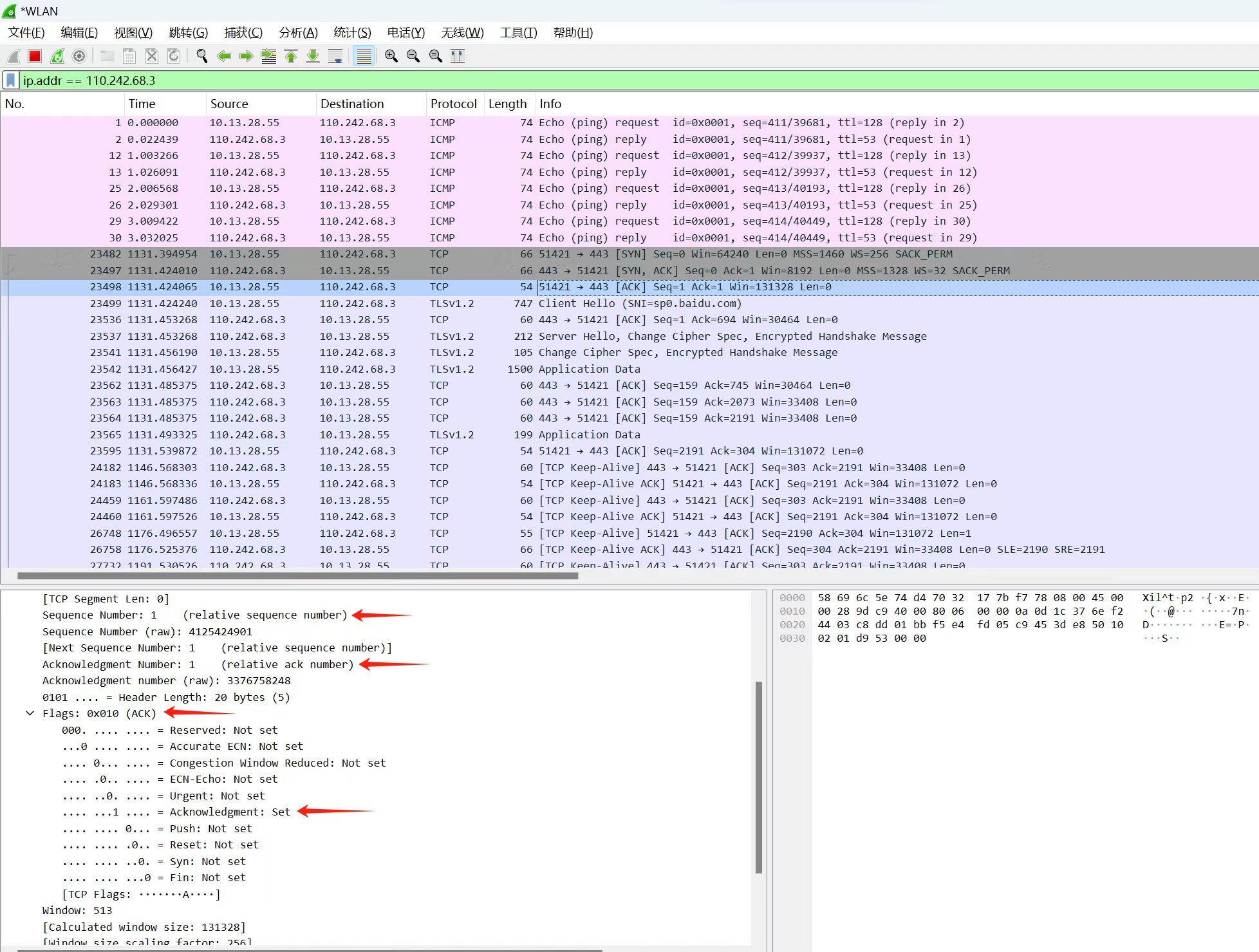
系列文章目录
总结一下近5年的三维生成算法,持续更新
文章目录
- 系列文章目录
- 一、LRM:单图像的大模型重建(2023)
- 摘要
- 1.前言
- 2.Method
- 3.实验
- 二、SSDNeRF:单阶段Diffusion NeRF的三维生成和重建(ICCV 2023)
- 1 单阶段扩散NeRF训练
- 2 图像引导下的采样和微调
- 3 一些细节
- 三、ZeroRF:Zero Pretraining的快速稀疏视图360°重建(CVPR 2023)
- 1 对特征Volume的分解
- 2 Generator 架构
- 3.3 Decoder 架构
- 四、DiffRFL: 渲染引导的三维辐射场 Diffusion
- 1.3D 辐射场
- 2.生成辐射场
- 3.训练目标
- 4.实验
- 五、EG3D:高效的几何感知的三维生成对抗网络(CVPR 2022)
- 1.常见的:3D场景的神经表示方法
- 2.几种 生成式 3D-aware图像合成 对比
- 3.Tri-plane hybrid 3D 表示
- 4. 3D GAN framework
- 5.实验对比、应用
- 总结
一、LRM:单图像的大模型重建(2023)
题目:LRM: LARGE RECONSTRUCTION MODEL FOR SINGLE IMAGE TO 3D
论文:https://arxiv.org/pdf/2311.04400.pdf
来源:Adobe Research / Australian National Univeristy
项目:https://yiconghong.me/LRM/
摘要
LRM,是一个大型重建模型,可以在5秒内从单个输入图像中预测一个物体的三维模型。与以前小规模数据集上训练的ShapeNet等特定类别的方法相比,LRM采用了一种高度可扩展的基于Transformer的架构(具体使用DINO作为图像编码器),具有5亿个可学习参数。以数据驱动的方式(在不同类别的大约100万种三维形状和视频数据上训练)从单个图像中学习对象的三维表示,直接从输入图像中,以三平面表示的形式回归一个NeRF。
具体的:LRM学习了一个图像到三平面的Transformer解码器,通过交叉注意,将二维image特征投影到三平面上,并通过自注意对空间结构的三平面token 之间的关系进行建模。
1.前言
NLP任务(如GPT)巨大成功的三要素:
(1)使用高度可扩展和有效的神经网络,如Transformer。
(2)用于学习通用先验的巨大数据集
(3)类似我监督的训练目标,鼓励模型发现底层数据结构,同时保持高可扩展性
GINA-3D 应用VIT编码器和交叉注意(而不是LRM中的Transformer 解码器)将图像转换为三平面表示。但模型和训练规模很小,对特定类别的生成有不同的关注。最近的数据驱动方法MCC利用CO3D-v2数据训练一个可推广的基于Transformer 的解码器,从输入图像及其未投影点云预测占用率和颜色。虽然MCC可以处理真实的和生成的图像和场景,但结果通常过于平滑,失去了细节。
2.Method
LRM架构如(图1):包含一个图像Encoder(预训练的DINO),它将输入图像编码为patch 尺度的特征token;然后是一个图像到三平面Decoder,通过交叉注意将图像特征投射到三平面token上。输出的三平面token被上采样并重塑为reshape的三平面表示,用于查询三维点特征。最后,将三维点特征传递到多层感知,以预测RGB和密度进行体积渲染。
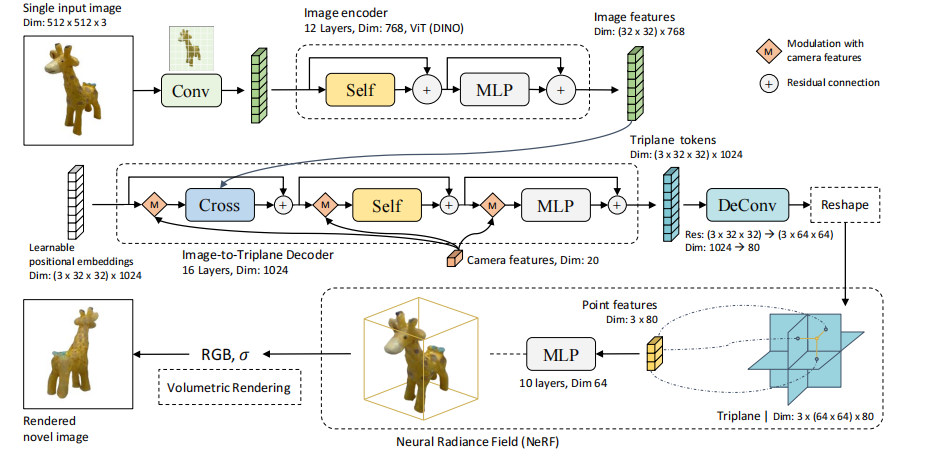
- 编码器
预训练DINO得到的图像 patch特征表示为: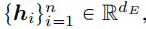
i 表示图像patch索引,n是patch总数,dE 是编码器维度。DINO是一个自蒸馏训练的模型,它学习对图像中显著内容的结构和纹理的可解释注意力,LRM可以使用它来重建三维空间的几何和颜色。
- 解码器
Transformer解码器:将(图像和摄像机特征)投射到(可学习的空间位置嵌入)上,并将它们转换为三平面表示。 该解码器可以被认为是一个先验网络,用大规模数据进行训练, 以提供必要的几何和外观信息,以补偿单图像重建的模糊性 。
