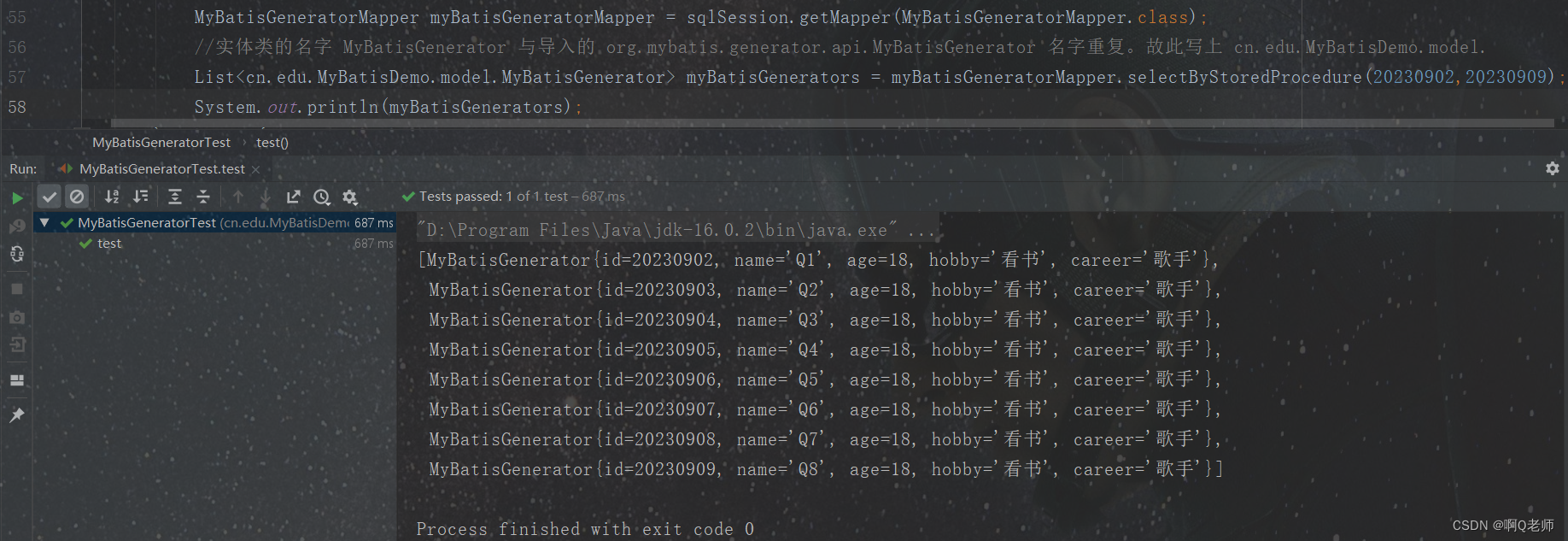
目录
mySQL事务
1.事务的概念
2.事务的ACID特点
3.多客户端同时访问一个表时,出现的一致性问题
4.事务的隔离级别
5.事务的隔离级别作用范围
查询全局事务隔离级别
设置全局事务隔离级别
编辑查询会话事务隔离级别
设置会话事务隔离级别
6.事务控制语句
测试提交事务
测试回滚事务
测试多点回滚
7.使用set设置控制事务
实验
mySQ存储引擎
1.定义
2.常用的存储引擎
myisam和innoDB的区别
3.查看系统支持的存储引擎
4.查看表使用的存储引擎
5.修改存储引擎
6.通过create table创建表时指定存储引擎
7.InnoDB行锁与索引的关系
3.死锁
如何避免死锁
mySQL事务
1.事务的概念
- 事务是一种机制、一个操作序列,包含了一组数据库操作命令,并且把所有的命令作为一个整体一起向系统提交或撤销操作请求,即这一组数据库命令要么都执行,要么都不执行。
- 事务是一个不可分割的工作逻辑单元,在数据库系统上执行并发操作时,事务是最小的控制单元。
- 事务适用于多用户同时操作的数据库系统的场景,如银行、保险公司及证券交易系统等等。
- 事务通过事务的整体性以保证数据的一致性
- 事务能够提高在向表中更新和插入信息期间的可靠性
2.事务的ACID特点
原子性(A):
- 事务管理的基础,把事务中的所有操作看作是一个不可分割的工作单元,要么执行,要么不执行
一致性(C):
- 事务管理的目的,保证事务开始前和结束后数据的完整性一致
隔离性(I):
- 事务管理的手段,使多个事务并发操作同一个数据表时,每个事务都有各自独立的数据空间,事务的执行不会收到其他事务的干扰,可通过设置隔离级别解决不同的一致性问题
持久性(D):
