文章目录
- 网络分类
- 模型
- 基座模型
- 衍生模型
- 二次元模型
- 2.5D模型
- 写实风格模型
- 名称解读
- VAE
- Lora
- 嵌入
- 文件放置
- 界面使用
网络分类
当使用SD webui绘图时,为了提升绘图质量,可以多种网络混合使用,可选的网络包括了模型、VAE、超网络、Lora和嵌入。
其中,模型就是我们所熟知的最核心的生成图片的稳定扩散模型,不需要额外的文件就可以直接运行,大小也最大,通常在2GB以上。
而其他网络本质上是依附于模型的插件,不能独立运行。在这其中,VAE是模型中用于从潜空间生成图片的网络模块,大小通常为几百MB,注意模型本身自带VAE,但是你可以用选择的其他VAE替换掉这部分;超网络是添加到交叉注意力层的附加网络模块,会改变模型结构,大小通常为几百MB;Lora(Low-Rank Adaption,低秩自适应)可以修改交叉注意力层的参数权重,不改变模型结构,大小同样为几百MB;嵌入则可以看做是一种特殊的提示词,它可以影响模型对文本的编码层,通常为 10-100 KB。
从效果和流行程度上来看,VAE>Lora>嵌入>>超网络,所以接下来我们重点介绍模型、VAE、Lora和嵌入这几部分。
模型
基座模型
虽然当你打开熟悉的C站寻觅模型时,可能会看到各种奇奇怪怪让人眼花缭乱的名字,但这些模型并不是创作者自己从零开始创造的,而是基于Stable Diffusion官方发布的一系列基座模型训练而来。在模型卡片的右侧,可以看到它所基于的基座模型(Base Model):
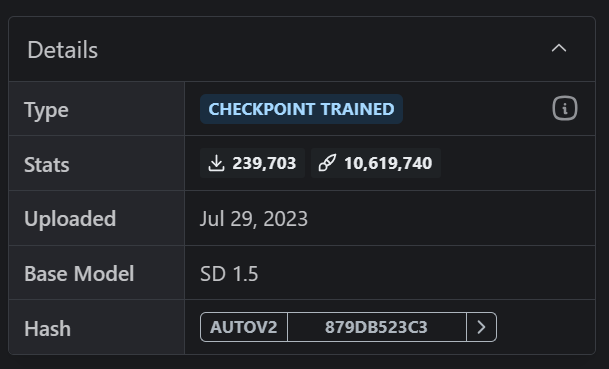
按发展的时间顺序,基座模型有这样几个系列:
- SD1.X:包括了最早的SD1.4和SD1.5,图像大小一般为512×512,没有什么生成限制,SD1.5至今长盛不衰。
- SD2.X:包括了后来的SD2.0和SD2.1及其生成图片大小为768的版本。注意这类模型虽然在绘画效果尤其是手部上更好,但不支持NSFW和名人内容,因此并不受欢迎。
- SDXL:参数量大大增加,对自然语言的理解能力大大增强,生成画面更加细腻真实,生成尺寸一般设为1024×1024。基座模型包括一个基础生图模型和一个用于精修的Refiner模型,使用时分文生图和图生图两阶段。
- SDXL Turbo:基于SDXL 1.0开发而成,由于使用了一种全新的对抗扩散蒸馏技术(ADD),可将图像所需的生成步骤减少至1—4步,从而实现秒级出图。
衍生模型
上述基座模型的图片生成能力一般比较平庸但均衡,基于这些基座模型,开发者可以使用谷歌提出的Dreambooth方法(Dreambooth : It’s like a photo booth, but once the subject is captured, it can be synthesized wherever your dreams take you)在自己构建的数据集上做微调,使其特别擅长生成某种主题或风格的图片,也就是特定领域的衍生模型。这也是目前最为广泛使用的一类模型。
按照生成的风格不同,衍生模型大致可分为二次元模型、2.5D模型和写实风格模型,下面将具体介绍一些常用模型的信息和使用方法。
二次元模型
顾名思义,主打动漫风格的模型。
- OrangeMixs
https://civitai.com/models/4769?modelVersionId=5460
生成高质量、高度逼真的插图,基于 Basil_Mix
命名规则
_sfw:SFW(全年龄模型)
_nsfw : SFW ~ 软 NSFW (R16状态)
_hard : SFW ~ 硬 NSFW(R18G状态)
- Anything
https://civitai.com/models/66/anything-v3
Anything是个神奇的二次元模型,据说是基于几十种模型融合+未知图片训练而来,随便写几个提示,就能到的不错的结果。
自称是Anything最新版本的模型,实际一切都是未知的。
仅需几个提示即可生成详细的 2D 插图的能力以及使用 danbooru 标签的能力。
整体比过拟合的v3更自然,人物姿势等更容易操作。
- AbyssOrangeMix3
https://civitai.com/models/9942?modelVersionId=11811
著名的深渊橘模型,很适合可爱型的人物形象。
现在sfw和nsfw模型被合并了,作者的说法是,发现sfw模型如果混合其他的NSFW模型可能会出现怪异的生成结果。
AOM3A1模型因为混合了ChilloutMix所以是禁止商用的,可以尝试用AOM3A1B替代
命名规则
A1 :动漫风格插图
A2 : 油画风格的艺术插图和时尚的背景
A3 : 介于A1与A2风格之间吧
A1B:介于A1与A3风格之间吧
- Elysium
https://civitai.com/models/7850/elysium
偏真实风的模型,手画的还不错,模型底稿基本是以西方人为主,所以生成的脸也偏西方人。
