文章目录 1. 理论介绍 1.1. 深度卷积神经网络(AlexNet) 1.2. 使用块的网络(VGG) 1.3. 网络中的网络(NiN) 2. 实例解析 2.1. 实例描述 2.2. 代码实现 2.2.1. 在FashionMNIST数据集上训练AlexNet 2.2.1.1. 主要代码 2.2.1.2. 完整代码 2.2.1.3. 输出结果 2.2.2. 在FashionMNIST数据集上训练VGG-11 2.2.2.1. 主要代码 2.2.2.2. 完整代码 2.2.2.3. 输出结果 2.2.2.1. 主要代码 2.2.2.2. 完整代码 2.2.2.3. 输出结果
特征本身应该被学习 ,而且在合理地复杂性前提下,特征应该由多个共同学习的神经网络层组成,每个层都有可学习的参数。在机器视觉中,最底层可能检测边缘、颜色和纹理,更高层建立在这些底层表示的基础上,以表示更大的特征。包含许多特征的深度模型需要大量的有标签数据 ,才能显著优于基于凸优化的传统方法(如线性方法和核方法)。ImageNet挑战赛 为研究人员提高超大规模的数据集。 深度学习对计算资源要求很高 ,训练可能需要数百个迭代轮数,每次迭代都需要通过代价高昂的许多线性代数层传递数据。用GPU训练神经网络 大大提高了训练速度,相比于CPU,GPU由100~1000个小的处理单元(核心)组成,庞大的核心数量使GPU比CPU快几个数量级;GPU核心更简单,功耗更低;GPU拥有更高的内存带宽;卷积和矩阵乘法,都是可以在GPU上并行化的操作。 AlexNet首次证明了学习到的特征可以超越手工设计的特征。
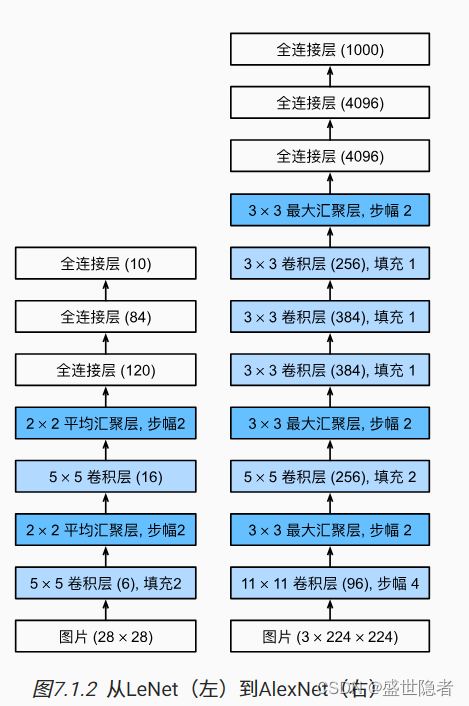
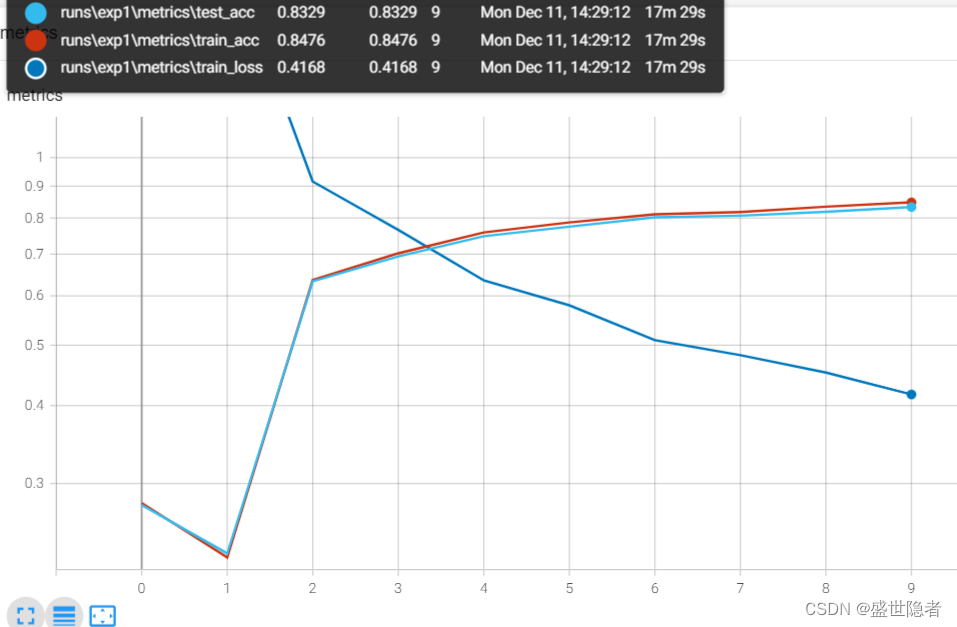
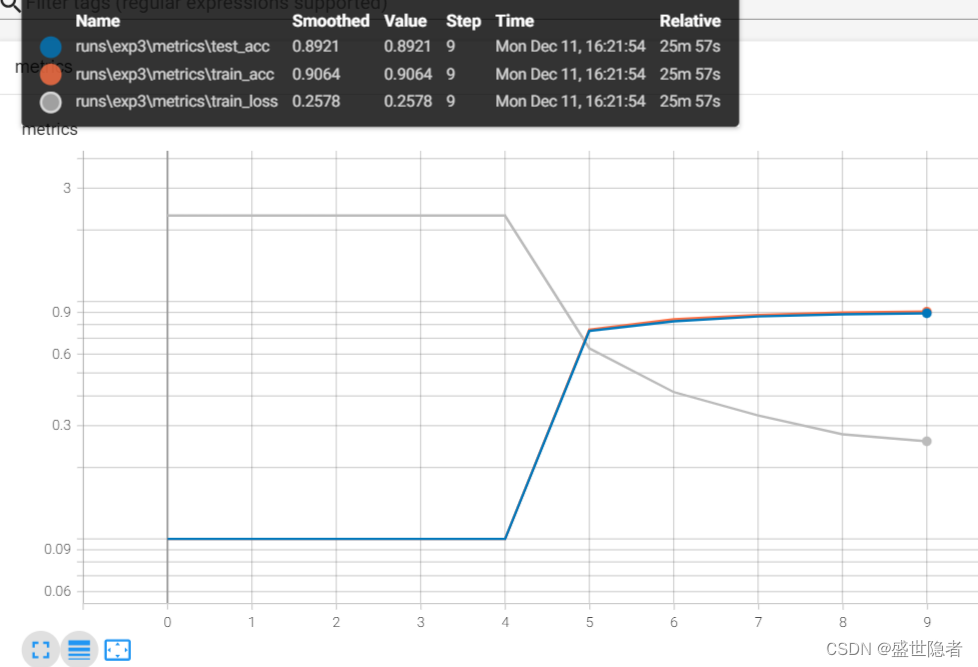
AlexNet使用ReLU 而不是sigmoid作为其激活函数。 在最后一个卷积层后有两个全连接层,分别有4096个输出。 这两个巨大的全连接层拥有将近1GB的模型参数。 由于早期GPU显存有限,原版的AlexNet采用了双数据流设计 ,使得每个GPU只负责存储和计算模型的一半参数。 AlexNet通过暂退法 控制全连接层的模型复杂度。 为了进一步扩充数据 ,AlexNet在训练时增加了大量的图像增强数据,如翻转、裁切和变色。 这使得模型更健壮,更大的样本量有效地减少了过拟合。 经典卷积神经网络的基本组成部分 VGG块 由一系列卷积层组成,后面再加上用于空间下采样的最大池化层。深层且窄的卷积(即 3 × 3 3\times3 3 × 3 VGG网络 由几个VGG块和全连接层组成。超参数变量conv_arch指定了每个VGG块里卷积层个数和输出通道数。全连接模块则与AlexNet中的相同。VGG-11有5个VGG块,其中前两个块各有一个卷积层,后三个块各包含两个卷积层,共8个卷积层。 第一个模块有64个输出通道,每个后续模块将输出通道数量翻倍,直到该数字达到512。 网络中的网络(NiN)在每个像素的通道上分别使用多层感知机 。 在FashionMNIST数据集上训练AlexNet。注:输入图像增加 224 × 224 224\times224 224 × 224 在FashionMNIST数据集上训练VGG-11。注:可以按比例缩小通道数以减少参数量,学习率可以设置得略高。 AlexNet = nn. Sequential( nn. Conv2d( 1 , 96 , kernel_size= 11 , stride= 4 , padding= 1 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Conv2d( 96 , 256 , kernel_size= 5 , padding= 2 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Conv2d( 256 , 384 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. Conv2d( 384 , 384 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. Conv2d( 384 , 256 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Flatten( ) , nn. Linear( 6400 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 10 )
) . to( device, non_blocking= True )
import os, torch
from tensorboardX import SummaryWriter
from rich. progress import track
from torchvision. datasets import FashionMNIST
from torchvision. transforms import Compose, ToTensor, Resize
from torch. utils. data import DataLoader
