1. 引言
开源代码实现见:
- https://github.com/hashcloak/fhe_risc0_zkvm(Rust)
- https://github.com/weikengchen/vfhe-profiled(Rust)
- https://github.com/l2iterative/vfhe0(Rust)
L2IV Research团队近期尝试用ZKP来验证FHE,原因在于如下2大应用场景的出现:
- 1)fhEVM的链下计算:Fhenix和Inco,正基于Zama的fhEVM构建在L1链上具有全同态加密增强的EVM。其中fhEVM全称为fully homomorphic Ethereum Virtual Machine (EVM)。链下计算,使得L1 Validators无需rerun FHE计算,从而具备可扩展性,同时,可能可进一步隐藏函数,从而具备隐私性。
- 2)FHE mining:受Aleo的proof of succinct work (PoSW) 和 ZPrize 启发,认为FHE mining是一个值得注意的未来方向,以鼓励FHE的ASIC制造,并激励FHE矿工成为fhEVM网络的Validators。FHE mining的核心任务是为FHE上下文中的PoSW开发ZKP系统。
FHE方案有多种,L2IV Research团队尤其关注Zama所使用TFHE。其实现的TFHE使用模 p = 2 64 p=2^{64} p=264——其可在现代CPU和其它硬件平台上高效计算。L2IV Research团队对验证FHE的兴趣源于其在fhEVM中的直接适用性。
但是,使用模 p = 2 64 p=2^{64} p=264,对ZKP来说挑战不小,因仅有有限的ZKP系统可高效兼容该模:
- 1)大多数ZKP系统都设计为某Field内运算,但模 p = 2 64 p=2^{64} p=264不构成a field,因为其缺少对2的modular inverse,其仅仅是a ring。现有的2021年论文Rinocchio: SNARKs for Ring Arithmetic 是针对ring设计的,但其不能用于本场景,因其仅支持:
- 若该ZKP为designed-verifier的,可支持任意rings,但这不适于区块链应用场景。
- rings与安全、composite-order pairing-friendly curves关联使用,其与 p = 2 64 p=2^{64} p=264不兼容。
- 2)使用合适的域来模拟64位整数计算,这是可选项,尽管其由自己的开销。仅有少量VMs设计为64位整数的,如RISC Zero和Aleo的Leo。也可使用32位域来模拟64位整数计算,如Polygon Miden 和 Valida(使用Plonky3)。
L2IV Research团队选择RISC Zero的原因有3:
- 1)其工具链和开发生态相对稳定和成熟。
- 2)RISC Zero的证明生成性能,尤其是在Apple M2 chips上的性能,相当不错。
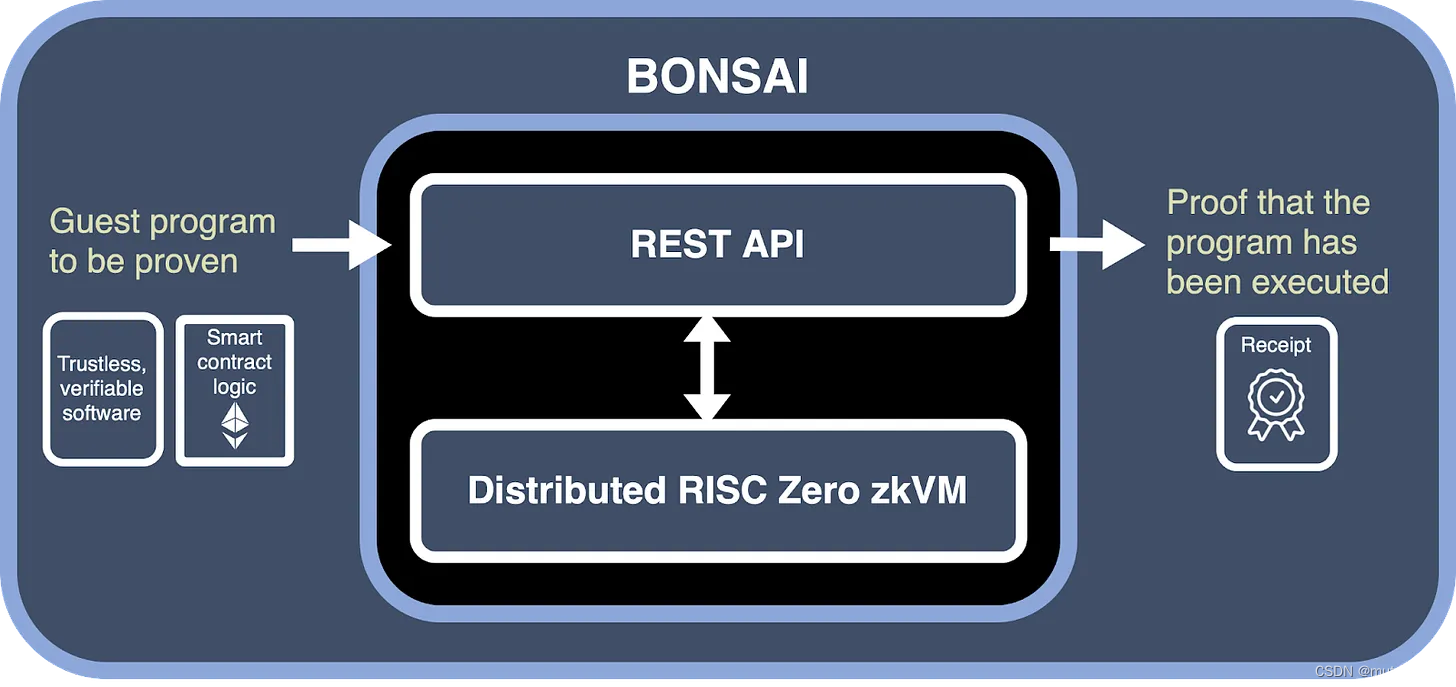
- 3)通过Bonsai API,可将证明生成处理,卸载给RISC Zero的专用Bonsai服务器,从而避免需在本地生成proof。
本文重点展示功能而暂未优化的原型。后续将做一系列优化实现。未来也将探索不同的方向。
本文概述了FHE和RISC Zero,详细介绍了将现有Rust代码用于RISC Zero的过程,介绍了RISC Zero中一种新的数据加载优化技巧,并演示了使用Ghidra对RISC-V代码进行分解和分析,以确定进一步的优化机会。
2023年12月14日更新:我们注意到“include_bytes”可能无法正确对齐数据,并可能导致对齐错误。因此,选择使用include_bytes_aligned crate中的include_bytes_aligned。
2. 何为TFHE?
