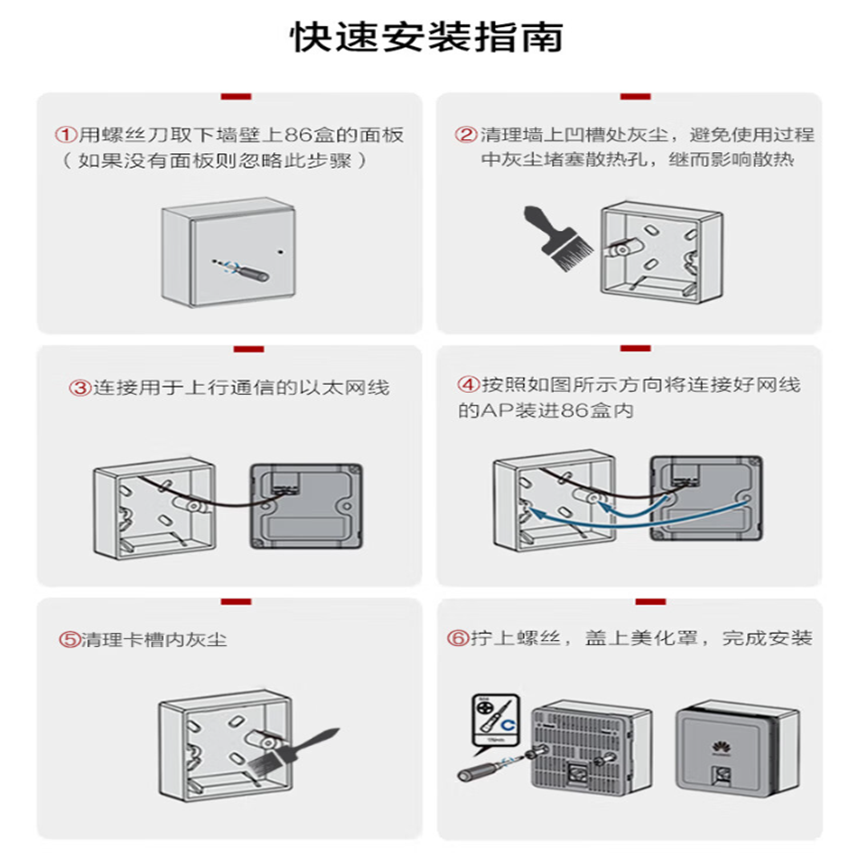
前言
Sentinel是阿里开源的一款面向分布式、多语言异构化服务架构的流量治理组件。
主要以流量为切入点,从流量路由、流量控制、流量整形、熔断降级、系统自适应过载保护、热点流量防护等多个维度来帮助开发者保障微服务的稳定性。
核心概念
要想理解一个新的技术,那么首先你得理解它的一些核心概念
资源
资源是Sentinel中一个非常重要的概念,资源就是Sentinel所保护的对象。
资源可以是一段代码,又或者是一个接口,Sentinel中并没有什么强制规定,但是实际项目中一般以一个接口为一个资源,比如说一个http接口,又或者是rpc接口,它们就是资源,可以被保护。
资源是通过Sentinel的API定义的,每个资源都有一个对应的名称,比如对于一个http接口资源来说,Sentinel默认的资源名称就是请求路径。
规则
规则也是一个重要的概念,规则其实比较好理解,比如说要对一个资源进行限流,那么限流的条件就是规则,后面在限流的时候会基于这个规则来判定是否需要限流。
Sentinel的规则分为流量控制规则、熔断降级规则以及系统保护规则,不同的规则实现的效果不一样。
来个Demo
为了兼顾文章的完整性和我一贯的风格,必须要来个demo,如果你已经使用过了Sentinel,那么就可以直接pass这一节,直接快进到核心原理。
1、基本使用
引入依赖
<dependency><groupId>com.alibaba.csp</groupId><artifactId>sentinel-core</artifactId><version>1.8.6</version>
</dependency>
测试代码
public class SentinelSimpleDemo {public static void main(String[] args) {//加载流控规则initFlowRules();for (int i = 0; i < 5; i++) {Entry entry = null;try {entry = SphU.entry("sayHello");//被保护的逻辑System.out.println("访问sayHello资源");} catch (BlockException ex) {System.out.println("被流量控制了,可以进行降级处理");} finally {if (entry != null) {entry.exit();}}}}private static void initFlowRules() {List<FlowRule> rules = new ArrayList<>();//创建一个流控规则FlowRule rule = new FlowRule();//对sayHello这个资源限流rule.setResource("sayHello");//基于qps限流rule.setGrade(RuleConstant.FLOW_GRADE_QPS);//qps最大为2,超过2就要被限流rule.setCount(2);rules.add(rule);//设置规则FlowRuleManager.loadRules(rules);}}
解释一下上面这段代码的意思
-
initFlowRules方法就是加载一个限流的规则,这个规则作用于
sayHello这个资源,基于qps限流,当qps超过2之后就会触发限流。 -
SphU.entry("sayHello")这行代码是Sentinel最最核心的源码,这行代码表面看似风平浪静,实则暗流涌动。这行代码表明接下来需要访问某个资源(参数就是资源名称),会去检查需要被访问的资源是否达到设置的流控、熔断等规则。对于demo来说,就是检查sayHello这个资源是否达到了设置的流量控制规则。 -
catch BlockException也很重要,当抛出BlockException这个异常,说明触发了一些设置的保护规则,比如限流了,这里面就可以进行降级操作。
-
System.out.println("访问sayHello资源")这行代码表面是一个打印语句,实则就是前面一直在说的需要被保护的资源。
所以上面这段代码的整体意思就是对sayHello这个需要访问的资源设置了一个流控规则,规则的内容是当qps到达2的时候触发限流,之后循环5次访问sayHello这个资源,在访问之前通过SphU.entry("sayHello")这行代码进行限流规则的检查,如果达到了限流的规则的条件,会抛出BlockException。
测试结果

