爬取第三方网站视频
文章目录
- 爬取第三方网站视频
- 前言
- 一、基本情况
- 二、基本思路
- 三、代码编写
- 四、注意事项(ffmpeg)
- 总结
前言
国内主流的视频平台有点难。。。就暂且记录一些三方视频平台的爬取吧。比如下面这个:

一、基本情况
这次爬取的方式,跟之前的方式有点不同。
之前都是直接去获取视频的下载链接,然后去下载保存视频。这个是通过m3u8文件的地址,读取m3u8文件信息来下载所有的ts小文件并将其合并成mp4格式的视频文件。
不太懂的,先看一下这个链接:https://blog.csdn.net/yyz_1987/article/details/133783787
二、基本思路
随便打开这个网站的一个视频,然后打开开发者工具,点击查看器,搜索:m3u8。看下图(接下来会用这个地址来进行操作):

三、代码编写
代码如下:
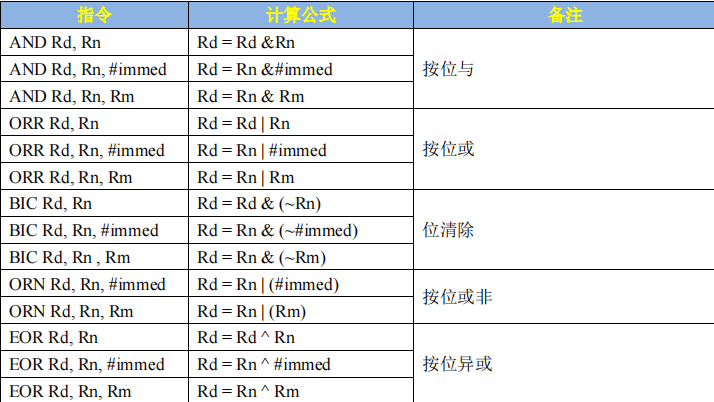
import subprocess# 当前播放视频的网页地址中获取的m3u8地址
url = "https://new.1080pzy.co/20230116/34sxZOJQ/1100kb/hls/index.m3u8"
output_file = "output.mp4"# 这个很重要,需要提前在电脑里安装一下这个ffmpeg东西
ffmpeg_path = r"C:\Users\MECHREVO\Downloads\ffmpeg-2023-12-21-git-1e42a48e37-full_build\bin\ffmpeg.exe"command = f'{ffmpeg_path} -i "{url}" -c copy "{output_file}"'
subprocess.run(command, shell=True)
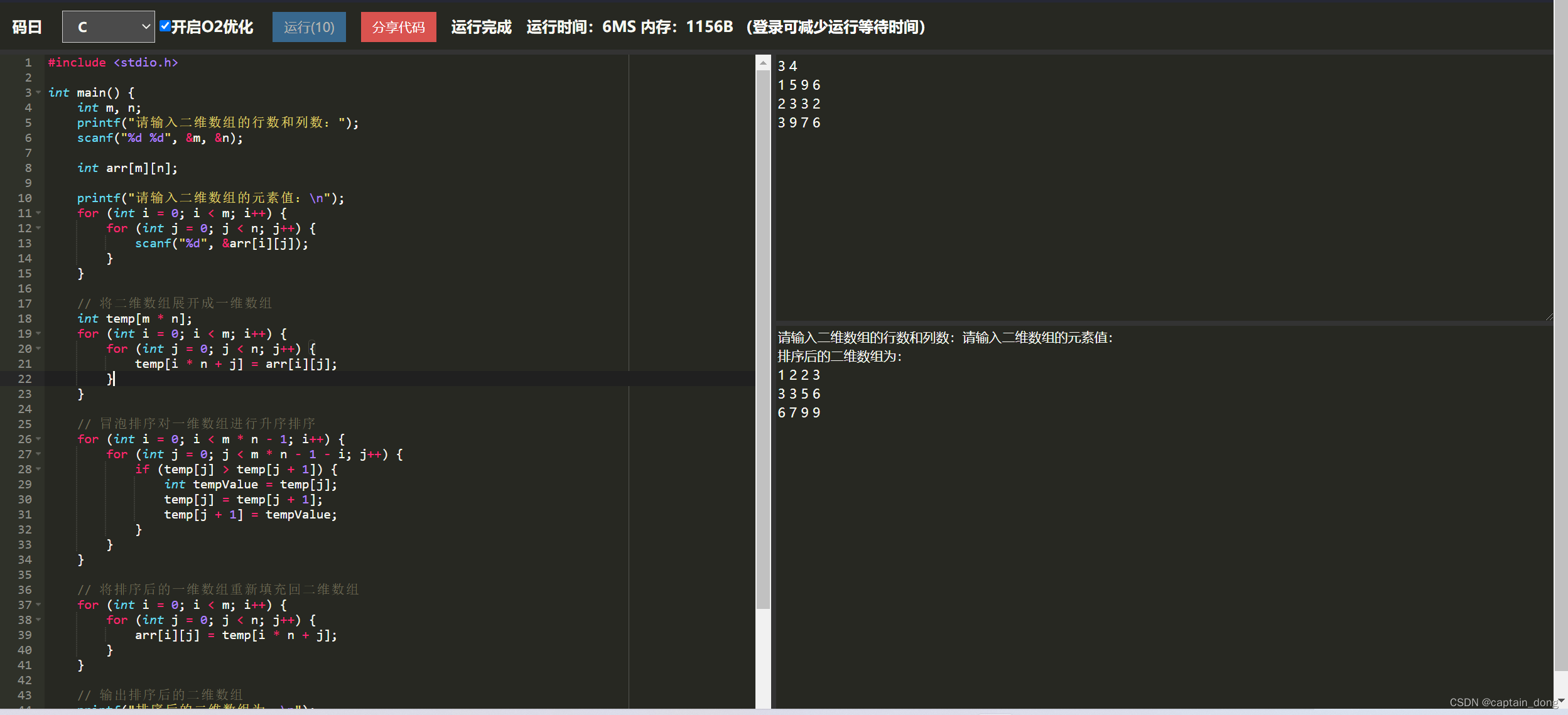
代码不多,这就是全部的代码,代码运行效果,如下图所示:

四、注意事项(ffmpeg)
需要先安装ffmpeg。可以从FFmpeg官网下载https://ffmpeg.org/download.html预编译的二进制文件,然后将其解压到一个目录,在Python代码中指定ffmpeg的完整路径。
首先,需要找到ffmpeg的实际路径。在Windows中,这通常是ffmpeg可执行文件(如ffmpeg.exe)所在的目录。然后,在Python代码中使用这个路径。
总结
这样就可以下载保存各位想要的视频了。玩玩就行哈哈哈哈哈,迅雷百度云毕竟不是吃素的嘛。