fully homomorphic encryption (FHE) 为加密算法,表示为 E E E,用于做数据加密。如已知明文 a a a,经FHE加密后获得密文 E ( a ) E(a) E(a):
a → E ( a ) a \rightarrow E(a) a→E(a)
全同态性,意味着可基于密文做加法、减法和乘法运算:
- 加法: Addition: E ( a ) , E ( b ) → E ( a + b ) \text{Addition:}~E(a),~E(b)\rightarrow E(a+b) Addition: E(a), E(b)→E(a+b)
- 减法: Subtraction: E ( a ) , E ( b ) → E ( a − b ) \text{Subtraction:}~E(a),~E(b)\rightarrow E(a-b) Subtraction: E(a), E(b)→E(a−b)
- 乘法: Multiplication: E ( a ) , E ( b ) → E ( a × b ) \text{Multiplication:}~E(a),~E(b)\rightarrow E(a \times b) Multiplication: E(a), E(b)→E(a×b)
当明文为二进制位(0和1)时,可使用FHE来表示所有二进制逻辑门。包括XOR和AND这样的基础门,因其构成了FHE中任意二进制逻辑运算的基础:
- XOR: E ( a ) , E ( b ) → E ( a + b − a × b ) \text{XOR:}~E(a),~E(b)\rightarrow E(a + b - a \times b) XOR: E(a), E(b)→E(a+b−a×b)
- AND: E ( a ) , E ( b ) → E ( a × b ) \text{AND:}~E(a),~E(b)\rightarrow E(a \times b) AND: E(a), E(b)→E(a×b)
由于其可表示所有二进制门,FHE可执行bounded size内的任意计算。在区块链应用中,FHE因在去中心化金融(DeFi)应用中实现隐私而引起了极大的兴趣。例如,在隐私增强的去中心化交易所(DEX)中,FHE可以秘密地为自动做市商(AMM)处理计算。
FHE的大部分计算开销归因于管理和减轻“噪声(noise)”。所有现有的FHE构建都依赖于learning-with error(LWE)假设或其变种——构成了这些密码学系统的基础。对于计算的每一步,输出——如 E ( a + b − a × b ) E(a+b-a\times b) E(a+b−a×b)——将比输入 E ( a ) E(a) E(a)和 E ( b ) E(b) E(b)具有更多的噪声,并且该输出可能成为后续步骤的输入。随着计算的进行,密文积累的噪声量越来越大。如下图所示,一旦密文中的噪声达到某个阈值,就会使密文不可解密。【下图摘自2021年Zama团队Marc Joye论文《Guide to Fully Homomorphic Encryption over the [Discretized] Torus》。】
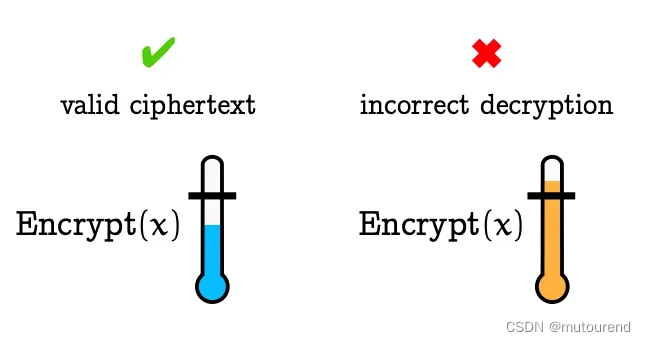
为促进FHE中的无限计算,必须找到一种在噪声变得过大之前清除噪声的方法。这种技术被称为“自举(bootstrapping)”——由Craig Gentry于2009年通过其关于FHE的开创性论文首次引入。bootstrapping包括使用FHE secret key的加密版本,通常被称为“bootstrapping key”,来解密并刷新有噪声的密文,这会产生包含相同数据但噪声较小的新密文。
可以想象,对于密文来说,FHE计算是一项非常累人的工作——就像马拉松一样,密文需要休息以避免“精疲力竭(burn out)”。如下图所示,将FHE bootstrapping看成是某人需要休息以避免在马拉松中精疲力尽。

在不同的全同态加密(FHE)算法中,TFHE引起了人们的极大关注,因为TFHE中的自举是有效的,并且TFHE非常适合于评估加密数据上的布尔电路。Zama、Fhenix、Inco都在使用TFHE。
因此,验证FHE的主要挑战在于准确地验证自举过程。在TFHE中,自举包括使用自举密钥根据被自举的密文“盲目地旋转(blindly rotate)”多项式,随后从这个旋转后的多项式中提取刷新的密文。
虽然这最初看起来像是对高级密码学的一次尝试,但值得注意的是,这个过程主要围绕着操作多项式和矩阵,如下图所示,其摘自2021年Zama团队Marc Joye论文《Guide to Fully Homomorphic Encryption over the [Discretized] Torus》。对于那些热衷于深入研究的人,我们强烈推荐Marc Joye关于TFHE的这本入门书,对于那些只对线性代数有基本了解的人来说,这本书很容易上手。

3. 何为RISC Zero?