from torch import nn, optimdef load_dataset ( ) : """加载数据集""" root = "./dataset" transform = Compose( [ Resize( 224 ) , ToTensor( ) ] ) mnist_train = FashionMNIST( root, True , transform, download= True ) mnist_test = FashionMNIST( root, False , transform, download= True ) dataloader_train = DataLoader( mnist_train, batch_size, shuffle= True , num_workers= num_workers, pin_memory= True , ) dataloader_test = DataLoader( mnist_test, batch_size, shuffle= False , num_workers= num_workers, pin_memory= True , ) return dataloader_train, dataloader_testif __name__ == "__main__" : num_epochs = 10 batch_size = 128 num_workers = 3 lr = 0.01 device = torch. device( 'cuda' ) def log_dir ( ) : root = "runs" if not os. path. exists( root) : os. mkdir( root) order = len ( os. listdir( root) ) + 1 return f' { root} /exp { order} ' = SummaryWriter( log_dir= log_dir( ) ) dataloader_train, dataloader_test = load_dataset( ) AlexNet = nn. Sequential( nn. Conv2d( 1 , 96 , kernel_size= 11 , stride= 4 , padding= 1 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Conv2d( 96 , 256 , kernel_size= 5 , padding= 2 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Conv2d( 256 , 384 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. Conv2d( 384 , 384 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. Conv2d( 384 , 256 , kernel_size= 3 , padding= 1 ) , nn. ReLU( ) , nn. MaxPool2d( kernel_size= 3 , stride= 2 ) , nn. Flatten( ) , nn. Linear( 6400 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 10 ) ) . to( device, non_blocking= True ) criterion = nn. CrossEntropyLoss( reduction= 'none' ) optimizer = optim. SGD( AlexNet. parameters( ) , lr= lr) metrics_train = torch. zeros( 3 , device= device) metrics_test = torch. zeros( 2 , device= device) for epoch in track( range ( num_epochs) , description= 'AlexNet' ) : AlexNet. train( ) for X, y in dataloader_train: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) loss = criterion( AlexNet( X) , y) optimizer. zero_grad( ) loss. mean( ) . backward( ) optimizer. step( ) AlexNet. eval ( ) with torch. no_grad( ) : metrics_train. zero_( ) for X, y in dataloader_train: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) y_hat = AlexNet( X) loss = criterion( y_hat, y) metrics_train[ 0 ] += loss. sum ( ) metrics_train[ 1 ] += ( y_hat. argmax( dim= 1 ) == y) . sum ( ) metrics_train[ 2 ] += y. numel( ) metrics_train[ 0 ] /= metrics_train[ 2 ] metrics_train[ 1 ] /= metrics_train[ 2 ] metrics_test. zero_( ) for X, y in