推荐写这些负面提示lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry
(General model): Clip skip 1, VAE: ‘vae-ft-mse-840000’ from StabilityAI (https://huggingface.co/stabilityai/sd-vae-ft-mse-original/tree/main). Sampler: DPM++ 2M Karras
(Anime model): Clip skip 1 or 2, VAE: ‘kl-f8-anime2.clowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurrykpt’ from Waifu Diffusion (https://huggingface.co/hakurei/waifu-diffusion-v1-4/tree/main/vae). Sampler: DPM++ 2M Karras
- Elysium Anime
https://civitai.com/models/8602?modelVersionId=10145
动漫的附加学习模型,NSFW化相当严重,有更清晰的轮廓和轻微的三维效果。基于Elysium_V1
- Copax Anime XL
https://civitai.com/models/155973
动漫大模型
模型的效果非常唯美,但脖子太长
采样器: Euler a CFG : 7 步数 : 32
Negative Prompt
watermark, text, logo, contact, error, blurry, cropped, username, artist name, (worst quality, low quality, nsfw, nipple, pussy:1.5)
- 古风大模型XL GuFengXL
https://civitai.com/models/189523
国画风格
风格触发关键词(有些情况不用写也能出效果,相关词越多效果越好):traditional chinese ink painting,black and white ink painting
场景辅助词(可以配合风格触发关键词,增强古风效果,相关词越多效果越好):willow branches,willow tree in background
采样步数我一般是30
(((simple background))),monochrome ,lowres, bad anatomy, bad hands, text, error, missing fingers, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, lowres, bad anatomy, bad hands, text, error, extra digit, fewer digits, cropped, worst quality, low quality, normal quality, jpeg artifacts, signature, watermark, username, blurry, ugly,pregnant,vore,duplicate,morbid,mut ilated,tran nsexual, hermaphrodite,long neck,mutated hands,poorly drawn hands,poorly drawn face,mutation,deformed,blurry,bad anatomy,bad proportions,malformed limbs,extra limbs,cloned face,disfigured,gross proportions, (((missing arms))),(((missing legs))), (((extra arms))),(((extra legs))),pubic hair, plump,bad legs,error legs,username,blurry,bad feet
- SDXL Turbo Unstable Diffusers
https://civitai.com/models/84040
不稳定模型是限制消失和创造力无界限的大模型,从这个大模型获得的结果具有固有的不可预测性。你可能会在特定提示下达到完美的巅峰,或者遭遇视觉混乱的愉悦。
不需要面部修复
图像大小:1024x1024(SDXL的标准),16:9,4:3
步数:35-150(低于30步可能会出现某些伪影和/或奇怪的饱和度,例如,图像可能看起来更粗糙,颜色更不丰富。)
Hires Upscaler:4x_foolhardy_Remacri 或 4xUltraSharp
Hires upscale:唯一限制是GPU(我将基础图像放大2.5倍,576x1024)