从结果可以看出,当前两次访问sayHello成功之后,qps达到了2,之后再访问就被限流了,失败了。
2、集成Spring
在实际的项目使用中一般不会直接写上面的那段demo代码,而是集成到Spring环境底下。
引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId><version>2.2.5.RELEASE</version>
</dependency>
<dependency><groupId>com.alibaba.cloud</groupId><artifactId>spring-cloud-starter-alibaba-sentinel</artifactId><version>2.2.5.RELEASE</version>
</dependency>
之后提供一个/sayHello接口
@RestController
public class SentinelDemoController {@GetMapping("/sayHello")public String sayHello() throws InterruptedException {return "hello";}}
配置文件
server:port: 9527spring:application:name: SentinelDemo
到这demo就搭建完成了。
此时你心理肯定有疑问,那前面提到的资源和对应的规则去哪了?
前面在说资源概念的时候,我提到Sentinel中默认一个http接口就是一个资源,并且资源的名称就是接口的请求路径。
而真正的原因是Sentinel实现了SpringMVC中的HandlerInterceptor接口,在调用Controller接口之前,会将一个调用接口设置为一个资源,代码如下
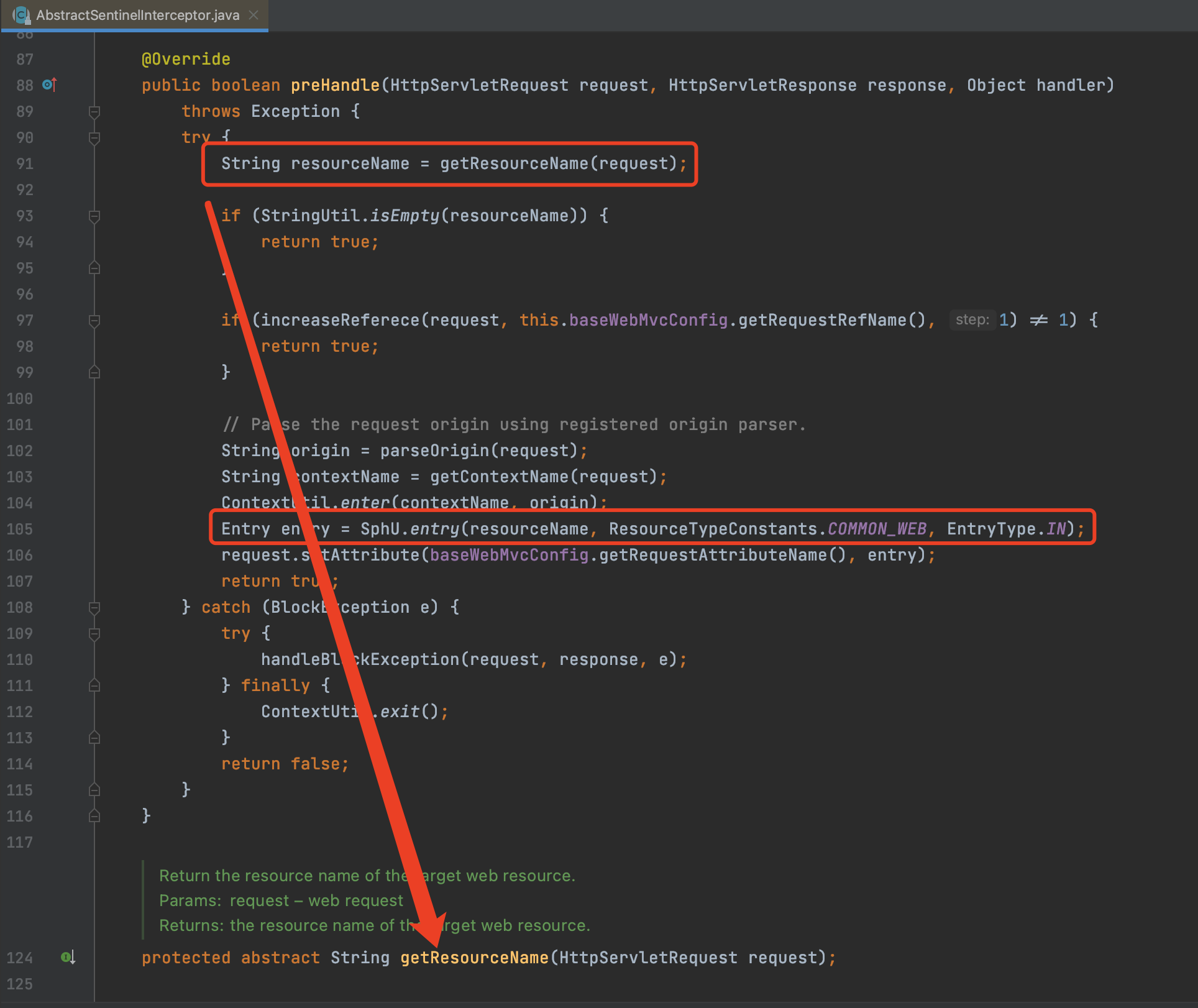
而getResourceName方法就是获取资源名,其实就是接口的请求路径,比如前面提供的接口路径是/sayHello,那么资源名就是/sayHello。
再后面的代码就是调用上面demo中提到表面风平浪静,实则暗流涌动的SphU.entry(..)方法,检查被调用的资源是否达到了设置的规则。
好了,既然资源默认是接口,已经有了,那么规则呢?
规则当然可以按照第一个demo的方式来做,比如在Controller接口中加载,代码如下。
@RestController
public class SentinelDemoController {static {List<FlowRule> rules = new ArrayList<>();//创建一个流控规则FlowRule rule = new FlowRule();//对/sayHello这个资源限流rule.setResource("/sayHello");//基于qps限流rule.setGrade(RuleConstant.FLOW_GRADE_QPS);//qps最大为2,超过2就要被限流rule.setCount(2);rules.add(rule);//设置规则FlowRuleManager.loadRules(rules);}@GetMapping("/sayHello")public String sayHello() throws InterruptedException {return "hello";}}
此时启动项目,在浏览器输入以下链接
http://localhost:9527/sayHello
疯狂快速使劲地多点几次,就出现下面这种情况