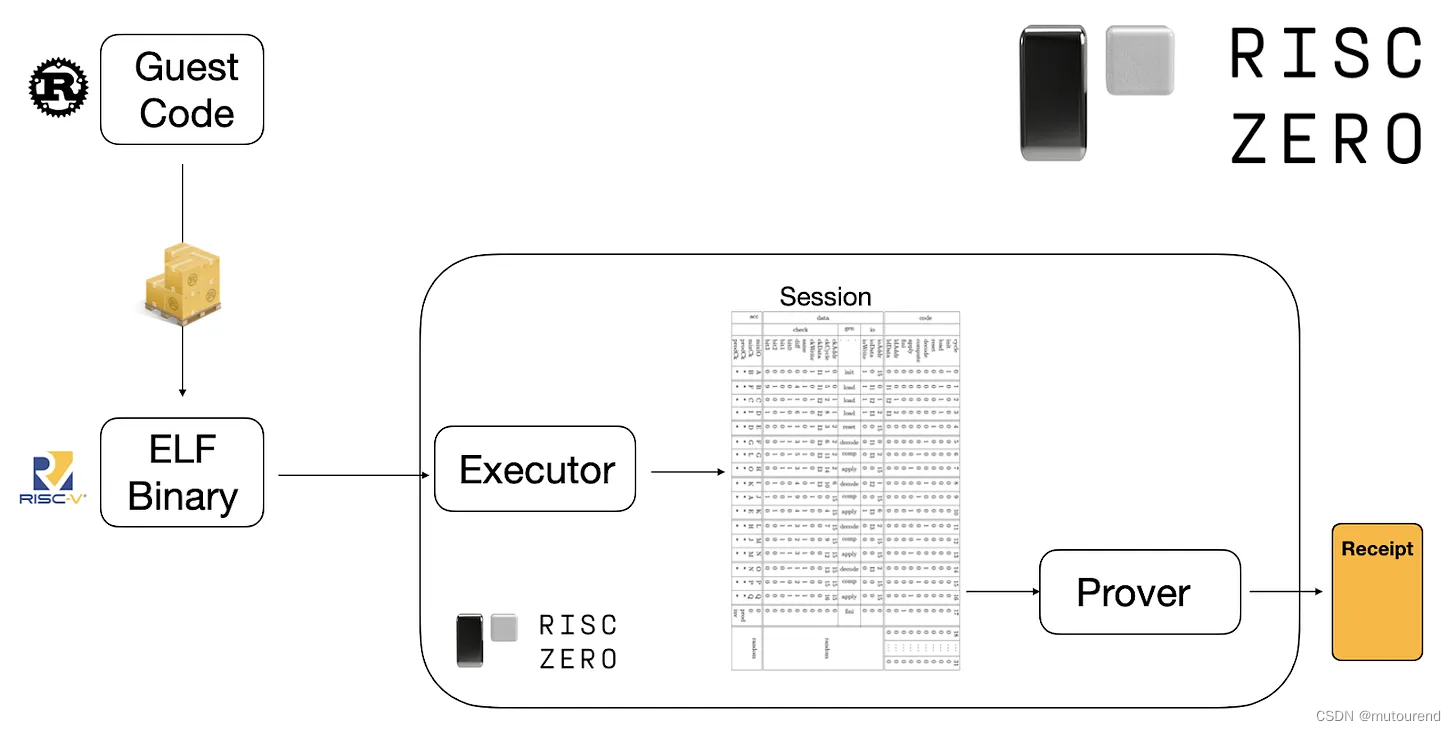
RISC Zero是专门为RISC-V体系结构设计的通用零知识证明系统。换句话说,任何可通过riscv32im(用于整数乘法和除法的,具有“M”扩展的RISC-V 32位)编译成ELF(executable and linkable format)程序的程序都与RISC Zero兼容。在VM执行时,RISC Zero生成该执行的零知识证明,称为“receipt”。具体如下图所示。
人们常问的一个问题是:RISC Zero为什么选择RISC-V而不是其它指令集?其主要原因有2方面:
- 1)RISC-V为简单通用指令集。RISC Zero仅需支持riscv32im中的如下46种指令:
相比于现代Intel x86的1131条指令,以及现代ARM的数百条指令,其要简单得多。同时,RISC-V也与其他极简主义指令集没有太大区别——MIPS(MIPS公司后来转型为RISC-V)、WASM和早期几代ARM,如ARMv4T。LB, LH, LW, LBU, LHU, ADDI, SLLI, SLTI, SLTIU, XORI, SRLI, SRAI, ORI, ANDI, AUIPC, SB, SH, AW, ADD, SUB, SLL, SLT, SLTU, XOR, SRL, SRA, OR, AND, MUL, MULH, MULSU, MULU, DIV, DIVU, REM, REMU, LUI, BEQ, BNE, BLT, BGE, BGEU, JALR, JAL, ECALL, EBREAK - 2)由于有LLVM,很容易将各种语言编译为RISC-V。
LLVM是一个编译工具链,它实现了后端(“ISAs”)和前端(“编程语言”)之间的中间层(称为“intermediate representation(IR)”)。由于RISC-V是支持的后端之一,LLVM允许将许多前端(包括C、C++、Haskell、Ruby、Rust、Swift等)编译成RISC-V。
见Chris Lattner书籍The Architecture of Open Source Applications (Volume 1) LLVM,LLVM的3阶段设计实现,其中RISC-V也是可用的LLVM后端之一。
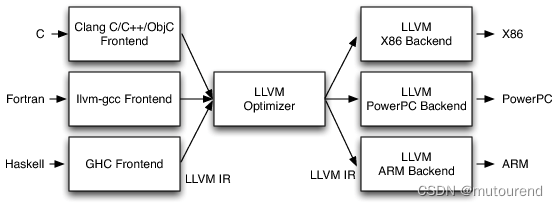
换句话说,通过自下而上的方法,RISC Zero:
- 能够支持使用现有的Web2编程语言编写的程序。
- 还能针对ZKP domain-specific language(DSL),如ZoKrates、Cairo、Noir和Circom,并创建一个编译器将它们转换为RISC-V。
对于直接编译到RISC-V困难的DSL语言,另一种方法是首先将DSL编译成像C/C++这样的中间语言,然后使用现有的LLVM编译器最终转换到RISC-V。
人们会问的另一个问题是,尽管RISC-V是一个有利的选择,为什么以虚拟机方式启动?难道不能在现有的ZK-specific DSL中编写“约束系统”吗,比如ZoKrates、Cairo、Noir和Circom?
