每周一期,纵览音视频技术领域的干货。
新闻投稿:contribute@livevideostack.com。

467亿参数MoE追平GPT-3.5!爆火开源Mixtral模型细节首公开,中杯逼近GPT-4
今天,Mistral AI公布了Mixtral 8x7B的技术细节,不仅性能强劲,而且推理速度更快!还有更强型号的Mistral-medium也已开启内测,性能直追GPT-4。
8x7B开源MoE击败Llama 2逼近GPT-4!欧版OpenAI震惊AI界,22人公司半年估值20亿
前几日,一条MoE的磁力链接引爆AI圈。刚刚出炉的基准测试中,8*7B的小模型直接碾压了Llama 2 70B!网友直呼这是初创公司版的超级英雄故事,要赶超GPT-4只是时间问题了。有趣的是,创始人姓氏的首字母恰好组成了「L.L.M.」。
深度学习大牛权威预测2024年AI行业热点,盘点开源AI趋势!
AI社区大佬Sebastian总结了2023年全年AI行业的热点和问题,针对开源社区和AI研究的热点问题给出了自己读到的解读和发展建议,精彩内容千万不能错过。
将Transformer用于扩散模型,AI 生成视频达到照片级真实感
在视频生成场景中,用 Transformer 做扩散模型的去噪骨干已经被李飞飞等研究者证明行得通。这可算得上是 Transformer 在视频生成领域取得的一项重大成功。

随意指定CLIP关注区域!上交复旦等发布Alpha-CLIP:同时保持全图+局部检测能力
本文介绍了一个名为Alph-CLIP的框架,它在原始的接受RGB三通道输入的CLIP模型的上额外增加了一个alpha通道。在千万量级的RGBA-region的图像文本对上进行训练后,Alpha-CLIP可以在保证CLIP原始感知能力的前提下,关注到任意指定区域。通过替换原始CLIP的应用场景,Alpha-CLIP在图像识别、视觉-语言大模型、2D乃至3D生成领域都展现出强大作用。
一套参数,狂揽160个SOTA!厦大等重磅开源「视觉感知基础模型」APE
由厦门大学等机构提出的全新视觉感知基础模型APE,只需一个模型外加一套参数,就能在160个测试集上取得当前SOTA或极具竞争力的结果。而且训练和推理代码以及模型权重全部开源,无需微调,开箱即用。
矩阵模拟!Transformer大模型3D可视化,GPT-3、Nano-GPT每一层清晰可见
Transformer大模型工作原理究竟是什么样的?一位软件工程师打开了大模型的矩阵世界。
全方位、无死角的开源,邢波团队LLM360让大模型实现真正的透明
开源模型正展现着它们蓬勃的生命力,不仅数量激增,性能更是愈发优秀。图灵奖获得者 Yann LeCun 也发出了这样的感叹:「开源人工智能模型正走在超越专有模型的路上。
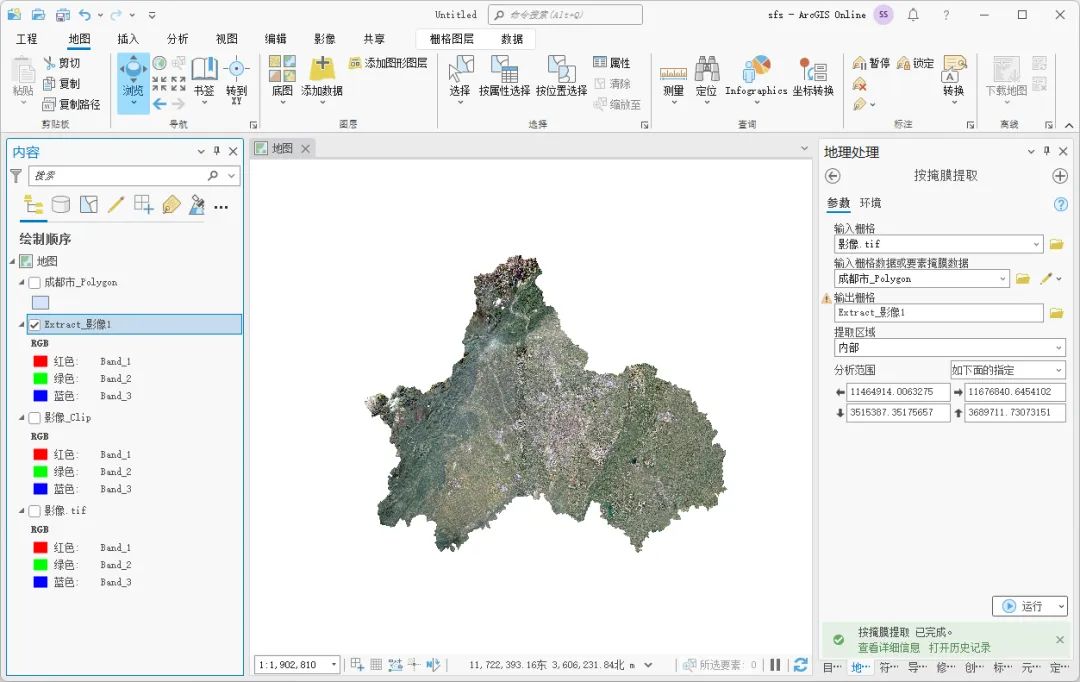
AI新范式下,阿里云视频云大模型算法实践
在AI技术发展如火如荼的当下,大模型的运用与实践在各行各业以千姿百态的形式展开。音视频技术在多场景、多行业的应用中,对于智能化和效果性能的体验优化有较为极致的要求。如何运用好人工智能提升算法能力,解决多场景业务中的具体问题,需要创新地探索大模型技术及其应用方式。LiveVideoStackCon2023深圳站邀请到阿里云智能高级算法专家刘国栋,为我们介绍阿里云视频云的大模型算法实践。