- 事务管理的结果,当事务被提交以后,事务中的命令操作修改的记过会被持久保存,且不会被回滚
3.多客户端同时访问一个表时,出现的一致性问题
脏读
- 当一个事务正在访问数据,并且对数据进行了修改,而这种修改还没有提交到数据库中,这时,另外一个事务也访问这个数据,然后使用了这个数据。
不可重复读
- 指在一个事务内,多次读同一数据。在这个事务还没有结束时,另外一个事务也访问该同一数据。那么,在第一个事务中的两次读数据之间,由于第二个事务的修改,那么第一个事务两次读到的的数据可能是不一样的。这样就发生了在一个事务内两次读到的数据是不一样的,因此称为是不可重复读。(即不能读到相同的数据内容)
幻读
- 一个事务对一个表中的数据进行了修改,这种修改涉及到表中的全部数据行。同时,另一个事务也修改这个表中的数据,这种修改是向表中插入一行新数据。那么,操作前一个事务的用户会发现表中还有一个没有修改的数据行,就好象发生了幻觉一样。
丢失更新
- 两个事务同时读取同一条记录,A先修改记录,B也修改记录(B不知道A修改过),B提交数据后B的修改结果覆盖了A的修改结果。
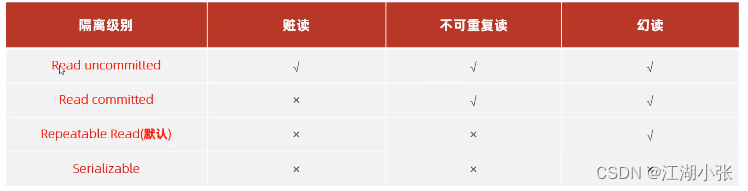
4.事务的隔离级别
- MySQL事务支持如下四种隔离,用以控制事务所做的修改,并将修改通告至其它并发的事务
未提交读(Read Uncommitted(RU))
- 允许脏读,即允许一个事务可以看到其他事务未提交的修改。
提交读(Read Committed(RC))
- 允许一个事务只能看到其他事务已经提交的修改,未提交的修改是不可见的。防止脏读。
可重复读(Repeatable Read(RR)) -- mysql默认的隔离级别
