重磅推荐专栏: 《大模型AIGC》;《课程大纲》
本专栏致力于探索和讨论当今最前沿的技术趋势和应用领域,包括但不限于ChatGPT和Stable Diffusion等。我们将深入研究大型模型的开发和应用,以及与之相关的人工智能生成内容(AIGC)技术。通过深入的技术解析和实践经验分享,旨在帮助读者更好地理解和应用这些领域的最新进展
VisualGLM
BLIP-2
https://arxiv.org/pdf/2301.12597.pdf
BLIP-2是一种用于视觉-语言预训练的方法,它利用了冻结的预训练图像编码器和大型语言模型。BLIP-2的核心架构是Querying Transformer(Q-Former),它经过两个阶段的预训练来弥合模态差距。
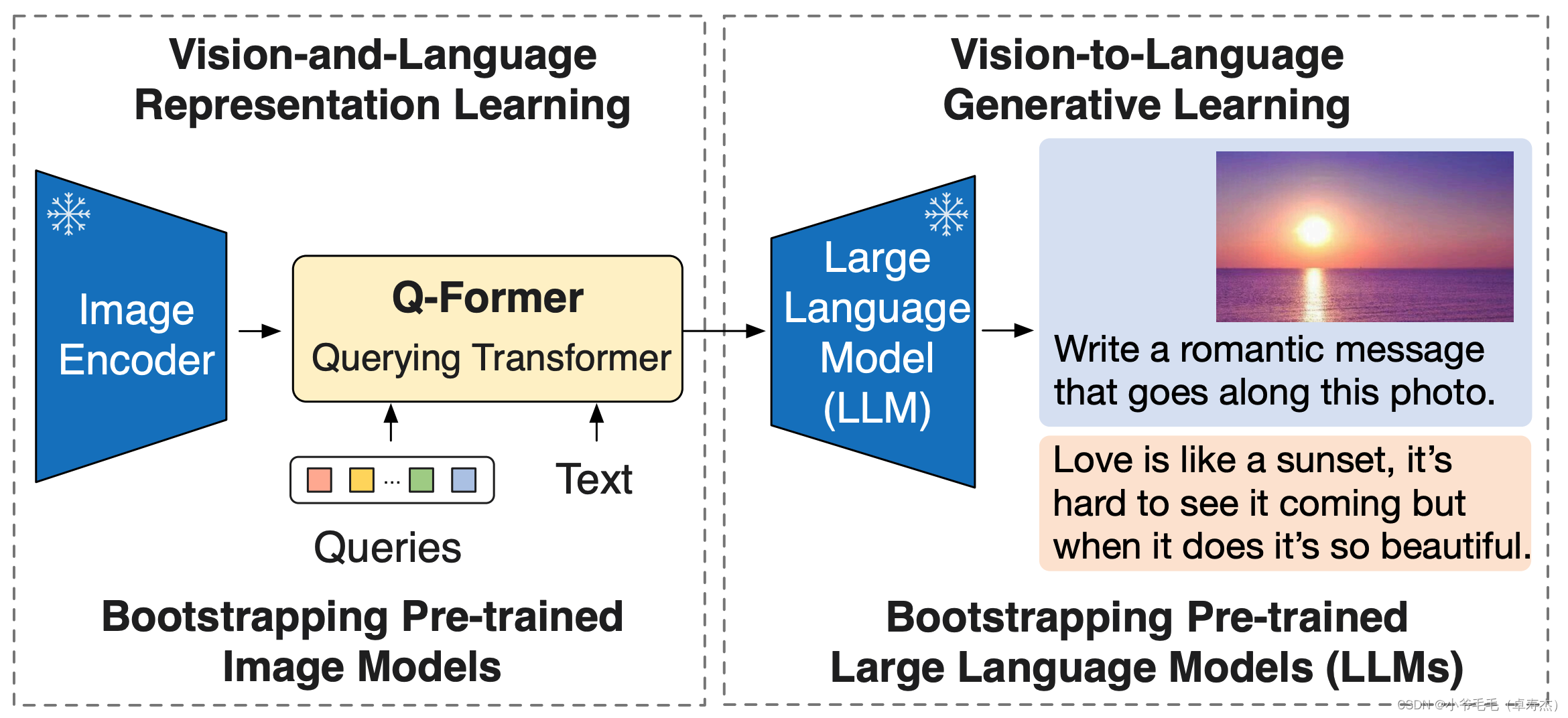
在第一个预训练阶段,Q-Former与一个冻结的图像编码器一起进行视觉-语言表示学习。这个阶段的目标是让Q-Former学习与文本最相关的视觉表示。通过与图像编码器的连接,Q-Former可以从冻结的图像编码器中获取视觉特征。
在第二个预训练阶段,Q-Former与一个冻结的语言模型进行视觉-语言生成学习。这个阶段的目标是让Q-







![[密码学]AES](https://img-blog.csdnimg.cn/direct/ba0b792076044a7a9b943b87d4526712.png)