VAE:SDXL VAE
2.5D模型
介于二次元和三次元的模型,主打一个梦幻,看上去有一种“美得不真实”的感觉。
- 3DKX v2
https://civitai.com/models/2504?modelVersionId=12751
3D渲染/卡通图像/NSFW
推荐分辨率为 1152 x 768 或更高
如果你想让你的 3D 角色有一张更“二次元”的脸,提示词最开始写 “3d cartoon of”,或者如果你想要经典的 3D 渲染外观,写“a 3d render of”
- CuriousMerge 2.5D
https://civitai.com/models/79070?modelVersionId=99101
模型绘制的画面非常精致,有一种接近真人超级美颜的效果。最大的特点,是眼睛处理的非常棒,有评论称:眼睛最有灵魂的模型。
Sampler: DPM++ 2M Karras, DPM++ SDE Karras Steps: 20~40
Hires upscaler: R-ESRGAN 4x+ , R-ESRGAN 4x Anime6B Hires upscale: 2
Denoising strength: 0.4 ~ 0.6 CFG scale: 8 ~ 10
VEA: kl-f8-anime2 OR vae-ft-mse-840000-ema-pruned
常用tag:
(masterpiece:1.4, best quality), (intricate details), unity 8k wallpaper, ultra detailed, beautiful and aesthetic, (photorealistic:1.4), perfect lighting
For better results, try to add “close-up” to the prompt
- AnRealSpiceMix
https://civitai.com/models/204962?modelVersionId=251594
有点超现实
Sampling method: DPM++ 2M Karras
Sampling Steps: 20-45
- DreamShaper
https://civitai.com/models/4384/dreamshaper
在2.5D类型中也是属于最全面和万能的模型,出来的图片效果能让你一眼感觉出,超出二次元的层次感,又不输于真实场景的细腻感,也就是太过于精致让你感觉这不是一张真实画面。
- DreamShaper LCM快速版
https://civitai.com/models/4384?modelVersionId=252914
5-15 steps, ~2 cfg,LCM SAMPLER
- AlbedoBase XL
https://civitai.com/models/140737
媲美Midjourney的Stable Diffsion大模型,各个风格都行
refiner无需使用,已包含 VAE。
保留负面提示的空缺是实现高品质的方法。
- Colossus Project XL
https://civitai.com/models/147720
在制造极度逼真的图片、动漫和艺术方面非常擅长。
- DreamShaper XL
https://civitai.com/models/112902
不需要refiner。只需做高分辨率修复(上采样+i2i)
- DreamShaper XL Turbo
https://civitai.com/models/112902?modelVersionId=251662
步数:4-7
CFG:2
采样器:DPM++ SDE Karras
- DynaVision XL
https://civitai.com/models/122606?modelVersionId=198962
绘制3D卡通IP
- Fantastic hacker_Style_bailing-奇幻骇客
https://civitai.com/models/158852?modelVersionId=195081
奇幻骇客:本模型是一个基于sd xl1.0的偏写实风格类模型,追求极致梦幻,用AI实现现实中无法实现的特殊效果
可显示水 火 冰 雷等元素
•推荐尺寸:10241024起,8961280,7681360,10241280等
•推荐步数:25起
•推荐采样:本地【restart】【dpm++ 3m sde karras】
•反词推荐:lowres,(Style-Japan:1.2),Paintings,sketches,lowres,
•cfg scale:7起步
- FenrisXL
https://civitai.com/models/122793
这个模型最初是为动物和生物设计的,但随着模型的进一步发展,它也可作为各种生成的通用模型。
它可以处理1-30+的广泛CFG范围
不需要refiner,因为基础模型是XL6 HEPHAISTOS
