最近读完了这本《游戏人工智能编程 案例精粹》,感觉获益匪浅,在对游戏人工智能的设计上有了更深的感悟。

这本书既适合初学者学习,因为次书会从最基础的数学物理公式推导一步一步介绍到完整的人工智能开发;同时也适合进阶程序员,因为其设计思路、解决方案能给人以很大启发。
要注意的是:这里讲的人工智能,并非现在大火的强人工智能(AI),而是游戏中的行为体智能控制(例如控制 NPC 行动的状态机)。
层级状态机
目前的游戏AI开发,一般是状态机模式或者行为树模式。这里我就不介绍状态机、行为树的基本概念了,有不清楚的可以参考以下文章的介绍。
-
游戏AI游戏研究(二):状态机与行为树_状态机和行为树-CSDN博客
-
行为树VS状态机 - 卧沙的猫眼螺 知乎专栏
书中除了对常规的状态机进行了运用和讨论之外,特别提到了状态机的 “崩溃” 问题:即在存在大量状态节点时,维护状态机就变得特别复杂(复杂度为 n*n)。

作者给出的解决方案是分层状态机:将部分状态统一整合成一个层级,与其他状态区分开来,从而大量减少维护难度。具体的介绍参考以下链接:
-
FSM(状态机)、HFSM(分层状态机)、BT(行为树)的区别-CSDN博客
-
层次化状态机的讨论 – AI分享站

这个解决方案也很简单,但很少听人提起过(可能是我孤陋寡闻)。在我看来,层次化状态机极大减少了AI系统的复杂度,且相似的状态机层级可以复用,减少代码量,增加了扩展性。
例如游戏中常见的矿工 NPC,他的行为有以下类型:
-
饿了吃饭,渴了喝水,困了睡觉等基本行为需求;
-
当遇到敌人攻击时,选择攻击敌人,或者逃跑;
-
生病了需要找医生、娱乐值低了需要找酒馆等;
-
无所事事时,会去街上散步,去广场上找人聊天等;
如果按照传统状态机的写法,那将会出现数十种状态,每个状态都要能互相切换。此时状态机的控制将会非常复杂,且每增加一种行为都会导致控制难度呈几何增长。于是我们对状态机进行分层,例如按照马斯洛需求层次理论将状态机分到不同层级,并按照优先级排序。

通过对状态机进行分层,将大量状态整合,控制起来更为清晰,同时也更能符合玩家的通常认知。
除AI外,有限状态机的一大应用场景就是 Unity 里面的动画状态机(Animation Controller),这套系统甚至能支持多层级状态机,可以说非常完整了。在制作状态机编辑器时,最方便的就是直接复用这套系统(参考 Unity -> 用动画状态机来做行为树 - 哔哩哔哩)或者使用 Vitrual Scripting 来做状态机:About Visual Scripting | Visual Scripting | 1.9.5。
值得一提的是,状态机和行为树并不是互斥的,没有说法用了一个就不能用另一个。我们在开发时完全可以对 AI 的各个层级进行抽象,内部既可以使用状态机也可以使用行为树。考虑到 AI 一般是程序开发可视化编辑工具,策划进行配置,所以不论实现上多复杂,抽象后的行为逻辑也应简洁明了。
自治智能体
自治智能体,简单来说,就是 AI 不会精确控制到智能体的准确行为,而由智能体自己决定。例如上层 AI 只会命令智能体从 A 点移动到 B 点,至于搜索到的路径、中途如何避让障碍物这些行为则并不关心,交由智能体自行处理(底层的寻路算法、RVO等)。
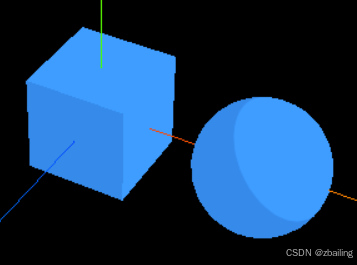
在实际游戏中,通常遇到的情景是智能体常常会被各种系统影响,例如避障、物理碰撞(模拟),以及自身的行走(寻路),以图中所示:

-
蓝色箭头:寻路指引的方向,也是智能体自身期望的行进方向。
-
浅红色:墙体的阻挡对当前智能体施加的碰撞;
-
浅黄色:其他智能体单位对目标智能体施加的挤压碰撞力;
这么多的力结合起来,最终形成一个合力(图中绿色箭头),便是最终的行进方向。但并不是简单地加和,而是带优先级的加权截断(Weighted Truncated Running Sum wtih Prioritization)。
在实际游戏中,我们通常会尽量避免穿模发生。所以我们总是会把墙体、障碍物等静态阻挡视为第一优先级,所以一旦有来自此方向的力就会只考虑这一种力,而把其他的力计算截断。当然也可以不这么粗暴,而是给其赋予极高的权重。这就是是带优先级的加权截断(Weighted Truncated Running Sum wtih Prioritization)
如果游戏 CPU 开销太高,在 Reynolds 的论文中也建议了一种计算合力的方法,成为带优先级的抖动(Prioritized Dithering)。简单地说就是给每一种力增加一个概率,每次计算时根据概率决定此时应该计算哪一种力,其他的力本帧便不予考虑。这种方法的 CPU 开销会显著降低,但会损失一些精度。
此外,对于之前提到的 “确保无重叠” 需求,其实单凭群组分离、碰撞推挤等其实并无法绝对避免重叠。书中还提到可以主动进行避障(也就是 RVO),通过主动+被动实现避免单位重叠。但说实话,其实即便使用了各种方案,也并不能避免穿模的发生(我忘了在哪里看见的一个说法,就是游戏中的穿模无论如何都避免不了的)。所以我个人看法,就是我们将穿模提到一个较高的优先级即可,但不必为不穿模而弄出很多特殊处理、不合系统设计的代码。轻微、短暂的穿模,其实玩家也是能接受的,谁还没在游戏里见过穿模啊!
寻路的答案
其实寻路不是游戏AI开发的重点(虽然有一章专门在讲寻路),其作为底层的算法只是 AI 行为的一个辅助。但由于我我在寻路上思考过很多方案,且距离我的终极目标都有一定距离(时间复杂度低、同时支持海量起点终点并发寻路且寻路地图可以实时重建),所以看这一章时不免精神了一些。
按照我之前的研究学习,对主流的几种寻路方案总结如下:
| 寻路方案 | 搜索效率 | 分步寻路* | 地图重建代价 | 多起点/目标* | 最优路径 |
|---|---|---|---|---|---|
| A Star | 低 | 否 | 低 | 是 | 是 |
| JPS/JPS+ | 高 | 否 | 高 | 是 | 是 |
| FlowFiled/Dijkstra | 极高 | 是 | 中 | 否 | 是 |
| NavMesh | 高 | 否 | 较高 | 是 | 是 |
| 蚁群算法 | 低 | 是 | 低 | 否 | 否 |
分步寻路:这里指是否可以不进行完整搜索就返回部分路径,且部分路径与最终结果相同。例如 FlowFiled 就可以先返回一小段路径,后续再补全;显然 A* 这类的寻路不行,其没有完成搜索时无法返回路径。
多起点/目标*:这里的多起点/目标的前提条件是只使用一张地图。FlowFiled/Dijkstra、蚁群算法理论上是支持多起点多终点的寻路的,但每一个路径都需要一个新的地图(内存开销成倍增长)。
-
A Star(A*):这个大家都非常熟悉了,这里就不讲算法原理了。他的缺点就是搜索效率低,极差情况下会遍历大量格子。了解这个算法的原理就知道,A* 是不能返回部分路径的,一定要完全搜索之后才能返回结果。
-
JPS/JPS+ :这两个相当于 A* 的加速,通过设置跳点、缓存最近跳点的方式能在搜索时直接跳过大量的格子。但是代价就是地图重建代价很大,需要对地图进行不止一次的遍历。如果是那种不会更改地图的游戏,离线烘焙就很优雅,但如果是地图实时重建的话,就不美好了。
-
FlowFiled/Dijkstra :FlowFiled 的原理就是 Dijkstra,这个算法会生成一张流场图,搜索时直接查图,运行时开销忽略不计。但可惜的是,这个算法是对多单位、单目标支持最好的(比如RTS游戏),对多目标的情况就很难支撑了(每增加一个目标就要多生成一张流场图)。
-
NavMesh:网格导航是将空间按照凸多边形划分,然后按照图搜索寻路。目前 Unity 内置了这一套寻路,而且非常好用。但是其缺点在于其重建地图有一定开销,而且不能很好支持战棋类游戏(例如文明系列,每一个地格都有单独的开销)。
-
蚁群算法:蚁群算法我了解得不对,它比较特殊,是派出了很多小蚂蚁去搜索目标,每个小蚂蚁每次移动都会留下信息素,之后并全局更新信息素地图。一旦有小蚂蚁找到目标,就直接能通过信息素最强烈的路径直达。这个算法的特点是他无论如何都能找到一条路(虽然不一定会达到终点),其搜索结果可能不是最优路径,但在多次迭代下会收敛。和 FlowFiled 寻路一样,他的信息素地图也是一个目标一份,因此同样不适合多目标搜索。
现有的各种寻路方案,总体上来讲都各有优缺点,只能在特定使用环境选择最适合的,而没有一个通解。之前我一直在思考,对于海量单位的开放世界寻路,应该从哪个方向入手,但无果。这次学习这本书有点茅塞顿开的意思:A* 其实一直都带有启发因子,但是我之前一直把启发因子当做了优化项,而没有想过会对这个算法产生质变。所以有结果了,能提供良好启发因子的的 A* 寻路其实就是版本答案。因为如果启发因子(G值)取得够好,就能直接让 A* 用最小代价搜索出结果。

