文章目录
- 0. 数据代码下载
- 1. 项目介绍
- 1.1 背景描述
- 1.2 常见信用卡欺诈使用的情况有:
- 1.3 数据描述
- a. 数据集内容
- b. 属性描述
- c. 注意
- 2. 提出问题
- 3. 数据预处理
- 3.1 加载数据
- 3.2 查看数据类型,是否需要做数据转换处理
- 3.3 对数据进行简单的统计,检查数据有无缺失值和异常值
- a. 可通过统计函数.isnull().sum() :计数空值
- b. 通过数据描述统计信息,查看是否存在缺失值和异常值
- 4. 数据探索
- 4.1 查看“Class”中的分布情况。寻求交易类型中欺诈交易占比多少。
- 4.2 对欺诈交易金额进行分析,查看欺诈交易金额呈现什么规律?
- 4.3 查看信用卡交易的时间分布情况,探索信用卡欺诈交易在哪些时间点发生的概率更高?
- 4.4 对V1~V28分析,分析该字段下欺诈交易与非欺诈交易各自的规则
- 5. 数据分析结论
- 6. 构建逻辑回归分析信用卡欺诈预测模型
- 第1步,数据的特征处理
- a. 对Time和Amount列进行标准化收敛
- b. 针对Calss,利用逻辑回归算法建立欺诈预测模型。
0. 数据代码下载
关注公众号:『AI学习星球』
回复:利用python进行信用卡欺诈检测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我

1. 项目介绍
1.1 背景描述
信用卡是传统金融行业的范畴,但同时信用卡支付仍为日常生活中常见的一种支付方式,是一种透支消费行为。当然,在交易中也会存在着这种欺诈(信用卡被盗刷)行为。加入可以利用机器学习完成对欺诈情况的预测,有助于信用卡发卡机构实现反欺诈,保护持卡人的财产安全。
信用卡欺诈是指故意使用伪造、作废的信用卡,冒用他人的信用卡骗取财物,或用本人信用卡进行恶意透支的行为。
1.2 常见信用卡欺诈使用的情况有:
- 失卡冒用:失卡一般有三种情况,一是发卡银行在向持卡人寄卡时丢失,即未达卡;二是持卡人自己保管不善丢失;三是被不法分子窃取。
- 假冒申请:利用他人资料申请信用卡,或是故意填写虚假资料申请,伪造身份证,填报虚假单位或家庭住址等
- 伪造信用卡:据统计,国际上信用卡诈骗案件中,有60%以上是伪造卡的诈骗,其特点是团伙性质,从盗取卡资料、制造假卡、贩卖假卡,到用假卡作案。伪造者经常利用一些最新的科技手段盗取真实的信用卡资料,有些是用微型测录机窃取信用卡资料,有些是伺机偷改授权机终端功能窃取信用卡资料,当窃取真实的信用卡资料后,便进行批量性的制造假卡,然后通过贩卖假卡大肆作案,牟取暴利。
本项目通过利用信用卡的历史交易数据,通过数据预处理,变量选择,建模分析预测等方法,构建简单的信用卡反欺诈预测模型,提前发现客户信用卡被盗刷的事件。
1.3 数据描述
a. 数据集内容
2013年9月由欧洲持卡人通过信用卡进行的交易。包括信用卡交易的金额、时间,是否欺诈等信息。
通过excel查看数据整体特征
| 数据集名称 | 数据类型 | 特征数 | 实例数 | 值缺失 | 相关任务 |
|---|---|---|---|---|---|
| 信用卡欺诈检测数据集 | 数值数据 | 31 | 284807 | 无 | 不平衡样本处理,预测分类 |
b. 属性描述
数据包含31个字段,每一行记录啦一条交易
| NO | 字段名称 | 字段含义 | 字段描述 |
|---|---|---|---|
| 1 | Time | Float | 数据集中第一条记录与本条记录的时间差值(seconds elapsed),秒为单位 |
| 2 | V1 | Float | 主要成分1 |
| 3 | V2 | Float | 主要成分2 |
| 4 | V3 | Float | 主要成分3 |
| … | |||
| 29 | V28 | Float | 主要成分28 |
| 30 | Amount | Float | 该条交易记录的金额 |
| 31 | Class | Float | 类别是否为欺诈:1-是,0-否 |
c. 注意
特征V1,V2,… V28是经过PCA转换后的数据,(PCA:Principal Component Analysis,主成成分分析,用于数据特征提取,使用PCA对特征数据进行降维处理。)由于机密性问题,对原始数据进行保密。功能“时间”包含每个事务与数据集中第一个事务之间经过的秒数。功能“金额”是交易金额,此功能可用于依赖于成本的成本敏感学习。
特征“类”是响应变量,在欺诈情况下取值为1,否则取0。
2. 提出问题
根据信用卡数据提供的字段信息,提出以下几个问题:
- 交易类型中欺诈交易占比多少?
- 欺诈交易金额呈现什么规律?
- 信用卡欺诈交易在哪些时间点发生的概率更高?