TUM、Snap开源! 基于扩散先验,生成高质量室内场景!
SceneTex,该方法使用深度到图像的扩散先验来有效地为室内场景生成高质量和风格一致的纹理。与以前的方法不同,SceneTex在没有精确的几何和风格线索的情况下,迭代地将2D视图变形到网格表面或蒸馏扩散潜在特征,将纹理合成任务描述为RGB空间中的优化问题,其中风格和几何一致性得到了适当的反映。
UIUC斯坦福等开源!解决因为各种遮挡导致的跟踪失败问题!
TrackDLO算法从一系列RGB-D图像中估计可变形线性物体(DLO)在遮挡情况下的形状。TrackDLO是仅依赖视觉信息的实时算法。它不需要来自物理建模、仿真、视觉标记或接触的外部状态信息作为输入。
详解|3D Gaussian Splatting:实时的神经场渲染
辐射场方法改变了多张照片或视频主导的场景新视角合成。Gaussian Splatting引入了三个关键元素,在保持有竞争力的训练时间的同时实现最先进的视觉质量,重要的是允许在1080p分辨率下实现高质量的实时(≥30 fps)的新视图合成。

FBEC2023 | ARknovv联合创始人阮郑福:AI助力AR创造性探索
FBEC2023未来商业生态链接大会暨第八届金陀螺奖于2023年12月8日在深圳福田大中华喜来登酒店6楼盛大召开,本次大会由广东省游戏产业协会、深圳市互联网文化市场协会指导,陀螺科技主办,中国光谷、游戏陀螺、VR陀螺、陀螺财经、陀螺电竞联合主办。
联想正式发布ThinkVision裸眼3D显示器;HTC VIVE与NuEyes为视障人群推出可穿戴XR解决方案
近日,在以“因思而变 智领未来”为主题的联想ThinkVision和ThinkCentre20周年纪念活动上,联想正式发布业内首款27英寸4K裸眼3D显示器——联想ThinkVision 27 3D。
利用Gaussian Splatting,Meta为Codec Avatar实现头部的高保真重照明
自出世以来便迅速吸引了业界的关注,3D Gaussian Splatting的主要优点是在保证高重建质量的同时支持传统光栅化,而且优化速度快速。自2019年正式公开介绍旨在创建图片真实感虚拟数字人的Codec Avatar项目以来,Meta就一直在积极探索各种优化方式。在日前公布的一项研究中,团队已经开始利用Gaussian Splatting来提升Avatar的逼真程度,主要涉及重照明。

ASML的困境:High NA太难了
近年来,光刻技术的“下一件大事”是高数值孔径极紫外(IE high-NA EUV),这是 ASML 光刻工具技术开发的下一个革命性步骤。High-NA 的宣传目标是降低工艺复杂性并能够扩展到 2nm 以上。在ASML看来,这将降低复杂性可以降低成本。
详解AWS Graviton4
在最近的亚马逊 AWS re:Invent 2023 上,该公司推出了第四代定制内部服务器处理器——Graviton4。该芯片由以色列 Annapurna Labs 开发,采用最新的 Arm Neoverse IP 以及主要旨在扩展和加速器连接改进的定制 IP。
WLCSP晶圆级芯片封装技术
WLCSP(Wafer Level Chip Scale Packaging)即晶圆级芯片封装方式,不同于传统的芯片封装方式(先切割再封测,而封装后至少增加原芯片20%的体积),此种最新技术是先在整片晶圆上进行封装和测试,然后才切割成一个个的IC颗粒,因此封装后的体积即等同IC裸晶的原尺寸。WLCSP的封装方式,不仅明显地缩小内存模块尺寸,而符合行动装置对于机体空间的高密度需求;另一方面在效能的表现上,更提升了数据传输的速度与稳定性。