主要原因有二:
- 1)使用RISC Zero可大幅降低开发时长。
传统上,为ZKP构建约束系统是一项艰巨的任务,只有熟练的开发人员才能完成,而且可能需要数周时间。更糟糕的是,调试约束系统可能需要更长的时间,而且很难确保约束系统没有错误。这是限制零知识证明的开发和采用的因素之一,因为它很难构建应用程序。
对于建立验证比特币或以太坊历史的historical proofs,或者在零知识的情况下证明某AI的输出,这些曾经是雄心勃勃的创业项目。现在,有了RISC Zero,曾经雄心勃勃的努力即使作为一个黑客马拉松项目也变得可行。例如,验证Zama的FHE——一个非常复杂的应用程序,以前从来没有人为它编写过ZKP约束系统——可以在RISC Zero中用几行代码完成。
这种转变也简化了招聘开发人员的过程。一个有过Rust经验的人可以很容易地将现有的Rust代码迁移到RISC Zero中,而这个人甚至不需要很多Rust知识。 - 2)RISC Zero甚至可能在某些方面超过人类的性能。RISC Zero的关键优势在于,它经过专门优化,可以进行32位和64位整数计算,还可以管理大型存储和内存,即使是熟练的ZKP工程师也无法击败它。
在RISC Zero之前,执行这样的优化需要顶尖的ZKP研究人员和工程师,因为这样的技术是最新的,从未被记录在案。优化至少需要几个月的时间来开发,因为它可能需要最有创意地使用lookup arguments。
RISC Zero已将这些尖端技术封装到其Bonsai框架中,使其既可访问又可负担。如果密码学就像烹饪,那么RISC Zero就是一个微波炉。
接下来将探讨如何利用RISC Zero以零知识验证Zama的FHE计算。看起来,所需要的只是重用Zama团队的一些代码,然后添加几行代码。
4. 以RISC Zero来验证Zama的FHE计算
4.1 验证FHE密文的bootstrapping
首先,需展示如何来验证某FHE密文bootstrapping的主要步骤:
- 使用bootstrapping key来对多项式做“blind rotation”,具体如下:
#![no_main]
risc0_zkvm::guest::entry!(main);// load the toy FHE Rust library from Louis Tremblay Thibault (Zama)
use ttfhe::{N,ggsw::{cmux, GgswCiphertext},glwe::GlweCiphertext,lwe::LweCiphertext
};// load the bootstrapping key and the ciphertext to be bootstrapped
static BSK_BYTES: &[u8] = include_bytes_aligned!(8, "../../../bsk");
static C_BYTES: &[u8] = include_bytes_aligned!(8, "../../../c");pub fn main() {// a zero-copy trick to load the key and the ciphertext into RISC Zerolet bsk = unsafe {std::mem::transmute::<&u8, &[GgswCiphertext; N]>(&BSK_BYTES[0])};let c = unsafe {std::mem::transmute::<&u8, &LweCiphertext>(&C_BYTES[0])};// initialize the polynomial to be blindly rotatedlet mut c_prime = GlweCiphertext::trivial_encrypt_lut_poly(); c_prime.rotate_trivial((2 * N as u64) - c.body);// perform the blind rotationfor i in 0..N {c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));}eprintln!("test res: {}", c_prime.body.coefs[0]);
}
以上代码中,除加载依赖或常量数据等trivial操作代码行之外,实际的关键代码仅5行——包括多项式的初始化及其blindly rotating:
let mut c_prime = GlweCiphertext::trivial_encrypt_lut_poly();
c_prime.rotate_trivial((2 * N as u64) - c.body);for i in 0..N {c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));
}
执行FHE steps的关键函数和算法,均源自Zama团队Louis Tremblay Thibault所开发https://github.com/tremblaythibaultl/ttfhe/ Rust库,具体关键函数和算法有:
trivial_encrypt_lut_polyrotate_trivialcmux
使用RISC Zero,可为该RISC-V程序的执行生成proof。RISC Zero的如下代码会执行该RISC-V程序(为ELF格式的可执行文件),并生成认证该执行的proof(称为“receipt”):
let env = ExecutorEnv::builder().build().unwrap();
let prover = default_prover();let receipt = prover.prove_elf(env, METHOD_NAME_ELF).unwrap();
receipt.verify(METHOD_NAME_ID).unwrap();
可将receipt发送给第三方,第三方可验证该RISC-V程序的执行情况,而无需访问其详细工作。对于需要更紧凑证明格式的情况,RISC Zero还能够生成succinct proof,在更简洁的同时保留其可验证性。
4.2 验证FHE(VFHE)