像机特征。我们将4×4的相机外参E(表示 camera-to-world 变换)展开,并将其与相机焦距 foc 和参考点 pp 连接来构造输入图像的相机特征 c=[E1×16, focx, focy, ppx, ppy], c∈R20。此外,我们通过相似性变换对摄像机的外参E进行归一化,使所有的输入摄像机在同一个轴上对齐(查找方向与z轴对齐)。 请注意,LRM并不依赖于对象的标注pose,而Groundtruth只应用于训练。对归一化摄像机参数的调节大大减少了三平面特征的优化空间,便于模型的收敛。 为了嵌入相机特征,我们进一步实现了一个多层感知器(MLP),将相机特征映射到高维嵌入 c ~ \tilde{c} c~。像机内参(焦距和参考点)在输入MLP层之前,由图像的高和宽进行归一化。
三平面特征。一个三平面T包含三个轴对齐的特征平面TXY、TYZ和TXZ,每个平面的维数为(64×64)×dT,其中64×64为空间分辨率,dT为特征通道的数量。对于NeRF物体的边界框[-1,1]3内三维点,可将其投影到每个平面上,通过双线性插值查询相应的点特征 (TXY,TYZ,TXZ) ,然后由MLPNeRF解码为NeRF颜色和密度.
在前向过程中,基于摄像机特征 c ~ \tilde{c} c~和图像特征{hin},图像到三平面Transformer解码器的每一层,分别通过modulation和交叉注意力,将初始位置嵌入 finit,更新到最终的三平面特征。 应用两种不同的条件操作的原因是,照相机控制了整个形状的方向和失真,而图像特征则携带了需要嵌入到三平面上的细粒度的几何和颜色信息
像机特征的Modulation。相机特征的Modulation受到DiT的启发,它实现了一个adaptive layer 范数(adaLN),通过去噪时间步长和类别标签来,modulate 图像的latents 。假设{fj}是Transformer中的一个向量序列,将摄像机特征c的Modulation函数定义为:
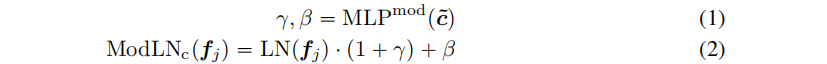
Transformer layers:包含一个交叉注意子层、一个自注意子层和一个MLP层(每个子层的输入token,由摄像机特征Modulate)。假设特征序列 fin 是Transformer 层的输入(可以视为三平面隐藏特征,因为它们对应于最终的三平面特征T)。过程如下:
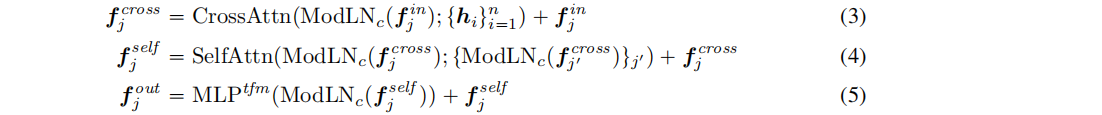
3. 三平面NeRF
从三平面表示T中查询的点特征来预测RGB和密度σ(代表MLPNeRF输出的4维度)。MLPNeRF包含多个线性层,与ReLU激活。
- 训练目标
LRM从单视图生成3D形状,并利用额外的侧视图来指导训练时的重建:每个形状随机选择V-1个侧视图作为监督。V个渲染视图 x ^ \hat{x} x^和GT(包括输入视图和侧视图)之间损失:
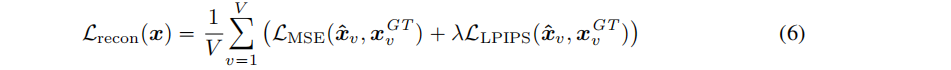
3.实验
数据集采用 Objaverse和MVImgNet,分别包括合成3D数据和现实数据视频,以学习可推广的交叉形状3D先验。对于每个3D物体,将形状归一化为世界空间中的[-1,1]3,以任意pose渲染32个随机视图,分辨率为1024×1024,相机pose从半径为 [1.5、30]、高度范围为[-0.75、1.60]3 的球中采样。总共预处理了730,648个3D assets和220,219个视频进行训练。
二、SSDNeRF:单阶段Diffusion NeRF的三维生成和重建(ICCV 2023)
题目:Single-Stage Diffusion NeRF: A Unified Approach to 3D Generation and Reconstruction
论文:https://arxiv.org/pdf/2304.06714.pdf
任务:无条件3D生成(如从噪音中,生成不同的车等)、单视图3D生成
机构:Hansheng Chen,1,* Jiatao Gu,2 Anpei Chen, 同济、苹果、加利福尼亚大学
代码:https://github.com/Lakonik/SSDNeRF
SSDNeRF,一个expressive的三平面NeRF自动解码器,与三平面 latent diffusion 模型连接起来的框架。图3提供了该模型的概述。
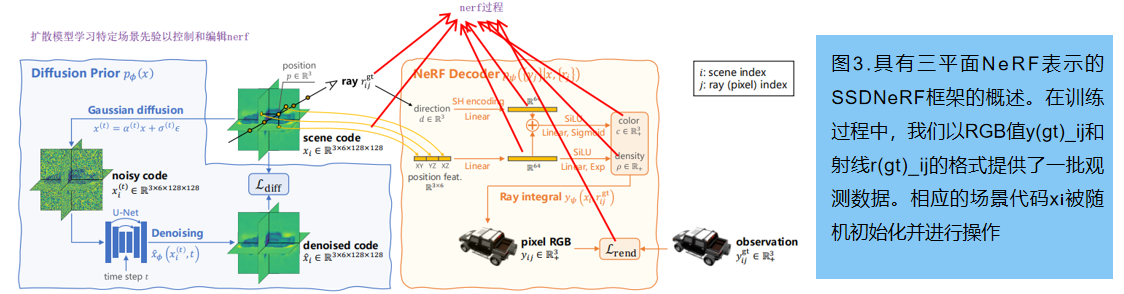
1 单阶段扩散NeRF训练
训练目标可以以类似于VAEs的方式推导出。利用NeRF解码器
pψ({yj} | x, {rj}) 和扩散潜先验 pϕ(x),训练目标:最小化观测数据{yijgt,rijgt}的负对数似然(NLL)的变分上界。忽略 latent code 中的不确定性(方差),得到一个简化的训练损失:
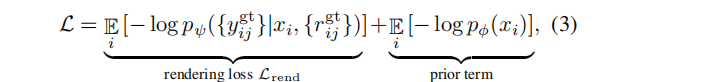