可以艺术地描绘神话生物
生成效果稳定和连贯
细节丰富,可生成高质量图像
可扩展到各类生成任务,不仅限于神话生物
- ProtoVision XL
https://civitai.com/models/125703
夜景+照片+3D
- 国风4 GuoFeng4 XL
https://civitai.com/models/118009?modelVersionId=199325
GuoFeng4模型是对国人喜欢的画风微调过的模型,具有2.5D,CG,游戏,建模质感。基于SDXL1.0训练。
采样器:DPM++ 2M SDE Karras
提示词相关性(CFG Scale):8
Face Editor(或者其他修脸插件):开启
- BriXL | A must in your toolbox
https://civitai.com/models/131703
BriXL是一个经过微调的模型,专注于科幻和电影化的效果。它的不完美之处造就了它的独特魅力!它经过了我大量原创内容以及电影素材的训练。
它擅长制作机械对象并提供电影化的灯光效果,同时不会过度对比或滥用色彩饱和度,可提供从卡通化到全真照片场景的风格灵活性
这个模型可以轻松的画出各种科幻场景,甚至可以绘制普通人难以想象的外星人
- [Lah] Mysterious | SDXL
https://civitai.com/models/118441
基于 SDXL 1.0 训练的一款奇幻风格大模型,出图质量高且非常稳定性。东西方奇幻风都可以生成,在赛博朋克、奇幻生物、3D 游戏人物上的效果也不错。
Remember: High CFG Scale for Fantasy and Low (1-3) if u want realistic photos
CFG scale: 3-9
Sampling Step: 30-60
Sampling Method: DPM++ 2M SDE Karras or Euler a
ADetailer ON
- TurboVisionXL - Super Fast XL based on new SDXL Turbo
https://civitai.com/models/215418
建议的最佳输出设置:
采样器:DPM++ SDE Karras,LCM
步骤:3-5
CFG:1-2.25
您可以将此模型以正常XL模型的模式在Automatic1111中运行,但并非所有采样器都与它兼容。我发现DPM++ SDE Karras效果最好,LCM采样器(如果您不知道的话,AnimateDiff在A1111中添加的)与它配合得也相当不错。
LoRAs表现良好,我测试了多个LoRAs,它们仍然产生预期的结果,但结果可能因人而异。
我要说的是,这个模型目前在一致性方面存在一些问题。当它每隔几秒就生成一大批图像时,您可能不在乎,但我会积极地在未来的版本中改进输出的一致性。
关于许可的说明 - 这个模型基于Stability AI发布的SDXL Turbo模型。他们将模型标识为非商业研究许可证,仅允许个人非商业使用。请注意,此模型目前不能用于图像生成服务。如果您有任何疑问,请通过Discord与我联系。
写实风格模型
看上去有真实感,难以看出是AI的作品。
- Basil mix
https://civitai.com/models/173756?modelVersionId=195113
逼真的真人模型,基于亚洲风格训练,支持Danbur标签提示词
需要加载VAE,不然画面色彩浓度和边缘会很淡
提示词应尽可能简单
不要堆砌大量质量标签和负面提示,不然会适得其反。
- ChilloutMix
https://civitai.com/models/6424?modelVersionId=11745
逼真的真人模型,基于亚洲风格训练,支持Danbur标签提示词,
根据许可证,这个模型的生成结果不能商用。
请不要用真人模型画明星和未成年的NSFW内容,不然你可能会遇到很麻烦的法律问题
- URPM
https://civitai.com/models/2661
模型包含VAE,相比V1.2大幅优化了体积,使用了11个基础模型(1.2是4个),在不损失真人质量的前提下,合并了二次元模型。
- F222
https://civitai.com/models/1188?modelVersionId=1224
生成更符合真人解剖结构的真人模型,训练集以女性图像为主
请不要用真人模型画明星和未成年的NSFW内容,不然你可能会遇到很麻烦的法律问题
- AbsoluteReality
https://civitai.com/models/81458?modelVersionId=132760
跟DreamShaper比更具真实感
Use between 4.5 and 10 CFG Scale and between 25 and 30 Steps with DPM++ SDE Karras. Worse samplers might need more steps.
