Flink系列之:SQL提示
- 一、动态表选项
- 二、语法
- 三、例子
- 四、查询提示
- 五、句法
- 六、加入提示
- 七、播送
- 八、随机散列
- 九、随机合并
- 十、嵌套循环
- 十一、LOOKUP
- 十二、进一步说明
- 十三、故障排除
- 十四、连接提示中的冲突案例
- 十五、什么是查询块
SQL 提示可以与 SQL 语句一起使用来更改执行计划。本章解释如何使用提示来强制执行各种方法。
一般来说,提示可用于:
- 执行计划器:没有完美的计划器,因此实现提示以让用户更好地控制执行是有意义的;
- 附加元数据(或统计信息):一些统计信息,例如“扫描的表索引”和“某些洗牌键的倾斜信息”对于查询来说有些动态,使用提示配置它们会非常方便,因为我们来自规划器的规划元数据很多时候并不那么准确;
- 算子资源限制:在很多情况下,我们会给执行算子一个默认的资源配置,即最小并行度或托管内存(资源消耗UDF)或特殊资源要求(GPU或SSD磁盘)等等,这将非常灵活使用每个查询的提示(而不是作业)来分析资源。
一、动态表选项
动态表选项允许动态指定或覆盖表选项,与使用 SQL DDL 或连接 API 定义的静态表选项不同,这些选项可以在每个查询的每个表范围内灵活指定。
因此它非常适合用于交互式终端中的临时查询,例如,在 SQL-CLI 中,您可以通过添加动态选项 /*+ OPTIONS(’ 来指定忽略 CSV 源的解析错误csv.ignore-parse-errors’=‘true’) */。
二、语法
为了不破坏SQL兼容性,我们使用Oracle风格的SQL提示语法:
table_path /*+ OPTIONS(key=val [, key=val]*) */key:stringLiteral
val:stringLiteral
三、例子
CREATE TABLE kafka_table1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE kafka_table2 (id BIGINT, name STRING, age INT) WITH (...);-- 覆盖查询源中的表选项
select id, name from kafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */;-- 覆盖连接中的表选项
select * fromkafka_table1 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t1joinkafka_table2 /*+ OPTIONS('scan.startup.mode'='earliest-offset') */ t2on t1.id = t2.id;-- 覆盖 INSERT 目标表的表选项
insert into kafka_table1 /*+ OPTIONS('sink.partitioner'='round-robin') */ select * from kafka_table2;
四、查询提示
查询提示可用于建议优化器影响指定查询范围内的查询执行计划。它们的有效范围是指定查询提示的当前查询块(什么是查询块?)。现在,Flink Query Hints 仅支持 Join Hints。
五、句法
Flink 中的查询提示语法遵循 Apache Calcite 中的查询提示语法:
# Query Hints:
SELECT /*+ hint [, hint ] */ ...hint:hintName| hintName '(' optionKey '=' optionVal [, optionKey '=' optionVal ]* ')'| hintName '(' hintOption [, hintOption ]* ')'optionKey:simpleIdentifier| stringLiteraloptionVal:stringLiteralhintOption:simpleIdentifier| numericLiteral| stringLiteral
六、加入提示
连接提示允许用户向优化器建议连接策略,以获得更高性能的执行计划。现在 Flink Join Hints 支持 BROADCAST、SHUFFLE_HASH、SHUFFLE_MERGE 和 NEST_LOOP。
笔记:
- 连接提示中指定的表必须存在。否则,将抛出表不存在错误。