其中,场景码 {xi} 、先验参数 ϕ 和解码器参数 ψ 在单个训练阶段中共同进行优化。这个损失包括渲染损失 Lrend,以及一个以NLL形式存在的扩散先验项。仿照[Maximum likelihood training of score-based diffusion models, Score-based generative modeling in latent space 等]论文,我们用近似上界 Ldiff (也被称为分数蒸馏)代替扩散NLL 。加入经验权重因子,最终的训练目标:
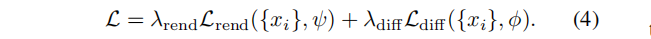
单阶段训练,使用以上损失约束场景码 {xi},允许学好的先验完成看不见的部分,这对于稀疏视图数据的训练特别有益(expressive triplane codes 严重不确定)
渲染和先验权重的平衡
渲染-先验的权重比 λrend/λdiff 是单阶段训练的关键。为保证泛化,设计了一个经验加权机制,其中扩散损失由场景码的 Frobenius 范数的指数移动平均(EMA)归一化,表示为:
λdiff := cdiff / EMA(||xi||2F) , cdiff 为固定尺度;
λrend := crend(1−e−0.1Nv)/Nv。 渲染权重由可见视图 Nv 的数量决定:基于Nv 的加权是对解码器 pψ 的校准,防止渲染损失根据射线数量线性缩放
与两阶段生成性神经场的比较
之前的两阶段方法[Gaudi,Diffrf,3d neural field generation using triplane diffusion] 在训练第一阶段,忽略了前项 λdiffLdiff。这可以看作是将 渲染-先验 的权重 λrend/λdiff 设置为无穷大,导致 biased和有噪声的场景码 xi。论文[3d neural field generation using triplane diffusion]通过在三平面场景代码上施加全变分(TV)正则化来强制进行平滑先验,部分地缓解了这一问题,类似于在潜在空间上的LDM约束(图2的中列)。 Control3Diff 提出对在单视图像上预训练的3D GAN生成的数据学习条件扩散模型。相比之下,我们的单阶段训练的目标是在促进端到端一致性之前直接纳入扩散。
2 图像引导下的采样和微调
为了实现可推广的快速NeRF重建,并覆盖了单视到密集多视的重建,我们建议执行图像引导采样,同时考虑扩散先验和渲染似然,对采样码进行微调。根据[Video diffusion models]重建引导的采样方法,计算了近似的渲染梯度g,即一个噪声码x(t):
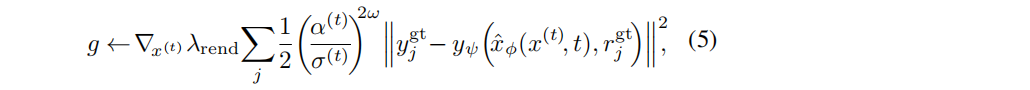
其中,(α(t)/σ(t))2ω 是一个基于信噪比(SNR)的附加加权因子 (超参数ω为0.5或0.25)。引导梯度g与无条件分数预测相结合,表示为对去噪输出 x ^ \hat{x} x^ 的修正:
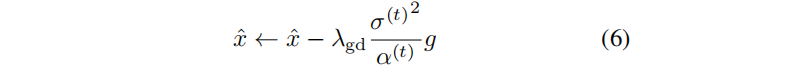
引导尺度为λgd。我们采用 预测-校正采样器[52],通过交替使用DDIM步骤和多个朗之万校正步骤来求解x(0)。
我们观察到,重建指导不能严格地执行忠实重建的渲染约束。为了解决这个问题,我们在等式4中重用,对采样的场景码 x 进行微调,同时冻结扩散和解码器参数:
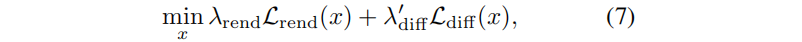
其中,λ’diff 是测试时间的先验权值,它应该低于训练权值 λdiff(因为从训练数据集学习到的先验在转移到不同的测试数据集时不太可靠)。使用Adam来优化代码x以进行微调
与以往的NeRF微调方法的比较
虽然用渲染损失进行微调在 view-conditioned 的NeRF回归方法[8,61]中很常见,但我们的微调方法在三维场景代码上使用扩散先验损失方面有所不同,这显著提高了对新视图的泛化,如5.3所示。
3 一些细节
- 先验梯度缓存
三平面NeRF重建需要对每个场景码 xi 至少进行数百次优化迭代。公式(4)中单阶段损失中,扩散损失Ldiff 比原生NeRF渲染损失Lrend 需要更长的时间来验证,降低了整体效率。为了加速训练和微调,我们引入了一种技术称为先验梯度缓存:Prior Gradient Caching,缓存的反传梯度 ∇xλdiffLdiff 重用在多个Adam步中,同时在每一步中刷新渲染梯度 ∇xλrendLrend 。它允许更少的扩散渲染比。以下是一次算法的伪代码:
- 去噪的参数化和加权