可以看出规则生效了,接口被Sentinel限流了,至于为什么出现这个提示,是因为Sentinel有默认的处理BlockException的机制,就在前面提到的进入资源的后面。

当然,你也可以自定义处理的逻辑,实现BlockExceptionHandler接口就可以了。
虽然上面这种硬编码规则的方式可以使用,但是在实际的项目中,肯定希望能够基于系统当期那运行的状态来动态调整规则,所以Sentinel提供了一个叫Dashboard应用的控制台,可以通过控制台来动态修改规则。
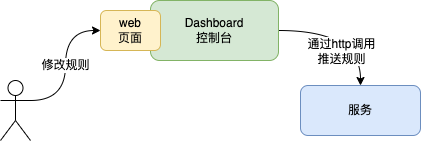
控制台其实就是一个jar包,可以从Sentinel的github仓库上下载,或者是通过从下面这个地址获取。
链接:https://pan.baidu.com/s/1Lw8V5ab_FUq934nLWDjfaw 提取码:obr5
之后通过java -jar命令启动就可以了,端口默认8080,浏览器访问http://ip:8080/#/login就可以登录控制台了,用户名和密码默认都是sentinel。
此时服务要接入控制台,只需要在配置文件上加上控制台的ip和端口即可
spring:cloud:sentinel:transport:# 指定控制台的ip和端口dashboard: localhost:8080
项目刚启动的时候控制台默认是没有数据的,需要访问一下接口,之后就有了。
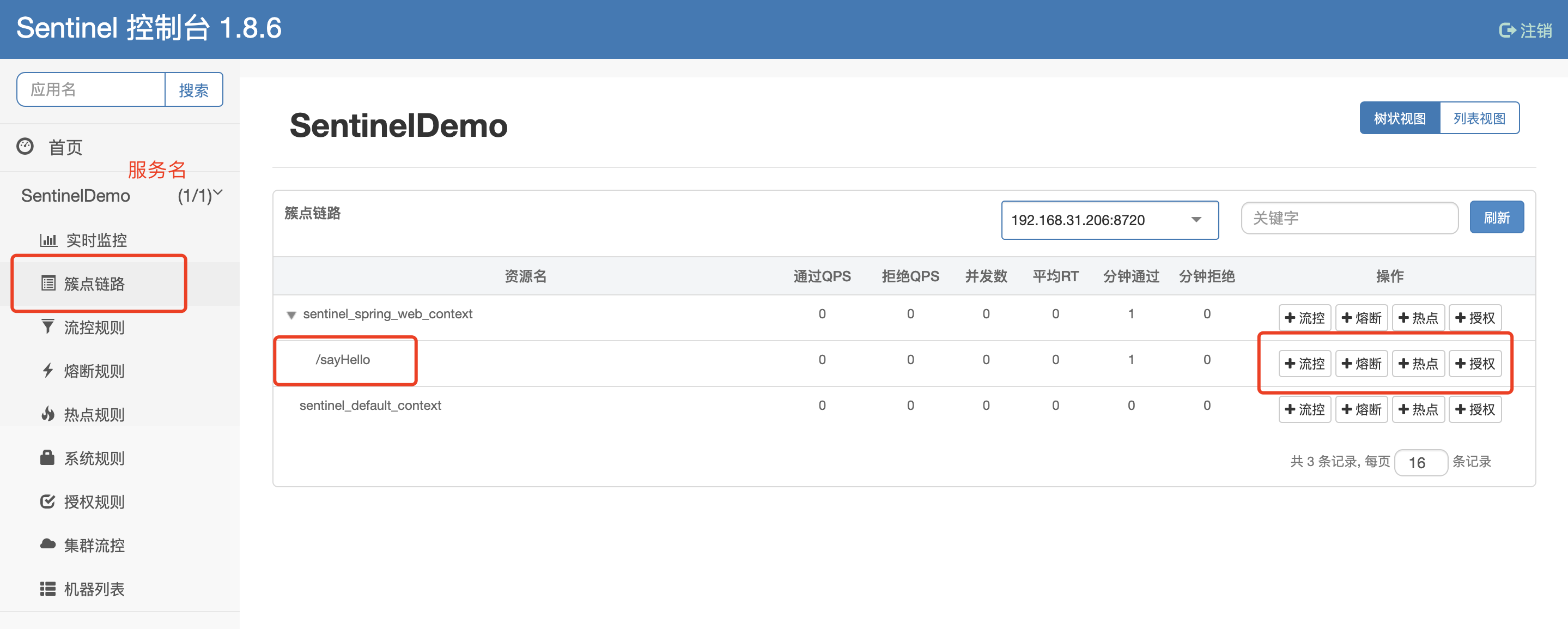
之后就可以看到/sayHello这个资源,后面就可以通过页面设置规则。
核心原理