- Flink Join Hints 只支持一个查询块中包含一个提示块,如果指定多个提示块,如 /*+ BROADCAST(t1) / /+ SHUFFLE_HASH(t1) */,则解析该查询语句时会抛出异常。
- 在一个提示块中,在单个连接提示中指定多个表,例如 /*+ BROADCAST(t1, t2, …, tn) / 或指定多个连接提示,例如 /+ BROADCAST(t1), BROADCAST(t2), …、BROADCAST(tn) */ 均受支持。
- 对于单个 Join Hints 中的多个表或一个hint 块中的多个 Join Hints,Flink Join Hints 可能会发生冲突。如果发生冲突,Flink 将选择最匹配的表或连接策略。 (参见:连接提示中的冲突案例)
七、播送
批
BROADCAST 建议 Flink 使用 BroadCast join。无论table.optimizer.join.broadcast-threshold如何,带有hint的join端都会被广播,因此当表的hint端数据量很小时,它表现良好。
注意:BROADCAST 仅支持等价连接条件的连接,不支持 Full Outer Join。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用广播连接,t1 将是广播表。
SELECT /*+ BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用广播连接来进行连接,并且 t1、t3 将是广播表。
SELECT /*+ BROADCAST(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- BROADCAST 不支持非等价连接条件。
-- Join Hint 将不起作用,并且只能应用嵌套循环连接。
SELECT /*+ BROADCAST(t1) */ * FROM t1 join t2 ON t1.id > t2.id;-- BROADCAST 不支持完全外连接。
-- 这种情况下Join Hint不起作用,规划器会根据成本选择合适的Join策略。
SELECT /*+ BROADCAST(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;
八、随机散列
批
SHUFFLE_HASH建议Flink使用Shuffle Hash join。带hint的join端将是join构建端,当表的hint端数据量不太大时,它表现良好。
注意:SHUFFLE_HASH 仅支持等价连接条件的连接。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用哈希连接,t1 将作为构建端。
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用 hash join 进行连接,t1、t3 将作为连接构建端。
SELECT /*+ SHUFFLE_HASH(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_HASH 不支持非等价连接条件。
-- 对于这种情况,Join Hint 将不起作用,只能应用嵌套循环连接。
SELECT /*+ SHUFFLE_HASH(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
九、随机合并
批
SHUFFLE_MERGE 建议 Flink 使用 Sort Merge join。这种类型的Join Hint推荐用于两个大表之间的Join场景或者Join两边的数据都已经有序的场景。
注意:SHUFFLE_MERGE 仅支持具有等价连接条件的连接。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- 采用排序合并连接策略。
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- 这两种连接均采用排序合并连接策略。
SELECT /*+ SHUFFLE_MERGE(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- SHUFFLE_MERGE don't support non-equivalent join conditions.