I3C下一代接口技术
I2C与SPI历来是嵌入式设备领域的主流接口技术,特别是在成像传感器等设备的连接中。这些接口以其简易的实施和广泛的采用而闻名,但随着技术的深入发展和应用的专业化,它们在关键特性和性能上的局限性逐渐显现,这可能对高密度和精密度的系统设计构成挑战。
让3D编辑像PS一样简单!GaussianEditor:在几分钟内完成3D场景增删改!
3D 编辑在游戏和虚拟现实等领域中发挥着至关重要的作用,然而之前的 3D 编辑苦于耗时间长以及可控性差等问题,很难应用到实际场景。近日,南洋理工大学联合清华和商汤提出了一种全新的 3D 编辑算法 GaussianEditor,首次实现了在 2-7 分钟完成对 3D 场景可控的多样化的编辑,全面超越了之前的 3D 编辑工作。

SHCST2023 音频生成主题分享
本期分享卢恒老师在第三届SpeechHome语音技术研讨会的音频生成主题报告的内容《语音AIGC技术进展--音频技术在喜马拉雅的研发和落地应用》。
用于语言和方言识别的多语言语音模型的自监督自适应预训练
经过预训练的基于transformer的语音模型在对自动语音识别和口语识别(SLID)等各种下游任务进行微调时表现出惊人的性能。然而,域不匹配的问题仍然是该领域的一个挑战,其中预训练数据的域可能与用于微调的下游标记数据的域不同。在SLID等多语言任务中,预先训练的语音模型可能不支持下游任务中的所有语言。为了应对这一挑战,我们提出了自监督自适应预训练(SAPT),以使预训练模型适应下游任务的目标领域和语言。我们将SAPT应用于XLSR-128模型,并研究这种方法对SLID任务的有效性。
https://arxiv.org/abs/2312.07338
仅需30秒完美复刻任何人的声音 - 最强AI音频11Labs
ElevenLabs 简称11Labs ,在TTS(文字转音频)这个领域,当之无愧的“最强”。
如何使用更少的投入在研发阶段进行高级噪声源识别?
如今,法规和指令已对制造产品产生的噪声进行了多年管制;室外机械有最大的噪声级,电动汽车有最小的噪声级。

音视频问题汇总--非零frame_num值导致的一个绿屏问题
本周收到这样一个反馈的问题:我们的测试小姐姐通过自研RTSP客户端拉流过程时发现了一个较为困扰的问题。她注意到,在操作一款特定型号的IPC设备时,每次拉流都会出现首帧绿屏的情况。这个异常状况出现的频率和持续性都让人无法忽视,它在很大程度上影响了使用者的体验。
RTC技术|弹幕互动玩法方案&低延时传输引擎的体验优化
随着互联网技术的不断发展,直播不再只是主播的独角戏,而是一个充满实时互动的娱乐生态系统,其中直播弹幕互动玩法作为一种创新的方式正风靡直播平台。火山引擎融合云游戏服务的强大算力和RTC的先进音视频能力,助力抖音快速增量并拓展直播创新玩法。LiveVideoStackCon 2023 深圳站邀请了火山引擎的郭健,为大家分享弹幕互动玩法背后的探索和实践历程。

谷歌的自研芯片帝国
12月6日,谷歌官宣了了全新的多模态大模型 Gemini,包含了三个版本,根据谷歌的基准测试结果,其中的 Gemini Ultra 版本在许多测试中都表现出了“最先进的性能”,甚至在大部分测试中完全击败了 OpenAI 的 GPT-4。
据外媒报道,华为首家海外工厂已经确定落地法国!!!华为自研手机芯片的艰辛历程!!!
12月12日消息,据外媒报道,华为法国公司表示,华为首家海外工厂已经确定落地法国,预计2025年底投产!
微软小模型击败大模型:27亿参数,手机就能跑
上个月,微软 CEO 纳德拉在 Ignite 大会上宣布自研小尺寸模型 Phi-2 将完全开源,在常识推理、语言理解和逻辑推理方面的性能显著改进。

重磅首发|2024音视频技术发展报告(文末附下载)
11月24日,在LiveVideoStackCon 2023深圳站大会上,我们与腾讯云音视频联合首发《2024音视频技术发展报告》。报告通过300+音视频开发者调研,40+专家一线访谈,下沉8大细分技术领域进行全面解读,涵盖音视频编解码/AI编码/多媒体处理框架/媒体传输协议/超低延迟技术/虚拟现实/AIGC/出海等领域,深入洞察音视频技术现状和未来发展趋势。
▲点击“阅读原文”▲
跳转报告下载链接