dataloader_test: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) y_hat = AlexNet( X) metrics_test[ 0 ] += ( y_hat. argmax( dim= 1 ) == y) . sum ( ) metrics_test[ 1 ] += y. numel( ) metrics_test[ 0 ] /= metrics_test[ 1 ] _metrics_train = metrics_train. cpu( ) . numpy( ) _metrics_test = metrics_test. cpu( ) . numpy( ) writer. add_scalars( 'metrics' , { 'train_loss' : _metrics_train[ 0 ] , 'train_acc' : _metrics_train[ 1 ] , 'test_acc' : _metrics_test[ 0 ] } , epoch) writer. close( )
def vgg_block ( num_convs, in_channels, out_channels) : """定义VGG块""" layers = [ ] for _ in range ( num_convs) : layers. append( nn. Conv2d( in_channels, out_channels, kernel_size= 3 , padding= 1 ) ) layers. append( nn. ReLU( ) ) in_channels = out_channelslayers. append( nn. MaxPool2d( kernel_size= 2 , stride= 2 ) ) return nn. Sequential( * layers) def vgg ( conv_arch) : """定义VGG网络""" vgg_blocks = [ ] in_channels = 1 out_channels = 0 for num_convs, out_channels in conv_arch: vgg_blocks. append( vgg_block( num_convs, in_channels, out_channels) ) in_channels = out_channelsreturn nn. Sequential( * vgg_blocks, nn. Flatten( ) , nn. Linear( out_channels * 7 * 7 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 10 ) , )
import os
from tensorboardX import SummaryWriter
from rich. progress import track
import torch
from torch import nn, optim
from torch. utils. data import DataLoader
from torchvision. transforms import Compose, Resize, ToTensor
from torchvision. datasets import FashionMNISTdef load_dataset ( ) : """加载数据集""" root = "./dataset" transform = Compose( [ Resize( 224 ) , ToTensor( ) ] ) mnist_train = FashionMNIST( root, True , transform, download= True ) mnist_test = FashionMNIST( root, False , transform, download= True ) dataloader_train = DataLoader( mnist_train, batch_size, shuffle= True , num_workers= num_workers, pin_memory= True , ) dataloader_test = DataLoader( mnist_test, batch_size, shuffle= False , num_workers= num_workers, pin_memory= True , ) return dataloader_train, dataloader_testdef vgg_block ( num_convs, in_channels, out_channels) : """定义VGG块""" layers = [ ] for _ in range ( num_convs) : layers. append( nn. Conv2d( in_channels, out_channels, kernel_size= 3 , padding= 1 ) ) layers. append( nn. ReLU( ) ) in_channels = out_channelslayers. append( nn. MaxPool2d( kernel_size= 2 , stride= 2 ) ) return nn. Sequential( * layers) def vgg ( conv_arch) : """定义VGG网络""" vgg_blocks = [ ] in_channels = 