-- Join Hint will not work, and only nested loop join can be applied.
SELECT /*+ SHUFFLE_MERGE(t1) */ * FROM t1 join t2 ON t1.id > t2.id;
– SHUFFLE_MERGE 不支持非等价连接条件。
– Join Hint 将不起作用,并且只能应用嵌套循环连接。
十、嵌套循环
批
NEST_LOOP 建议 Flink 使用 Nested Loop join。如果没有特殊场景需求,不建议使用此类连接提示。
注意:NEST_LOOP 支持等效和非等效连接条件。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Flink 将使用嵌套循环连接,t1 将作为构建端。
SELECT /*+ NEST_LOOP(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Flink 将使用嵌套循环连接来进行连接,t1、t3 将是连接构建端。
SELECT /*+ NEST_LOOP(t1, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;
十一、LOOKUP
流
LOOKUP 提示允许用户建议 Flink 优化器:
- 使用同步(sync)或异步(async)查找功能
- 配置异步参数
- 启用查找的延迟重试策略
查找提示选项:
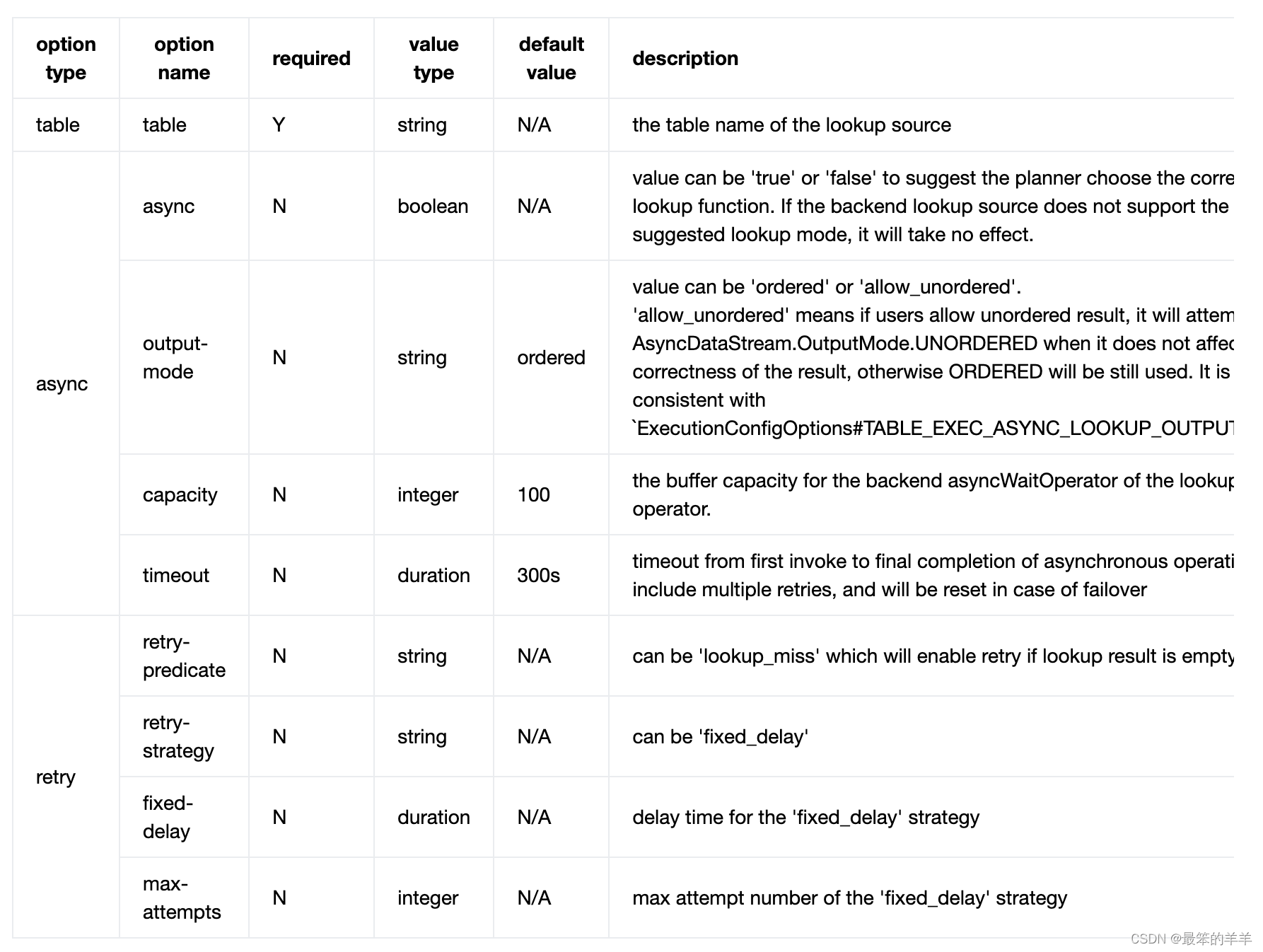
笔记:
- 'table’选项为必填项,仅支持表名(与FROM子句中的保持一致),注意如果表有别名,则只能使用别名。
- async选项都是可选的,如果没有配置将使用默认值。
重试选项没有默认值,需要启用重试时,所有重试选项都应设置为有效值。
1.使用同步和异步查找功能#
如果连接器同时具有异步和同步查找功能,则用户可以指定选项值“async”=“false”以建议规划器使用同步查找或“async”=“true”以使用异步查找:
例子:
-- suggest the optimizer to use sync lookup
LOOKUP('table'='Customers', 'async'='false')-- suggest the optimizer to use async lookup
LOOKUP('table'='Customers', 'async'='true')
注意:如果未指定“async”选项,优化器更喜欢异步查找,在以下情况下它将始终使用同步查找:
- 连接器仅实现同步查找
- 用户启用“table.optimizer.non-definistic-update.strategy”的“TRY_RESOLVE”模式,并且优化器已检查是否存在由非确定性更新引起的正确性问题。
- 配置异步参数 #
用户可以通过异步查找模式下的异步选项配置异步参数。
例子:
-- configure the async parameters: 'output-mode', 'capacity', 'timeout', can set single one or multi params
LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
注意:异步选项与作业级别执行选项中的异步选项一致,如果不设置将使用作业级别配置。另一个区别是LOOKUP提示的范围更小,仅限于当前查找操作中设置的提示选项对应的表名(其他查找操作不会受到LOOKUP提示的影响)。
例如,如果作业级别配置是:
table.exec.async-lookup.output-mode: ORDERED
table.exec.async-lookup.buffer-capacity: 100
table.exec.async-lookup.timeout: 180s
然后出现以下提示:
1. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered')
2. LOOKUP('table'='Customers', 'async'='true', 'timeout'='300s')
相当于:
3. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='allow_unordered', 'capacity'='100', 'timeout'='180s')