以Zama团队Louis Tremblay Thibault所开发https://github.com/tremblaythibaultl/ttfhe/ toy FHE Rust库为例,来演示如何使用RISC Zero来验证FHE。选择这个库的原因有二:
- 1)其非常接近于Zama生产fhEVM中所使用的库
- 2)其以Rust编写,便于直接编译到RISC-V。
该toy FHE Rust库是极简主义的——它只有6个文件,包含800行代码——但它完全支持将使用的三种不同类型的FHE密文:
- 1)LWE密文(lwe.rs):其结构为1024个64位整数组成的向量。
- 2)General LWE(GLWE)密文(glwe.rs):其结构也是1024个64位整数组成的向量。
- 3)General Gentry–Sahai–Waters(GGSW)密文(ggsw):其结构为由64位整数组成的size为 4 × 1024 4\times 1024 4×1024的矩阵。
这就足以启动使用RISC Zero的开发,因为主要需求是一个高效的Rust实现,其可无缝编译到RISC-V。Louis Tremblay Thibault已经在VFHE库中开发了这些概念的初步版本(https://github.com/tremblaythibaultl/vfhe),作为基本出发点:
#![no_main]
use risc0_zkvm::guest::env;
use ttfhe::{ggsw::BootstrappingKey, glwe::GlweCiphertext, lwe::LweCiphertext};
risc0_zkvm::guest::entry!(main);pub fn main() {// bincode can serialize `bsk` into an blob that weighs 39.9MB on disk.// This `env::read()` call doesn't seem to stop - memory is allocated until the process goes OOM.let (c, bsk): (LweCiphertext, BootstrappingKey) = env::read();let lut = GlweCiphertext::trivial_encrypt_lut_poly();// `blind_rotate` is a quite heavy computation that takes ~2s to perform on a M2 MBP.// Maybe this is why the process is running OOM?let blind_rotated_lut = lut.blind_rotate(c, &bsk);let res_ct = blind_rotated_lut.sample_extract();env::commit(&res_ct);
}
不过,在上述代码的注释中,明确指出了其存在的2个主要问题:
- 1)第一个问题与数据加载有关。当前面临着一个尚未解决的挑战,即如何有效地将自举密钥和密文加载到RISC-V程序中,因二者size可能很大。
Louis的方法是使用RISC Zero的env::readchannel,这是在proof生成期间将数据从外部输入RISC-V机器的标准方法。然而,正如Louis所指出的,这种方法并不是最优的,主要是由于其显著的内存需求和仅用于数据加载所需的大量VM CPU周期,导致了内存不足(OOM)问题。RISC Zero的Parker Thompson承认,这可能是问题的根源:“通常,向client读取大块数据的成本相当高。”
作为避免这种数据加载开销的初步解决方案,建议将数据直接嵌入RISC-V程序中。在Rust中,一个典型的解决方案为使用include_bytes_aligned!宏,指示编译器将数据集成到RISC-V可执行文件中。随后,可从byte反序列化这些数据,例如,使用bincode::deserialize。代码如下所示:
然而,重大挑战,源自,RISC-V程序为整个64MB自举密钥分配内存和复制数据所需的大量cycles。基准测试表明,仅证明密钥的正确加载就需要至少2个小时。static BSK_BYTES: &[u8] = include_bytes_aligned!(8, ("../../../bsk"); let bsk: BootstrappingKey = bincode::deserialize(BSK_BYTES);
本文揭示了RISC zero中解决这个问题的“零拷贝(zero-copy)”技巧。它允许实现几乎零CPU周期的自举密钥。本文将深入研究这项技术的细节。 - 2)第二个主要问题涉及计算。正如Louis对代码所评论的那样,blind rotation盲旋转(这是自举的主要步骤)的效率可能是一个问题,因为它本身不是一个轻量级的计算(“在M2 MBP上执行需要2秒”)。这是整个“在RISC Zero中验证FHE”的更大挑战。
L2IV Research团队在RISC Zero中设计并实现了许多技巧和技术来优化这一部分。在RISC Zero中优化FHE计算的过程是广泛的,计划在本系列中专门发表几篇文章来彻底解释每种技巧和技术。
4.2.1 加载大量数据的zero-copy trick
L2IV Research团队深入研究了克服RISC-V程序中数据加载挑战的方法,强调了显著减少RISC-V CPU周期的方法。
核心思想是避免在RISC-V中复制数据。这一点至关重要,因为在RISC-V中复制64MB的数据集将需要超过5000万条指令——一条指令读取数据,一条指令写入数据,以及一条指令更新指针。所有这些指令在某种程度上都是不必要的,因为Rust编译器已经将数据作为RISC-V程序的一部分包含在内,因此数据已经可用。
由于其固有的内存安全设计,在Rust中实现这一点具有挑战性。Rust中的标准实践涉及通过一个严格的过程初始化数据结构:在stack或heap中分配数据结构,将数据结构的内存归零(通过在整个内存中学以致用地填充零),然后一个接一个地复制数据。可以看出,Rust在计算周期上的花费甚至更大,因为将内存归零至少需要另外3400万条指令。