- 确保如果在一个事务中执行两次相同的SELECT语句,都能得到相同的结果,不管其他事务是否提交这些修改。可以防止脏读和不可重复读。
串行读(Serializable):---相当于锁表
- 完全串行化的读,将一个事务与其他事务完全地隔离。每次读都需要获得表级共享锁,读写相互都会阻塞。可以防止脏读,不可重复读取和幻读,(事务串行化)会降低数据库的效率。
5.事务的隔离级别作用范围
- 全局级:对所有的会话有效
- 会话级:只对当前的会话有效
查询全局事务隔离级别
show global variables like '%isolation%';
SELECT @@global.tx_isolation;
设置全局事务隔离级别
set global transaction isolation level read committed;
set @@global.tx_isolation='read-committed';
需要重启服务后生效 查询会话事务隔离级别
查询会话事务隔离级别
show session variables like '%isolation%';
SELECT @@session.tx_isolation;
SELECT @@tx_isolation;
设置会话事务隔离级别
set session transaction isolation level repeatable read;
set @@session.tx_isolation='repeatable-read';
总结:在事务管理中,原子性是基础,隔离性是手段,一致性是目的,持久性是结果
6.事务控制语句
begin; #开启一个事务
.... create database/table insert into update XXX set delete from #事务性操作
savepoint XX; #在事务中创建回滚点