- 对V1~V28分析,分析该字段下欺诈交易与非欺诈交易各自的规则。
- 通过建模,对新的信用卡交易进行欺诈交易识别,即判断出现欺诈交易的概率。
关注公众号:『AI学习星球』
回复:利用python进行信用卡欺诈检测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
3. 数据预处理
3.1 加载数据
#导入工具包
# Numpy,Pandas
import numpy as np
import pandas as pd
import datetime as datetime # matplotlib
import matplotlib.pyplot as plt
import matplotlib.gridspec as gridspec
import seaborn as sns
import missingno as msno
%matplotlib inline#导入数据,查看数据data = pd.read_csv('creditcard.csv')
data.head()

data.shape
(284807, 33)
数据共31列,分别是time,V1-V28,Amount,Class。可以分析出time是无用列,V1-V28已经过PCA处理,Amount列仍需要预处理操作,Class是响应变量,发生欺诈时为1,否则为0。
3.2 查看数据类型,是否需要做数据转换处理
data.dtypes

输出结果显示,数据类型统一,无需做数据类型转换处理
3.3 对数据进行简单的统计,检查数据有无缺失值和异常值
a. 可通过统计函数.isnull().sum() :计数空值
data.isnull().sum()

数据比较干净,无需做处理
b. 通过数据描述统计信息,查看是否存在缺失值和异常值