Set CLIP Skip to 2
Use BadDream and UnrealisticDream negative embeddings (BadDream, (UnrealisticDream:1.2)). Add weight to UnrealisticDream between 1.2 and 1.5. Do not use FastNegative or EasyNegative if you aim at realism. However, they’re good for artworks.
Use Highres.fix with the following settings: Denoising strength: 0.45, Hires steps: 20, Hires upscaler: 8x_NMKD-Superscale_150000_G and as much upscale as you can (my gpu only handles up to x1.8 at 512x768 base resolution, but you can go higher).
- AbsoluteReality LCM快速版
https://civitai.com/models/81458?modelVersionId=256668
采样器:LCM
CFG 为 2,步数:15
- majicMIX realistic 麦橘写实
https://civitai.com/models/43331?modelVersionId=176425
开启动态cfg修复,以避免出现噪点图
Sampler: Euler a, Euler, restart
Steps: 20~40
Hires upscaler: ESRGAN 4x or 4x-UltraSharp or 8x_NMKD-Superscale_150000_G
Hires upscale: 2+
Hires steps: 15+
Hires denoising strength: 0.05~0.5
clip skip 2
如果要修复脸部,请使用after detailer.
- LEOSAM’s MoonMix Utopia | 乌托邦
https://www.liblib.art/modelinfo/2c9398ced43b7346a41bbf465946341d
utopia的意思是乌托邦,作者称:MoonMix Utopia系列的制作目的是在保证人物写实感的前提下,力争题材泛用性上的最大化,这也是本系列模型起名“乌托邦”的由来,我希望这个模型可以绘制乌托邦世界中的千奇百态。
和其他号称真实的模型相比,MoonMix Utopia无论是在人体细节(如发丝、皮肤)方面,还是在光影方面,都更有质感。
- Copax TimeLessXL
https://civitai.com/models/118111/copax-realistic-xl-sdxl101.0
真实模型,似乎很适合搞动植物摄影
Steps : 40~60
