也具有鲁棒性,例如移动目标/障碍物以及机器人关闭抽屉后将其拉开。
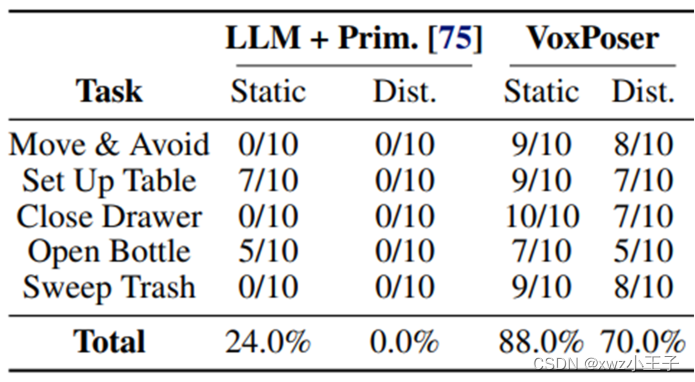
实验结果
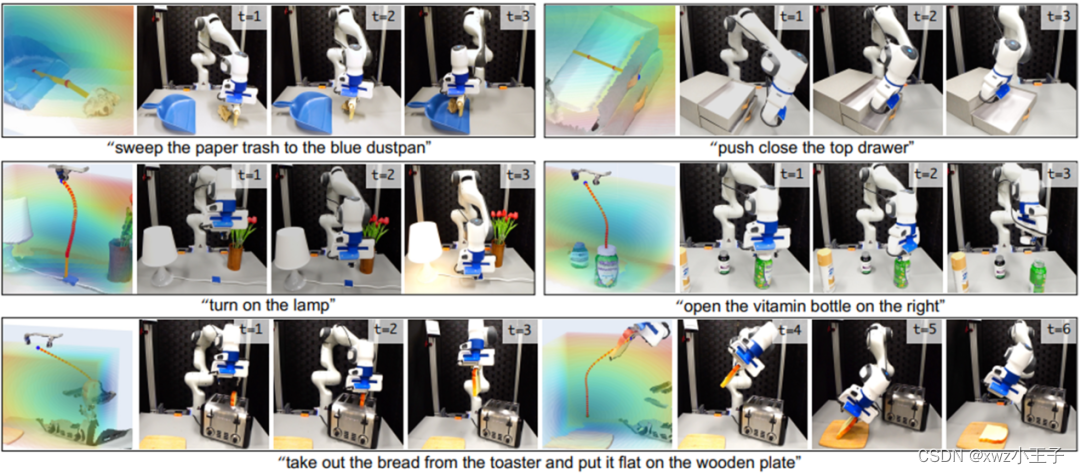
生成3D价值图可视化结果
该工作进一步与 Code as Policies的变体进行比较,该变体使用 LLM 来参数化简单基元的预定义列表(例如,移动到姿势、打开夹具)。该工作发现,与链接顺序策略逻辑相比,在联合优化方案下考虑其他约束的同时进行空间组合的能力是一种更灵活的表述,释放了更多操作任务的可能性并导致更稳健的执行。
2)泛化到新指令或属性
新任务泛化性能结果
表 2 显示了每项任务 20 个回合的平均成功率。该工作发现 VoxPoser 在所有场景中都表现出卓越的泛化能力。通过价值图组合而不是直接指定原始参数,将 LLM 知识扎根于机器人感知中,可以提供更大的灵活性和更好的泛化能力。
总结与展望
这项工作中,该工作提出了VOXPOSER,一个用于提取可供性和约束的通用框架,基于3D感知空间,从LLM和VLM中提取现实世界中的日常操作任务,为开放集指令和对象提供显着的泛化优势。尽管取得了引人注目的结果,VoxPoser仍存在一些局限性。首先,它依赖于外部感知模块,这限制了需要整体视觉推理或理解细粒度物体几何形状的任务。其次,虽然适用于高效的动力学学习,但仍然需要通用的动力学模型来实现具有相同泛化水平的接触丰富的任务。第三,该工作的运动规划器仅考虑末端执行器轨迹,而全臂规划也是可行的,并且可能是更好的设计选择。最后,LLM需要手动提示工程。还看到了未来工作的几个令人兴奋的场所。例如,最近成功的多模态LLM可以直接转化为VoxPoser以实现直接视觉基础。为对齐和提示开发的方法可用于减轻临时工程工作。最后,可以开发更先进的轨迹优化方法,与VoxPoser合成的值图进行最佳接口。