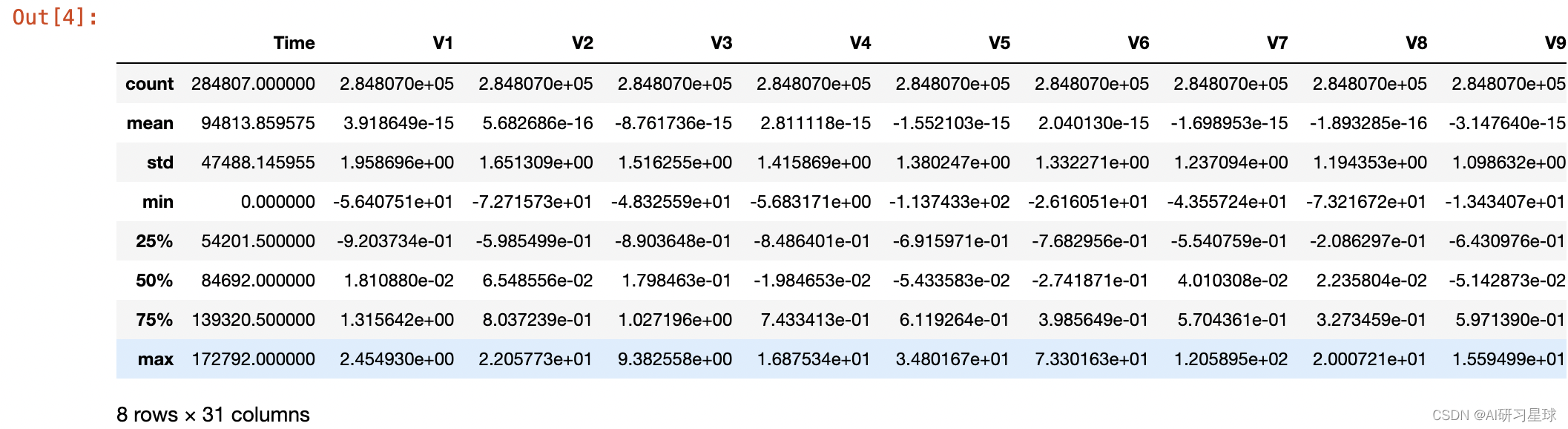
- 查看数据统计信息的主要目的:进一步检查数据- 有无缺失值和异常值。
- 查看数据缺失值方法:可以用统计函数describe和缺失值可视化函数missingno。
- 函数 .describe();
- 函数msno.matrix(data);
data.describe()
msno.matrix(data)
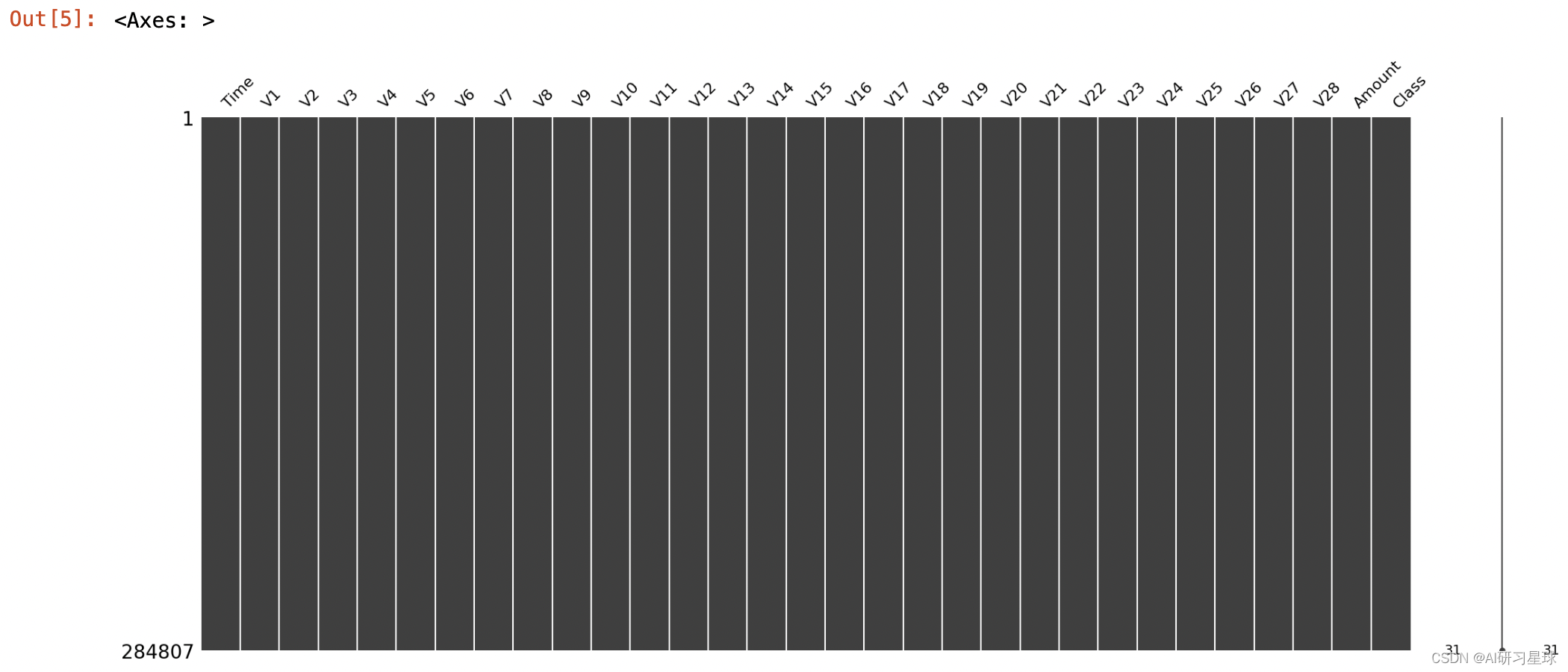
数据集中数据类型规范一致,且无缺失值和异常值,无需进行数据转换和缺失值异常值处理。
关注公众号:『AI学习星球』
回复:利用python进行信用卡欺诈检测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
4. 数据探索
4.1 查看“Class”中的分布情况。寻求交易类型中欺诈交易占比多少。
#统计class 为 0 和 1出现的频数
count_classes =pd.value_counts(data['Class'])
count_classes
0 284315
1 492
Name: Class, dtype: int64
#将结果展示
count_classes.plot(kind='bar')
plt.show()
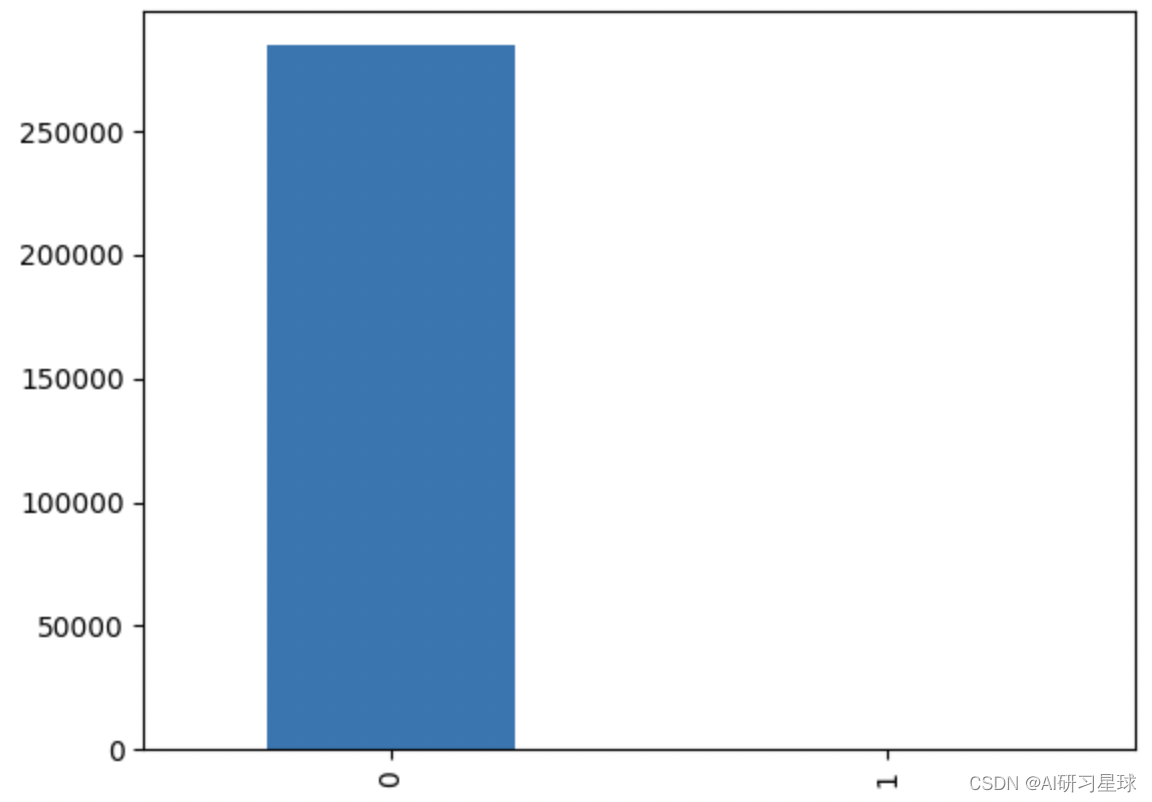
此数据集显示284,807笔交易中有492个欺诈。数据集高度不平衡,欺诈交易占总交易的比例是492/(284315+492)*100%=0.172%。
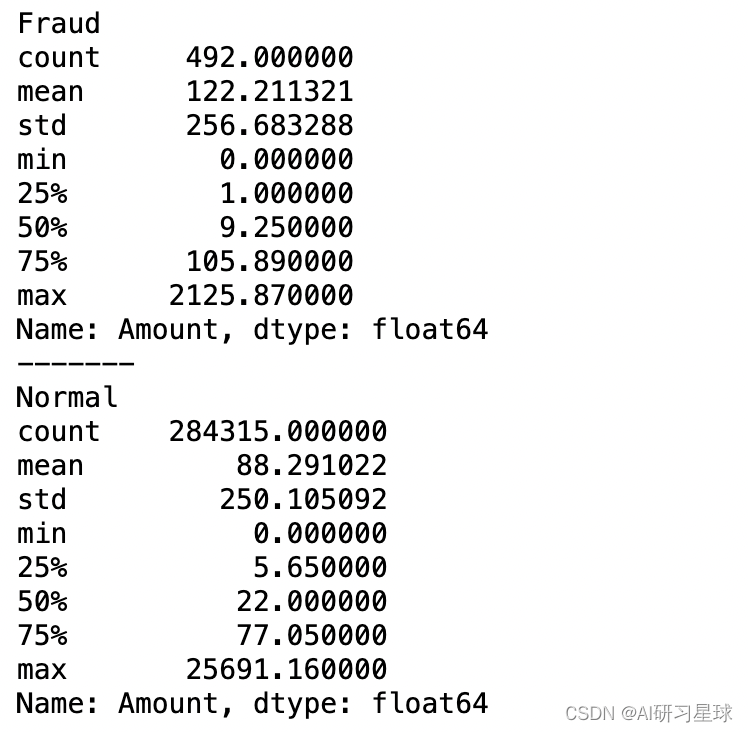
4.2 对欺诈交易金额进行分析,查看欺诈交易金额呈现什么规律?