去噪模型 x ^ \hat{x} x^ϕ(x(t),t) 被实现为一个DDPM中的U-Net网络(共计122M参数)。其输入和输出分别是有噪声和去噪的三平面特征(三个平面的通道堆叠在一起)。对于测试的形式,我们采用[43:Progressive distillation for fast sampling of diffusion models]中的 v-参数化 v ^ \hat{v} v^ϕ(x(t),t),使 x ^ \hat{x} x^ = α(t)x(t)−σ(t) v ^ \hat{v} v^。关于等式(2)中扩散损失的加权函数w(t),LSGM [54]分别采用两种不同的机制来优化 latent xi 和扩散权重 ϕ ;我们发现使用NeRF自动解码器是不稳定的。相反,我们观察到在公式5中使用的基于信噪比的加权w(t) =(α(t)/σ(t))2ω 表现很好。
三、ZeroRF:Zero Pretraining的快速稀疏视图360°重建(CVPR 2023)
题目:ZeroRF: Fast Sparse View 360◦ Reconstruction with Zero Pretraining
任务:稀疏重建;拓展:Image to 3D、文本到3D
作者:Ruoxi Shi* Xinyue Wei* Cheng Wang Hao Su ,来自UC San Diego
code:https://github.com/eliphatfs/zerorf
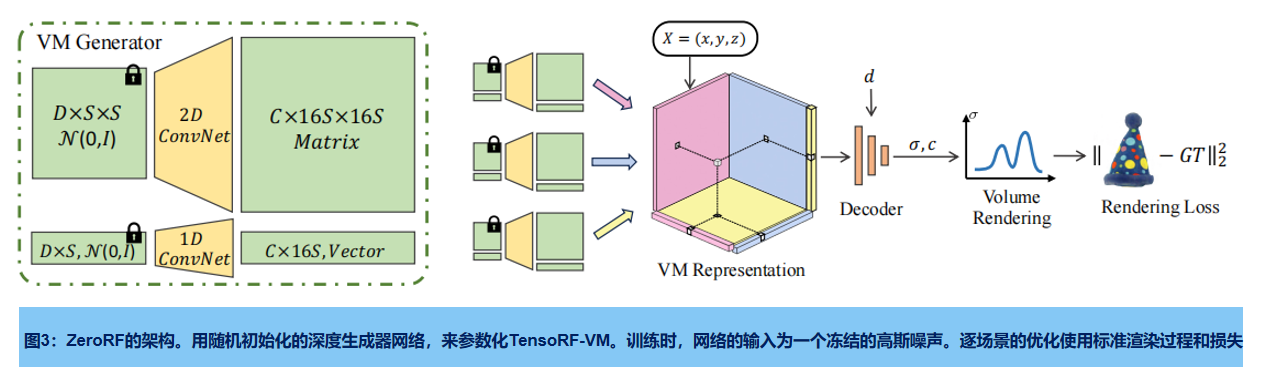
ZeroRF管道如图3所示:使用冻结标准高斯噪声样本的深度生成器网络作为输入,以TensoRF-VM的方式生成平面和向量,形成一个分解的张量特征体。然后在渲染光线中对特征体进行采样,并由多层感知器(MLP)进行解码(标准的体渲染过程,损失为MSE)。
ZeroRF的主要思想是,应用未训练的深度生成网络,作为空间特征网格的参数化。网络可以从稀疏的观察学习不同规模的模式,自然推广到不可见视图,不需要进一步的上采样技巧或显式正则化,通常需要大量的人工调整,而不是之前的工作稀疏视图重建。
重要的设计如下:空间构成(特征体的表示),表示生成器的结构;以及特征解码器的结构。
1 对特征Volume的分解
应用深度生成网络进行参数化的原理,普遍适用于任何基于网格的表示。最直接的解决方案是直接参数化一个特征 Volume。然而,如果想要高渲染质量,特征Volume将特别大,占用内存且计算效率低。TensoRF 使用张量分解来利用特征卷的低秩性。当向量为常数时,[17]中使用的三平面表示可以看作是向量为TensoRF-VM表示的一种特殊情况。DiF将特征Volume 分解为多个编码不同频率的较小Volume。Instant-NGP[39]采用了多分辨率的hashmap,因为特征中的信息本质上是稀疏的。
在这些分解中,hash 打破了相邻单元之间的空间相关性,因此不能应用深度先验。深度生成网络可用于参数化(TensoRF、triplane和DiF)。
我们构建了用于生成一维向量、二维矩阵和三维体积的生成器架构,在此基础上我们实验了所有三种分解。由于工作原理类似,比以前的技术获得了更好的性能;TensoRF-VM性能最好,作为因子分解的最终选择。
2 Generator 架构
深度参数化的质量在很大程度上取决于框架。到目前为止,大多数Generator 都是Conv 和Attention 架构, 包括深度解码器(DD)、稳定扩散(SD)、变分自动编码器(VAE)、Kadinsky中的decoder,以及基于ViT解码器的SimMIM生成器。ZeroRF将二维卷积、池化和上采样层转换为一维和三维,以得到不同分解所需的相应的一维和三维Generator 。
这些生成器最初的体积相当大,因为它们被设计成适合于一个非常大的数据集,以生成高质量的内容。当涉及到单个NeRF场景时,这将导致不必要的长运行时间和较慢的收敛。幸运的是,我们发现,当我们缩小模型的宽度和深度时,收敛后的ZeroRF的性能保持不变。因此,我们保留了block的组成,但修改了这些架构的大小,以提高训练速度 。请注意, 在推理过程中,我们只需要存储辐射场表示,而不需要存储 Generator,因此在渲染过程中,ZeroRF与它的底层因子分解方法相比,其开销为零。
我们发现,SD VAE及其解码器部分,以及Kadinsky 解码器在新的视图合成中同样有效,其次是深度解码器,而SimMIM架构,作为辐射场的深度先验被证明是无效的。SD/Kadinsky编码器大多是卷积的原始结构,Kadinsky 在前两个区块中增加了自注意力。我们将(修改后的)SD解码器作为生成器架构的最终选择,因为它的计算量最少。