1 out_channels = 0 for num_convs, out_channels in conv_arch: vgg_blocks. append( vgg_block( num_convs, in_channels, out_channels) ) in_channels = out_channelsreturn nn. Sequential( * vgg_blocks, nn. Flatten( ) , nn. Linear( out_channels * 7 * 7 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 4096 ) , nn. ReLU( ) , nn. Dropout( p= 0.5 ) , nn. Linear( 4096 , 10 ) , ) if __name__ == '__main__' : num_epochs = 10 batch_size = 128 num_workers = 3 lr = 0.05 device = torch. device( 'cuda' ) def log_dir ( ) : root = "runs" if not os. path. exists( root) : os. mkdir( root) order = len ( os. listdir( root) ) + 1 return f' { root} /exp { order} ' = SummaryWriter( log_dir= log_dir( ) ) dataloader_train, dataloader_test = load_dataset( ) ratio = 4 conv_arch = ( ( 1 , 64 ) , ( 1 , 128 ) , ( 2 , 256 ) , ( 2 , 512 ) , ( 2 , 512 ) ) small_conv_arch = [ ( pair[ 0 ] , pair[ 1 ] // ratio) for pair in conv_arch] net = vgg( small_conv_arch) . to( device, non_blocking= True ) criterion = nn. CrossEntropyLoss( reduction= 'none' ) optimizer = optim. SGD( net. parameters( ) , lr= lr) metrics_train = torch. zeros( 3 , device= device) metrics_test = torch. zeros( 2 , device= device) for epoch in track( range ( num_epochs) , description= 'VGG' ) : net. train( ) for X, y in dataloader_train: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) loss = criterion( net( X) , y) optimizer. zero_grad( ) loss. mean( ) . backward( ) optimizer. step( ) net. eval ( ) with torch. no_grad( ) : metrics_train. zero_( ) for X, y in dataloader_train: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) y_hat = net( X) loss = criterion( y_hat, y) metrics_train[ 0 ] += loss. sum ( ) metrics_train[ 1 ] += ( y_hat. argmax( dim= 1 ) == y) . sum ( ) metrics_train[ 2 ] += y. numel( ) metrics_train[ 0 ] /= metrics_train[ 2 ] metrics_train[ 1 ] /= metrics_train[ 2 ] metrics_test. zero_( ) for X, y in dataloader_test: X, y = X. to( device, non_blocking= True ) , y. to( device, non_blocking= True ) y_hat = net( X) metrics_test[ 0 ] += ( y_hat. argmax( dim= 1 ) == y) . sum ( ) metrics_test[ 1 ] += y. numel( ) metrics_test[ 0 ] /= metrics_test[ 1 ] _metrics_train = metrics_train. cpu( ) . numpy( ) _metrics_test = metrics_test. cpu( ) . numpy( ) writer. add_scalars( 'metrics' , { 'train_loss' : _metrics_train[ 0 ] , 'train_acc' : _metrics_train[ 1 ] , 'test_acc' : _metrics_test[ 0 ] } , epoch) writer. close( )