L2IV Research团队的解决方案采用了某些低级Rust原语,能够“绕过”Rust LLVM编译器施加的限制,从而更有效地编程RISC-V。
在与Greater Heat合作进行Aleo mining的过程中,学到了一项有价值的技术,涉及std::mem::transmite。这是一个特殊的Rust函数,可以将一种类型的bits重新解释为另一种类型。特别是,它可以用来修改指针的类型。
在本应用中,可直接在RISC-V文件中显式地嵌入(或者更准确地说,硬编码)自举密钥(BSK_bytes)和要自举的密文(C_bytes。为了避免复制数据,可直接操作指针的类型,如下所示:
let bsk = unsafe { std::mem::transmute::<&u8, &[GgswCiphertext; N]>(&BSK_BYTES[0])
}; let c = unsafe { std::mem::transmute::<&u8, &LweCiphertext>(&C_BYTES[0])
};
如前一段代码所示,获得了指向硬编码数据的ELF段指针,最初是一个字节指针(&u8)。然后,将其转换为指向自举密钥的指针(&[GgswCiphertext; N])或指向LWE密文的指针(&LweCiphertext)。此外,有必要将此代码封装在“不安全”括号中,因为Rust将此低级函数归类为不安全,并要求通过不安全明确承认其潜在风险。这种不安全的使用本身并不意味着危险;相反,这意味着需要专门的专业知识来处理这种低级操作。
对于熟悉C/C++的人来说,这个过程可以比作typecasting。在C/C++中,等效代码如下所示:
/* C */
BootstrappingKey *bsk = (BootstrappingKey*) &BSK_BYTES[0];
LweCiphertext *c = (LweCiphertext*) &C_BYTES[0];/* C++ */
BootstrappingKey *bsk = reinterpret_cast<BootstrappingKey*>(&BSK_BYTES[0]);
LweCiphertext *c = reinterpret_cast<LweCiphertext*>(&C_BYTES[0]);
实验结果表明,使用这种方法实际上消除了数据加载通常需要的cycles数。后续分析将通过使用RISC-V反编译器进一步验证这种零拷贝操作。
5. RISC-V一览
L2IV Research团队已经解决了来自Zama的Louis在使用RISC Zero进行FHE自举验证时遇到的最初挑战。在本系列即将发表的文章中,将深入探讨性能改进及其细微差别这一主题。
本节关注,使用RISC-V反编译器在零知识上下文中检查RISC Zero所验证的程序。目标有两个:
- 1)确认L2IV Research团队的技术在RISC-V汇编级别上有效地实现了零拷贝。
- 2)全面了解RISC-V程序的总体结构。
为此,使用https://github.com/NationalSecurityAgency/ghidra——由US National Security Agency (NSA)开发的全面、免费使用的逆向工程框架,其支持RISC-V。
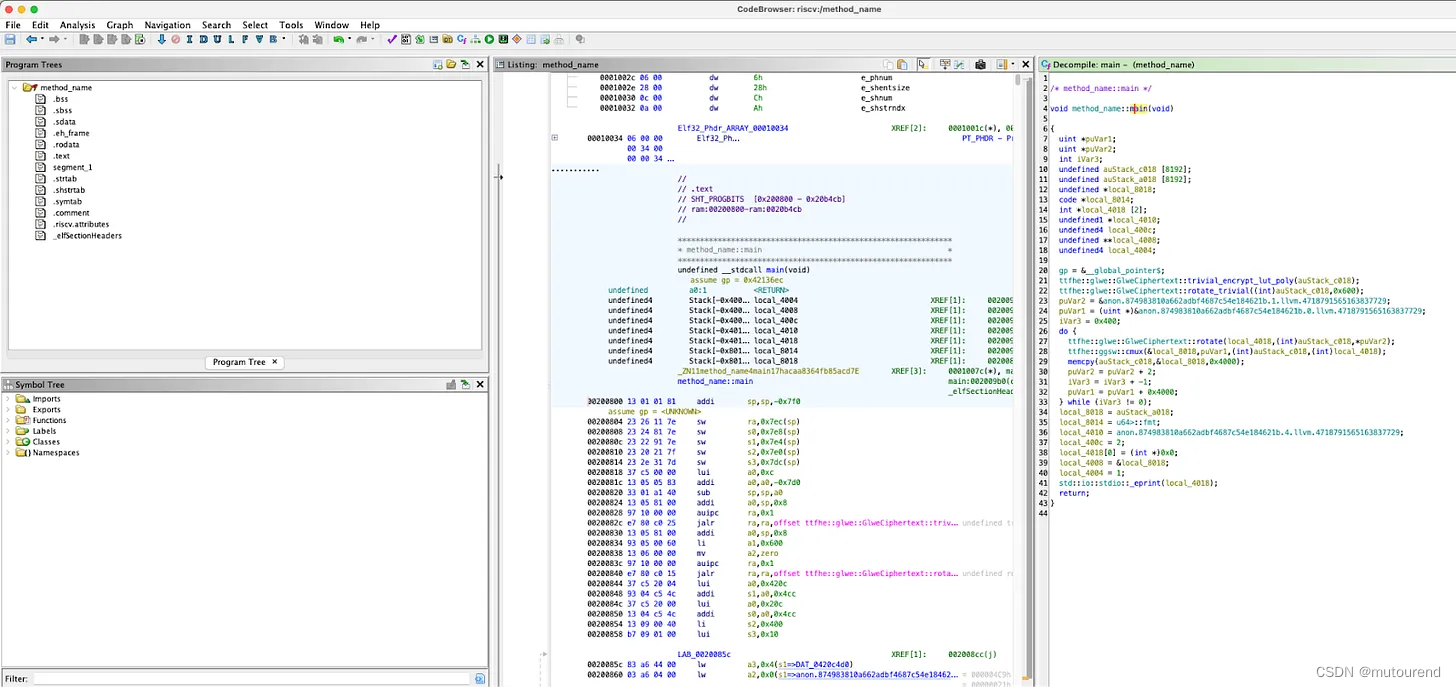
上图展示了对RISC Zero所证明的RISC-V程序的Ghidra CodeBrowser。
Ghidra同时支持:
- 展示RISC-V汇编代码,见上图中间窗格。
- 以及反编译的代码(以C表示)——见上图右侧窗格。回顾之前提到的RISC-V的46条指令,值得注意的是,正在分析的汇编代码使用了这些精确的指令。
先专注于自动生成的反编译代码,如下所示:
/* method_name::main */void method_name::main(void){uint *puVar1;uint *puVar2;int iVar3;undefined auStack_c018 [8192];undefined auStack_a018 [8192];undefined *local_8018;code *local_8014;int *local_4018 [2];undefined1 *local_4010;undefined4 local_400c;undefined **local_4008;undefined4 local_4004;gp = &__global_pointer$;ttfhe::glwe::GlweCiphertext::trivial_encrypt_lut_poly(auStack_c018);ttfhe::glwe::GlweCiphertext::rotate_trivial((int)auStack_c018,0x600);puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;iVar3 = 0x400;do {ttfhe::glwe::GlweCiphertext::rotate(local_4018,(int)auStack_c018,*puVar2);ttfhe::ggsw::cmux(&local_8018,puVar1,(int)auStack_c018,(int)local_4018);memcpy(auStack_c018,&local_8018,0x4000);puVar2 = puVar2 + 2;iVar3 = iVar3 + -1;puVar1 = puVar1 + 0x4000;} while (iVar3 != 0);local_8018 = auStack_a018;local_8014 = u64>::fmt;local_4010 = anon.874983810a662adbf4687c54e184621b.4.llvm.4718791565163837729;local_400c = 2;local_4018[0] = (int *)0x0;local_4008 = &local_8018;local_4004 = 1;std::io::stdio::_eprint(local_4018);return;
}