讲完demo,接下来就来讲一讲Sentinel的核心原理,也就是前面提到暗流涌动的SphU.entry(..)这行代码背后的逻辑。
Sentinel会为每个资源创建一个处理链条,就是一个责任链,第一次访问这个资源的时候创建,之后就一直复用,所以这个处理链条每个资源有且只有一个。
SphU.entry(..)这行代码背后就会调用责任链来完成对资源的检查逻辑。
这个责任链条中每个处理节点被称为ProcessorSlot,中文意思就是处理器槽

这个ProcessorSlot有很多实现,但是Sentinel的核心就下面这8个:
-
NodeSelectorSlot
-
ClusterBuilderSlot
-
LogSlot
-
StatisticSlot
-
AuthoritySlot
-
SystemSlot
-
FlowSlot
-
DegradeSlot
这些实现会通过SPI机制加载,然后按照一定的顺序组成一个责任链。
默认情况下,节点是按照如下的顺序进行排序的

虽然默认就8个,但是如果你想扩展,只要实现ProcessorSlot,按照SPI的规定配置一下就行。
下面就来按照上面节点的处理顺序来好好扒一扒这8个ProcessorSlot。
1、NodeSelectorSlot
这个节点的作用是来设置当前资源对应的入口的统计Node。
首先什么是统计Node?
比如就拿上面的例子来说,当/sayHello这个资源的qps超过2的时候,要触发限流。
但是有个疑问,Sentinel是怎么知道/sayHello这个资源的qps是否达到2呢?
当然是需要进行数据统计的,只有通过统计,才知道qps是否达到2,这个进行数据统计的类在Sentinel中叫做Node。