rollback to XX; #在事务中回滚操作到指定的回滚点位置
commit; 或 rollback; #提交或回滚结束事务例:
use ybc;
create table cxk(id int(10) primary key not null,name varchar(40), money double);
insert into cxk values(1,'A',1000);
insert into cxk values(2,'B',1000); 

测试提交事务
begin;
update cxk set money= money - 100 where name='A';
commit;
quit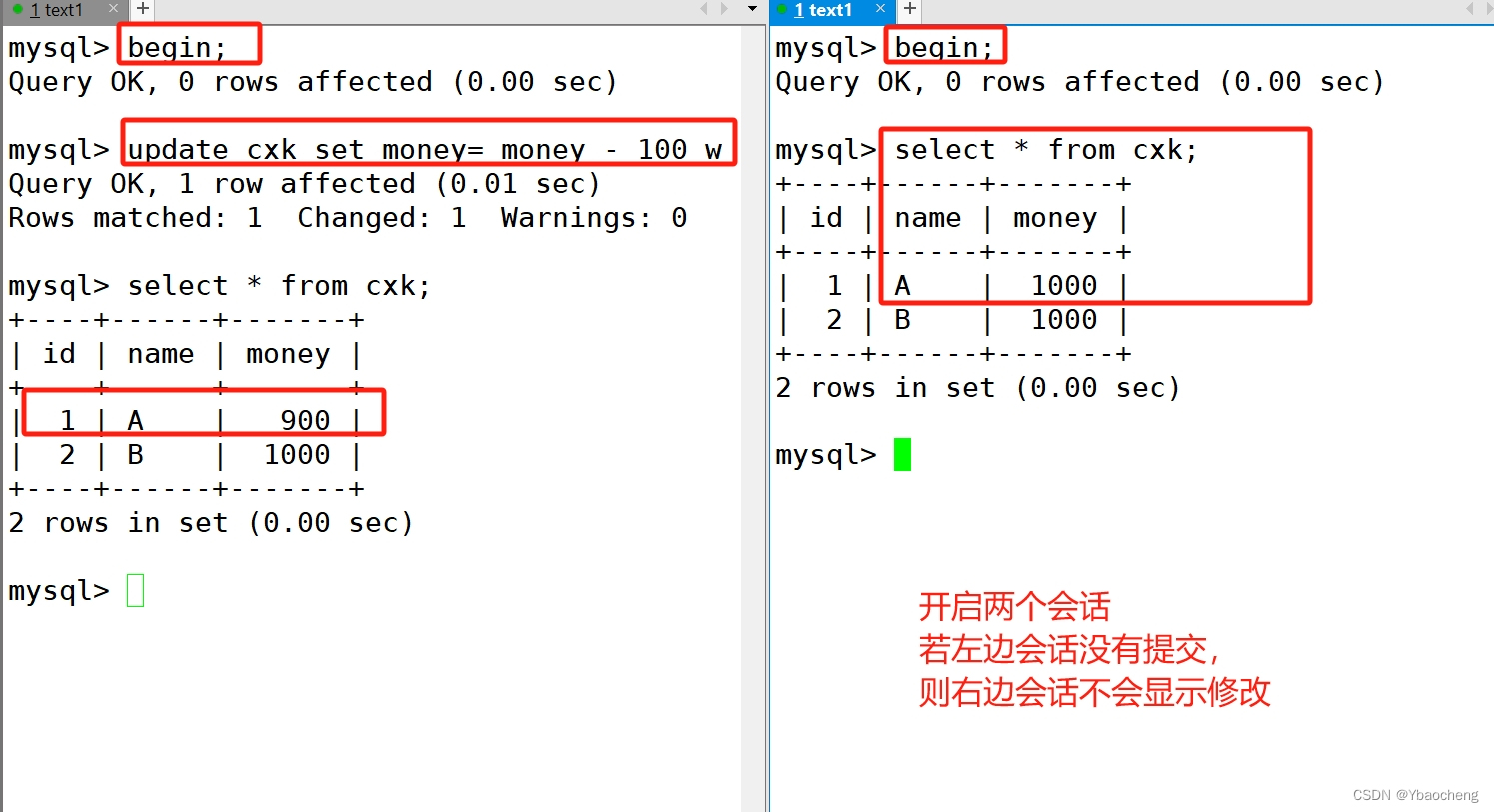

测试回滚事务
begin;
update cxk set money= money + 100 where name='A';
rollback;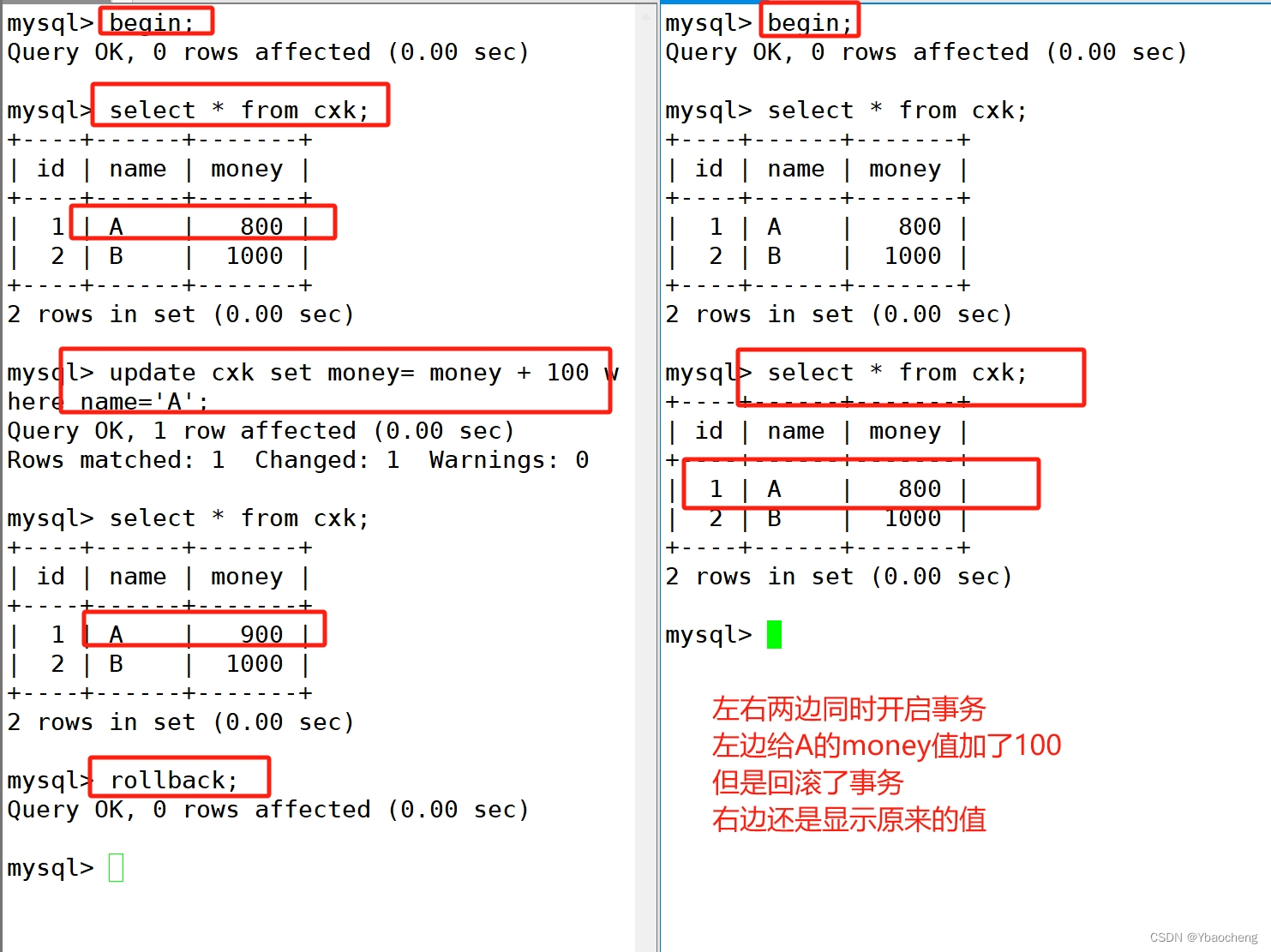
测试多点回滚
begin;
update cxk set money= money + 100 where name='A';
SAVEPOINT S1;
update cxk set money= money + 100 where name='B';
SAVEPOINT S2;
insert into cxk values(3,'C',1000);select * from cxk;
ROLLBACK TO S1;
select * from cxk;

7.使用set设置控制事务
SET AUTOCOMMIT=0; #禁止自动提交
SET AUTOCOMMIT=1; #开启自动提交,Mysql默认为1