4. LOOKUP('table'='Customers', 'async'='true', 'output-mode'='ordered', 'capacity'='100', 'timeout'='300s')
- 启用查找延迟重试策略 #
查找连接的延迟重试旨在解决外部系统延迟更新导致流数据意外丰富的问题。提示选项’retry-predicate’='lookup_miss’可以启用同步和异步查找重试,目前仅支持固定延迟重试策略。
固定延迟重试策略选项:
'retry-strategy'='fixed_delay'
-- fixed delay duration
'fixed-delay'='10s'
-- max number of retry(counting from the retry operation, if set to '1', then a single lookup process
-- for a specific lookup key will actually execute up to 2 lookup requests)
'max-attempts'='3'
例子:
1.启用异步查找重试
LOOKUP('table'='Customers', 'async'='true', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
2.启用同步查找重试
LOOKUP('table'='Customers', 'async'='false', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
如果查找源只有一种功能,则可以省略“异步”模式选项:
LOOKUP('table'='Customers', 'retry-predicate'='lookup_miss', 'retry-strategy'='fixed_delay', 'fixed-delay'='10s','max-attempts'='3')
十二、进一步说明
启用缓存对重试的影响
FLIP-221 增加了对查找源的缓存支持,有 PARTIAL 和 FULL 缓存模式(NONE 模式表示禁用缓存)。当启用完整缓存时,根本不会重试(因为通过查找源的完整缓存镜像重试查找是没有意义的)。当启用 PARTIAL 缓存时,它将首先从本地缓存查找即将到来的记录,如果缓存未命中,将通过后端连接器进行外部查找(如果缓存命中,则立即返回记录),这将在查找结果时触发重试为空(与禁用缓存相同),重试完成时确定最终查找结果(在PARTIAL缓存模式下,也会更新本地缓存)。
关于查找键和‘retry-predicate’=‘lookup_miss’重试条件的注意事项
对于不同的连接器,索引查找能力可能会有所不同,例如内置的HBase连接器只能在rowkey上查找(没有二级索引),而内置的JDBC连接器可以提供更强大的任意列的索引查找能力,这是由不同的连接器决定的。物理存储。这里提到的查找键是索引查找的字段或字段组合,以查找连接为例,其中c.id是连接条件“ON o.customer_id = c.id”的查找键:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id
如果我们将连接条件更改为“ON o.customer_id = c.id and c.country = ‘US’”:
SELECT o.order_id, o.total, c.country, c.zip
FROM Orders AS oJOIN Customers FOR SYSTEM_TIME AS OF o.proc_time AS cON o.customer_id = c.id and c.country = 'US'
当 Customers 表存储在 MySql 中时,c.id 和 c.country 都将用作查找键:
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
)
当Customers表存储在HBase中时,只有c.id可以作为查找键,其余连接条件c.country = 'US’将在查找结果返回后进行评估
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING,PRIMARY KEY (id) NOT ENFORCED
) WITH ('connector' = 'hbase-2.2',...