通过Node这个统计的类就知道有多少请求,成功多少个,失败多少个,qps是多少之类的。底层其实是使用到了滑动窗口算法。
那么什么叫对应的入口?
在Sentinel中,支持同一个资源有不同的访问入口。
举个例子,这个例子后面会反复提到。
假设把杭州看做是服务,西湖看做是一个资源,到达西湖有两种方式,地铁和公交。

所以要想访问西湖这个资源,就可以通过公交和地铁两种方式,而公交和地铁就对应前面说的入口的意思。
只不过一般一个资源就一个入口,比如一个http接口一般只能通过http访问,但是Sentinel支持多入口,你可以不用,但是Sentinel有。
所以NodeSelectorSlot的作用就是选择资源在当前调用入口的统计Node,这样就实现了统计同一个资源在不同入口访问数据,用上面的例子解释,就可以实现分别统计通过公交和地铁访问西湖的人数。
资源的入口可以在进入资源之前通过ContextUtil.enter("入口名", origin)来指定,如果不指定,那么入口名称默认就是sentinel_default_context。
在SpringMVC环境底下,所有的http接口资源,默认的入口都是sentinel_spring_web_context
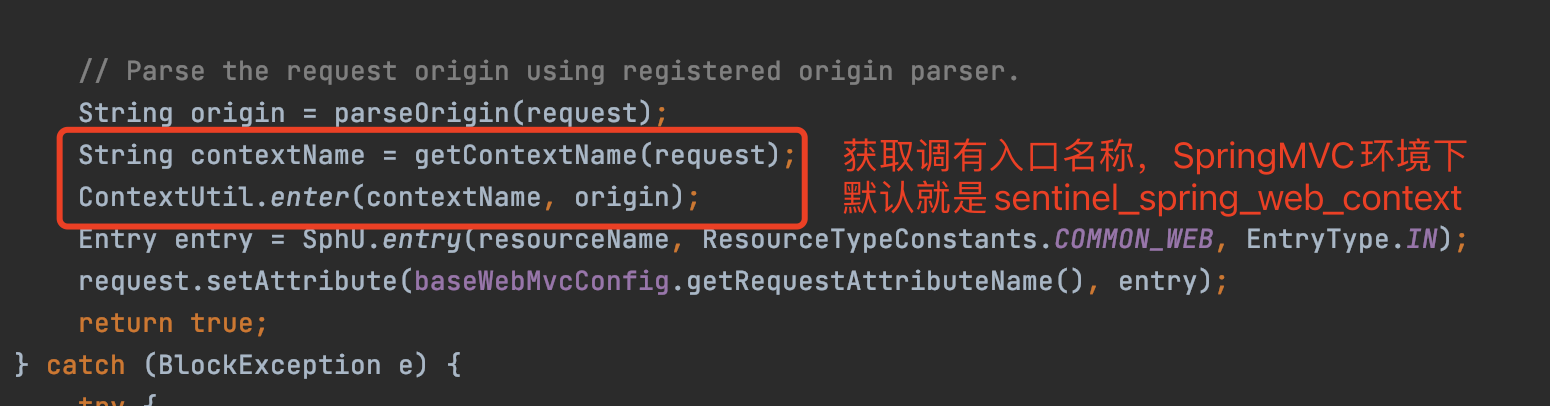
入口名称也可以通过控制台看到

那么为什么要搞一个入口的概念呢?这里咱先留个悬念,后面再说。
2、ClusterBuilderSlot
ClusterBuilderSlot的作用跟NodeSelectorSlot其实是差不多的,也是用来选择统计Node,但是选择的Node的统计维护跟NodeSelectorSlot不一样。
ClusterBuilderSlot会选择两个统计Node:
-
第一个统计Node是资源的所有入口的统计数据之和,就是资源访问的总数据
-
第二个统计Node就是统计资源调用者对资源访问数据
资源调用者很好理解,比如一个http接口资源肯定会被调用,那么调用这个接口的服务或者应用其实就是资源的调用者,但是一般资源的调用者就是指某个服务,后面调用者我可能会以服务来代替。
一个接口可以被很多服务调用,所以一个资源可以很多调用者,而不同调用者都会有单独的一个统计Node,用来分别统计不同调用者对资源的访问数据。
举个例子,现在访问西湖这个资源的大兄弟来自上海,那么就会为上海创建一个统计Node,用来统计所有来自上海的人数,如果是北京,那么就会为北京创建一个统计Node。
那么如何知道访问资源来自哪个服务(调用者)呢?
也是通过ContextUtil.enter("入口名", origin)来指定,这个方法的第二个参数origin就是代表服务名的意思,默认是空。
所以
ContextUtil.enter(..)可以同时指定资源的入口和调用者,一个资源一定有入口,因为不指定入口默认就是sentinel_default_context,但是调用者不指定就会没有。
对于一个http请求来说,Sentinel默认服务名需要放到S-user这个请求头中,所以如果你想知道接口的调用服务,需要在调用方发送请求的时候将服务名设置到S-user请求头中。
当资源所在的服务接收到请求时,Sentinel就会从S-user请求头获取到服务名,之后再通过ContextUtil.enter("入口名", "调用者名")来设置当前资源的调用者