SHOW VARIABLES LIKE 'AUTOCOMMIT'; #查看Mysql中的AUTOCOMMIT值- 如果没有开启自动提交,当前会话连接的mysql的所有操作都会当成一个事务直到你输入rollback|commit;当前事务才算结束。当前事务结束前新的mysql连接时无法读取到任何当前会话的操作结果。
- 如果开起了自动提交,mysql会把每个sql语句当成一个事务,然后自动的commit。
- 当然无论开启与否,begin; commit|rollback; 都是独立的事务
实验
use ybc;
select * from cxk;
SET AUTOCOMMIT=0;
update cxk set money= money + 100 where name='B';
select * from cxk;
quit 

mySQ存储引擎
1.定义
存储引擎是mysql数据库中的组件,负责执行实际的数据I/O操作(数据的存储和操作),工作在文件系统之上,数据库的数据会先传到储存引擎,再按照存储引擎的存储格式保存到文件系统
2.常用的存储引擎
- myisam
- innoDB
myisam和innoDB的区别
myIsam:
- 不支持外键约束
- 支持表记锁定,适合单独的查询和插入操作
- 读写会相互阻塞,至此全文索引,硬件资源占用少
- 数据文件和索引文件是分开存储的(存储存储成三个文件:表结构文件.frm、数据文件.MYD、索引文件.MYI)
使用场景:适用于不需要事务至此,单独查询或插入数据的业务场景
innoDB:
- 支持事务,外键约束
- 支持行级锁定(再主表扫描时依然会表记锁定)
- 读写性能,并发性能较好,支持全文索引(5.5版本之后)
- 缓存能力好,可以减少磁盘的IO压力