)
因此,当启用“lookup_miss”重试谓词和固定延迟重试策略时,上述查询将对不同存储产生不同的重试效果。
例如,如果 Customers 表中有一行:
id=100, country='CN'
在处理订单流中id=100的记录时,在jdbc连接器中,对应的查找结果为空(country='CN’不满足条件c.country = ‘US’),因为c.country=‘US’。 id 和 c.country 用作查找键,因此这将触发重试。
当在’hbase’连接器中时,仅使用c.id作为查找键,相应的查找结果不会为空(会返回记录id=100,country=‘CN’),因此不会触发重试(对于返回的记录,剩余的连接条件 c.country = ‘US’ 将被评估为不正确)。
目前基于SQL语义考虑,只提供了lookup_miss重试谓词,当需要等待维度表的延迟更新时(表中已经存在而不是不存在历史版本记录),用户可以使用可以尝试两种解决方案:
- 使用 DataStream Async I/O 中新的重试支持实现自定义重试谓词(允许对返回的记录进行更复杂的判断)。
- 通过添加另一个连接条件(包括比较由时间戳生成的某种数据版本)来启用延迟重试,对于上面的示例,假设 Customers 表每小时更新一次,我们可以添加一个新的与时间相关的版本字段 update_version,该字段保留为每小时精度,例如,记录的更新时间“2022-08-15 12:01:02”会将 update_version 存储为“2022-08-15 12:00”
CREATE TEMPORARY TABLE Customers (id INT,name STRING,country STRING,zip STRING,-- the newly added time-dependent version fieldupdate_version STRING
) WITH ('connector' = 'jdbc','url' = 'jdbc:mysql://mysqlhost:3306/customerdb','table-name' = 'customers'
)
将 Order 流的时间字段和 Customers.update_version 上的相等条件附加到连接条件:
ON o.customer_id = c.id AND DATE_FORMAT(o.order_timestamp, 'yyyy-MM-dd HH:mm') = c.update_version
那么当Order的记录无法在Customers表中查找到‘12:00’版本的新记录时,我们可以启用延迟重试。
十三、故障排除
当开启延迟重试查找时,查找节点更有可能遇到背压问题,这可以通过Web ui“任务管理器”页面上的“线程转储”快速确认。分别从异步和同步查找中,线程睡眠的调用堆栈将出现在:
- 异步查找:RetryableAsyncLookupFunctionDelegator
- 同步查找:RetryableLookupFunctionDelegator
笔记:
- 带重试的异步查找无法对所有输入数据进行固定延迟处理(应使用其他较轻的方法来解决,例如挂起的源消耗或使用带重试的同步查找)
- 同步查找中延迟等待重试执行是完全同步的,即,直到当前记录完成后才开始处理下一条记录。
- 在异步查找中,如果“output-mode”为“ORDERED”模式,则延迟重试导致背压的概率可能高于“UNORDERED”模式,在这种情况下,增加异步“容量”可能无法有效减少背压,并且可能有必要考虑缩短延迟时间。
十四、连接提示中的冲突案例
如果 Join Hints 发生冲突,Flink 会选择最匹配的一个。
- 如果同一个Join Hint策略发生冲突,Flink会选择第一个匹配的表进行Join。
- 当不同的Join Hints策略发生冲突时,Flink会选择第一个匹配的hint进行Join。
例子:
CREATE TABLE t1 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t2 (id BIGINT, name STRING, age INT) WITH (...);
CREATE TABLE t3 (id BIGINT, name STRING, age INT) WITH (...);-- Conflict in One Same Join Hints Strategy Case-- The first hint will be chosen, t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2), BROADCAST(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- BROADCAST(t2, t1) will be chosen, and t2 will be the broadcast table.
SELECT /*+ BROADCAST(t2, t1), BROADCAST(t1, t2) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- This case equals to BROADCAST(t1, t2) + BROADCAST(t3),
-- when join between t1 and t2, t1 will be the broadcast table,
-- when join between the result after t1 join t2 and t3, t3 will be the broadcast table.