CFG : 7~10
You can also use hiresfix or After Detailer
Sampling : DPM 3M++ SDE Karass, Euler a or DPM 2M ++ SDE Karass
Nprompt:
(worst quality, low quality, illustration, 3d, 2d), open mouth, tooth,ugly face, old face, long neck,
- Copax TimeLessXL Turbo
https://civitai.com/models/219293?modelVersionId=247259
自带美颜滤镜的真人模型
Steps : 1~4
CFG : 1~2
Size: 576x768
Hires upscaler: 4x-UltraSharp
Sampling : DPM++ SDE
VAE: none
- Juggernaut XL
https://civitai.com/models/133005
最受欢迎的欧美美少女模型
Sampler: DPM++ 2M Karras
Steps: 30-40
CFG: 3-7 (less is a bit more realistic)
VAE is already Baked In
- LEOSAM’s HelloWorld SDXL
https://civitai.com/models/43977/leosams-helloworld-sdxl-base-model
写实大模型
Steps ≥ 25
Sampler: DPM++ 2M Karras
CFG scale: 10
Size ≥ 1024x1024
ADetailer: open
HelloWorld 1.0模型使用必备的触发词是leogirl,除此以外,建议同时添加realistic和looking at viewer两个正向提示词。建议使用的负面提示词是:bad eyes, incorrect hands, worst teeth, abnormal anatomy, wrong lips, illustration, cartoon, painting。
HelloWorld模型支持1024*1024分辨率直接出图,不需要高分辨率放大,目前在近景人像直出质感上不输于SD1.5版本,但直出远景人像时仍存在瑕疵,因此建议搭配ADetailer插件使用,可以很好地修正远景人脸问题。
- LEOSAM HelloWorld Turbo + LCM
https://civitai.com/models/214823/leosam-helloworld-turbo-lcm
本模型为HelloWorld SDXL原版结合SDXL Turbo和LCM技术的运行加速版本。搭配Eular a采样器,可以在6-8步内生图,是原sdxl版本的三倍速。本模型针对Eular a采样器进行效果调优,只推荐使用Eular A采样器出图。
采样器:Eular A(重要!模型针对Eular a专门适配,其他采样器效果不佳)