3.3 Decoder 架构
我们的解码器架构遵循SSDNeRF:用线性插值(双线性或三线性)从特征网格中进行解码,将其与第一个线性层投影, 得到密度和外观解码之间共享的基本特征代码。我们发现,共享特征代码可以通过耦合几何形状和外观紧密地帮助减少漂浮物。应用SiLU激活,并调用另一个线性层来进行密度预测。对于颜色预测,我们用球形谐波(SH)对视图方向进行编码,并将其通过线性层的投影添加到基本特征中,来添加视图依赖性。然后,我们应用SiLU激活,并使用另一个类似于密度预测的线性层来预测RGB值,表示如下:
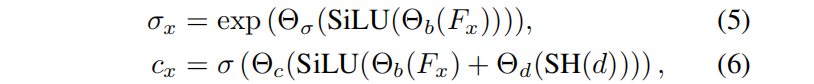
Fx 是特征场, σ(·) 是sigmoid 函数,Θ• 是线性层。与TensoRF和DiF中使用的解码器不同,该解码器不消耗任何位置编码, 否则有可能泄露(深度先验之外的)位置信息,破坏或降低ZeroRF性能。
四、DiffRFL: 渲染引导的三维辐射场 Diffusion
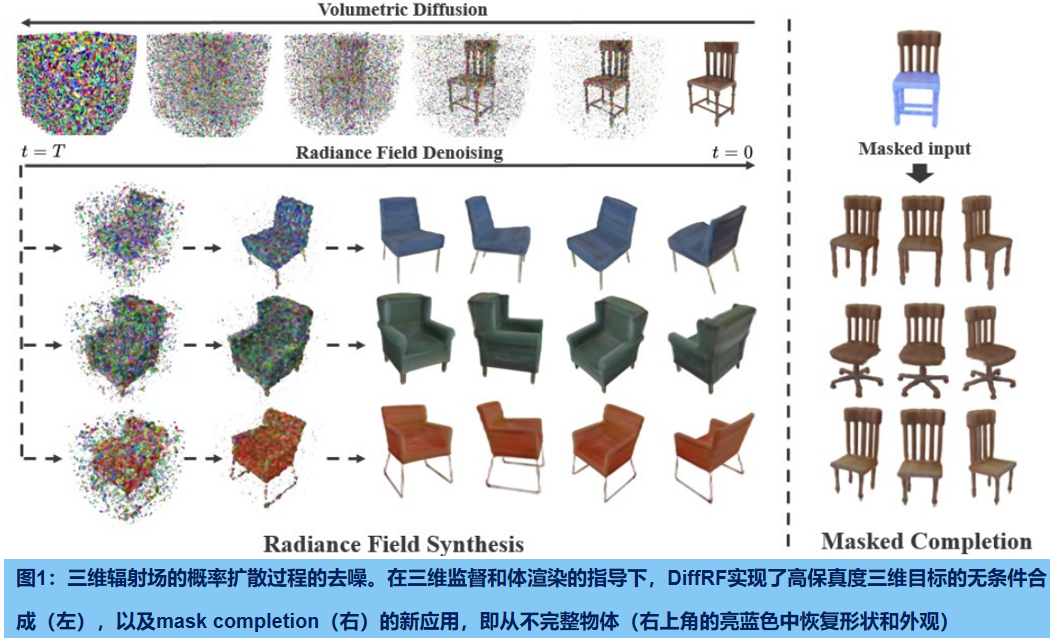
DiffRF是第一个直接生成体积辐射场的方法,直接基于显式体素网格表示的三维去噪模型。由于一组姿态图像产生的辐射场可能是模糊的,并包含伪影,难以获得辐射场的GT样本。我们通过将去噪公式与渲染损失配对来解决这一挑战,使我们的模型能够学习一个偏离的先验,有利于良好的图像质量,而不是试图复制拟合错误(如漂浮物)。与二维扩散模型相比,我们的模型学习了多视图一致的先验,实现了自由视图的合成和精确的形状生成。与3D GANs相比,DiffRF自然地实现条件生成,如 遮蔽图像复原,或单视图三维合成。
合并场景语义的两篇论文推荐:
《Panoptic neural fields: A semantic object-aware neural scene representation》CVF, 2022
《Panoptic nerf: 3d-to-2d label transfer for panoptic urban scene segmentation》3DV, 2022
多对象类别或跨数据集场景学习先验的神经场表示,是很难的任务,尽管支持单图像3D对象生成[7,41,51,69,75]和无约束场景探索[16]等应用程序。这些方法探索了将物体先验分解为基于形状和外观的组件,或将辐射场分解为几个小的局部条件辐射场,以提高场景生成质量;然而,他们的结果在摄影逼真性和几何精度上仍有显著的差距。
denoising diffusion模型很难直接应用于3D volumetric radiance fields,原因在于扩散模型的性质,它需要在噪声向量和相应的GT 数据样本之间进行一对一的映射。而辐射场的GT数据难获取,即使运行一个昂贵的逐样本NeRF优化,也会导致不完全的辐射场重建。
DiffRF是直接基于显式体素网格表示的三维去噪模型(图1,左图),从而产生高频噪声估计。为了解决每个训练样本的模糊和不完全的辐射场表示,我们提出将去噪扩散概率模型(DDPMs)的噪声预测公式偏向于通过估计的额外的体渲染损失来合成更高的图像质量。这使得我们的方法能够学习辐射场先验,更不容易在采样过程中拟合伪影或噪声积累。学习到的扩散先验可以应用于无条件的设置,其中三维对象合成以多视图一致的方式获得,生成高精度的三维形状,并允许自由视图合成。
1.3D 辐射场
我们的方法包括一个三维对象的生成模型,建立在最近的最先进的扩散概率模型[24]。实现辐射场的方法,从神经网络[39]到显式体素网格[28,61]。我们选择了后者,因为它可以实现良好的渲染质量,以及更快的训练和推理。通过对体素顶点的双线性插值,可以在连续位置上查询显式网格。
在显式表示下,辐射场变成了四维张量,其中前三维查询一个跨越X的网格,而最后一个维度查询密度和颜色通道。
2.生成辐射场
- 生成过程
辐射场的生成(也称为去噪)过程,由一个离散时间马尔可夫链控制,它定义在所有可能的预激活的辐射场的状态空间 F上,表示为固定大小的平坦的四维张量。该链的时间步长有限: {0, . . . , T}。去噪过程首先从一个标准的多元正态分布 p(fT) := N(fT |0,I) 中采样一个状态 fT,并利用带有参数θ的反向转换概率 pθ(ft−1|ft),生成状态 ft−1。
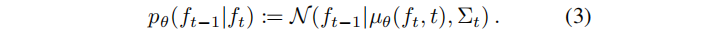
生成过程一直迭代到最终状态 f0,表示由我们的方法生成的三维对象的辐射场。(3)中的高斯分布的均值可以直接用神经网络进行建模。该公式可以重新参数化为:
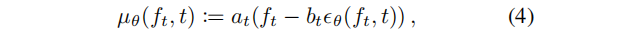