# 分别查看信用卡正常交易和欺诈交易的描述性统计
print('Fraud')
print(data.Amount[data.Class ==1].describe())
print('-------')
print('Normal')
print(data.Amount[data.Class ==0].describe())
#查看信用卡交易金额的分布情况
f,(ax3,ax4) = plt.subplots(2,1,sharex=True,figsize=(12,6))
bins = 30ax3.hist(data.Amount[data.Class==1], bins=bins)
ax3.set_title("Fraud",fontsize = 23)ax4.hist(data.Amount[data.Class==0], bins=bins)
ax4.set_title("Normal",fontsize = 23)plt.xlabel("Amount($)",fontsize = 12)
plt.ylabel("Number of Transcations",fontsize = 12)plt.show()
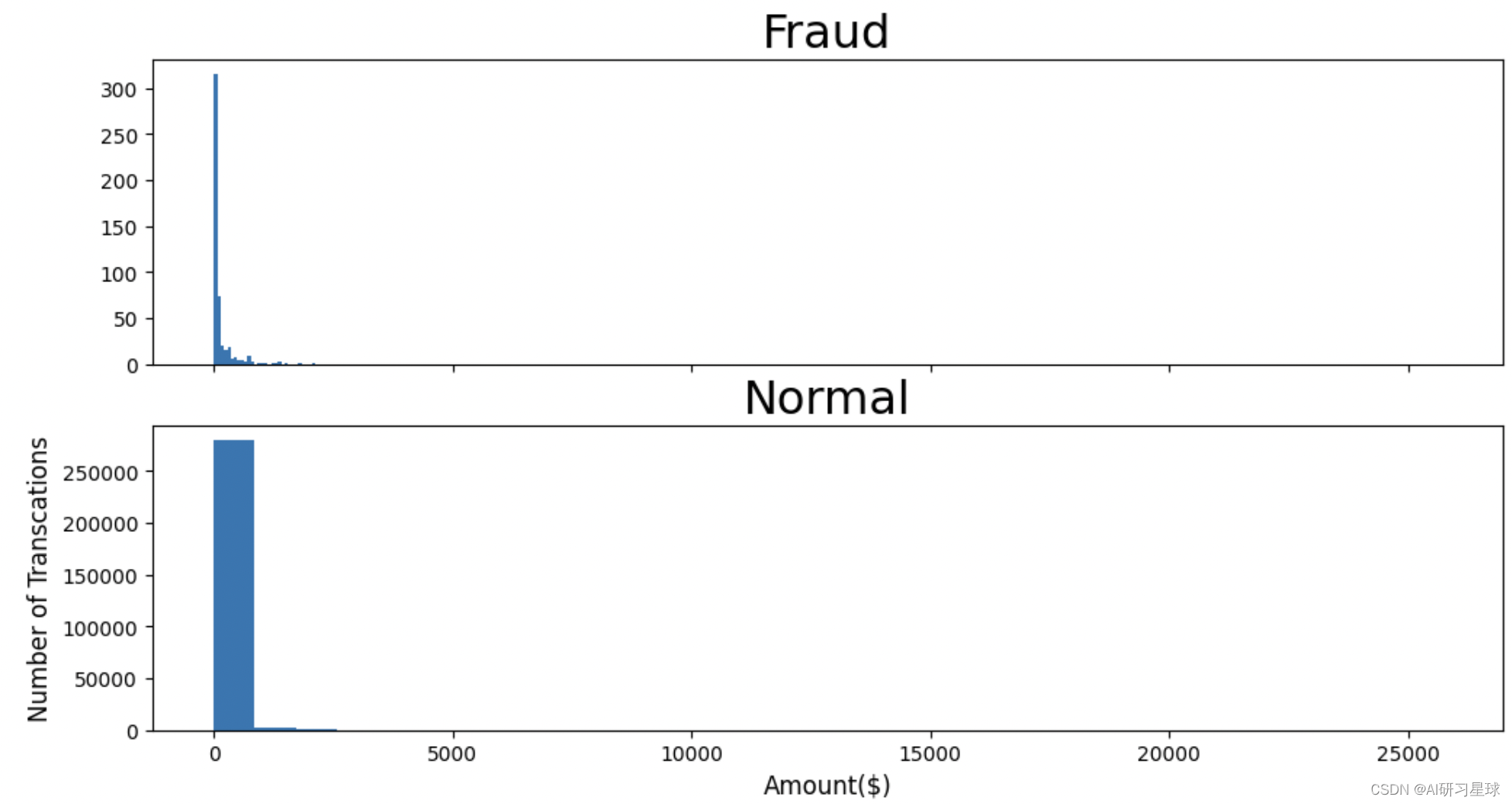
最大的欺诈交易金额为2125.87,金额不大,且整体的欺诈交易金额都集中在小额交易。
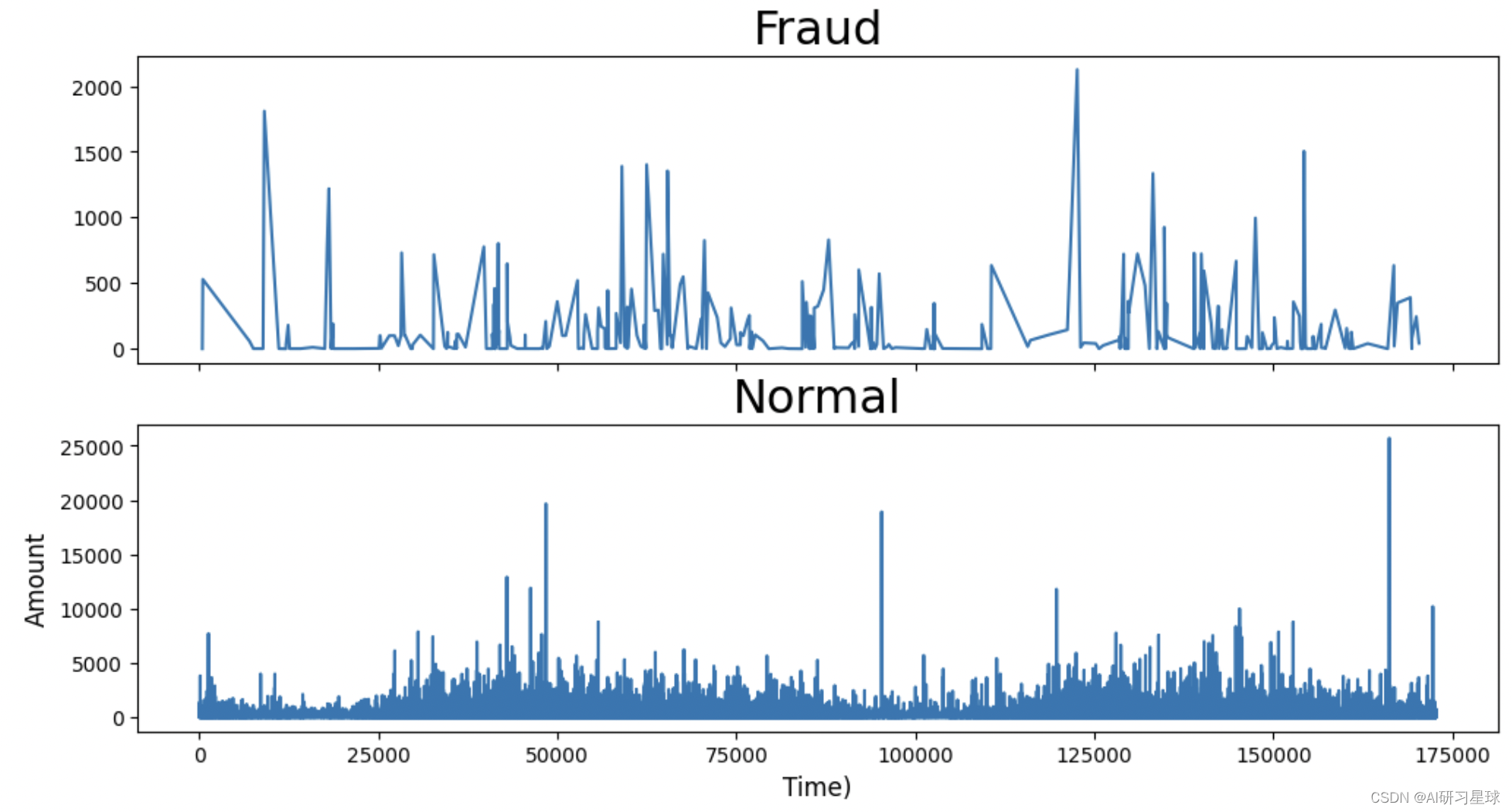
再观察,随着时间变化,交易金额如何变化?
