文章目录
- 第1关:MySQL 数据源
- 任务描述
- 相关知识
- PySpark JDBC 概述
- PySpark JDBC
- PySpark Streaming JDBC
- 编程要求
- 测试说明
- 答案代码
- 第2关:Kafka 数据源
- 任务描述
- 相关知识
- Kafka 概述
- Kafka 使用基础
- PySpark Streaming Kafka
- 编程要求
- 测试说明
- 答案代码
第1关:MySQL 数据源
任务描述
本关任务:读取套接字流数据,完成词频统计,将结果写入 Mysql 中。
相关知识
为了完成本关任务,你需要掌握:
- PySpark JDBC 概述;
- PySpark JDBC;
- PySpark Streaming JDBC。
PySpark JDBC 概述
在 PySpark 中支持通过 JDBC 的方式连接到其他数据库获取数据生成 DataFrame,当然也同样可以使用 Spark SQL 去读写数据库。除了 JDBC 数据源外,还支持 Parquet、JSON、Hive 等数据源。
PySpark JDBC
在学习 PySpark Streaming JDBC 之前,我们先来了解一下在 PySpark 中如何使用 JDBC。
需求:
- 读取 Mysql 中的数据;
- 往 Mysql 中写入数据。
首先,打开右侧命令行窗口,等待连接后,进入 MySQL,任意创建一个库,在该库中任意创建一张表,任意写入一些数据。
# 启动 mysql 服务
service mysql start
# 进入 mysql
mysql -uroot -p123123
# 创建 test 库
create database if not exists test;
# 创建表
use test;
create table if not exists student(
id int,
name varchar(50),
class varchar(50));
# 数据写入
insert into student values(1,"zhangsan","A");
insert into student values(2,"lisi","B");
insert into student values(3,"wangwu","C");
创建完成后,进入 python3 shell 界面。
python3

开始编写程序,第一步,先导入相关包
from findspark import init
init()
from pyspark import SparkConf, SparkContext
from pyspark.sql import SparkSession
第二步,创建 Spark 对象
spark = SparkSession.builder.appName("read_mysql").master("local[*]").getOrCreate()
第三步,读取 Mysql 中的数据
dataFrame = spark.read.format("jdbc").option("driver", "com.mysql.jdbc.Driver") .option("url", "jdbc:mysql://localhost:3306/test").option("dbtable", "student") .option("user", "root").option("password", "123123").load()
第四步,输出读取的数据
# 注意,show() 方法默认只会显示前 20 行数据。
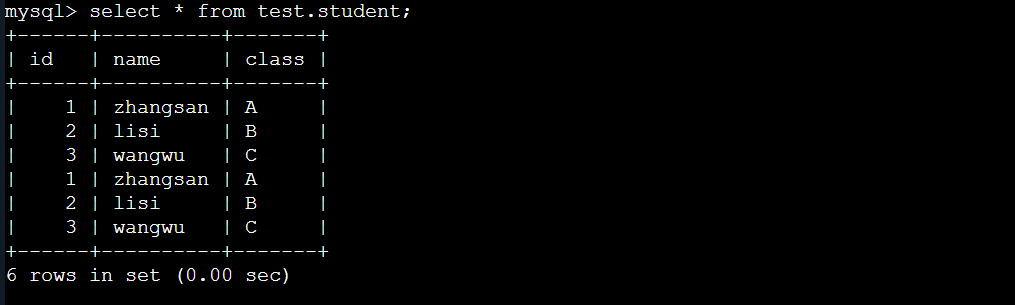
dataFrame.show()
输出结果如图所示: 
第五步,将读取的数据以追加的方式写入库中
dataFrame.write.format("jdbc").option("driver", "com.mysql.jdbc.Driver") .option("url", "jdbc:mysql://localhost:3306/test").option("dbtable", "student").option("user", "root").option("password", "123123").mode(saveMode="append").save()
进入 Mysql 中查看结果:
# 进入 Mysql
mysql -uroot -p123123
# 查询数据
select * from test.student;
PySpark Streaming JDBC
通过对 PySpark JDBC 的学习,我们了解了在 Python 中是如何使用 JDBC 的,现在来学习 PySpark Streaming JDBC 的连接方式。
需求:通过读取套接字流,进行词频统计,将数据写入 Mysql 中。
首先,打开右侧命令行窗口,等待连接后,进入 MySQL,创建 spark 库,在该库中创建 wordcount 表。
# 启动 mysql 服务
service mysql start
# 进入 mysql
mysql -uroot -p123123
# 创建 test 库
create database if not exists spark;
# 创建表
use spark;