采样步数:8步(6~8步均可)
CFG scale:2(重要!CFG scale建议1.5~2.5)
放大算法:ESRGAN 4x(其他放大算法也可以,非必须选项,请确保GPU显存充足)
放大倍数:1.5倍
放大步数:8步
放大降噪系数:0.3
- SDS_FILM / 胶片摄影_XL
https://civitai.com/models/183133
现代亚洲女性、男性胶片摄影
现在大部分采样方法在大部分场景下不再产生过度的噪点,所以refiner不再是必须,After Detailer 也可以正常使用。其余部分依然同下。
DPM++ 2M Karras、Euler、Restart表现相对更好。
- ICBINP - “I Can’t Believe It’s Not Photography” LCM快速版
https://civitai.com/models/28059?modelVersionId=253668
在C站,最受欢迎的摄影类大模型叫ICBINP,“I Can’t Believe It’s Not Photography”(我不敢相信这不是照片)
VAE 已经内置
采样器:DPM++ SDE Karras、LCM均可(后者风格更加阴郁)
分辨率为 640x960 或 960x640,CFG 为 1-2,步数:5
- ⊣ Realities Edge XL ⊢ ⋅ LCM+SDXLTurbo!
https://civitai.com/models/129666?modelVersionId=242718
照片级真实感、3D、2.5D、插图、照片处理、肖像
分辨率采用768x1344和1024x1296
即使在更高的 CFG 上,生成错误的风险也非常低 - 建议使用 5.5-15
采样器推荐DPM+ 3M SDE Karras
Clip Skip 1-4,经常使用2
所有的img2img模式都非常有效,平衡低CFG和更高的去噪强度,将产生充满有趣细节的清晰清晰放大
名称解读
当模型过多的时候,很多时候我们会记不清它们的特点和用法,但其实从模型的名称里,就可以看出一些重要信息:
- 安全性:文件名后缀为ckpt意味着用 pickle 序列化文件,可能包含恶意代码;而safetensors只包含张量数据,更加安全。
- 完整性:pruned是完整版,emaonly(ema)是裁剪版,如果是想要自己练模型的话,需要下载完整版。
- 非文生图功能:inpainting用于图片重绘,upscaler用于图片超分。
- 是否使用加速:LCM即Latent Consistency Models(潜在一致性模型),可用少数几步推理就生成图像,可大大加快生成速度。如果LCM和Turbo同时出现,那只能恭喜你捡到宝了。
- 是否需使用VAE:VAE是可以内置到模型里面的,如果包含
No VAE或VAE,意味着模型内置了基座模型的默认VAE,如果包含Baked VAE,意味着模型内置了自己重新训练的VAE,这两种情况下都可以选择不加载额外VAE。
VAE