其中 ϵ \epsilon ϵθ(ft, t)是神经网络用来预测 ft−1 的噪声,而 at 和bt 是预定义系数。此外,协方差Σt 也接受一个预定义的值,尽管它可能依赖于数据。
- 扩散过程
生成过程是迭代去噪完全随机辐射场,而扩散过程则相反,迭代地从我们想要建模的三维物体的分布中破坏样本(在生成过程的训练中十分重要)。扩散过程由一个离散时间马尔可夫链控制,它具有生成过程中提到的相同的状态空间和时间边界,但具有高斯转移概率,该概率由
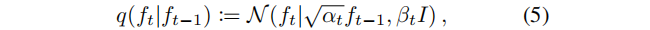
其中,αt := 1−βt , 0≤βt≤1 是预定义系数,调整注入的噪声方差。过程首先选择我们想建模的三维对象辐射场的分布 q(f0)的f0,迭代采样给定 ft−1的 ft,产生后者的缩放和噪声破坏的版本,并停止与于接近完全随机的 fT。利用高斯分布的性质,我们可以方便地将 f0 条件下的ft 分布直接表示为高斯分布,得到:
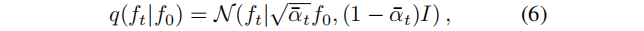
3.训练目标
训练目标包括两个互补的损失: i)一个损失 LRF,惩罚产生不符合数据分布的辐射场,以及ii)一个RGB损失LRGB,旨在提高从生成的辐射场的渲染质量。每个数据点 f0 的最终损失为加权组合,并从均匀分布 κ(t) 对步骤 t 进行随机抽样:
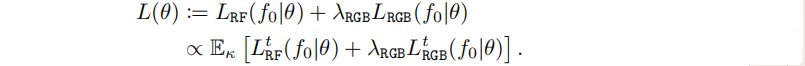
最终损失。综上所述,:
- Radiance field generation loss
根据DDPM,我们从负对数似然(NLL)的变分上界开始,推导出训练目标。 这个上界需要指定一个替代分布,我们称之为q,因为它确实对应于控制扩散过程的分布q,建立了与生成过程的预期的基本联系。 通过Jensen不等式,一个数据点 f0∈F 的NLL可以通过利用q得到上界,如下所示:
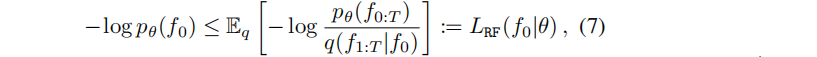
LRF 公式如下,取决于一个独立于θ的常数:
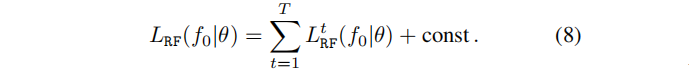
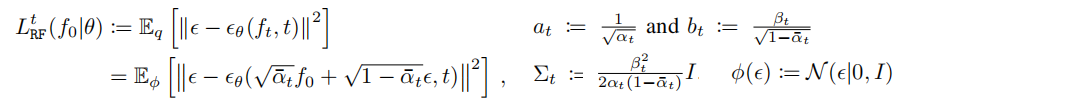
- Radiance field rendering loss
我们用额外的RGB损失 LRGB(f0|θ)来补充前一的损失,提高辐射场中渲染的质量。前项损失中隐式地使用的表示上的欧氏度量来评估生成的辐射场的质量,并不一定能确保在渲染时没有伪影。
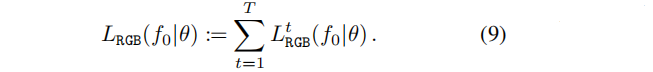
辐射场 f 的在视角v 渲染图像 和GroundTruth 图像Iv 之间的欧氏距离损失:
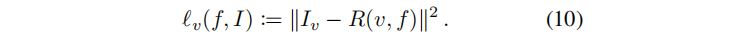
核心思想是比较:从被 t 步扩散破坏的数据分布中,采样的给定辐射场f0的渲染,然后与用于获得f0 的原始GT图像 Lv 进行完全去噪.。这意味着,首先从 q(ft|f0) 开始采样ft,然后从 pθ(f0|ft) 采样回 f0。我们求助于一个更简单的近似。从 LRFt 的定义,损失有 ϵ \epsilon ϵ≈ ϵ \epsilon ϵθ(ft,t),由此推导出的近似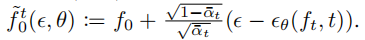
渲染损失定义为:
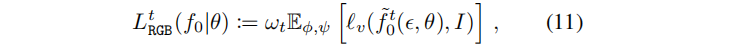
其中,对视点v 和 ϵ \epsilon ϵ≈φ( ϵ \epsilon ϵ)的先验分布 ψ进行期望。由于近似只有在步长t接近于零时是合理的,我们引入了一个权重wt,它随着步长值的增加而衰减(例如:使用ωt := α ˉ \bar{α} αˉt2)。我们在实验部分提供的证据表明,尽管这是一个近似值,但所提出的损失有助于显著改善结果
- 细节
ϵ \epsilon ϵθ具体采用一个3D-UNet,将论文呢[Diffusion models beat gans on image synthesis]中用3D操作符替换2D卷积和注意层。均匀采样时间步长t = 1,…,T = 1000,扩散方差从β1 = 0.0015,线性增加到 βT = 0.05;ωt := α ˉ \bar{α} αˉt2。
4.实验
数据集:选择 PhotoShape Chairs (从200个视图上渲染提供的15576把椅子) 和 Amazon Berkeley Objects (ABO) Tables 数据集(91个渲染图,每个对象2-3个不同设置,得以纯图像形式,使用基于体素的方法从多视图渲染中以323 的分辨率生成.