create table if not exists wordcount(
word varchar(50),
count int);
创建完成后,进入主目录 /root,创建代码文件 mysql.py,对其进行编辑。
cd /root
vi mysql.py
开始编写程序,第一步,先导入相关包
from findspark import init
init()
import time
import pymysql
from pyspark import SparkContext
from pyspark.streaming import StreamingContext
第二步,创建 Spark 环境与检查点
sc = SparkContext(appName="mysql_streaming", master="local[*]")
ssc = StreamingContext(sc, 10)
# 设置套接字流信息
inputStream = ssc.socketTextStream("localhost", 7777)
# 设置检查点
ssc.checkpoint("/usr/local/spark")
第三步,对数据进行相关操作
# 累加器(状态更新)
def updateFunction(newValues, runningCount):if runningCount is None:runningCount = 0return sum(newValues, runningCount)
pairs = inputStream.flatMap(lambda x: x.split(" ")).filter(lambda x: x != "").map(lambda x: (x, 1))
wordCounts = pairs.updateStateByKey(updateFunction)
wordCounts.pprint(100)
第四步,写入 Mysql 处理
def dbfunc(records):db = pymysql.connect("localhost", "root", "123123", "spark")cursor = db.cursor()def doinsert(p):sql = "insert into wordcount(word,count) values ('%s', '%s')" % (str(p[0]), str(p[1]))try:cursor.execute(sql)db.commit()except:db.rollback()for item in records:doinsert(item)
def func(rdd):repartitionedRDD = rdd.repartition(3)repartitionedRDD.foreachPartition(dbfunc)
wordCounts.foreachRDD(func=func)
第五步,启动与停止
ssc.start()
time.sleep(30)
ssc.stop()
第六步,新增一个命令行窗口,启动数据流服务
nc -l -p 7777
第七步,返回代码文件窗口,运行程序
python3 /root/mysql.py
第八步,程序启动后,切换到数据流服务窗口,输入如下数据:
hello pyspark
hello pyspark streaming
hello jdbc
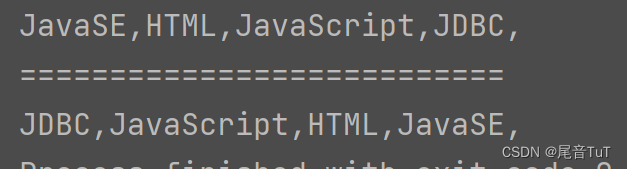
程序结束后,进入 Mysql 中查看结果:
# 进入 Mysql
mysql -uroot -p123123
# 查询数据
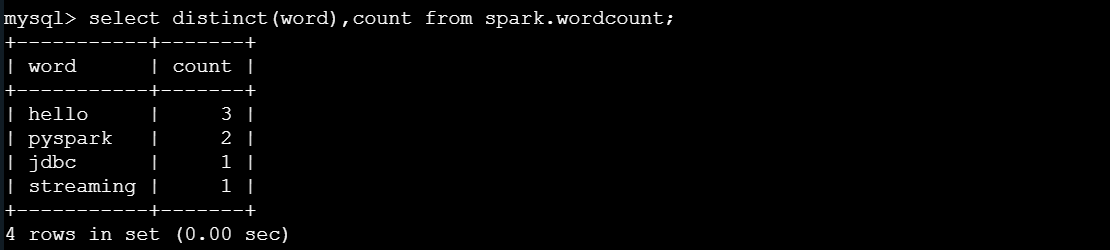
select distinct(word),count from spark.wordcount;
结果如图所示:
编程要求
打开右侧代码文件窗口,在 Begin 至 End 区域补充代码,执行程序,读取套接字流数据,按空格进行分词,完成词频统计。在 Mysql 中创建 work 数据库,在该库中创建表 wordcount,添加字段 word(字符型),字段 count(整型),将词频统计结果写入该表中。
代码文件目录: /data/workspace/myshixun/project/step1/work.py
套接字流相关信息:
- 地址:
localhost - 端口:
8888 - 输入数据:
待程序启动后(5s),请在 60 秒内写入数据,如果需要调整时间,你可以通过修改代码文件中 time.sleep(60) 来指定时间。
When summer comes, people like to go to the beach and play in the seawater.
It is such a good way to drive away the hotness.
But it has been reported that many people drawn while they were swimming on the beach.
The people who died were good at swimming, the reason they got killed was the invisible demon under the seawater.