但关键是如何设定每一个格子的 G 值。
其实方案有很多,比如根据地图生成一份热力图,或者烘培一张低精度的 NavMesh 图,再或者根据 Dijkstra 或者蚁群算法进行迭代等。根据不同项目,总会有一些处理方案。其实当明确了最终答案就是 A* 之后,反而思路明确了很多,之后再据此进行深入研究。
目标驱动(关系依赖图)
所谓目标驱动,即是让一个 AI 行为体决定自己要做什么。听起来似乎上面的状态机已经解决了这个问题,但在战略层面并没有给出解决方案。
举个例子:当一名勇士想要打造一把高级武器(传说之剑),需要材料(铁、木头)、技能、金钱以及一个铁匠朋友,那如何给勇士设定 AI 呢?如果我们将目标设置更复杂一些,例如结交朋友需要送礼,送礼需要特殊道具,特殊道具也需要打造……似乎进入了一个不休止的轮回。
一般游戏开发者都是偷懒,要么就直接设定NPC之间的关系,要么到了特定时间(或条件)直接获得对应道具。虽然这样也能实现需求,但显然 AI 的可能性就大大降低了。而且,随着游戏内容的增加,AI 的配置内容就会越来越多,越来越难以维护。
书中给出的方案是制作一个关系依赖图,画出每个目标所有依赖:

当 AI 产生这个需求时,就根据传说之剑的依赖树进行搜索,将一个大任务分解成一个一个的小任务,在之后的 AI 逻辑就简单了:伐木、交易或者出门打怪。
关系依赖图不用特别配置,根据配置表(例如物品合成表)直接自动生成即可。当然实际上会有很多优化工作可以做,例如某些行为不让 AI 去做,例如在检测到关系依赖图中存在环则需要验证配置等。而这样的关系依赖图属于这个游戏的 “常识” ,所有的 AI 都可以共用。
通过关系依赖图来确定 AI 的战略决策,显然使 AI 变得更像玩家了。当然并不是所有的 NPC 都需要使用这个,有的 NPC 就是游戏里的 “工具人” 。当我们需要在游戏里添加更多生命力时,需要让每个 AI “活起来” 时,关系依赖图则必不可少。
模糊逻辑
在实际游戏开发中,我们会给智能体施加各种行为逻辑,有的甚至是互斥的:
当自身血量较少时,要寻找医院治疗;
当敌人攻击时,要奋勇反击,驱除敌人;
当智能体手上没有武器,第一要务是去装备一件武器去准备战斗;
当敌人已经残血,应该立马给他一拳送他去轮回。
平时游戏开发怎么处理这些问题呢?一般是策划给配置一个参数,例如血量低于20%时就要找医院,敌人血量低于5%时,视为残血……诸如此类。这种情况就会导致智能体出现行为突变:例如血量从80%掉到20%的时候智能体行为如常,但从20%掉到19%时(明明变化值更少)却立马逃跑;要是此时恰好遇到敌人的血量从6%掉到4%……如此种种的行为突变,给玩家的感觉就是莫名其妙。更有甚者,部分玩家会测试出这个边界值,然后在边缘来回横跳来戏弄智能体。总而言之,这些行为都会导致玩家更能确定智能体是一段程序(虽然玩家一开始就知道智能体是程序,但还是期待着智能体能像人一样思考)。
书中推荐了使用模糊逻辑来处理这种问题:将血量映射出一个治疗欲望的期望值(线性或是分段都可以),敌人的血量映射出一个攻击欲望的期望值,诸如此类。这一步就叫做模糊化,将各种明确的逻辑转换成 “模棱两可” 的参数(治疗的欲望为 0.4,攻击敌人的欲望有 0.2 ……)。再之后,根据映射出的参数决定智能体当前的逻辑,这一步叫做去模糊化。

模糊逻辑实际上能更好地帮助智能体通过图灵测试,行为没有那么明确的边界值。在模糊逻辑下,智能体在做决策时,综合考虑了多个变量,行为也会变得更合理。当然,这样设计 AI 的缺点就是无法精准控制其每时每刻在做什么,智能体似乎有他自己的想法。
推荐阅读
-
全部文章 – AI分享站
-
云风的 BLOG: 模糊逻辑在 AI 中的应用