如果你对模型的生成效果不满意,可以在使用时设置一个匹配的VAE(Variable Auto Encoder,变量自动编码器)模型。它可以融入到模型结构中,常常能让色彩更丰富,图片更清晰,改善手部和面部,简直是体虚大模型的必备保健品。
许多模型都会发布自己的VAE,但我一般常用的只有三个,对于SD1.5及其衍生模型,如果想偏动漫风一些,可以使用kl-f8-anime2;如果想偏真人,可以使用vae-ft-mse-840000-ema-pruned。对于SDXL和SDXL Turbo,可以使用原生的sdxl_vae。
Lora
Lora文件一般以safetensors或ckpt作为后缀名,使用时需在提示中输入特定格式语句lora:filename:multiplier,其中filename为名字,multiplier为权重。
- Lora分为很多种,功能包括绘制人脸、美化人体、绘制服饰、添加风格、加速运算等。
- 需要注意的一点是,一个Lora一般只能针对一类基座及其衍生模型,不要跨用。
- Lora的权重一般在0到1之间,但有时候也会变化很大,并且带来不同的效果,可以多多尝试。
- 有时候Lora要和特定的触发词一起使用。
嵌入
嵌入文件一般以pt或bin作为后缀名,使用时需在提示中输入嵌入名。
文件放置
不同网络文件下载完成后,需要放在本地对应的路径下才能成功加载。
- 基座模型及衍生模型:stable-diffusion-webui\models\Stable-diffusion
- VAE: stable-diffusion-webui\models\VAE
- Lora:stable-diffusion-webui\models\Lora
- 嵌入:stable-diffusion-webui\embeddings
注意为了方便管理,你可以按照功能或类别存放到不同的子文件夹中,例如我的模型就是按类别存放:
Lora就是按功能存放:
界面使用
-
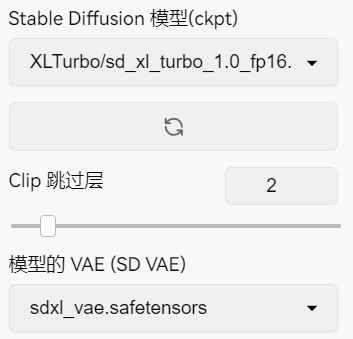
左侧模型选择界面:用于选择模型和VAE
-
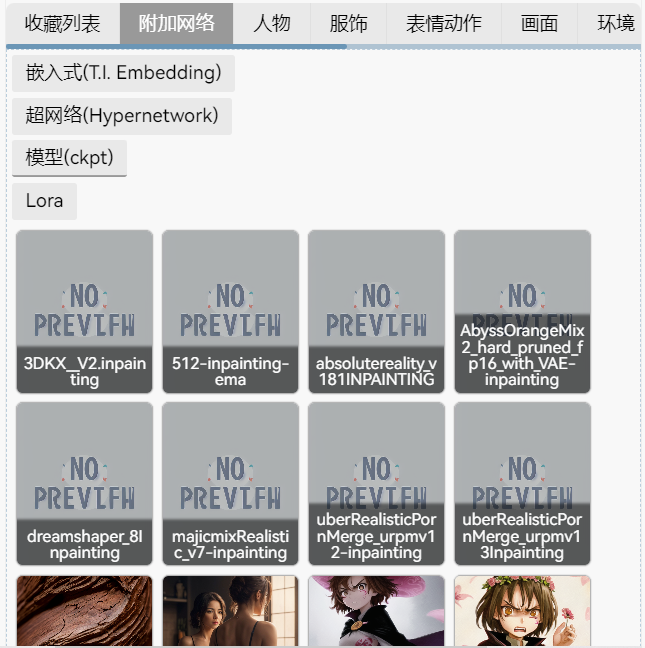
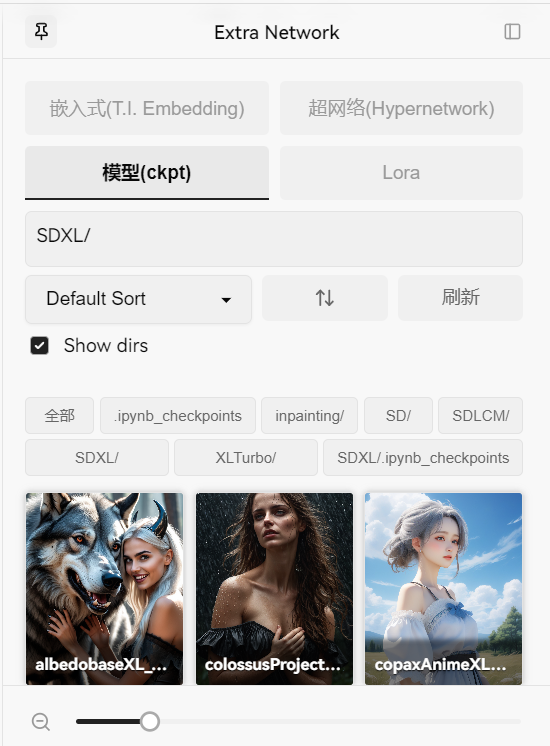
右侧额外网络界面:用于选择模型、超网络、Lora和嵌入
点击Show dirs可以根据自定义的子文件夹筛选模型
点击模型右上角的锤子,可以对其信息进行编辑
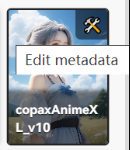
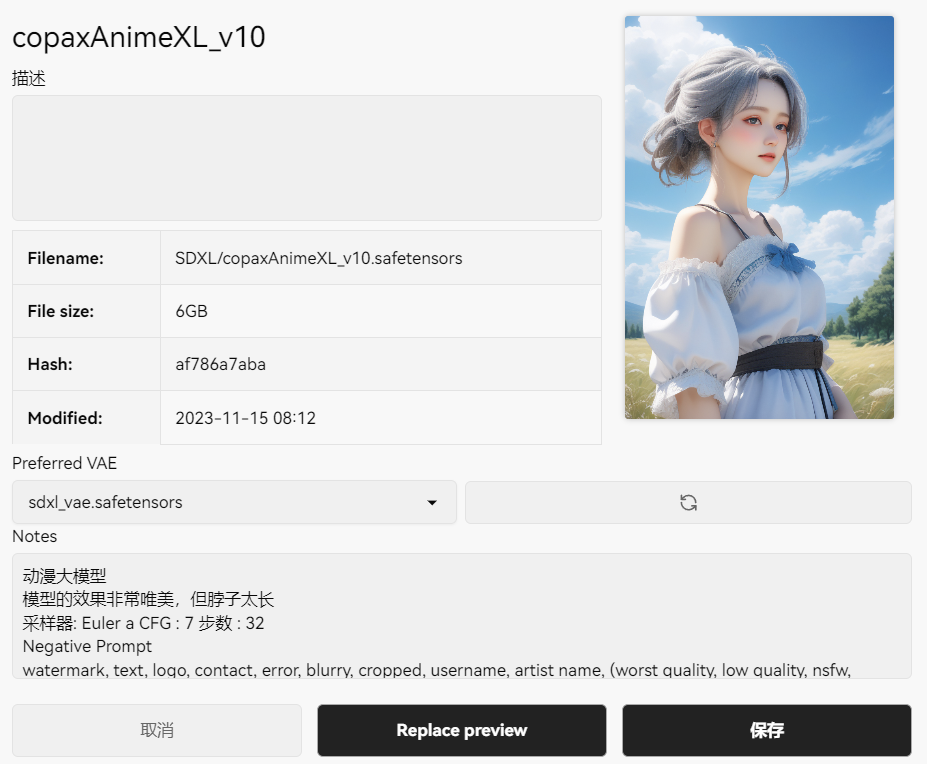
我一般把对模型的描述放在notes里面,因为如果放在描述里会显示在选择界面里,看着非常乱,点击Replace preview可以将模型封面图替换为当前生成的图片。
炫耀一下我的老婆们:
-
sd-webui-prompt-all-in-one插件:用于选择模型、超网络、Lora和嵌入
但无法根据文件目录来做筛选,也无法编辑模型信息,应该只是调用了额外网络界面的显示接口