指标:使用(FID)和KID评估图像质量。为几何质量使用倒角距离(CD)计算覆盖率评分(COV)和最小匹配距离(MMD)。MMD评估生成样本的质量(分辨率均为128×128)
1. 无条件生成
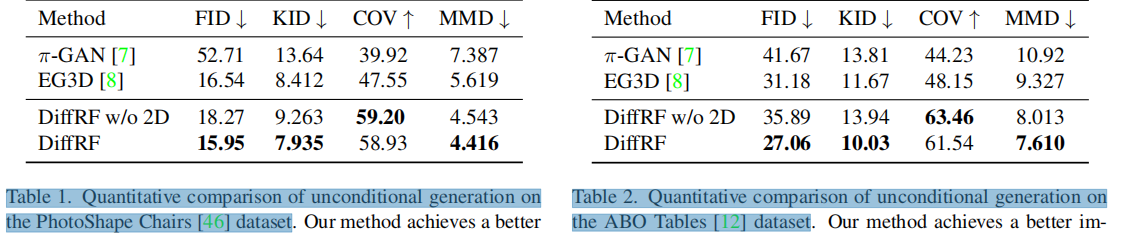

表1和表2显示了消融结果:二维监督对辐射合成的影响,删除2D监督(“DiffRFw/o2D”,表中第3行)对FID有显著影响。这表明,通过体积渲染损失使DDPM的噪声预测公式偏置会导致更高的图像质量。
- 条件生成
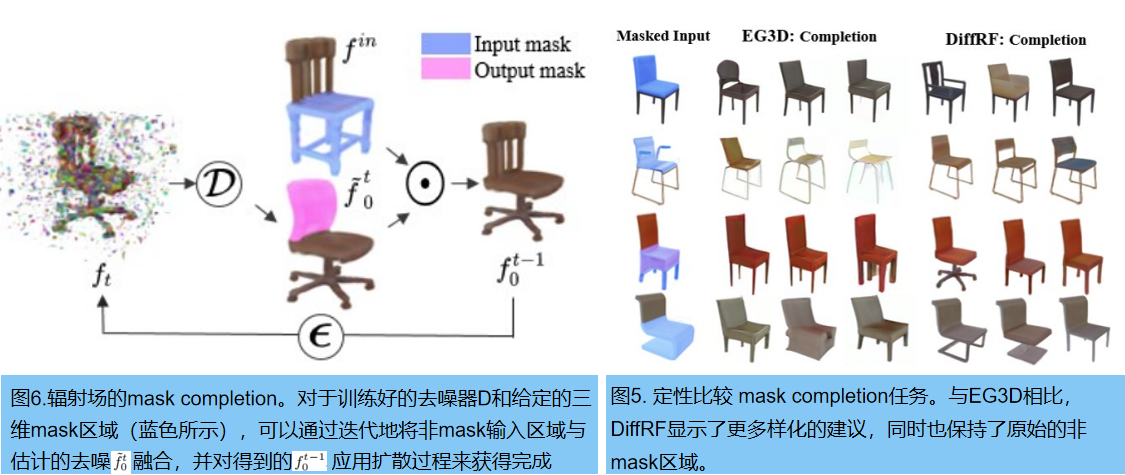
GANs需要训练后,才能以特定的任务为条件,而扩散模型可以在测试时间内有效地作为条件。我们利用这一特性来进行辐射场的 masked completion任务。
masked completion
Shape completion 和 image inpainting 是被深入研究的任务,旨在分别填充几何表示中或图像中的缺失区域。masked completion 任务结合了两者:给定一个辐射场和一个三维mask,合成一个与非mask区域协调的重建。受RePaint [34]的启发,我们通过逐步引导已知区域的无条件采样过程,来执行输入fin 的条件补全。
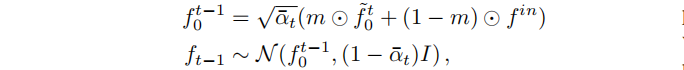
其中,m是应用于输入的二进制掩模(图6中的浅蓝色),⚪表示体素网格上的元素级乘法。
单张图像重建

五、EG3D:高效的几何感知的三维生成对抗网络(CVPR 2022)
题目:EG3D: Efficient Geometry-aware 3D Generative Adversarial Networks
论文: https://nvlabs.github.io/eg3d/media/eg3d.pdf
工程: EG3D: Efficient Geometry-aware 3D GANs
代码: GitHub - NVlabs/eg3d
任务:基于单视角2D图片,通过无监督方法,生成高质量、多视角一致的3D形状
;现有3D GAN存在:1)计算开销大;2)不具有3D一致性(3D-consistent)等问题。
现有2D GAN无法显式地建模潜在的3D场景;最近的3D GAN工作,开始解决:1)多视角一致的图片生成;2)无需多视角图片和几何监督,提取3D形状。但是3D GAN生成的图片质量和分辨率仍然远逊于2D GAN。还有一个问题是,目前3D GAN和Neural Rendering方法计算开销大。
3D GAN通常由两部分组成:1)生成网络中的3D结构化归纳偏置;2)neural rendering engine提供视角一致性结果。其中,归纳偏置可以被建模为:显式的体素网格或隐式的神经表达。但受限于计算开销,这两种表达方式都不适用于训练高分辨率的3D GAN。目前常用的方法是超分,但超分又会牺牲视觉连续性和3D形状的质量。
本文提出EG3D,具有如下优点:
1.提出一种三平面的 3D GAN框架,作为expressive hybrid explicit-implicit 神经网络框架:提速、减小计算开销;
2.解耦的特征生成和神经渲染:借助StyleGAN2等 2D GAN网络,对生成器引入pose-based conditioning,解耦pose相关属性,例如人脸表情系数;
3.提出一种3D GAN训练策略dual discrimination,用于保持多视角一致性
3.在FFHQ和AFHQ Cats的3D-aware synthesis任务上达到sota。
1.常见的:3D场景的神经表示方法
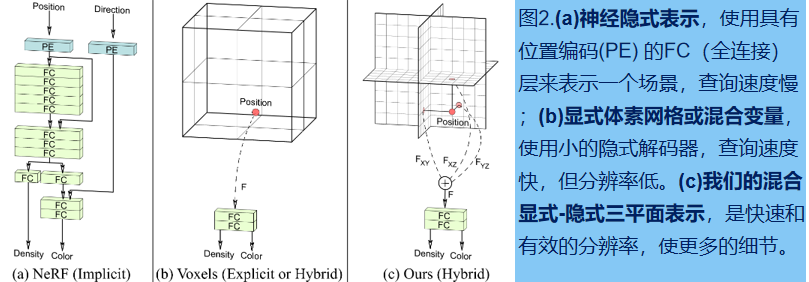
1.显示表达(图b),例如:discrete voxel grids。优点是fast to evaluate,缺点是需要大量的内存开销大;
2.隐式表达(图a):例如:neural rendering。优点是内存使用高效,缺点是slow to evaluate。