初步可确认,其数据加载流程确实实现了zero-copy efficiency。该代码片段使用std::mem::transmute来将数据加载编译进16-byte sequence of RISC-V machine codes:
37 c5 20 04 93 04 c5 4c 37 c5 20 00 13 04 c5 4c
反编译展示了4条汇编指令,负责将指针值存储到s1和s0寄存器中。本质上,该代码分配0x420c4cc值给s1寄存器,分配0x020c4cc值给s0寄存器:
00200844 37 c5 20 04 lui a0,0x420c00200848 93 04 c5 4c addi s1,a0,0x4cc0020084c 37 c5 20 00 lui a0,0x20c00200850 13 04 c5 4c addi s0,a0,0x4cc
可进一步将该汇编代码反编译为C类似格式,以有更清晰的理解,如下所示:
uint *puVar1;
uint *puVar2;puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;
puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;
在该反编译代码中,首个label anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729 明确指出了密文字节的位置,表示为C_BYTES。利用Ghidra,可直接观察该代码中的这些密文字节:

上图,展示了0x420c4cc位置的ELF可执行文件的数据,即s1寄存器的初始值,用于待自举的密文。
C_BYTE包含在名为"c"的文件中。通过使用Hex Fiend,一种用于十六进制编辑的工具,可检查该文件的内容。如下所述,检查确认了数据的一致性。
static C_BYTES: &[u8] = include_bytes!("../../../c");

如上十六进制编辑器中所示,"c"文件中存储了待自举的密文。
类似地,对第二个label——anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729,可定位对应自举密钥的字节,称为BSK_BYTES。
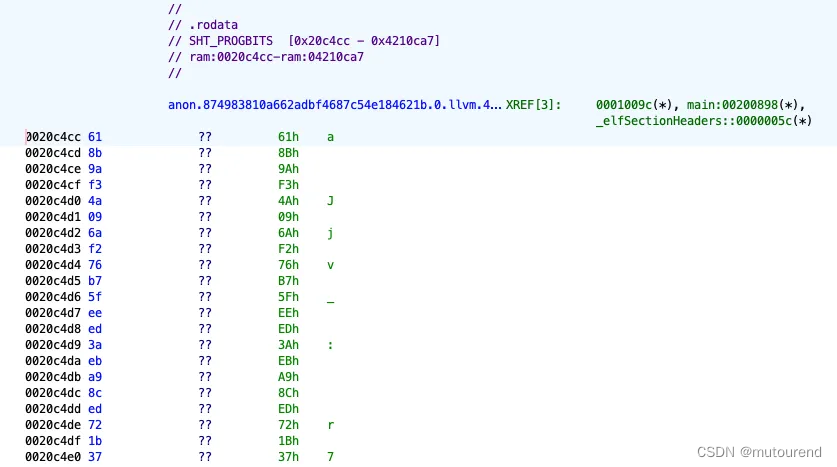
上图,展示了0x020c4cc位置的ELF可执行文件的数据,即s0寄存器的初始值,用于自举密钥。
此外,可通过将该数据与其源文件“bsk”进行交叉检查来验证该数据,确保其与上述信息一致。
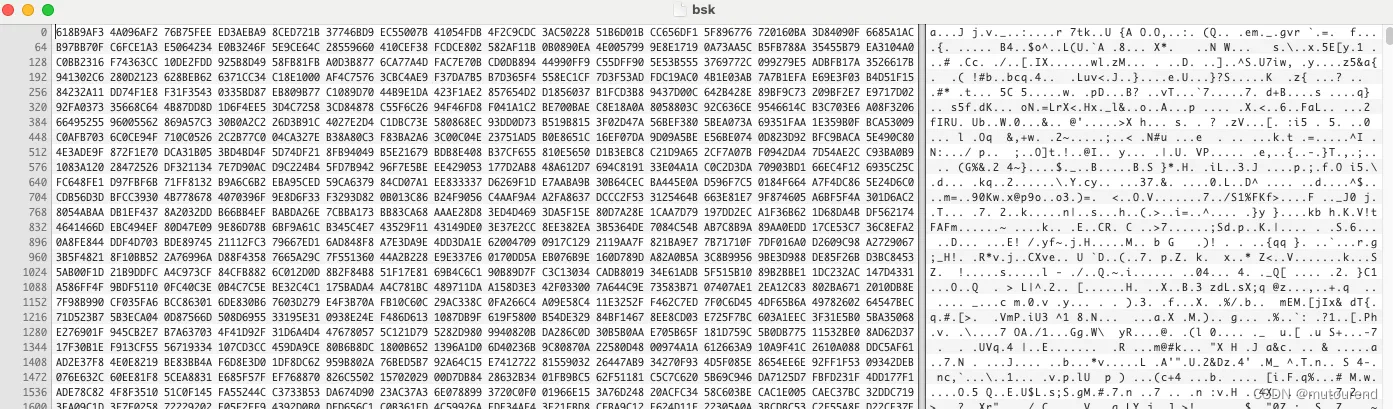
上图,在十六进制编辑器中,展示了“bsk”文件中存储了该自举密钥。
接下来,将展示如何在程序中使用该自举密钥和密文。Rust源代码中,通过明确调用cmux函数,在for循环中同时集成该自举密钥和密文:
// perform the blind rotation
for i in 0..N {c_prime = cmux(&bsk[i], &c_prime, &c_prime.rotate(c.mask[i]));
}
然后,借助Ghidra来定位并检查相应的反编译代码:
puVar2 = &anon.874983810a662adbf4687c54e184621b.1.llvm.4718791565163837729;
puVar1 = (uint *)&anon.874983810a662adbf4687c54e184621b.0.llvm.4718791565163837729;
iVar3 = 0x400;
do {ttfhe::glwe::GlweCiphertext::rotate(local_4018,(int)auStack_c018,*puVar2);ttfhe::ggsw::cmux(&local_8018,puVar1,(int)auStack_c018,(int)local_4018);memcpy(auStack_c018,&local_8018,0x4000);puVar2 = puVar2 + 2;iVar3 = iVar3 + -1;puVar1 = puVar1 + 0x4000;
} while (iVar3 != 0);
该反编译代码中包含不同组件:
- 1)Cursor Assignments:puVar2用作指向c的当前指针,而puVar1为指向bsk的当前指针。此设置便于通过密文和自举密钥进行导航。
- 2)Loop Mechanics:该循环使用iVar3作为从1024的自减计数器,当其值为0时接收循环。在每个迭代过程中,会做如下操作:
- 2.1)Ciphertext Manipulation:c_prime,存储在stack的auStack_c018中,首先与 c.mask[i](称为 *puVar2) rotate生成的结果存于local_4018中。
- 2.2)
cmuxFunction Invocation:cmux关键函数,以bsk[i] (puVar1)、原始c_prime、和已旋转的c_prime 为输入,输出的结果到local_8018中。 - 2.3)Optimization Opportunity:一个有趣的方面是local_8018的处理,它被视为更新的c_prime。它被复制回c_prime变量中,暗示潜在的优化。通过就地执行
cmux消除此拷贝可以提高效率。 - 2.4)Cursor Updates:该循环包含同时更新puVar2和puVar1。puVar2向前移动两个dwords(64位)到下一个c.mask[i],而puVar1向前移动16384个dwords(524288位)到随后的bsk[i]。
当iVar3值为0时,以上循环结束,这些steps共同表示在RISC-V程序中处理FHE自举的过程。
使用Ghidra的进一步分析能够仔细审查该计划的其他部分,从而深入了解潜在的优化机会。这个过程有助于评估Rust RISC-V编译器是否按预期生成RISC-V指令。
如,检查cmux函数的反编译代码。为了提供上下文,将首先考虑原始的Rust代码,如下所示:
/// Ciphertext multiplexer. If `ctb` is an encryption of `1`, return `ct1`. Else, return `ct2`.