这里我原以为Sentinel会适配比如OpenFeign之类的框架,会自动将服务名携带到请求头中,但是我翻了一下源码,发现并没有去适配,不知道是出于什么情况的考虑。
所以这一节加上上一节,我们知道了一个资源其实有三种维度的统计Node:
-
分别统计不同入口的访问数据
-
统计所有入口访问数据之和
-
分别统计来自某个服务的访问数据
为了方便区分,我来给这三个统计Node取个响亮的名字
不同入口的访问数据就叫他DefaultNode,统计所有入口访问数据之和就叫他ClusterNode,来自某个服务的访问数据就叫他OriginNode。
是不是够响亮!
那么他们的关系就可以用下面这个图来表示

3、LogSlot
这个Slot没什么好说的,通过名字可以看出来,其实就是用来打印日志的。

当发生异常,就会打印日志。
4、StatisticSlot
这个Slot就比较重要了,就是用来统计数据的。
前面说的NodeSelectorSlot和ClusterBuilderSlot,他们的作用就是根据资源当前的入口和调用来源来选择对应的统计Node。
而StatisticSlot就是对这些统计Node进行实际的统计,比如加一下资源的访问线程数,资源的请求数量等等。

前几个Slot其实都是准备、统计的作用,并没有涉及限流降级之类的,他们是为限流降级提供数据支持的。
5、AuthoritySlot
Authority是授权的意思,这个Slot的作用是对资源调用者进行授权,就是黑白名单控制。
可以通过控制台来添加授权规则。

在AuthoritySlot中会去获取资源的调用者,之后会跟授权规则中的资源应用这个选项进行匹配,之后就会出现有以下2种情况:
-
授权类型是黑名单,匹配上了,说明在黑名单内,那么这个服务就不能访问这个资源,没匹配上就可以访问
-
授权类型是白名单。匹配上了,说明在白名单内,那么这个服务就可以访问这个资源,没匹配上就不可以访问
6、SystemSlot
这个的作用是根据整个系统运行的统计数据来限流的,防止当前系统负载过高。
它支持入口qps、线程数、响应时间、cpu使用率、负载5个限流的维度。
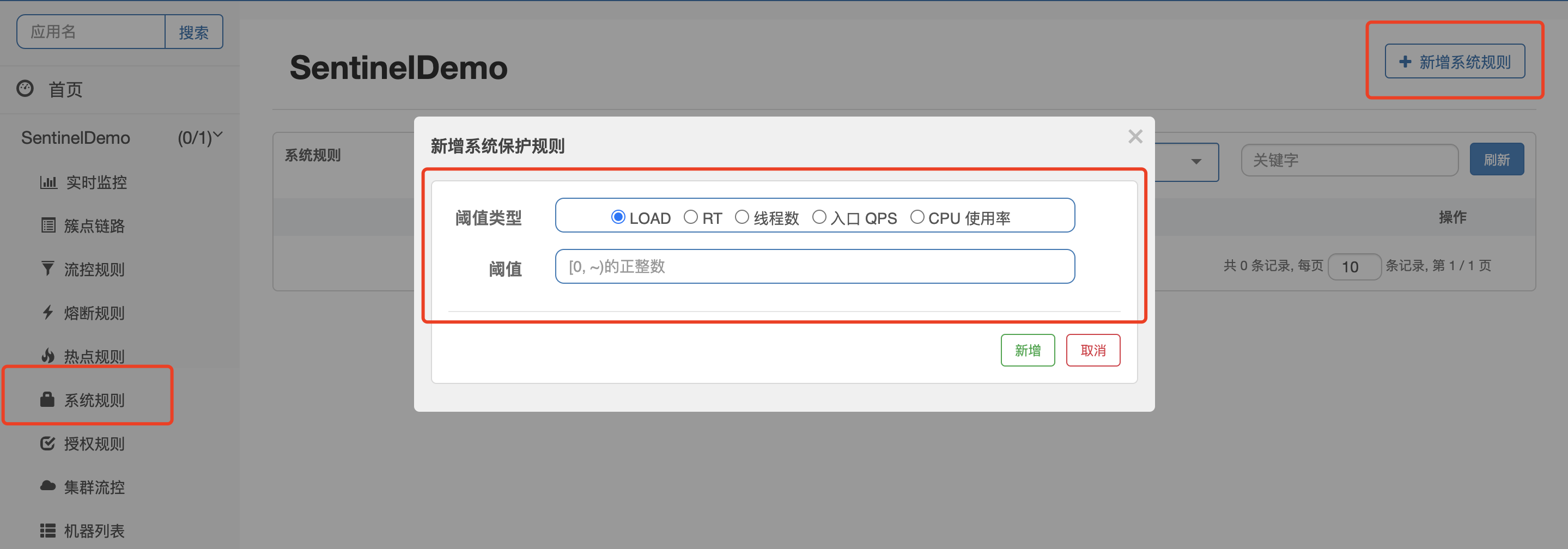
对于系统的入口qps、线程数、平均响应时间这些指标,也会有一个统计Node专门去统计,所以这个统计Node的作用就好比会去统计所有访问西湖的人数,统计也在StatisticSlot代码中,前面说的时候我把代码隐藏了