In the afternoon, there are some vortexes under the seawater, which people can’t see.
When people go swimming, they will be absorbed by the vortexes, even though they are good at swimming, they can’t resist the strong power.
So when we go to play in the beach, we must take care.
输入内容后,注意按回车。
Mysql 信息:
- 账号:
root - 密码:
123123 - 地址:
localhost - 端口:
3306
请在程序运行完成后再进行评测,否则会影响最终结果。
测试说明
平台将对你编写的代码进行评测,如果与预期结果一致,则通关,否则测试失败。
答案代码
from findspark import init
init()
import time
import pymysql
from pyspark import SparkContext
from pyspark.streaming import StreamingContextsc = SparkContext(appName="mysql_streaming", master="local[*]")ssc = StreamingContext(sc, 10)# 设置检查点
ssc.checkpoint("/usr/local/work")# 累加器(状态更新)
def updateFunction(newValues, runningCount):if runningCount is None:runningCount = 0return sum(newValues, runningCount)# 设置套接字流
############### Begin ###############
inputStream = ssc.socketTextStream("localhost", 8888)############### End ###############pairs = inputStream.flatMap(lambda x: x.split(" ")).filter(lambda x: x != "").map(lambda word: (word, 1))wordCounts = pairs.updateStateByKey(updateFunction)wordCounts.pprint(100)def dbfunc(records):# 根据传入的 records 参数,完成数据写入 Mysql 操作############### Begin ################ 连接 MySQL 数据库connection = pymysql.connect(host='localhost',user='root',password='123123',database='work',port=3306,)with connection.cursor() as cursor:# 根据传入的 records 参数,完成数据写入 Mysql 操作for record in records:word, count = recordcursor.execute('INSERT INTO wordcount (word, count) VALUES (%s, %s)', (word, count))connection.commit()connection.close()############### End ################ 分区设置
def func(rdd):repartitionedRDD = rdd.repartition(3)repartitionedRDD.foreachPartition(dbfunc)wordCounts.foreachRDD(func=func)ssc.start()time.sleep(60)ssc.stop()
打开一个命令行窗口
# 启动 mysql 服务
service mysql start
# 进入 mysql
mysql -uroot -p123123
# 创建 test 库
create database if not exists work;
# 创建表
use work;
create table if not exists wordcount(word varchar(50),count int
);
# 退出 mysql
exit
# 创建检查点目录
mkdir -p /usr/local/work/
nc -l -p 8888
再打开一个窗口
chmod 777 /data/workspace/myshixun/project/step1/work.py
python3 /data/workspace/myshixun/project/step1/work.py # 现在开始运行代码文件,请在 60 秒内创建文件并写入下面数据
回到第一个窗口,把下面数据粘贴上去再打一个回车
When summer comes, people like to go to the beach and play in the seawater.
It is such a good way to drive away the hotness.
But it has been reported that many people drawn while they were swimming on the beach.
The people who died were good at swimming, the reason they got killed was the invisible demon under the seawater.
In the afternoon, there are some vortexes under the seawater, which people can’t see.