使用场景:适用于需要事务的支持,一致性要求较高,数据会频繁更新,读写并发高的业务场景
3.查看系统支持的存储引擎
show engines;
4.查看表使用的存储引擎
#方法一
show table status from 库名 where name='表名'\G#方法二
use 库名;
show create table 表名;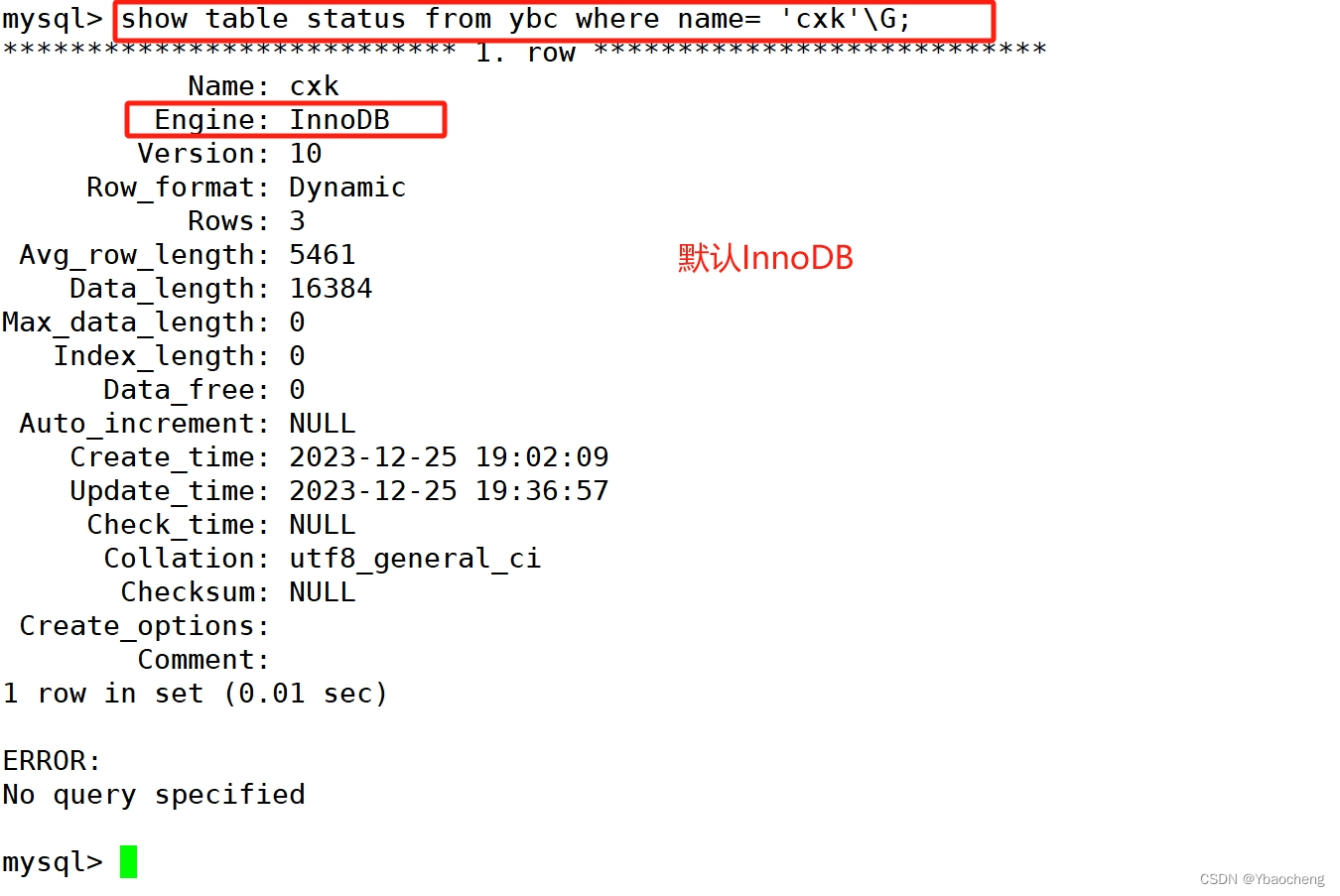
5.修改存储引擎
#方法一
use 库名;
alter table 表名 engine=MyISAM;#方法二
通过修改 /etc/my.cnf 配置文件,指定默认存储引擎并重启服务
vim /etc/my.cnf
......
[mysqld]
......
default-storage-engine=INNODBsystemctl restart mysql.service注意:此方法只对修改了配置文件并重启mysql服务后新创建的表有效,已经存在的表不会有变更。

6.通过create table创建表时指定存储引擎
use 库名;
create table 表名(字段1 数据类型,...) engine=MyISAM;
7.InnoDB行锁与索引的关系
- InnoDB行锁是通过给索引项加锁来实现的,如果没有索引,InnoDB将通过隐藏的聚簇索引来对记录加锁。
delete from t1 where id=1;
如果id字段是主键,innodb对于主键使用了主键索引,会直接锁住整行记录。delete from t1 where name='aaa';
如果name字段是普通索引,会先锁住索引的两行,接着会锁住相应主键对应的记录。delete from t1 where age=23;