pub fn cmux(ctb: &GgswCiphertext, ct1: &GlweCiphertext, ct2: &GlweCiphertext) -> GlweCiphertext {let mut res = ct2.sub(ct1);res = ctb.external_product(&res);res = res.add(ct1);res
}
其反编译代码表明,对“sub”和“add”的函数调用在编译过程中被有效地内联了。这种内联在代码中产生可见的循环,这些循环负责模拟64位整数运算。此外,该代码还使用了对memset和memcpy的几个调用。值得注意的是,memset的一些实例用于归零内存,这可能并不总是必要的。这一观察结果开辟了潜在的优化途径,特别是在消除不必要的memset调用方面。
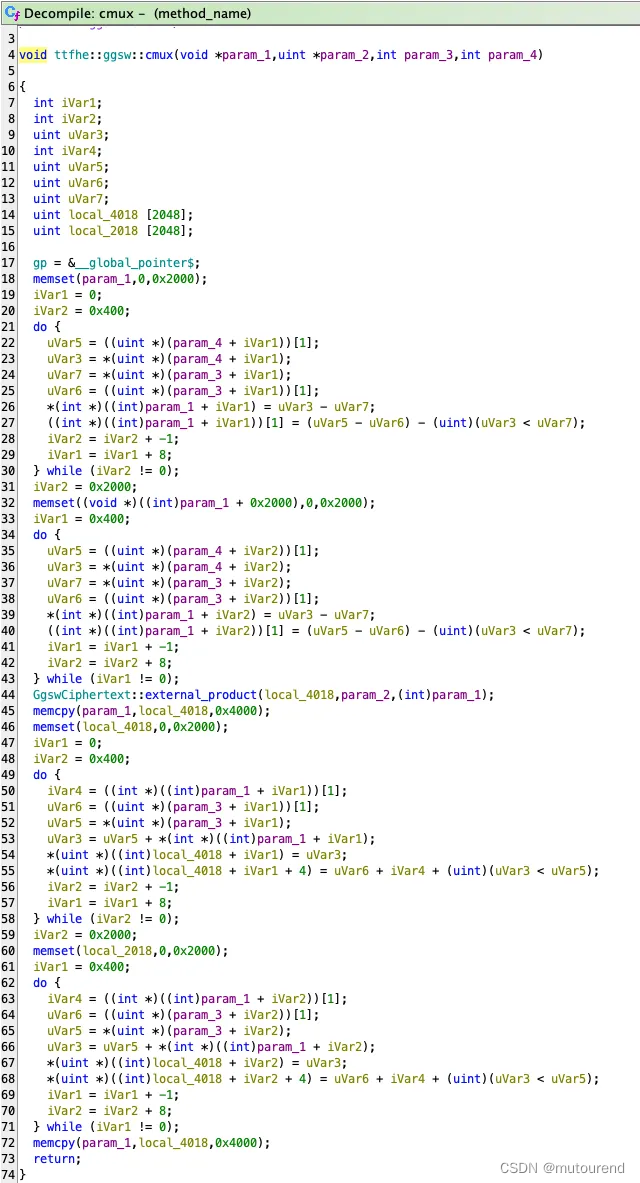
上图展示了cmux函数的反编译RISC-V指令代码。
参考资料
[1] L2IV Research团队2023年11月16日博客 Tech Deep Dive: Verifying FHE in RISC Zero, Part I:From Hidden to Proven: The ZK Path of FHE Validation
RISC Zero系列博客
- RISC0:Towards a Unified Compilation Framework for Zero Knowledge
- Risc Zero ZKVM:zk-STARKs + RISC-V
- 2023年 ZK Hack以及ZK Summit 9 亮点记
- RISC Zero zkVM 白皮书
- Risc0:使用Continunations来证明任意EVM交易
- Zeth:首个Type 0 zkEVM
- RISC Zero项目简介
- RISC Zero zkVM性能指标
- Continuations:扩展RISC Zero zkVM支持(无限)大计算
- A summary on the FRI low degree test前2页导读
- Reed-Solomon Codes及其与RISC Zero zkVM的关系
- RISC Zero zkVM架构
- RISC-V与RISC Zero zkVM的关系
- 有限域的Fast Multiplication和Modular Reduction算法实现
- RISC Zero的Bonsai证明服务
- RISC Zero ZKP协议中的商多项式
- FRI的Commit、Query以及FRI Batching内部机制
- RISC Zero的手撕STARK
- RISC Zero zkVM guest程序优化技巧 及其 与物理CPU的关键差异
- ZK*FM:RISC Zero zkVM的形式化验证
- Zirgen MLIR:RISC-Zero的ZK-circuits形式化验证
- 以RISC Zero ZK Fraud Proof赋能Optimistic Rollups
- zkSummit10 亮点记






![[C语言]大小端及整形输出问题](https://img-blog.csdnimg.cn/direct/b686faa76d764bc880fff886aa9748cc.png)