When people go swimming, they will be absorbed by the vortexes, even though they are good at swimming, they can’t resist the strong power.
So when we go to play in the beach, we must take care.
第2关:Kafka 数据源
任务描述
本关任务:读取 Kafka 生产的数据,完成输出。
相关知识
为了完成本关任务,你需要掌握:
- Kafka 概述;
- Kafka 使用基础;
- PySpark Streaming Kafka。
Kafka 概述
Kafka 就是一个分布式的用于消息存储的发布订阅模式的消息队列。一般用于大数据的流式处理中。 具有高水平扩展性、高容错性、访问速度快、分布式等特性,主要应用场景是日志收集系统和消息系统。但是随着 Kafka 的快速发展,也被应用于高性能数据管道、数据集成、流分析等。

Kafka 使用基础
在学习 Pyspark streaming Kafka 之前,我们先来学习一下 Kafka 的使用基础。
首先,打开右侧命令行窗口,等待连接后,启动 Kafka 服务。
# kafka 依赖 zookeeper,所以需要先启动 zookeeper 服务
cd /opt/zookeeper
bin/zkServer.sh start conf/zoo.cfg
# 启动 Kafka 服务
cd /opt/kafka
bin/kafka-server-start.sh -daemon config/server.properties
检查服务是否启动成功,输入 jps 后,出现如下所示,表示启动成功: 
创建 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --replication-factor 1 --partitions 1 --topic first
这个 topic 叫 first,2181 为 zookeeper 默认的端口号,partition 是 topic 里面的分区数,replication-factor 是备份的数量,在 kafka 集群中使用,这里单机版就不用备份了。
查看当前服务器中的所有 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --list

创建 producer 生产者
在 xxx 节点发送消息。
bin/kafka-console-producer.sh --broker-list xxx:9092 --topic first
创建 consumer 消费者
在 xxx 节点接收消息。
bin/kafka-console-consumer.sh --zookeeper xxx:2181 --from-beginning --topic first
删除 topic
bin/kafka-topics.sh --zookeeper master:2181 --delete --topic first
PySpark Streaming Kafka
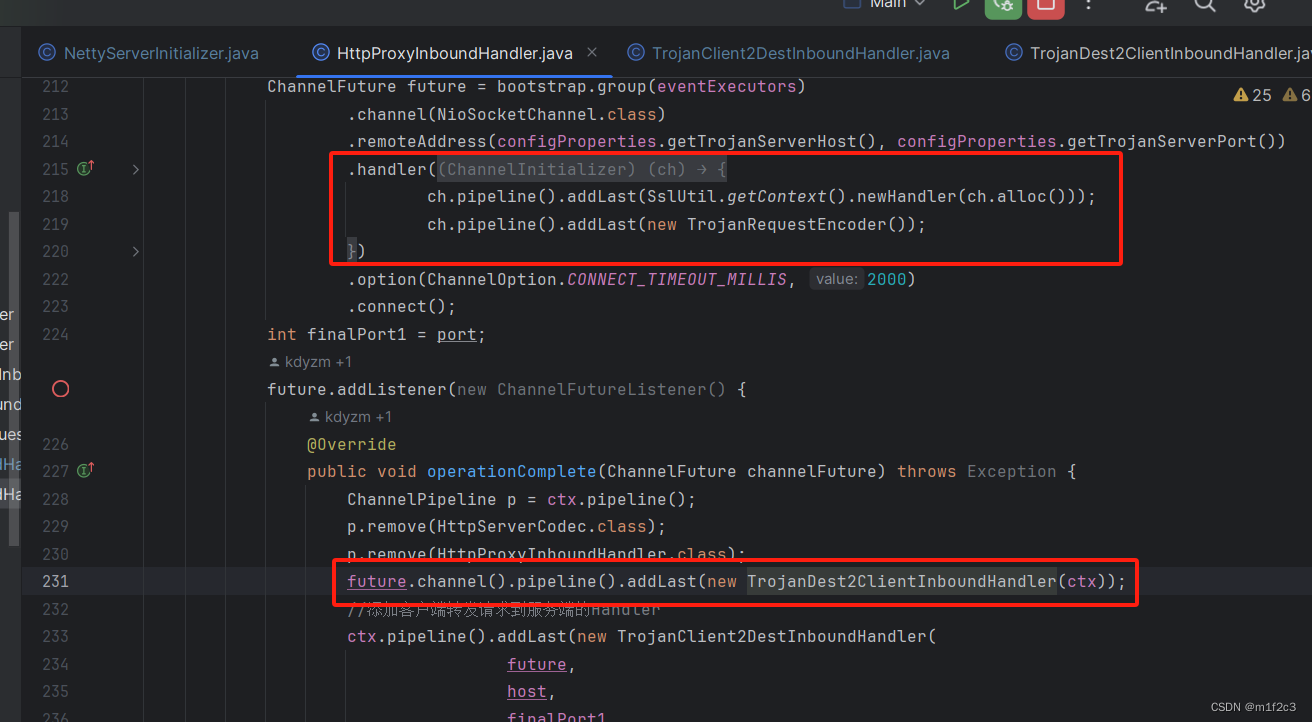
通过对 Kafka 基础使用的学习,现在来通过一个案例学习在 PySpark Streaming 中如何连接 Kafka。
需求:消费 Kafka 生产的数据,完成输出。
首先,打开右侧命令行窗口,等待连接后,启动 Kafka 服务。
# 启动 zookeeper 服务
cd /opt/zookeeper
bin/zkServer.sh start conf/zoo.cfg
# 启动 Kafka 服务
cd /opt/kafka
bin/kafka-server-start.sh -daemon config/server.properties
创建 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --replication-factor 1 --partitions 1 --topic test
新增一个命令行窗口,等待连接后,在 /root 目录下创建 test.py 程序文件
cd /root
touch test.py
编辑文件 test.py,编写程序,第一步,导入相关文件包。
from pyspark.sql import SparkSession
第二步,创建 Spark 环境
spark=SparkSession.builder.appName("kafka_stream").master("local[*]").getOrCreate()
第三步,创建 Kafka 数据流
在 pyspark 中,我们通过 KafkaUtils.createStream() 方法创建 Kafka 数据流,但该方法在 Spark 3.0 中以及弃用,现在采用 spark.readStream.format("kafka") 方法来创建 Kafka 数据流。
df = spark \.readStream \.format("kafka") \# 绑定 Kafka 生产地址.option("kafka.bootstrap.servers", "localhost:9092") \# 订阅 topic.option("subscribe", "test") \# 设置偏移量(最新).option("startingOffsets","latest") \.load()
第四步,收集数据
table = df.selectExpr("CAST(value AS STRING)")
第五步,输出到屏幕,启动程序
table.writeStream \# 指定监听间隔时间.trigger(processingTime='5 seconds') \# 输出方式.outputMode("append") \# 不将内容进行清空.option("truncate", "false")\.format("console") \.start() \# 60 秒后停止程序.awaitTermination(timeout=60)