#查看信用卡交易金额随之间变化如何分布?
f,(ax5,ax6) = plt.subplots(2,1,sharex=True,figsize=(12,6))ax5.plot(data.Time[data.Class==1],data.Amount[data.Class == 1])
ax5.set_title("Fraud",fontsize = 23)ax6.plot(data.Time[data.Class==0],data.Amount[data.Class == 0])
ax6.set_title("Normal",fontsize = 23)plt.xlabel("Time)",fontsize = 12)
plt.ylabel("Amount",fontsize = 12)plt.show()
4.3 查看信用卡交易的时间分布情况,探索信用卡欺诈交易在哪些时间点发生的概率更高?
#将时间转换为小时data['Time'] = data['Time'].apply(lambda x:divmod(x,3600)[0])#查看信用卡交易的时间分布情况
f,(ax3,ax4) = plt.subplots(2,1,sharex=True,figsize=(12,6))
bins = 50ax3.hist(data.Time[data.Class==1], bins=bins)
ax3.set_title("Fraud",fontsize = 23)ax4.hist(data.Time[data.Class==0], bins=bins)
ax4.set_title("Normal",fontsize = 23)plt.xlabel("Time",fontsize = 15)
plt.ylabel("Number of Transcations",fontsize = 15)plt.show()
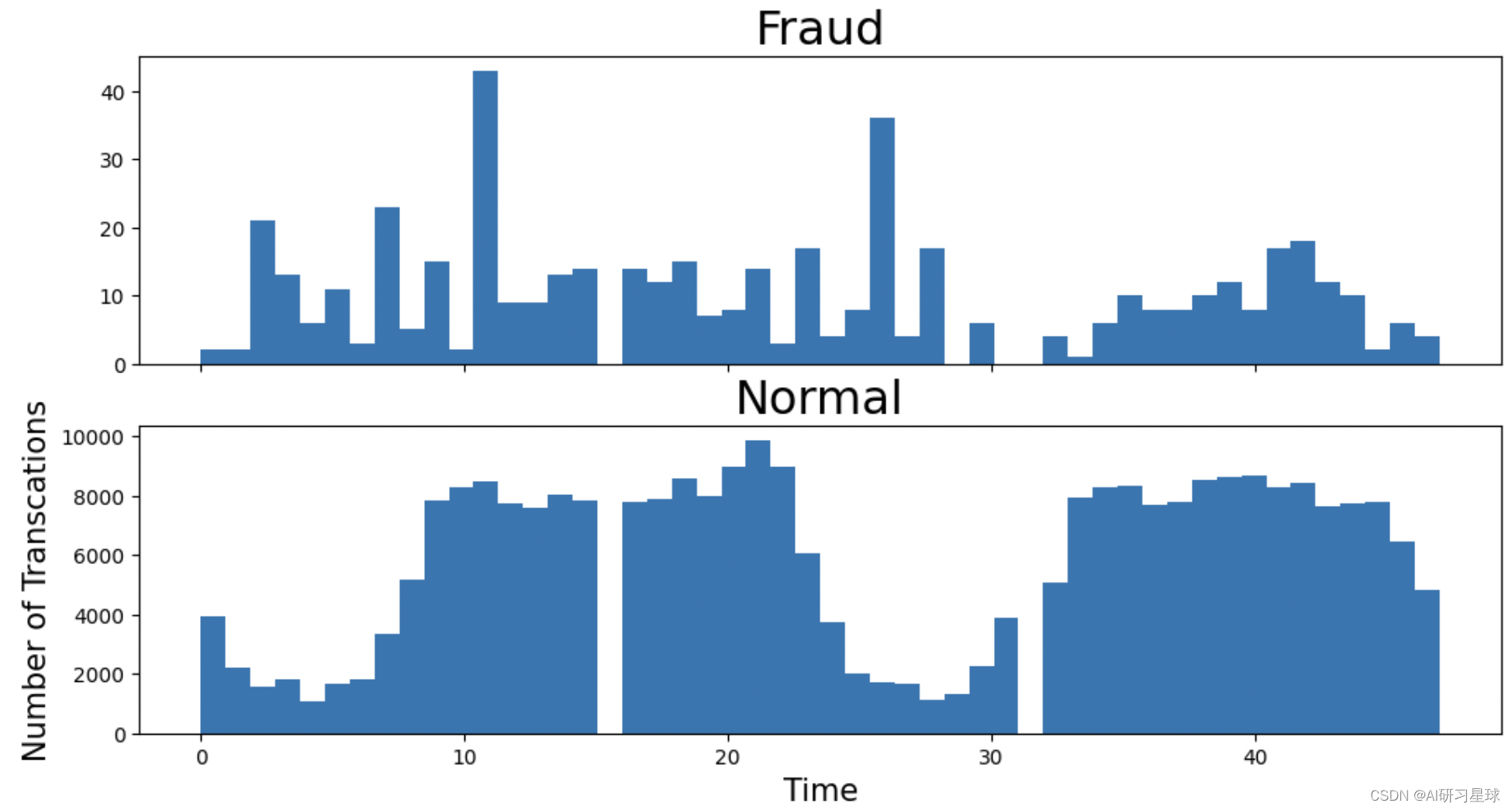
信息和(交易金额与随时间变化)单独的数量直方图反应的差不多。
输出结果显示,是48小时的信用卡交易情况,第一天0 ~ 24,第二天24 ~ 48 h。
欺诈交易看起来更均匀分布,而正常交易看起来则有交易周期,所以在正常交易的交易低频时间段更容易检测到欺诈交易。信用卡欺诈交易发生的高峰期时在第一天上午11点达到47次,其余发生信用卡被盗刷案发时间在晚上时间11点至第二早上9点之间,第一天相对多于第二天,这是否节日/工作日有关;
4.4 对V1~V28分析,分析该字段下欺诈交易与非欺诈交易各自的规则
查看各变量之间关系,数据太大,只截取其中部分
#查看各变量之间的相关性
corr = data.corr()
corr
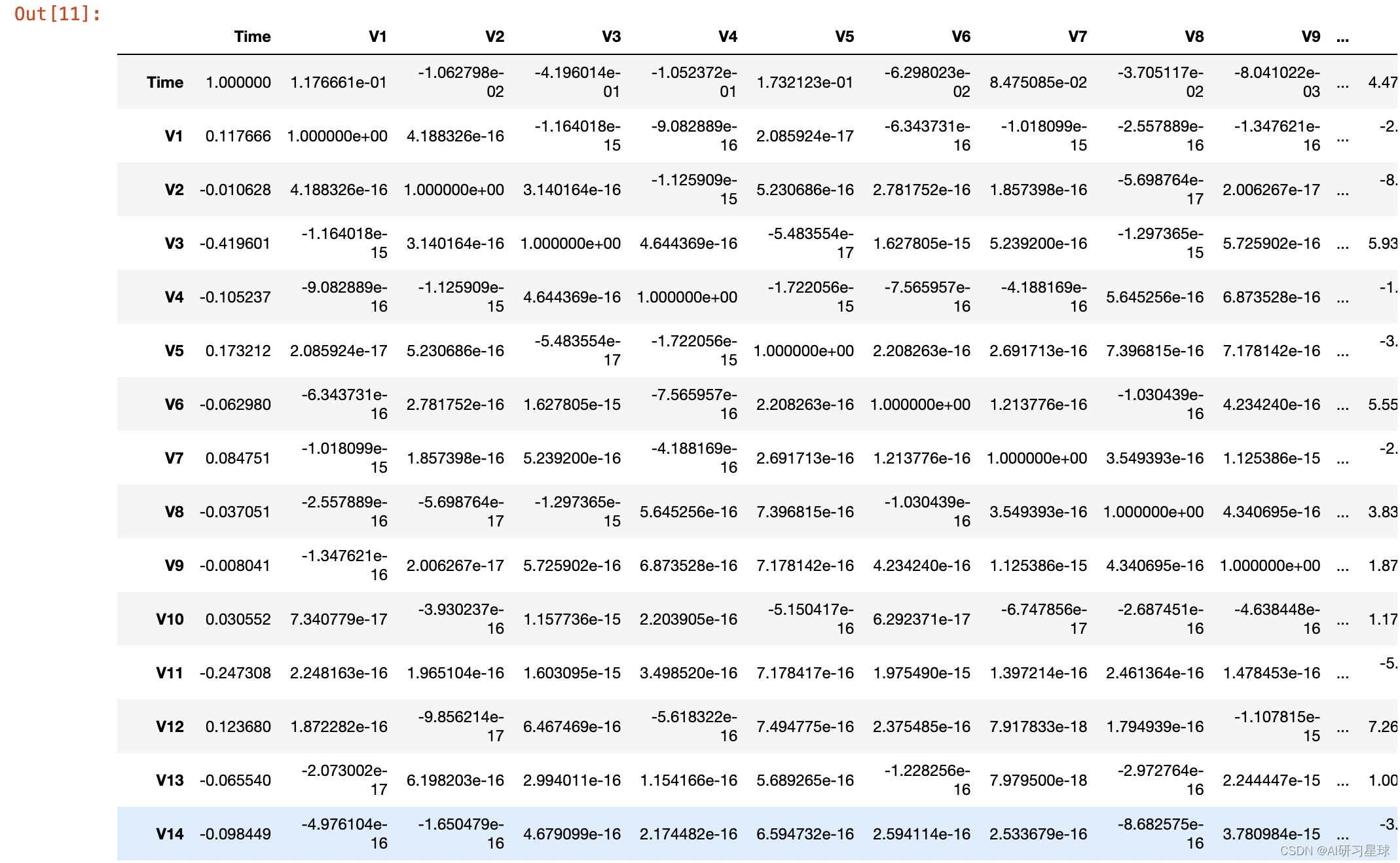
查看各变量与Class之间的相关性系数如下:V11、V4、V2这3个变量对Class的影响较大。