3.局部隐式表达和混合显-隐式表达,则兼具了两者优点。
受此启发,本文设计了hybrid explicit-implicit 3D-aware network(图c):用tri-plane representation去显示存储沿坐标轴对齐的特征,而特征则是被通过特征解码器隐式的渲染为体素。
2.几种 生成式 3D-aware图像合成 对比
- Mesh-based 方法;Voxel-based GANs,内存开销大,通常需要使用超分,但超分会导致视角不一致;Block-based sparse volume representations:泛化性不好。Fully implicit representation networks,但测试很慢。
- StyleGAN2-based 2.5D GAN:生成冗余的图片和深度图;
- 3D GAN,例如StyleNeRF和CIPS-3D的区别:在3D形状上表现不佳。
3.Tri-plane hybrid 3D 表示
建立xyz三个相互垂直的特征平面,每个特征平面维度为 N x N x C(N为平面分辨率,C为特征维度)。对于任意一个3D位置,通过双线性插值,可索引到3个特征向量(Fxy, Fxz, Fyz),最终特征F为3个特征向量的拼接。
通过一个轻量级MLP解码网络,将特征F映射为颜色和强度,最后通过neural volume rendering将他们渲染为RGB图片。下图显示,Tri-plane在具有更强表现能力的同时,内存开销更小,计算速度更快。

4. 3D GAN framework
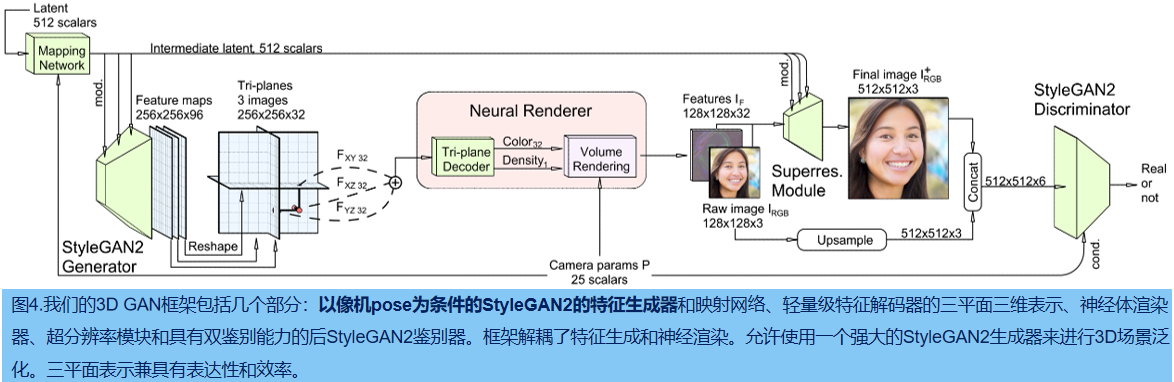
- 两种训练方法:
方法1:随机初始化,使用non-saturating GAN loss with R1 regularization,训练方法跟随StyleGAN2;
方法2:两阶段训练策略,先训64 x 64的neural rendering,然后接128 x 128的fine-tune。
实验显示,正则化有助于减少3D形状的失真。
- CNN generator backbone and rendering
decoder:MLP,每层包含64个神经元和softplus activation functions。MLP的输入可以是连续坐标,输出是scalar density和32维的特征
Volume rendering:输入feature ,而不是RGB图片。因为,feature 包含更多可在超分中使用的信息。
- Dual discrimination
鉴别器输入为6通道。本文认为image feature IF 的前三个通道是低分辨率RGB图片IRGB。dual discrimination首先要求IRGB 和超分图片 I ^ \hat{I} I^RGB+保持一致(通过双线性上采样);然后将超分图片和上采样图片拼接在一起送入鉴别器。对于真实图片,则是将真实图片和经过blur处理的真实图片拼接在一起送入鉴别器。
将相机内外参数送入鉴别器,作为条件标签。
- 建模 pose-相关属性
大多数现实世界数据集包含偏置,例如在FFHQ中,人脸表情和相机位置相关,通常来说,当相机正对人脸时,人是在笑的。本文提出generator pose conditioning,用于解耦训练图片中pose 和其他属性。
为增强模型对输入pose的鲁棒性,在训练中,会以50%概率将相机参数矩阵P中的位姿替换为随机pose。
消融实验发现,在训练时加入pose 作为条件很重要。未来的工作会考虑去除它。
5.实验对比、应用
FFHQ真实人脸数据集,AFHQv2 Cats,真实猫脸数据集。对比其他方法:


应用:

总结
提示:这里对文章进行总结:
例如:以上就是今天要讲的内容,本文仅仅简单介绍了pandas的使用,而pandas提供了大量能使我们快速便捷地处理数据的函数和方法。
d \sqrt{d} d 1 0.24 \frac {1}{0.24} 0.241 x ˉ \bar{x} xˉ x ^ \hat{x} x^ x ~ \tilde{x} x~ ϵ \epsilon ϵ