编写完程序后,保存退出,切换到 Kafka 服务的命令行窗口,创建生产者。
cd /opt/kafka
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
第六步,返回编写程序文件的命令行窗口,运行程序
spark-submit --master local[*] --driver-class-path /opt/kafka/libs/kafka-clients-2.8.0.jar --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.2 --jars /opt/spark/jars/spark-streaming-kafka-0-10-assembly_2,12-3,0,2.jar --py-files test.zip test.py
注意,运行程序前需要先压缩程序文件,压缩命令语法如下:
zip 压缩后文件名.zip 原文件名
第七步,程序启动后,切换到 Kafka 数据流服务窗口,输入如下数据:
hello kafka
hello pyspark streaming
I love big data
结果如图所示:
编程要求
打开右侧代码文件窗口,在 Begin 至 End 区域补充代码。 在 Kafka 中创建一个 topic,作为一个生产者,完善程序,读取 Kafka 流数据并以 append 方式输出。通过 spark-submit 的方式运行代码文件,将输出信息保存到 /data/workspace/myshixun/project/step2/result.txt 结果文件中。
代码文件目录: /data/workspace/myshixun/project/step2/work.py
Kafka 相关信息:
- Kafka 主目录:
/opt/kafka - Zookeeper 主目录:
/opt/zookeeper - Zookeeper 地址:
localhost:2181
Kafka 输入内容:
程序启动后(15s左右),请在 60 秒内写入数据,如果需要调整时间,你可以通过修改代码文件中 .awaitTermination(timeout=60) 的 timeout 指定时间。
Hello world!
Hello python!
Hello spark!
Hello Kafka!
I love bigdata.
提交命令:
注意压缩文件。
spark-submit --master local[*] --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.2 --py-files xxx.zip xxx.py > /data/workspace/myshixun/project/step2/result.txt
请等待程序运行完成后进行评测,否则会影响最终结果。
测试说明
平台将对你编写的代码进行评测,如果与预期结果一致,则通关,否则测试失败。
答案代码
from pyspark.sql import SparkSessionspark = SparkSession.builder.appName("kafka_stream").master("local[*]").getOrCreate()############### Begin ###############df = spark \.readStream \.format("kafka") \.option("kafka.bootstrap.servers", "localhost:9092") \.option("subscribe", "test") \.option("startingOffsets","latest") \.load()table = df.selectExpr("CAST(value AS STRING) as message")table.writeStream \.trigger(processingTime='5 seconds') \.outputMode("append") \.option("truncate", "false")\.format("console") \.start() \.awaitTermination(timeout=60) ############### Begin ###############进入右侧命令行窗口
# kafka 依赖 zookeeper,所以需要先启动 zookeeper 服务
cd /opt/zookeeper
bin/zkServer.sh start conf/zoo.cfg
# 启动 Kafka 服务
cd /opt/kafka
bin/kafka-server-start.sh -daemon config/server.properties
# 创建 topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --replication-factor 1 --partitions 1 --topic test
# 创建 producer 生产者
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
再打开一个命令行窗口
cd /data/workspace/myshixun/project/step2/
zip work.zip work.py
spark-submit --master local[*] --packages org.apache.spark:spark-sql-kafka-0-10_2.12:3.0.2 --py-files work.zip work.py > result.txt
回到前一个命令行窗口,在程序启动 15s 左右时间后再填入下面数据,并且在 60s 内完成写入
Hello world!
Hello python!
Hello spark!
Hello Kafka!
I love bigdata.