corr['Class']

将输出结果用可视化:
data_V = data.iloc[:,1:29]
Correlation = data_V.corr()
sns.heatmap(Correlation,cmap='coolwarm',square=True,center=0)
V1-V28 特征相关性不强,初步分析对分类的贡献率并不高,
下面分别对各个特征进行可视化,筛选贡献率相对较高的特征。
v_features = data.iloc[:,1:29].columns #选择V1-V28所有变量字段
#print(,v_features,data[v_features])
gs = gridspec.GridSpec(28,1) #设置子图的布局
#print(gs)
plt.figure(figsize=(12,4*28))
for i,j in enumerate(data[v_features]): #在同时需要index和value值的时候可以使用 enumerateax = plt.subplot(gs[i])sns.distplot(data[j][data.Class == 1],color='red')sns.distplot(data[j][data.Class == 0],color='green')plt.show()
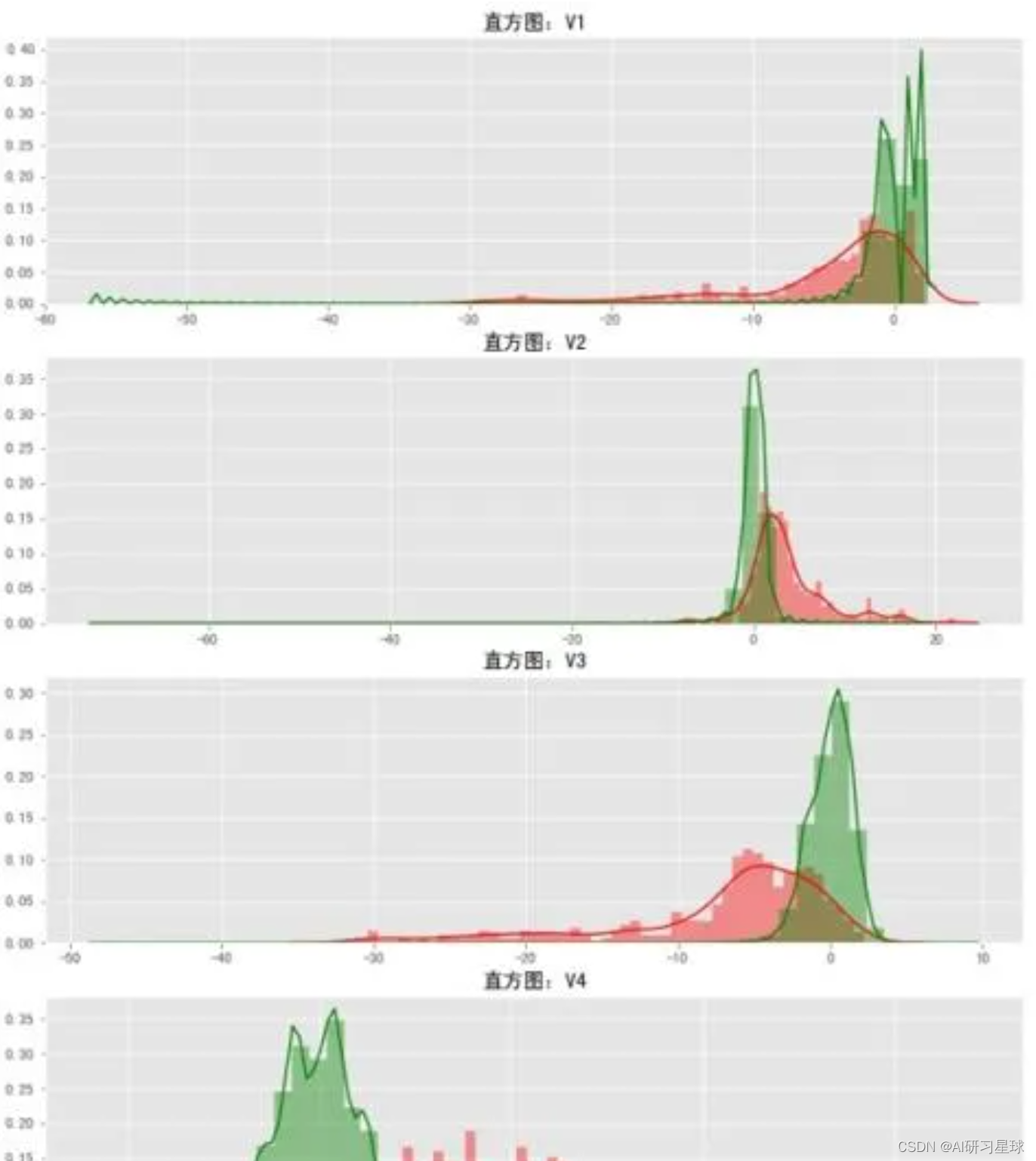
- 两个分布的交叉面积越大,欺诈与正常的区分度最小,如V15;
- 两个分布的交叉面积越小,则该变量对因变量的影响越大,如V14
- 输出图表为不同变量在信用卡欺诈交易和信用卡正常交易的不同分布情况,有很多特征的分布,欺诈交易和正常交易的分布非常相似,对分析贡献不大,可以剔除,选择选择在不同信用卡状态下的分布有明显区别的变量V1、V2、V3、V4、V5、V6、V7、V9、V10、V11、V12、V14、V16、V17、V18、V19。
5. 数据分析结论
- 数据集显示284,807笔交易中有492个欺诈。数据集高度不平衡,欺诈交易占总交易的比例是492/(284315+492)*100%=0.172%。
- 最大的欺诈交易金额为2125.87,金额不大,且整体的欺诈交易金额都集中在小额交易。且随时间变化分布均匀,与时间的单独分析情况差不多,具有周期性。
- 欺诈交易看起来更均匀分布,而正常交易看起来则有交易周期,所以在正常交易的交易低频时间段更容易检测到欺诈交易。信用卡欺诈交易发生的高峰期时在第一天上午11点达到47次,其余发生信用卡被盗刷案发时间在晚上时间11点至第二早上9点之间,第一天相对多于第二天,这是否节日/工作日有关;
- 对信用卡正常交易与否影响最大的3个变量是:V11、V4、V2。
关注公众号:『AI学习星球』
回复:利用python进行信用卡欺诈检测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我