如果age字段没有索引,会使用全表扫描过滤,这时表上的各个记录都将加上锁。
3.死锁
- 死锁一般是事务相互等待对方资源,最后形成环路造成的
案例:
create table t1(id int primary key, name char(3), age int);
insert into t1 values(1,'aaa',22);
insert into t1 values(2,'bbb',23);
insert into t1 values(3,'aaa',24);
insert into t1 values(4,'bbb',25);
insert into t1 values(5,'ccc',26);
insert into t1 values(6,'zzz',27);
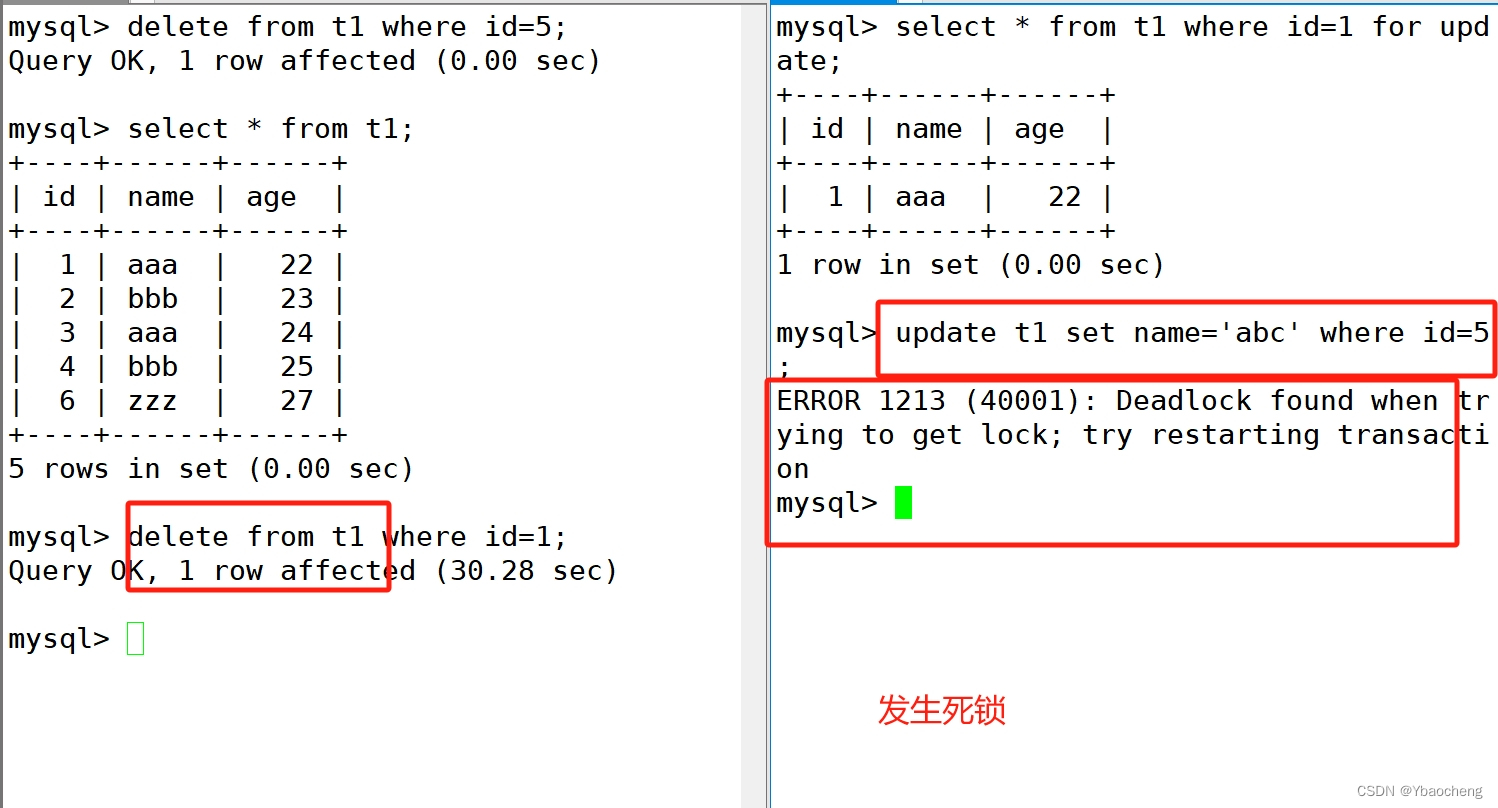
- for update 可以为数据库中的行上一个排它锁。当一个事务的操作未完成时候,其他事务可以读取但是不能写入或更新。
- 共享锁:又叫做读锁,当用户要进行数据的读取时,对数据加上共享锁,共享锁可以同时加上多个。
- 排他锁:又叫做写锁,当用户要进行数据的写入时,对数据加上排他锁,排他锁只可以加一个,它和其它的排他锁,共享锁都相斥。
如何避免死锁
- 设置事务超时等待时间 innodb_lock_wait_timeout
- 设置开启死锁检测 innodb_deadlock_detect
- 为表添加合理的索引,减少表锁发生的概率
- 如果业务允许,可以降低隔离级别,比如采用 提交读 隔离级别
- 建议开发人员尽量使用更合理的业务逻辑,多表操作时以固定顺序访问表,尽量避免同时锁定多个资源
- 建议开发人员尽量保持事务简短,减少对资源的占用时间和占用范围
- 建议开发人员在读多写少的场景下适用乐观锁机制