SELECT /*+ BROADCAST(t1, t2, t3) */ * FROM t1 JOIN t2 ON t1.id = t2.id JOIN t3 ON t1.id = t3.id;-- Conflict in Different Join Hints Strategies Case-- The first Join Hint (BROADCAST(t1)) will be chosen, and t1 will be the broadcast table.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 JOIN t2 ON t1.id = t2.id;-- Although BROADCAST is first one hint, but it doesn't support full outer join,
-- so the following SHUFFLE_HASH(t1) will be chosen, and t1 will be the join build side.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id = t2.id;-- Although there are two Join Hints were defined, but all of them are neither support non-equivalent join,
-- so only nested loop join can be applied.
SELECT /*+ BROADCAST(t1) SHUFFLE_HASH(t1) */ * FROM t1 FULL OUTER JOIN t2 ON t1.id > t2.id;
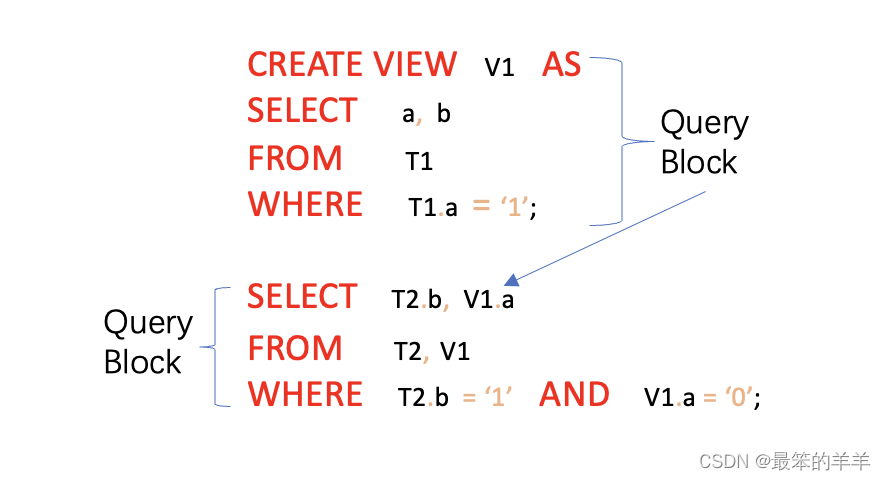
十五、什么是查询块
查询块是SQL的基本单元。例如,任何内联视图或 SQL 语句的子查询都被视为与外部查询不同的查询块。
例子:
一条 SQL 语句可以由多个子查询组成。子查询可以是 SELECT、INSERT 或 DELETE。子查询可以在 FROM 子句、WHERE 子句或 UNION 或 UNION ALL 的子查询中包含其他子查询。
对于这些不同的子查询或视图类型,它们可以由多个查询块组成,例如:
下面的简单查询只有一个子查询,但它有两个查询块 - 一个用于外部 SELECT,另一个用于子查询 SELECT。

下面的查询是一个联合查询,它包含两个查询块 - 一个用于第一个 SELECT,另一个用于第二个 SELECT。
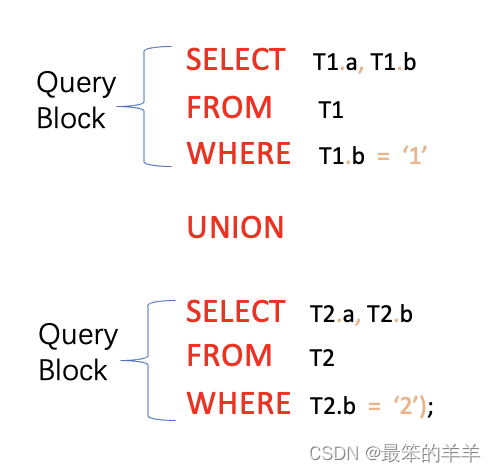
下面的查询包含一个视图,它有两个查询块 - 一个用于外部 SELECT,另一个用于视图。