6. 构建逻辑回归分析信用卡欺诈预测模型
建立逻辑回归模型,并通过AUC值进行模型评估,AUC(Area Under roc Curve)是一种用来度量分类模型好坏的一个标准,AUC越大,分类器分类效果越好。
第1步,数据的特征处理
V1-V28列的数据已经经过特征化处理,所以无需再做其他处理。但以下数据需要做处理:
- Time列和Amount列:数据规格和其他特征相差较大,因此为了避免权重影响,需要要进行特征缩放(标准化处理)
- Class列:Class=0和Class=1的频数相差较大,数据分布不均衡。
a. 对Time和Amount列进行标准化收敛
#数据的特征处理from sklearn.preprocessing import StandardScaler #导入工具包std = StandardScaler() #初始化缩放器data['Amount_p'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1,1)) #对Amount标准化
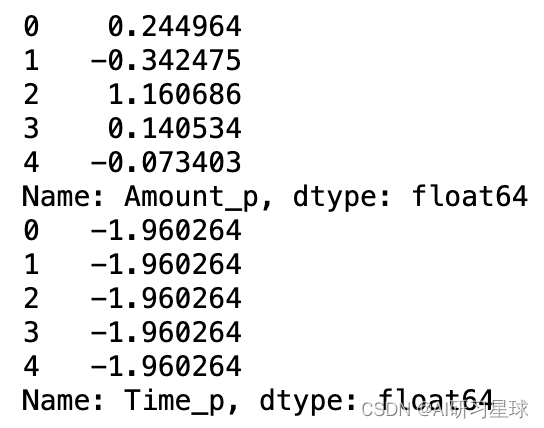
print(data['Amount_p'].head())
data['Time_p'] = StandardScaler().fit_transform(data['Time'].values.reshape(-1,1)) #对Time标准化
print(data['Time_p'].head())
b. 针对Calss,利用逻辑回归算法建立欺诈预测模型。
#拆分训练集和测试集
from sklearn.cross_validation import train_test_split# 构建自变量和因变量
X = np.array(data.iloc[:, data.columns != 'Class']) # 选取特征列数据
y = np.array(data.iloc[:, data.columns == 'Class']) # 选取类别labelprint('X shape:',X.shape, '\n y shape:',y.shape)
print('----------------')train_X,test_X,train_y,test_y = train_test_split(X,y,train_size=0.8)print('训练集数据大小为',train_X.size,train_y.size)
print('测试集数据大小为',test_X.size,test_y.size)

#导入逻辑回归模型
from sklearn.linear_model import LogisticRegression#构建逻辑回归分类器
modelLR=LogisticRegression() #建立训练模型