至于cpu使用率、负载指标,Sentinel会启动一个定时任务,每隔1s会去读取一次当前系统的cpu和负载。
7、FlowSlot
这个Slot会根据预设的规则,结合前面的统计出来的实时信息进行流量控制。
在说FlowSlot之前,先来用之前画的那张图回顾一下一个资源的三种统计维度

这里默默地注视10s。。
限流规则配置项比较多

这里我们来好好扒一扒这些配置项的意思。
针对来源,来源就是前面说的调用方,这个配置表明,这个规则适用于哪个调用方,默认是default,就是指规则适用于所有调用方,如果指定了调用方,那么这个规则仅仅对指定的调用方生效。
举个例子来说,比如说现在想限制来自上海的访问的人数,那么针对来源可以填上海,之后当访问的大兄弟来自上海的时候,Sentinel就会根据上海对应的OriginNode数据来判断是否达到限流的条件。
阈值类型,就是限流条件,当资源的qps或者访问的线程数到达设置的单机阈值,就会触发限流。
是否集群,这个作用是用来对集群控制的,因为一个服务可能在很多台机器上,而这个的作用就是将整个集群看成一个整体来限流,这里就不做深入讨论。
流控模式,这个流控模式的选项仅仅对阈值类型为qps有效,当阈值类型线程数时无效。
这个配置就比较有意思了,分为直接、关联、链路三种模式。
直接模式的意思就是当资源的ClusterNode统计数据统计达到了阈值,就会触发限流。
比如,当通过地铁和公交访问西湖人数之和达到单机阈值之后就会触发限流。
关联模式下需要填写关联的资源名称
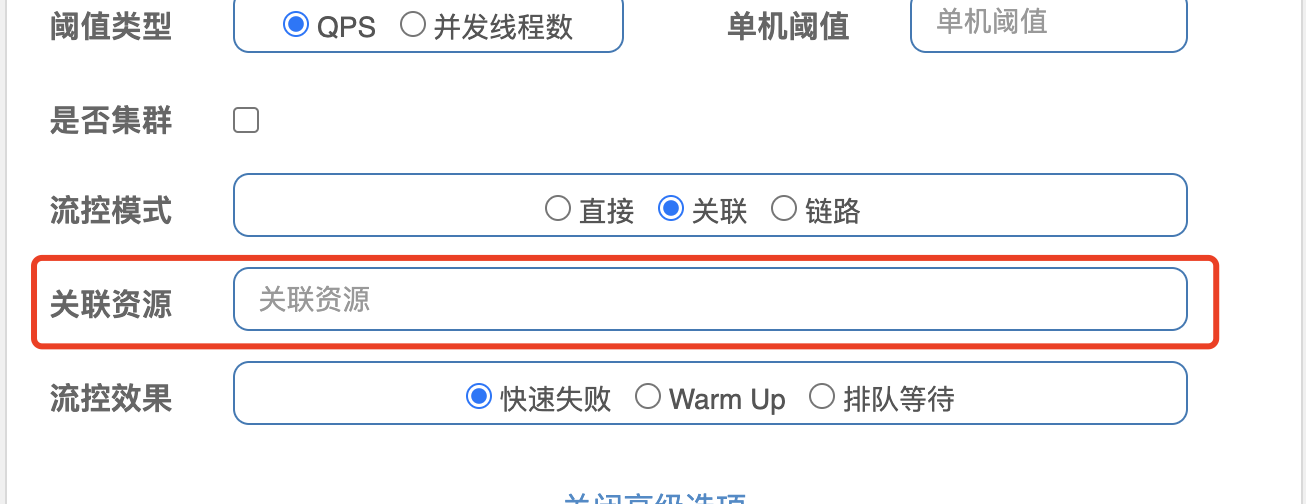
关联的意思就是当关联资源的ClusterNode统计的qps达到了设置的阈值时,就会触发当前资源的限流操作。
比如,假设现在西湖这个资源关联了雷峰塔这个资源,那么当访问雷峰塔的人数达到了指定的阈值之后,此时就触发西湖这个资源的限流,就是雷峰塔流量高了但是限流的是西湖。
链路模式也一样,它需要关联一个入口资源