modelLR.fit(train_X,train_y)#查看模型
print('modelLR')
print(modelLR)#用测试集数据进行测试,模型评分(即准确率)
modelLR.score(test_X,test_y)# 通过分类器产生预测结果,
#predicted1 = modelLR.predict(X) #print("Test set accuracy score: {:.5f}".format(accuracy_score(predicted1, y,)))
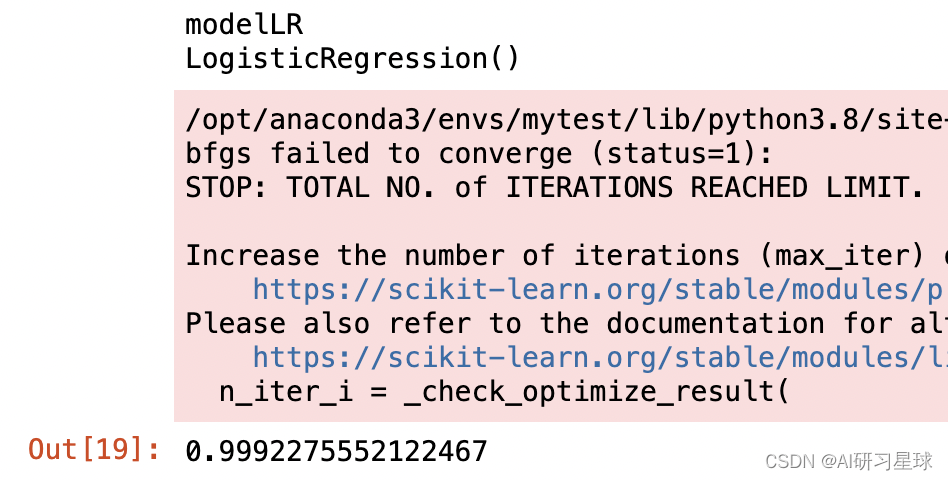
该模型的分类准确率为0.999
#预测情况
pred_y = modelLR.predict(test_X)
pred_y
array([0, 0, 0, …, 0, 0, 0])
#得到模型混淆矩阵
from sklearn.metrics import confusion_matrix
#混淆矩阵
confusion_matrix(test_y,pred_y)

从混淆矩阵可以看出:TN=56851,FP=7,FN=39,TP=65
- 该模型的准确率ACC为(56851+65)/(56851+7+39+65)=0.999991222。
- 真正率TPR和假正率FPR分别为0.625和0.000,说明该模型对负例的甄别能力更强(如果数据量更多,该指标更有说服性)。
#查看分类报告
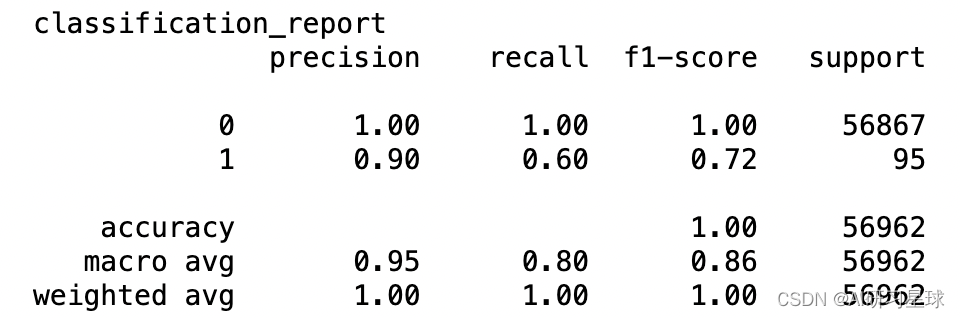
from sklearn import metrics
print('classification_report')
print(metrics.classification_report(test_y,pred_y))
#查看预测精度与决策覆盖面from sklearn.metrics import roc_curve, auc ###计算roc和aucfpr,tpr,threshold = roc_curve(test_y, pred_y) #计算真正率和假正率
roc_auc = auc(fpr,tpr) #计算auc的值
print('roc_auc: %f' %roc_auc)
print('Area under the curve:%f'%(metrics.roc_auc_score(test_y, pred_y)))
roc_auc: 0.799947
Area under the curve:0.799947
模型精度即AUC数值为0.812
通过以上分析,说明该模型具有较高的精准度,可以通过该模型进行自动批量化处理信用卡交易数据,完成欺诈检测,进行风险评估。
关注公众号:『AI学习星球』
回复:利用python进行信用卡欺诈检测 即可获取数据下载。
算法学习、4对1辅导、论文辅导或核心期刊可以通过公众号或➕v:codebiubiu滴滴我