关联入口的意思就是指,当访问资源的实际入口跟关联入口是一样的时候,就会根据这个入口对应的DefaultNode的统计数据来判断是否需要限流。
也就是可以单独限制通过公交和地铁的访问的人数的意思。
到这,其实前面说到的一个资源的三种统计维度的数据都用到了,现在应该明白了为什么需要这么多维度的数据,就是为不同维度限流准备的。
最后一个配置项,流控效果,这个就是如果是通过qps来限流,并且达到了限流的条件之后会做什么,如果是线程数,就直接抛出BlockException异常
也有三种方式,快速失败、Warm Up、排队等待
快速失败的意思就是指一旦触发限流了,那么直接抛出BlockException异常
Warm Up的作用就是为了防止系统流量突然增加时出现瞬间把系统压垮的情况。通过"冷启动",让通过的流量缓慢增加,在一定时间内逐渐增加到阈值上限。
排队等待,很好理解,意思当出现限流了,不是抛异常,而是去排队等待一定时间,其实就是让请求均匀速度通过,内部使用的是传说中的漏桶算法。
DegradeSlot
这是整个责任链中最后一个slot,这个slot的作用是用来熔断降级的。
Sentinel支持三种熔断策略:慢调用比例、异常比例 、异常数,通过规则配置也可以看出来。

熔断器的工作流程大致如下
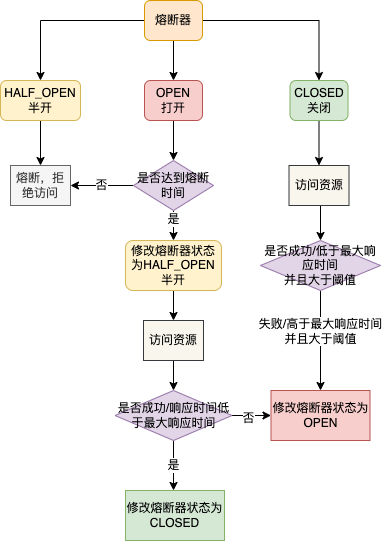
Sentinel会为每个设置的规则都创建一个熔断器,熔断器有三种状态,OPEN(打开)、HALF_OPEN(半开)、CLOSED(关闭)
-
当处于CLOSED状态时,可以访问资源,访问之后会进行慢调用比例、异常比例、异常数的统计,一旦达到了设置的阈值,就会将熔断器的状态设置为OPEN
-
当处于OPEN状态时,会去判断是否达到了熔断时间,如果没到,拒绝访问,如果到了,那么就将状态改成HALF_OPEN,然后访问资源,访问之后会对访问结果进行判断,符合规则设置的要求,直接将熔断器设置为CLOSED,关闭熔断器,不符合则还是改为OPEN状态
-
当处于HALF_OPEN状态时,直接拒绝访问资源
一般来说,熔断降级其实是对于服务的调用方来说的。
在项目中会经常调用其它服务或者是第三方接口,而对于这些接口,一旦它们出现不稳定,就有可能导致自身服务长时间等待,从而出现响应延迟等等问题。
此时服务调用方就可基于熔断降级方式解决。
一旦第三方接口响应时间过长,那么就可以使用慢调用比例规则,当出现大量长时间响应的情况,那么就直接熔断,不去请求。
虽然说熔断降级是针对服务的调用方来说,但是Sentinel本身并没有限制熔断降级一定是调用其它的服务。
总结
通过整篇文章的分析之后,再回头看看Sentinel的简介的内容,其实就能更好地理解Sentinel的定位和功能。
Sentinel核心就是一堆统计数据和基于这些统计数据实现的流控和熔断的功能,源码并不复杂,而且Sentinel的代码写得非常好。


![基于博弈树的开源五子棋AI教程[4 静态棋盘评估]](https://img-blog.csdnimg.cn/direct/89a5a7c5e1af4310a1d23ac757f79e77.png)


![[BackdoorCTF 2023] pwn](https://img-blog.csdnimg.cn/direct/aaf4a530f7474d668b4ff2c5fe7ed0dc.png)